Abstract
Vibe Coding hat sich innerhalb kurzer Zeit als neuartiger, KI-gestützter Ansatz in der Softwareentwicklung etabliert und wird im Kontext der Implementierungsphase des Software Development Life Cycles kontrovers diskutiert. Während dem Ansatz hohe Produktivitätsgewinne und ein einfacherer Zugang zur Softwareentwicklung zugeschrieben werden, verweisen kritische Stimmen auf Risiken in Bezug auf Softwarequalität, Wartbarkeit und Sicherheit. Diese Arbeit untersucht Vibe Coding anhand einer praktischen Fallstudie zur Entwicklung eines Microservices innerhalb der Lernplattform Studyfai. Der Microservice automatisiert die Extraktion von PDF-Inhalten, die Generierung von Quizfragen in unterschiedlichen Schwierigkeitsstufen sowie die Erstellung von H5PLernressourcen zur Integration in ein bestehendes Microfrontend-Ökosystem. Die Implementierung erfolgte nahezu vollständig dialogbasiert mit großen Sprachmodellen, ohne den Einsatz autonomer Agenten. Ziel der Untersuchung ist es, die Effekte des VibeCoding-Ansatzes auf Entwicklungsgeschwindigkeit, Softwarequalität und Prozessstabilität zu analysieren. Die Ergebnisse zeigen deutliche Effizienzgewinne bei standardisierten Entwicklungsaufgaben, zugleich jedoch qualitative Mängel insbesondere in den Bereichen Wartbarkeit, Testabdeckung und architektonische Konsistenz. Auf Basis einer ISO-orientierten Qualitätsbewertung wird Vibe Coding als wirkungsvolles Instrument für Rapid Prototyping eingeordnet, dessen nachhaltiger Einsatz eine menschliche Überprüfungsinstanz und angepasste Qualitätssicherungsstrategien erfordert.
Index Terms – Vibe Coding, Microservice, Studyfai, LLM-Benchmarks, H5P, Lernplattform, Content Generation, Quiz Generation, KI, Software Development Life Cycle, Softwareentwicklung, Programmierparadigma.
Einleitung
Vibe Coding hat sich innerhalb kurzer Zeit zu einem stark diskutierten Phänomen in der Softwareentwicklung entwickelt. Zahlreiche Medienberichte und Social-Media-Diskurse zeigen, dass der Ansatz polarisiert: Während manche Vibe Coding als demokratisierenden Zugang zur Softwareentwicklung feiern [1], warnen andere vor erheblichen Qualitäts- und Sicherheitsrisiken [2]. Diese Spannbreite zeigt sich sowohl in stark positiv konnotierten Erfolgsgeschichten als auch in kritischen Analysen der technischen Risiken. Die Diskussion über Vibe Coding wird auch kulturell sichtbar: Das Collins Dictionary ernannte den Begriff zum „Word of the Year“ [3], was sowohl die technologische als auch die gesellschaftliche Bedeutung dieses Trends unterstreicht.
Zielsetzung und Abgrenzung
Im Rahmen dieses Papers wird untersucht, welche Chancen und Herausforderungen sich beim Einsatz von Vibe Coding in der Softwareentwicklung ergeben. Als praktischer Bezugspunkt dient die Entwicklung eines Microservices innerhalb der Lernplattform Studyfai, die darauf ausgerichtet ist, digitale Lerninhalte automatisiert zu erzeugen und bereitzustellen.
Der zu entwickelnde Microservice ContentGen übernimmt mehrere Funktionen:
- Extraktion und Übersetzung der Inhalte aus PDF Dokumenten
- Generierung von Quiz-Fragen in verschiedenen Schwierigkeitsstufen
- Erstellung einer H5P-Datei zur Integration in die Lernplattform
Ergänzend erfolgt die Anbindung eines Microfrontends, das die Interaktion mit dem Service ermöglicht und die erzeugten Lernressourcen nutzbar macht. In unserem Projekt wurde der Vibe Coding Ansatz von Andrej Karpathy übernommen, das in Kapitel 1.1 näher beschrieben wird. Hierbei wurde bewusst auf spezialisierte Vibe-Coding-Tools oder IDEs wie Cursor verzichtet. Stattdessen wurden ausschließlich Modelle ohne autonome Tool-Nutzung verwendet.
Die Untersuchung betrachtet die Effizienz des Vibe Coding-Ansatzes und die technischen, organisatorischen und qualitativen Herausforderungen, die beim Einsatz großer Sprachmodelle im Entwicklungsprozess auftreten können.
Grundlagen & Grundbegriffe
Im Folgenden werden die zentralen Begriffe und theoretischen Grundlagen erläutert, die für das Verständnis des Gesamtprojekts erforderlich sind. Dazu gehören die Definition des Konzepts Vibe Coding, dessen Einordnung in die Softwareevolution, eine Darstellung des aktuellen Einsatzes von KI (Künstliche Intelligenz) im Entwickleralltag sowie eine Beschreibung relevanter Anwendungsfelder von KI.
Vibe Coding Definition
Der Begriff Vibe Coding wurde von Andrej Karpathy geprägt, einem Mitgründer von OpenAI. In einem Beitrag auf X beschrieb er den Ansatz als eine Form der Softwareentwicklung, bei der der Fokus nicht mehr auf einzelnen Codezeilen liegt, sondern auf der Beschreibung der gewünschten Ergebnissen oder auch den Vibes [4]. Karpathys Beschreibung des Workflows ist folgende:
1. Definition eines neuen Features
2. Mitteilung des Features an die KI
3. Akzeptieren der Änderungen ohne tiefgreifende Überprüfung
4. Ausführung von Tests und Behebung möglicher Fehler, indem Fehlermeldungen wieder in die KI zurückgespielt werden
Dieser Zyklus führe nach Karpathy zu einem schnellen, iterativen Wachstum des Codes und eigne sich besonders für Experimente sowie frühe Prototypen. Die Softwareentwicklung wird damit zu einem dialogischen Prozess, der durch natürliche Sprache gesteuert wird [4].
Eine alternative Betrachtungsweise ergibt sich aus der Theorie der verteilten Kognition, die Edwin Hutchins 1995 prägte [5]. Diese Theorie geht davon aus, dass Denken nicht ausschließlich im Kopf einer einzelnen Person stattfindet, sondern sich auf Werkzeuge, Umgebungen und externe Darstellungen verteilt. Notizen, Skizzen oder Code fungieren dabei als aktive Speicher und Werkzeuge des Denkens. Übertragen auf Vibe Coding bedeutet dies, dass die KI zu einem kognitiven Partner wird. Die kognitive Einheit erweitert sich von der einzelnen Entwicklerperson auf ein System bestehend aus Mensch, KI-Modell, Chatoberfläche und entstehendem Code [6].
