
Im Rahmen der Vorlesung “Software Development for Cloud Computing” haben wir uns hinsichtlich des dortigen Semesterprojektes zum Ziel gesetzt einen einfachen Instagram Klon zu entwerfen um uns die Grundkenntnisse des Cloud Computings anzueignen.
Grundkonzeption / Ziele des Projektes
Da wir bereits einige Erfahrung mit React aufgrund anderer studentischer Projekte sammeln konnten, wollten wir unseren Fokus weniger auf die Funktionalität und das Frontend der Applikation richten und ein größeres Augenmerk auf die Cloud spezifischen Funktionen und Vorgehensweisen legen.
Konkret planten wir die Umsetzung eines Instagram Klons mit den grundlegenden Funktionalitäten:
- Bilder bzw. Beiträge hochladen
- Titel & Beschreibung von Beiträgen anlegen
- Liken von Beiträgen
- Kommentieren von Beiträgen
- Accountmanagement
Entwurfsentscheidung
Frontend
Aufgrund von bereits existierenden Vorkenntnissen und guter Erfahrungen entschieden wir uns für die Umsetzung des Frontends mit Hilfe des React Frameworks. Mit der Gestaltung als Web App ergibt sich zudem der Vorteil, dass “Ynstagram” Plattform übergreifend erreichbar ist.
Backend – von Firebase zu AWS

Zunächst starteten wir unser Projekt mit Firebase umzusetzen. Zum einen verlor dies jedoch seinen Reiz hinsichtlich des Lerneffekts, da wir parallel unser Softwareprojekt mit Firebase verwirklichten. Gleichzeitig wurde uns durch die Einblicke in den Vorlesungen ein Bewusstsein für den Funktionsumfang von AWS geschaffen.
Interessant war für uns hierbei beispielsweise die wesentlich umfangreicheren Einsatzmöglichkeiten von Lambda Funktionen. Während diese in Firebase nur durch Einträge / Trigger geschehen kann, konnten wir hier auf API Aufrufe zurückgreifen. Auch die umsetzbaren Funktionalitäten gestalteten sich als wesentlich umfangreicher. So bot sich uns unter anderem die Möglichkeit Bilder beim Upload automatisiert zu skalieren und perspektivisch ließe sich auch recht einfach eine Analyse von Inhalten mit Hilfe von Künstlicher Intelligenz umsetzen. Während man bei Firebase in all dem schnell an gewisse Grenzen kommt, gibt es bei AWS einen viel breiteren Horizont an Möglichkeiten.
Dennoch gestaltete sich dieser Umstieg keineswegs als einfach, denn Firebase bietet eine wesentlich bessere Übersichtlichkeit und Dokumentation.
Serverless
Da uns die AWS Web Oberfläche und die Online Erstellung von Lambda Funktionen keineswegs ansprachen suchten wir nach Lösungen um alle Konfigurationen wenn möglich auch auf Github hinterlegt zu haben und im Code Editor anlegen zu können.
Dabei sind wir letztlich auf Serverless gestoßen. Hier werden alle Buckets, Tabellen und API Aufrufe über ein serverless.yaml File verwaltet. So lassen sich neue Elemente viel übersichtlicher / schneller anlegen und Konfigurationen können einfach von bereits erstellten Elementen übernommen werden.
Postman
Um einen Überblick über die erstellten API Routen zu behalten und um diese einfach testen zu können, haben wir uns für Postman entschieden. Über ein in Github geteiltes File können so alle am Projekt beteiligten die aktuellen API Routen sehen und neue Aufrufe anlegen.