Dieser Prozess schafft neue Abhängigkeiten: Sobald die KI-Anweisungen missversteht, muss der Mensch seine Prompts anpassen, klarer formulieren oder den Output manuell korrigieren. Vibe Coding wird damit zu einer Form der kooperativen Problemlösung, bei der Mensch und KI gemeinsam ein Team bilden.
Einordnung in die Softwareevolution
Historisch betrachtet reiht sich Vibe Coding in eine lange Entwicklung technischer Abstraktionsstufen ein [6]: Von frühen Low-Level-Sprachen über Hochsprachen, objektorientierte Paradigmen, Web-Frameworks sowie Low-Code- und No-Code-Plattformen bis hin zu KIgestütztem Programmieren. Der Fokus verschiebt sich stetig: Weg von technischer Hardware-Nähe hin zu höherer Abstraktion und Entwicklerproduktivität. Vibe Coding stellt in diesem Kontinuum die nächste Stufe dar: Es verlagert den Schwerpunkt von Befehlen auf Ziele und von technischer Umsetzung auf Kreativität. Die natürliche Sprache wird zum primären Interface der Softwareentwicklung.
Diese Entwicklung spiegelt sich deutlich in aktuellen arbeitsmarktbezogenen Befunden wider. Laut PwC AI Jobs Barometer 2025 [7]:
- wächst die Produktivität in KI-intensiven Branchen seit 2022 fast dreimal so schnell wie in anderen Sektoren.
- Skillsets in KI-nahen Berufen verändern sich derzeit 66 % schneller als zuvor. Wissen verschiebt sich von technischer Syntax hin zu Aufgabenorchestrierung und dem effizienten Anleiten KI-basierter Systeme.
- Die Eintrittsbarrieren sinken: Der Anteil an Stellenausschreibungen, die einen akademischen Abschluss verlangen, sank von 66 % auf 59 %.
- Gleichzeitig steigen die Gehälter für kompetenten KI-Einsatz im Durchschnitt um 56 % im Vergleich zu anderen Sektoren.
Diese Entwicklungen verdeutlichen, dass Vibe Coding nicht nur ein technisches Konzept, sondern auch ein bedeutendes arbeitsmarktpolitisches Phänomen darstellt.
Einsatz von KI
Entwickler:innen nutzen KI heute überwiegend reflexiv, wie die DORA-Studie zeigt [8]: Rund 90 % der befragten Tech-Professionals nutzen KI im Arbeitsalltag, über 80 % sehen Produktivitätsgewinne, aber etwa 30 % vertrauen KI-Code wenig. Zudem verzichten 61 % auf autonome KI-Agenten, die Aufgaben selbstständig ausführen können. Dies deutet darauf hin, dass Vibe Coding zwar in der Breite angekommen ist, jedoch bislang kaum als vollautonomer Entwicklungsstil akzeptiert wird. Der Mensch bleibt somit eine zentrale Instanz im Entwicklungsprozess.
LLM-Benchmarks
LLM-Benchmarks machen die Leistungsfähigkeit großer Sprachmodelle vergleichbar, prüfen etwa die CodeGenerierung, sind aber meist auf isolierte Aufgaben beschränkt.
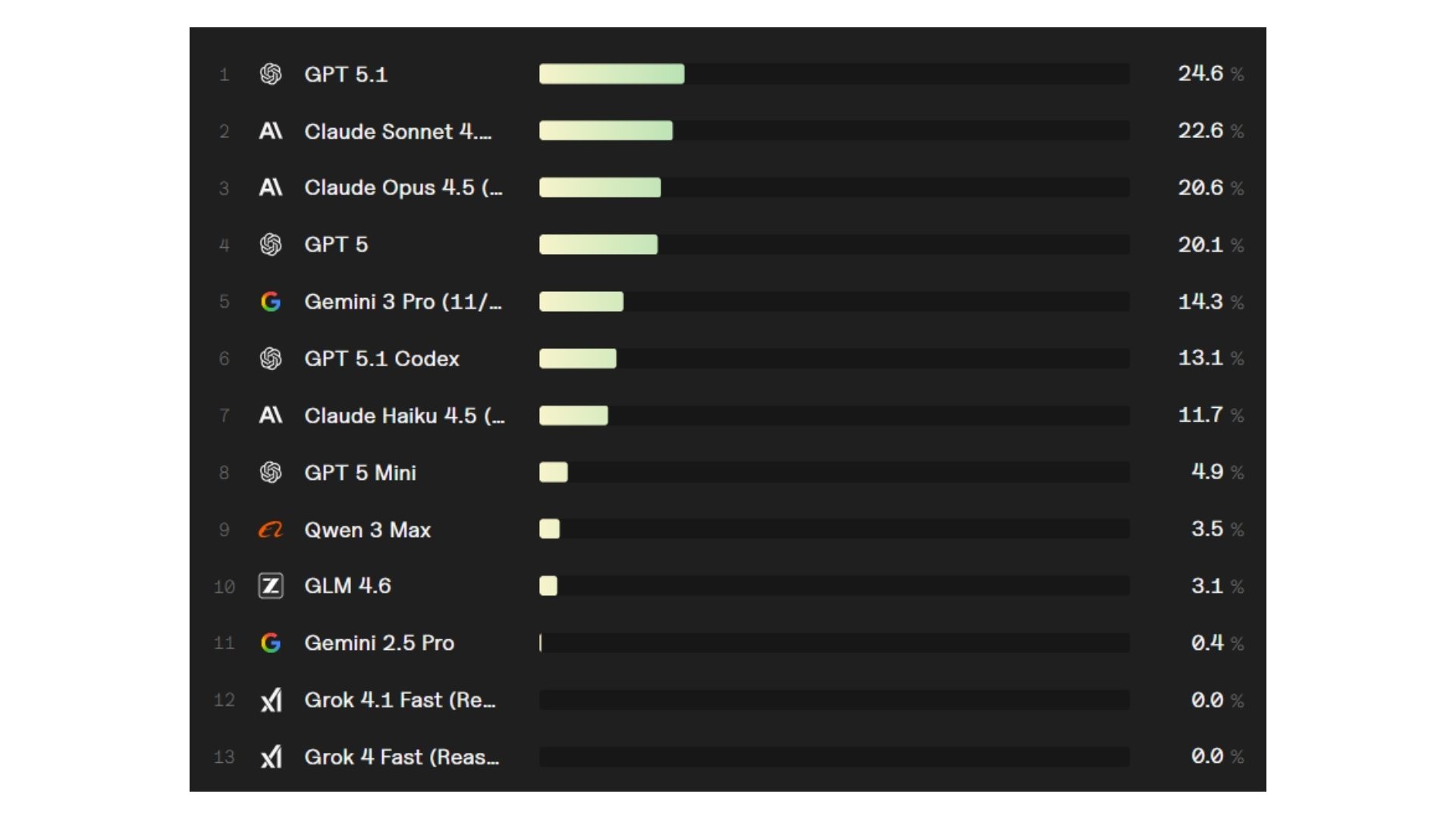
Ein neuartiger Ansatz ist der Vibe-Coding Benchmark von ValsAI. Er bewertet, wie gut Modelle vollständige Webanwendungen aus einer einseitigen, natürlichsprachlichen Beschreibung erstellen [9]. Modelle arbeiten dabei in Docker-Containern mit Zugriff auf weitere Tools, und die Umsetzung wird anhand von 20–60 automatisierten Tests geprüft, die Kernfunktionen, Edge Cases und User-Flows abdecken. Maßgeblich ist der Anteil bestandener Kern-Workflows als Leistungsindikator.
In folgender Abbildung sind die Ergebnisse des Benchmarks dargestellt
Anwendungsfälle
Es gibt insbesondere drei sinnvolle Anwendungsbereiche für Vibe Coding [6]:
- Rapid Prototyping & MVP-Entwicklung:
Studien berichten von einer 60–80 % kürzeren Entwicklungszeit im Vergleich zum klassischen Coding. - Repetitive Aufgaben und Boilerplate:
Es zeigt sich eine hohe Effizienz in der Generierung von UI-Gerüsten oder API-Strukturen sowie Unit-Test Generierung und der Dokumentation von Systemen. - Kreative Exploration:
Durch Vibe Coding werden technische Hürden reduziert und Entwickler:innen bleiben länger im Flow des Entwickelns und Ausprobierens. Der Ansatz eignet sich besonders für explorative und strukturell einfache Szenarien.
Praktische Analyse des Vibe-Coding-Prozesses mit Fokus auf Softwarequalität
Der praktische Teil der Untersuchung analysiert die Entwicklung eines Content-Gen-Microservices innerhalb der Lernplattform Studyfai mit besonderem Fokus auf die resultierende Softwarequalität. Der Microservice übernimmt die Extraktion und Transformation von PDF-Dokumenten, die Generierung von Quizfragen in unterschiedlichen Schwierigkeitsstufen sowie die Erstellung von H5P-Quizformate zur Integration in ein bestehendes Microfrontend-Ökosystem.
Auf Systemebene ist der Service in eine mehrstufige Prozesskette eingebettet: Textdaten werden zunächst durch einen Kurs-Service in einzelnen PDF-Ressourcen überführt, anschließend in H5P-Quizformate konvertiert und schließlich einem Quiz-Service zur Verfügung gestellt. Die Architektur umfasst ein Next.js-basiertes Microfrontend mit React und TailwindCSS sowie einen containerisierten Backend-Service, der über eine API mit einem Sprachmodell interagiert und die H5P-Generierung übernimmt.
Ausgangslage, Setup und Rolle der KI
Zu Projektbeginn existierte weder eine bestehende Implementierung noch eine vorgegebene Architektur. Funktionale Anforderungen und Systemkontext wurden im Rahmen des Hochschulkurses AI Driven Software Development an der Hochschule der Medien Stuttgart erarbeitet. Zur Präzisierung der Feature-Beschreibung, zur Identifikation technischer Rahmenbedingungen sowie zur Skizzierung eines initialen Architekturentwurfs wurden große Sprachmodelle genutzt.
Die Implementierung des Content-Gen-Services erfolgte anschließend nahezu vollständig mit GPT-5.1 unter aktivierter Reasoning-/Thinking-Konfiguration. OpenAI beschreibt GPT-5.1 als Modell für Coding-Aufgaben mit konfigurierbarem Reasoning-Effort, wodurch sich die Tiefe der schrittweisen Herleitung steuern lässt [10] [11]. Ergänzend wird GPT-5.1 Thinking als Variante beschrieben, die ihre Denkzeit adaptiver auf komplexere Aufgaben ausrichtet. Im Versuch wurde bewusst auf externe Tools, Retrieval-Mechanismen und autonome Agenten verzichtet, um ein kontrolliertes Vibe-Coding-Szenario zu erzeugen, in dem das Modell ausschließlich auf Basis natürlichsprachlicher Spezifikationen und fortlaufend zurückgespielter Fehlermeldungen agiert.
Diese Einordnung ist auch deshalb relevant, weil Vibe-Coding-spezifische Benchmarks zeigen, dass selbst leistungsfähige Modelle bei komplexen End-to-End-Aufgaben nur begrenzte Autonomie erreichen. Im Vibe Code Bench von ValsAI schnitt zudem GPT-5.1 als das am besten bewertete Modell ab (siehe Abbildung 2) [9].
Während der Implementierungsphase wurde die menschliche Rolle bewusst reduziert. GPT-5.1 generierte Code und leitete Korrekturen anhand von Compiler-, Build- und Runtime-Fehlermeldungen ab. Fehlermeldungen wurden nahezu ungefiltert in den Dialog zurückgespielt, und die Vorschläge wurden ohne systematisches manuelles Code-Review umgesetzt. Damit fungierte der Mensch primär als Ausführungsinstanz in der Entwicklungsumgebung, was den Einfluss des Vibe-Coding-Stils auf die entstehende Softwarequalität vergleichsweise direkt beobachtbar machte.
Entwicklungsprozess, Prompt-Strategien und Vibe-Coding-Fluss
Der Entwicklungsprozess begann mit einem promptbasierten Architekturentwurf. In mehreren Iterationen wurde ein strukturierter One-Shot-Prompt entwickelt, der Rolle, Projektziel, Systemumgebung sowie grundlegende Qualitäts- und Architekturvorgaben festlegte. Ziel war eine konsistente Gesamtarchitektur, die über einzelne Codefragmente hinaus tragfähig bleibt und die Gefahr lokaler, aber strukturell inkonsistenter Lösungen reduziert.
Im weiteren Verlauf kamen drei Prompt-Typen zum Einsatz:
- High-Level-One-Shot-Prompts zur Initialisierung größerer Arbeitspakete (z. B. Backend-Grundstruktur, API-Routen, Modellanbindung).
- Iterative Debug-Prompts, in die Fehlermeldungen aus Build- und Runtime-Prozessen eingespeist wurden, um konkrete Reparaturvorschläge zu erhalten.
- Self-Refactoring-Prompts zur Konsolidierung nach mehreren Iterationen (Entfernung redundanter Dateien, Vereinheitlichung von Namenskonventionen, Extraktion wiederkehrender Logik).