Umsetzung / Architektur
AWS Services
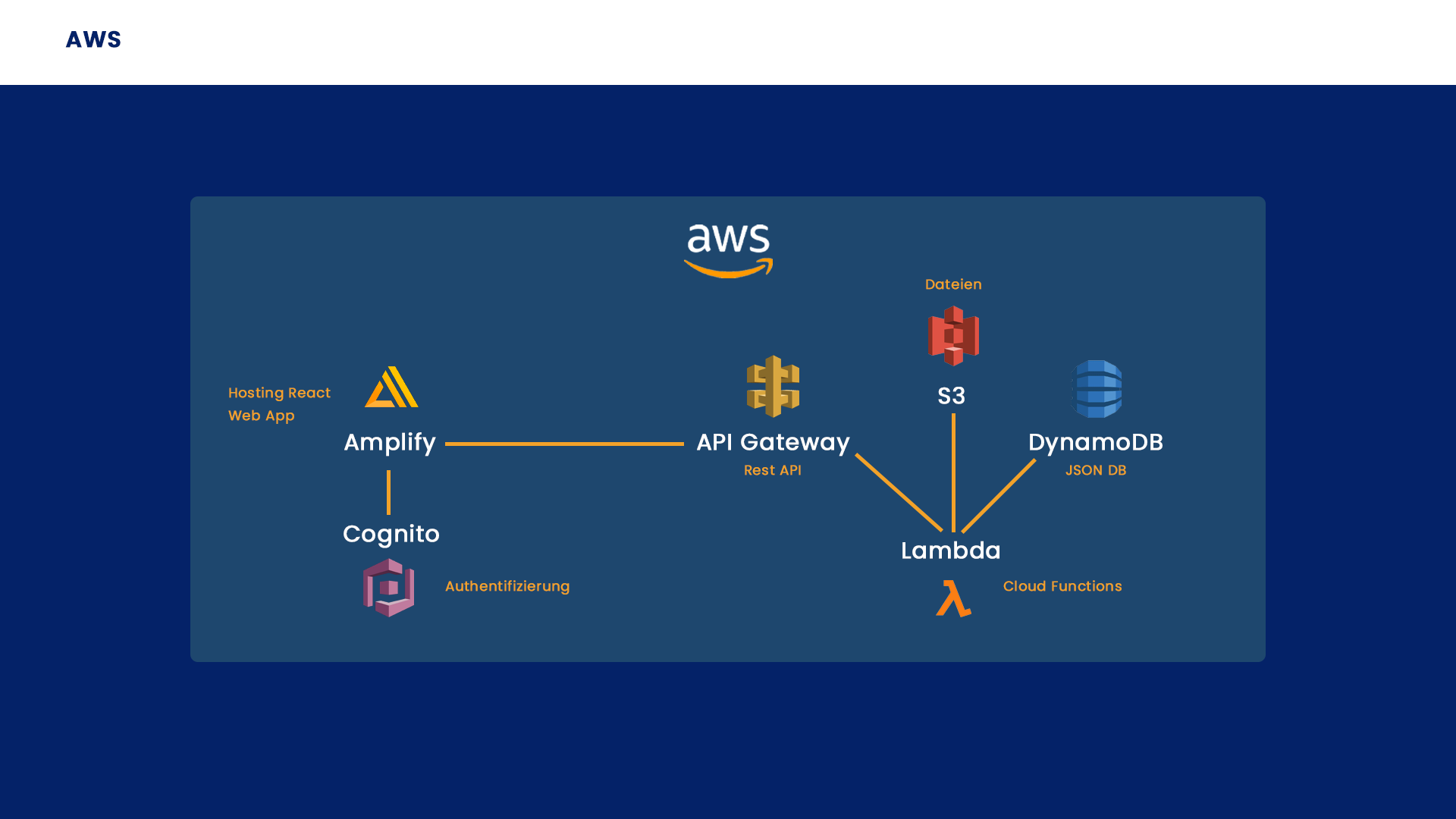
DynamoDB
Da wir bereits in Firebase auf die dortige NoSQL Datenbank “Firestore Database” zurückgegriffen hatten, entschieden wir uns hier für eine Beibehaltung dieser Datenbankstruktur. Der Vorteil liegt dabei gegenüber SQL Datenbanken in einfacheren Abfragen bedingt durch eine flachere Datenstruktur.
Wir verwenden DynamoDB Tabellen um die zu den Bildern gehörenden Informationen wie z.B. Titel, Beschreibung, Autor etc. zu speichern. Die Verknüpfung der Bilder mit den Datensätzen in den Tabellen erfolgt dabei durch eine einzigartige ID.
Es gibt dabei 2 Tabellen, eine in der zunächst die Eingaben gespeichert werden, und eine weitere in die verarbeitete Datensätze übertragen werden.