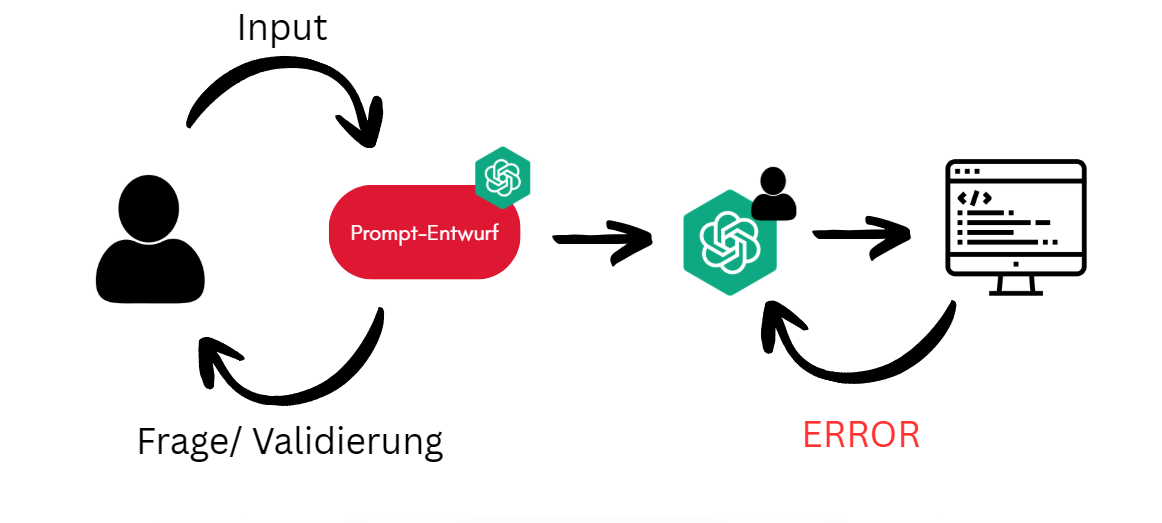
Der zugehörige Vibe-Coding-Fluss ist in Abbildung 2 dargestellt. Die Abbildung modelliert zwei gekoppelte Rückkopplungsschleifen:
- LLM-assisted Prompt Refinement: Schleife aus Input, Prompt-Entwurf und Frage/Validierung zur One-Shot Prompt Generierung
- Schleife aus Codegenerierung, Ausführung und Fehler-Rückkopplung
Im Versuch dominierte in der Implementierungsphase die zweite Schleife: Fehlermeldungen dienten als unmittelbare Steuerimpulse, die das Modell in Codeänderungen übersetzte. Diese Struktur ist fachlich relevant, weil sie erklärt, warum Vibe Coding in standardisierten Tasks schnell zu lauffähigem Code führt, bei architekturbezogenen Konflikten jedoch Reparaturschleifen begünstigt: Das Modell optimiert kurzfristig gegen sichtbare Fehlerausgaben, ohne zwingend die systemische Ursache zu isolieren.
Fehlerbilder und Auswirkungen auf die Softwarequalität
Im Verlauf mehrerer intensiver Arbeitssitzungen traten wiederkehrende Fehlermuster auf, die sich auf mehrere Qualitätsdimensionen auswirkten. Besonders relevant waren Architekturinkompatibilitäten, rekursive Fehlerketten sowie typische LLM-Artefakte in der Codebasis.
Ein zentrales Fehlerbild betraf Inkompatibilitäten zwischen Framework-Versionen, Webpack-Konfiguration und Module Federation. Das Modell reagierte auf Fehlermeldungen mit lokalen Reparaturvorschlägen, ohne den zugrunde liegenden Versionskonflikt konsistent zu identifizieren. Dies führte zu einer schrittweisen Fragmentierung der Projektstruktur (zusätzliche Konfigurationsdateien, alternative Build-Skripte), wodurch sich die Wartbarkeit und die Stabilität des Build-Prozesses verschlechterten.
Ein weiteres Muster waren rekursive Fehlerketten: Folgefehler wurden häufig als unabhängige Probleme behandelt, wodurch Reparaturschleifen entstanden. Begleitend zeigten sich LLM-Artefakte wie wenig aussagekräftige Variablennamen, unnötige Verschachtelungen und redundante Utility-Funktionen. Diese Artefakte sind funktional nicht zwingend kritisch, erhöhen aber die kognitive Komplexität und damit die spätere Änderbarkeit, Fehlersuche und Erweiterbarkeit.
Produktive Effekte im Qualitätskontext
Trotz dieser Einschränkungen zeigte sich ein deutlicher Produktivitätsgewinn bei standardisierten Entwicklungsaufgaben. Das Aufsetzen von API-Routen, die Anbindung externer Schnittstellen sowie das Erzeugen struktureller Grundgerüste erfolgte mit hoher Geschwindigkeit. In der Kernfunktionalität wurde die Pipeline von PDF-Extraktion über Quizgenerierung bis zur H5P-Erstellung in kurzer Zeit umgesetzt. Darüber hinaus wurde durch Containerisierung und klar definierte API-Kontrakte eine prinzipiell portable Integrationsstruktur erreicht, die die Einbettung in die bestehende Plattform erleichtert.
ISO/IEC 25010: Qualitätsmerkmale, Metriklogik und Begründung der Operationalisierung
Zur Strukturierung der Qualitätsbewertung wurde ISO/IEC 25010 als Referenzmodell herangezogen [12]. Der Standard definiert Qualitätsmerkmale und Submerkmale für Softwareprodukte, stellt jedoch kein fixes Metrik-Set bereit; Messverfahren müssen projektspezifisch operationalisiert und empirisch abgesichert werden. Genau daraus ergibt sich die methodische Kernlogik dieses Kapitels: Die nachfolgend berichteten Kennzahlen sind als ISO-orientierte Operationalisierung zu lesen, deren Aussagekraft unmittelbar von Messabdeckung, Datenqualität und Validierungsgrad abhängt.
Die Implementierung der Metriken und die Berechnung der Scores wurden im Projekt nicht manuell entwickelt, sondern durch Claude Sonnet 4.5 im Agentenmodus implementieren lassen [13].
Sonnet 4.5 wird von Anthropic explizit als Modell für „real-world agents“ und Coding positioniert, inklusive Workflows, bei denen das Modell Aufgaben schrittweise ausführt und Artefakte erstellt. Diese Entscheidung erhöhte die Umsetzungsgeschwindigkeit der Metrikpipeline, verschärft jedoch ein Bewertungsproblem: Die Qualitätsbewertung wird damit von einem generativen System operationalisiert, das weder eine formale Messtheorie noch eine projektexterne Ground-Truth besitzt. Das betrifft insbesondere die Konstruktvalidität, die Nachvollziehbarkeit und die Reproduzierbarkeit. In der Folge sind die Scores eher als strukturierende Heuristik zu interpretieren, nicht als belastbarer Qualitätsnachweis im Sinne klassischer Software-Qualitätssicherung. ISO-Qualitätsmerkmale nach ISO/IEC 25010:2024 sind [12]:
Functional Suitability: Grad, in dem Funktionen festgelegte Bedürfnisse erfüllen; operationalisiert über Requirements-Coverage sowie Defekt- und Fehlerindikatoren.
Performance Efficiency Leistung im Verhältnis zu eingesetzten Ressourcen; operationalisiert über Antwortzeiten, Durchsatz und Ressourcennutzung unter Last.
Compatibility: Fähigkeit zur Koexistenz und Interoperabilität; operationalisiert über Interoperabilitätsfehler, Plattformunterstützung und API-Konformität.
Usability: Effektive, effiziente und zufriedenstellende Nutzung durch definierte Nutzer; operationalisiert über Nutzerbeobachtung, Task-Erfolgsmaße und Fehlerraten, daher ohne User-Testing nicht belastbar.
Reliability: Fähigkeit, Leistung unter definierten Bedingungen aufrechtzuerhalten; operationalisiert über Verfügbarkeit, Fehlerraten und Wiederherstellbarkeit.
Security: Schutz von Informationen und Daten; operationalisiert über Indikatoren zu Vertraulichkeit, Integrität und Autorisierung.
Maintainability: Effektive und effiziente Modifizierbarkeit; operationalisiert über Komplexität, Testbarkeit (Coverage), Duplikation, technische Schuld und Änderungsaufwand.Portability: Übertragbarkeit und Installierbarkeit in anderen Umgebungen; operationalisiert über Installations- und Portierungsindikatoren, Containerisierung als Proxy für portable Deploymentfähigkeit.
Ergebnis des praktischen Teils
| ISO/IEC 25010 Merkmal | Score | Kernergebnis (stark gekürzt) |
| Functional Suitability | 87.5/100 | 7/8 Anforderungen umgesetzt, 1 fehlt |
| Performance Efficiency | N/A | Keine Messung, RAM ~45 MB (Schätzung) |
| Compatibility | 100/100 | Keine Interop-Fehler, OpenAPI-konform |
| Usability | N/A | Kein User-Testing, Accessibility als Basis erfüllt |
| Reliability | 99.95/100 | Keine Ausfälle beobachtet, Availability-Proxy |
| Security | 75/100 | npm audit clean, Auth 3/4 Endpoints |
| Maintainability | 65/100 | 0% Tests, Komplexität ~8 |
| Portability | 95/100 | Docker-ready, Installation erfolgreich |
Gesamtfazit aus Qualitätsperspektive
Die empirische Analyse zeigt ein konsistentes Spannungsfeld zwischen Geschwindigkeit und struktureller Qualität. Vibe Coding mit GPT-5.1 ermöglichte eine schnelle Realisierung großer Teile der Kernfunktionalität und beschleunigte standardisierte Implementierungsaufgaben. Gleichzeitig führten architekturbezogene Konflikte zu rekursiven Debugging-Schleifen und struktureller Fragmentierung, was die Maintainability und die Stabilität der Entwicklungsartefakte negativ beeinflusste.
Die ISO-orientierte Metriktabelle macht darüber hinaus eine methodische Grenze sichtbar: Mehrere Kennzahlen wie Performance und Usability beruhen auf Schätzungen oder nicht erhobenen Messreihen beziehungsweise auf fehlender Testabdeckung. Dadurch sind insbesondere Reliability- und Security-Aussagen nur eingeschränkt belastbar. Hinzu kommt, dass die Metriken durch Claude Sonnet 4.5 im Agentenmodus implementiert wurden, was den Score zusätzlich als artefaktabhängig kennzeichnet. Ohne unabhängige, reproduzierbare Implementierung und ohne empirische Datengrundlage (Tests, Monitoring, Lastmessungen, Nutzerstudien) strukturiert das System die Bewertung formal, kann aber objektive Qualität nur imitieren, nicht nachweisen. Diese Konstellation begünstigt eine Qualitätsillusion, wenn aggregierte Scores als Qualitätsbeleg interpretiert werden, obwohl die Messbasis die ISO-Merkmale nicht hinreichend trägt.
Systemische Auswirkungen von Vibecoding
Nach der Betrachtung des praktischen Fallbeispiels erfolgt nun die analytische Einordnung und Synthese der gewonnenen Erkenntnisse. Dabei wird der Fokus auf die meta-systemischen Auswirkungen erweitert. Es sollen Grenzen der Methodik, die ökonomischen Realitäten der Team-Performance sowie der Wandel in den Kompetenzprofile und Arbeitsprozesse des Software Development Life Cycle (SDLC) aufgezeigt werden.
Risiken und Grenzen
Wie bereits dargestellt, kann Vibecoding eine schnelle Umsetzung von Funktionalitäten ermöglichen. Jedoch wurde auch aufgezeigt, dass gerade diese Geschwindigkeit dazu verleitet, fundamentale Prinzipien der Softwarearchitektur und Sicherheit zu vernachlässigen. Daraus resultieren klare Grenzen, jenseits derer der Einsatz dieser Methodik nicht nur ineffizient, sondern risikobehaftet ist.
Der primäre Ausschlussbereich für Vibecoding liegt in Systemkomponenten, die Sicherheit und strikte Datenintegrität erfordern. Insbesondere Module, die finanzielle Transaktionen verarbeiten (Payment-Gateways, Billing-APIs) oder sensible personenbezogene Daten verwalten, sollten unter keinen Umständen ungeprüft auf Code-Generierung eines LLMs basieren. Die Tendenz von LLMs, funktionierenden, aber unsicheren Code zu erzeugen ist ein bekanntes Problem [14].
Diese Diskrepanz zeigt sich in der Praxis oft durch fehlende Eingabevalidierungen oder unzureichende Authentifizierungsmechanismen. Berichte über “gevibecodete” SaaS-Lösungen, bei denen Endnutzer durch triviale Manipulationen Datenbankeinträge verändern oder Paywalls umgehen konnten, unterstreichen die Gefahr von Business Logic Flaws, die durch das blinde Kopieren von generiertem Programmcode entstehen [15].
Zudem neigen KI-Modelle dazu, Sicherheitslücken durch Halluzinationen aktiv einzuführen, etwa durch den Import existierender, aber für den Kontext falscher Packages, oder durch Referenzieren von Phantom-Libraries [6].
Ein weiterer kritischer Aspekt betrifft die Skalierbarkeit unter Last. Der generierte Code ist oft nicht für den parallelen Zugriff durch eine große Nutzerbasis optimiert. Typische Defizite sind ineffiziente Datenbankabfragen oder fehlende Caching-Strategien, die in einer lokalen Entwicklungsumgebung unbemerkt bleiben. Sobald die Nutzerzahlen steigen, führt dies schnell zu hohen Performance-Einbrüchen, weshalb sich Vibecoding kaum für High-Traffic-Anwendungen eignet [6].
Vibecoding stößt auch dort an seine Grenzen, wo der Globale Scope einer Architektur das Kontextfenster des Modells übersteigt. In Deep-Legacy Projekten oder großen Multi-File-Kontexten braucht es zum heutigen Stand eine menschliche Mitarbeit, um die Abhängigkeiten und impliziten Architekturregeln als Kontext mit zu übergeben. Hier zeigt sich die klare Unterscheidung des Vibecoding zum Agentic Coding. Während Vibecoding primär als “Token-Chat” operiert, der nur Text-Ausschnitte verarbeitet und auf menschliches Copy-Paste angewiesen ist, interagieren Agenten-Systeme direkt mit der Umgebung und können so tiefere Abhängigkeiten in der gesamten Codebasis auch allein nachvollziehen [16].
Zusammenfassend lässt sich sagen, dass sobald die Kosten eines Fehlers (monetär, datenschutzrechtlich, performance-seitig) die Kosten der manuellen Entwicklung übersteigen, Vibecoding als alleinige Methode nicht zu empfehlen ist.
Team Performance
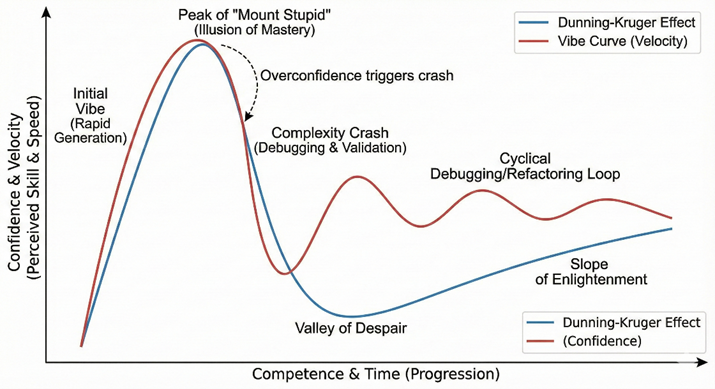
Die zentrale ökonomische Abwägung bei der Integration von KI-gestützten Entwicklungsprozessen ist das Verhältnis zwischen der Netto-Zeitersparnis durch initiale Code-Generierung und dem Brutto-Zeitverlust, der durch nachgelagertes Debugging und Refactoring entsteht. Unser Fallbeispiel verdeutlicht, dass die Performance beim Vibecoding nicht linear skaliert. Vielmehr folgt sie einem spezifischen Muster, das wir als “Vibe-Kurve” definieren.
Diese Kurve weist Ähnlichkeiten zum Verlauf des Dunning-Kruger-Effekts auf. Dies erscheint schlüssig, da aktuelle Untersuchungen nahelegen, dass LLMs selbst diesem Phänomen unterliegen. Sie tendieren dazu, ihre Kompetenz in komplexen Domänen zu überschätzen und liefern plausible, aber fehlerhafte Lösungen mit hoher Zuversicht [17] [18].
Im praktischen Verlauf äußerte sich dies zyklisch. Zu Beginn eines jeden Entwicklungsabschnitts war eine massive Beschleunigung messbar, getrieben durch die schnelle Generierung von Boilerplate-Code. Sobald die Anforderungen jedoch den generischen Bereich verließen und spezifische Expertise erforderten, kippte das Verhältnis. Der Aufwand für die Validierung und Korrektur subtiler Fehler, oft erschwert durch das Verstehen von fremden Code, führte zu einem rapiden Einbruch der Entwicklungsgeschwindigkeit. Zwar stieg die Produktivität nach jeder Fehlerbehebung wieder an, jedoch mit einer deutlich flacheren Steigung als in der Initialphase. Mit jedem neuen Arbeitsschritt begann dieser Zyklus von rapider Beschleunigung und anschließendem Einbruch von Neuem.
Grundlegend lässt sich trotzdem sagen, dass die Erstellung des Backends sowie des Frontends für unseren Service mit jeweils lediglich circa 2,5 Stunden deutlich schneller als üblich war. Im Vergleich zur manuellen Implementierung, die basierend auf Erfahrungswerten jeweils etwa einen Arbeitstag (8 Stunden) in Anspruch genommen hätte, entspricht dies einer
Effizienzsteigerung um den Faktor 3. Diese Datenpunkte bestätigen, dass Vibecoding besonders in der “Greenfield-Phase”, also beim Aufsetzen neuer Strukturen ohne Altlasten, deutliche Produktivitätsvorteile bieten kann.
Gefahr der kognitiven Passivität
Neben der reinen zeitlichen Ersparnis müssen weitere Faktoren für eine Analyse des langfristigen ökonomischen Nutzen beachtet werden. Ein oft unterschätztes Risiko des Vibecodings ist psychologischer Natur, die sogenannte kognitive Passivität. Diese Entkopplung von Denken und Tun führt dazu, dass das tiefere Verständnis für den eigenen Code verschwindet und das kritische Denken abnimmt [19]. Dies kann zu weitreichenden Folgen für Entwickler, ihre Projekte, Unternehmen oder bei Bildungseinrichtungen in der Lehre führen.
Ökonomisch gesehen führt das Verstehen des eigenen Codes zu einem erschwerten Wissenstransfer und kostenintensiverer Wartbarkeit. Zukünftige Teams können den KI-generierten Code schwerer nachvollziehen, ohne die Logik hinter dem ursprünglichen Prompt zu kennen. Hier ist das Stichwort „technical debt“, was ein Verschieben von Problemen technischer Natur zu Gunsten von der schnellen Entwicklung neuer Funktionen beschreibt.
Wie Untersuchungen des Fraunhofer IESE zeigen, führen lokale Produktivitätsgewinne durch KI nicht automatisch zu besseren Ergebnissen auf Systemebene. Im Gegenteil, wenn die Geschwindigkeit der Code-Produktion die Kapazität zur Qualitätssicherung übersteigt, summiert sich technische Schulden schneller, als sie abgebaut werden können. Vibecoding optimiert den individuellen Output, kann aber die langfristige Stabilität des Gesamtprojekts riskieren [20].
Besonders kritisch zeigt sich dieser Effekt auch für den Lernprozess beim Programmieren. Das mentale Modellieren von Datenflüssen und das Verstehen von Fehlermeldungen sind essenzielle Bestandteile des Kompetenzerwerbs. Vibecoding kürzt diesen Prozess ab. Für Lernende entsteht so eine gefährliche Illusion von Kompetenz. Sie können komplexe Ergebnisse produzieren, ohne die fundamentalen Bausteine verstanden zu haben [19].
Langfristig könnte eine Konsequenz ein Mangel an Senior-Entwickler sein, die in der Lage sind, komplexe Systeme ohne KI-Hilfe zu debuggen oder aufzusetzen. Methoden wie Pair Programming, Verknappung von Eingabetoken oder Konzentration auf Architekturwissen können Gegenmaßnahmen in Bildungseinrichtungen und Unternehmen darstellen.
Skill Shift und Auswirkungen auf den SDLC
Wie beschrieben stellt die Nutzung von Vibecoding Entwickler vor eine Transformation ihrer Kompetenzen. Allgemein lässt sich sagen, dass das handwerkliche Schreiben von Code sich eher hin zur Orchestrierung generativer Prozesse entwickelt.
Es wird zunehmend wichtiger werden, KI-Outputs selektiv zu filtern und in eine übergeordnete Systemarchitektur integrieren zu können. Diese neue Rolle erfordert eine gesteigerte Abstraktionsfähigkeit und ein gutes Systemverständnis, da LLMs zwar lokale Logikbausteine liefern, jedoch häufig an der globalen Dateistruktur und dem architektonischen Kontext scheitern. Einer gesteigerten Bedeutung kommt dabei dem Requirements Engineering in Form von präzisem “Prompt Engineering” zu. Da Anforderung ohne menschliche Zwischeninterpretation direkt in Code übersetzt werden, gilt das Prinzip “Garbage In, Garbage Out” schärfer denn je [16].
Gleichzeitig birgt dieser Wandel das Risiko des “De-Skillings”, insbesondere bei Einsteigern. Während das Auswendiglernen von Syntax und Standard-Bibliotheken an Relevanz verliert, wird die Fähigkeit zur kritischen Intervention, quasi ein “Anti-Vibe-Skill”, zur Kernkompetenz. Entwickler sollten in der Lage sein, die oft trügerisch souveränen Lösungen der KI durch technisches Verständnis zu hinterfragen und subtile Logikfehler, sowie endlos-Fehlerschleifen zu identifizieren. Fehlt dieses Fundament, warnt der aktuelle DORA-Report (2025) vor einer Generation von Entwicklern, die zwar Features generieren können, bei Low-Level-Problemen oder notwendigen Refactorings jedoch handlungsunfähig bleiben [8].
Die Beschleunigung in der Implementierung durch Vibecoding führt zu einer signifikanten Verschiebung des traditionellen Flaschenhalses im Software Development Life Cycle (SDLC).
Der Druck verlagert sich “nach links” in das Requirements Engineering und noch viel mehr “nach rechts” in die Qualitätssicherung. Da die Implementierung kaum noch Zeit beansprucht, werden unpräzise Anforderungen nun sehr schnell in fehlerhafte Software umgesetzt, was manuelle QA-Prozesse durch die schiere Masse an generierten Features überfluten könnte. Dies erzwingt eine Neuausrichtung der Test- und Qualitätsstrategien, inklusive erarbeiten von so genannten „Leitplanken“. Unser Projekt bestätigte diese Dynamik, da die hohe Prototyping-Geschwindigkeit uns zwang, Schnittstellendefinitionen weit früher als in klassischen Vorgehensmodellen finalisieren zu müssen.
Organisatorisch wirkt KI hierbei als Verstärker. Auf einer soliden Basis aus klarer Governance und Architektur skaliert sie Geschwindigkeit und Qualität. Fehlen diese Strukturen jedoch, multiplizieren sie lediglich technische Schulden und instabile Releases [8].
Um Problemen wie Scope Creep, begünstigt durch die schnelle Generierung neuer Funktionen, entgegenzuwirken, wird diszipliniertes Projektmanagement unverzichtbar. Ohne formale Steuerung und menschliches Refactoring droht der initiale Geschwindigkeitsvorteil langfristig durch steigende Integrationskomplexität und die „Zinsen“ der technischen Schulden neutralisiert zu werden.
Ausblick und Fazit
Diese Arbeit untersuchte die Potenziale von AI Aided Vibecoding in der Implementierungsphase des Software Development Life Cycle (SDLC). Ziel war es, am praktischen Beispiel eines Microservices zu evaluieren, inwieweit die direkte Interaktion mit State-of-the-Art LLMs (hier primär ChatGPT 5) klassische Entwicklungsmethoden substituieren oder ergänzen kann.
Das gewählte Vorgehen eines „Sparrings“, bei dem die Anforderungen über eine KI in Code übersetzt, testet und iterativ verfeinert, lieferte dabei ambivalente Ergebnisse.
Hinsichtlich der reinen Entwicklungsgeschwindigkeit wurde das Ziel übertroffen. Mit einer Implementierungszeit von einem Tag gegenüber einer geschätzten manuellen Dauer von mindestens zwei bis drei Personentag konnte eine signifikante Effizienzsteigerung nachgewiesen werden.
Dieser quantitative Erfolg steht jedoch einer gemischten qualitativen Bilanz gegenüber. Zwar wurden die funktionalen Anforderungen erfüllt, doch zeigten sich bei der Betrachtung von ISO-Qualitätsmetriken Defizite in den Bereichen Wartbarkeit und Testabdeckung.
Es wurde deutlich, dass Vibecoding ohne menschliches Korrektiv schnell an seine Grenzen stoßen kann. Das mangelnde tiefe Verständnis des generierten Codes seitens der Entwickler steigert zudem die Gefahr der kognitiven Passivität und der langfristigen Kosten bei Wartung und Sicherheit.
Als geeignetes Einsatzgebiet für Vibecoding kristallisiert sich daher das Rapid Prototyping und die “Greenfield”-Entwicklung heraus. Hier hilft die Methode effektiv, das “Problem des weißen Blattes” zu überwinden und Entwickler schnell in einen produktiven Flow State zu versetzen.
Für High Stake-Projekte hingegen – Systeme, die sensible Daten verarbeiten, finanzielle Transaktionen steuern oder kritische Infrastrukturen bilden – ist der alleinige Einsatz von Vibecoding derzeit als fahrlässig einzustufen.
Die Risiken durch Halluzinationen und ungeprüften Fremdcode erfordern zwingend, dass “Viben” untrennbar mit “Reviewen” verbunden bleibt. Damit sich Vibecoding von einem reinen Prototyping-Tool zu einem verlässlichen Instrument für den Enterprise-Einsatz entwickelt, bedarf es neuer technologischer Indikatoren und Werkzeuge.
Um die Diskrepanz zwischen Generierungsgeschwindigkeit und Qualitätssicherung zu schließen, könnten Self-Healing CI/CD Pipelines an Bedeutung gewinnen, in denen die KI nicht nur committed, sondern Fehler anhand von Testergebnissen autonom analysiert und korrigiert.
Ein wichtiger Schritt könnte zudem die Abkehr vom reinen Text-Kontext hin zu Graph-Based Contexts sein. Zukünftige Tools müssen das gesamte Repository als Knowledge Graph, inklusive Abhängigkeiten und Datenflüssen, erfassen, um die heute noch häufigen Logikbrüche bei komplexen Architekturen zu vermeiden. Ergänzend hierzu könnte sich ein Test-Driven AI Development etablieren, bei dem der Mensch präzise Testfälle als Spezifikation liefert, gegen die die KI entwickelt. Möglicherweise unter Nutzung von Multi- Variant Generation, bei der das Modell mehrere Lösungswege simuliert und den performantesten auswählt.
Meinung
Die Zukunft der Softwareentwicklung liegt in hybriden Workflows. Vibecoding für das schnelle Finden von Ideen und Prototypisierung, gefolgt von Agentic Coding und menschlichem Engineering für Skalierung und Ausarbeitung.
Entwickler werden sich zunehmend auf die Integration von KI-Komponenten und die Pflege der “Human-Written Core Modules” spezialisieren.
Trotz aller Automatisierung bleibt die menschliche Urteilskraft die letzte Instanz – Oder um es mit Linus Torvalds Aussage zu zitieren: “AI is just another tool, the same way compilers free people from writing assembly code by hand, and increase productivity enormously but didn’t make programmers go away” (zitiert nach [21])
Entwickler werden sich nur, wie so oft in der Geschichte der Informatik, neu erfinden müssen – weg vom reinen Schreiben von Syntax, hin zum Architekten intelligenter Systeme.
References
[1] M. Stöckel, „Golem,“ 07 07 2025. [Online]. Available: https://www.golem.de/news/mit-ki-an-die-spitze-vibe-coder-ohne-coding-skills-dominiert-hackathons-2507-197813.html. [Zugriff am 08 12 2025].
[2] M. Faust, „Golem,“ 19 11 2025. [Online]. Available: https://www.golem.de/news/open-source-linus-torvalds-sieht-vibe-coding-positiv-2511-202381.html. [Zugriff am 08 12 2025].
[3] L. Cress, „BBC,“ 06 11 2025. [Online]. Available: https://www.bbc.com/news/articles/cpd2y053nleo. [Zugriff am 08 12 2025].
[4] A. Karpathy, „X,“ 03 02 2025. [Online]. Available: https://x.com/karpathy/status/1886192184808149383?lang=de. [Zugriff am 08 12 2025].
[5] E. Hutchins, Cognition in the Wild, London, England: The MIT Press, 1995.
[6] N. Hemdev, „Vibe Coding: A Mixed-Methods Case Study on Conversational AI Programming and Application Development,“ International Journal on Science and Technology (IJSAT), Bd. 3, Nr. 16, pp. 1-19, 2025.
[7] V. M. Heyming, „PwCs AI Jobs Barometer 2025: So verändert KI unsere Arbeitswelt,“ 17 06 2025. [Online]. Available: https://www.pwc.de/de/workforce-transformation/ai-jobs-barometer.html. [Zugriff am 12 08 2025].
[8] G. Cloud, „DORA,“ 2025. [Online]. Available: https://dora.dev/research/2025/dora-report/. [Zugriff am 08 12 2025].
[9] H. a. N. L. a. K. R. a. B. A. a. G. A. Tran, „Vibe Code Bench: Can AI Models Build Web Applications from Scratch?,“ Vals AI, 08 12 2025. [Online]. Available: https://www.vals.ai/benchmarks/vibe-code. [Zugriff am 08 12 2025].
[10] OpenAI, „OpenAI API Documentation – GPT-5.1 Model,“ OpenAI, [Online]. Available: https://platform.openai.com/docs/models/gpt-5.1. [Zugriff am 23 01 2026].
[11] OpenAI, „OpenAI API Documentation – Reasoning models,“ OpenAI, [Online]. Available: https://platform.openai.com/docs/guides/reasoning. [Zugriff am 23 01 2026].
[12] U. (. I. d. Normazione), „UNI CEI ISO/IEC 25010:2024 – Systems and software engineering – Systems and software Quality Requirements and Evaluation (SQuaRE) – Product quality model,“ UNI, 2024.
[13] Anthropic, „Introducing Claude Sonnet 4.5,“ 29 September 2025. [Online]. Available: https://www.anthropic.com/news/claude-sonnet-4-5. [Zugriff am 23 01 2026].
[14] S. Sharma, „When AI nukes your database. The dark side of vibe coding: CSO online,“ 9 September 2025. [Online]. Available: https://www.csoonline.com/article/4053635/when-ai-nukes-your-database-the-dark-side-of-vibe-coding.html. [Zugriff am 1 Januar 2026].
[15] Leojrr, „X,“ November 2025. [Online]. Available: https://x.com/leojrr/status/1900767509621674109. [Zugriff am 1 Januar 2026].
[16] K. I. R. M. K. Ranjan Sapkota, „Vibe Coding vs. Agentic Coding: Fundamentals and Practical Implications,“ Cornell University, 2025.
[17] S. C. A. R. S. G. Mukul Singh, „Do Code Models Suffer from the Dunning-Kruger Effect?,“ arXiv, 2025.
[18] J. Rowe, „AI and the Illusion of Mastery: Software Engineering Skills in the Age of LLMs : James’ Thoughts,“ 28 Februar 2025. [Online]. Available: https://www.jsrowe.com/ai-and-the-illusion-of-mastery/. [Zugriff am 25 Januar 2026].
[19] M. T. Sqalli, „Eyes on the Code: Mapping Critical Thinking Through Eye-Tracking for StudentLLM Coding Interactions,“ Association for Computing Machinery, 2025.
[20] D. J. S. u. D. A. J. Patricia Kelbert, „KI in der Softwareentwicklung: Zwischen Produktivitätsschub und Vertrauenskrise – neue Erkenntnisse aus Forschung und Praxis: Fraunhofer IESE,“ 2 Oktober 2025. [Online]. Available: https://www.iese.fraunhofer.de/blog/ki-in-der-softwareentwicklung-neue-erkenntnisse-aus-forschung-und-praxis/. [Zugriff am 25 Januar 2026].
[21] M. Faust, „Golem,“ 19 11 2025. [Online]. Available: https://www.golem.de/news/open-source-linus-torvalds-sieht-vibe-coding-positiv-2511-202381.html. [Zugriff am 30 11 2025].
[22] A. T. K. B. Ahmed Fawzy, „Vibe Coding in Practice: Motivations, Challenges, and a Future Outlook — a Grey Literature Review,“ cs.SE, 2025.
[23] M. Horvat, „What is Vibe coding and when should you use it (or not)?,“ TechRxiv, 2025.
Leave a Reply
You must be logged in to post a comment.