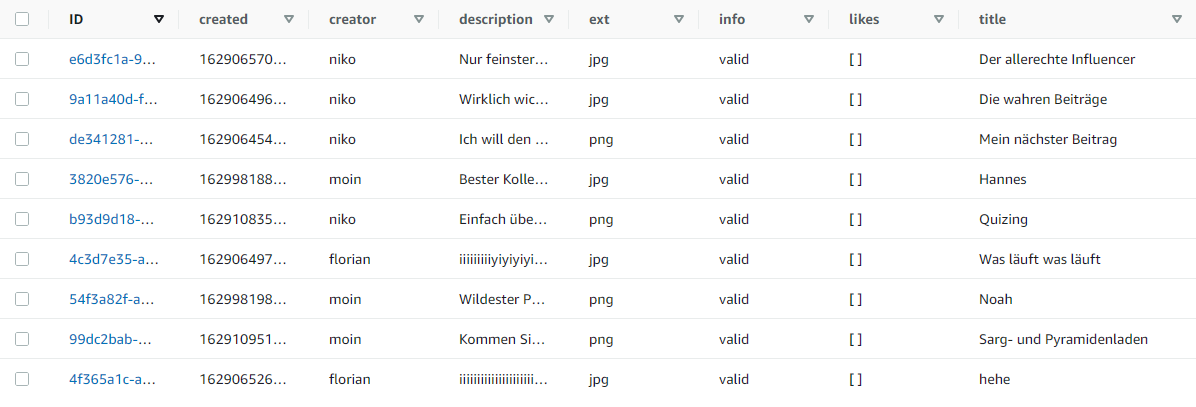
Beide Tabellen sind dabei strukturell gleich aufgebaut. Zentral sind hier eine eindeutige ID, Datum der Erstellung, Account Name des Erstellers, sowie Beschreibung und Titel des Beitrags. Kommentare und Likes werden über Arrays verwaltet.
S3
In S3 Buckets sind die zu den Beiträgen hinterlegten Bilder gespeichert. Dabei gibt es einen Bucket mit den Originaldateien, sowie einen mit verringerter Auflösung. Der Name der Bilder entspricht dabei stets der den Beiträgen zugehörigen einzigartigen ID.
Cognito
Mit AWS Cognito konnten wir in wenigen Schritten unser Account Management einrichten. Cognito bietet dabei die Unterstützung aktueller Identitäts und Zugriffsmanagement Standards wie zB. Oauth 2.0 und SAML 2.0 und bietet gleichzeitig auch die Möglichkeit Multifaktor Authentifizierung zu implementieren.
Amplify
Wir nutzen AWS Amplify um das Frontend unserer Applikation zu hosten und um hierfür eine CI/CD Pipeline mit Development und Master Umgebung zu realisieren. Eine genauere Erklärung hierzu findet sich im Abschnitt “CI/CD Pipeline”.
Lambda
API Gateway

Ein großteil unsere Lambda Funktionen wird über API Aufrufe genutzt. Eine Übersicht dieser haben wir wie eingangs erwähnt in einem Postman File hinterlegt.
API-Routen
POST /image-upload
Hochladen eines Bildes in den S3 Bucket. Wird sowohl mit Bilddaten als auch mit dazugehörigen Informationen wie Beschreibung und Titel aufgerufen (JSON-Format).
POST /image-info
Erstellt einen Eintrag in die DynamoDB Tabelle mit sämtlichen Informationen zu einem Beitrag, wird im Body als JSON übermittelt.
POST /create-file
Erstellt eine Datei im S3 Bucket. Der Dateiname entspricht dem URL Parameter.
GET /get-all-images
Gibt alle als “valid” markierten Beiträge als Array im JSON-Format zurück.
GET /get-file
Gibt eine Datei anhand des Dateinamens zurück.
GET /image-info
Gibt die Informationen zu einem einzelnen Beitrag im JSON-Format zurück.
PUT /update-image-info
Genutzt um Kommentare zu Beiträgen hinzuzufügen. Updated Einträge in der DynamoDB Tabelle.
PUT /update-likes
Verwendet um neue Likes hinzuzufügen.
DynamoDB / S3 Trigger
Neben direkten API Aufrufen verwenden wir auch Trigger auf DynamoDB Tabellen, sowie S3 Buckets.
Exemplarischer Ablauf eines Image Uploads
Dies lässt sich am Besten am Ablauf einer Beitragserstellung darstellen.
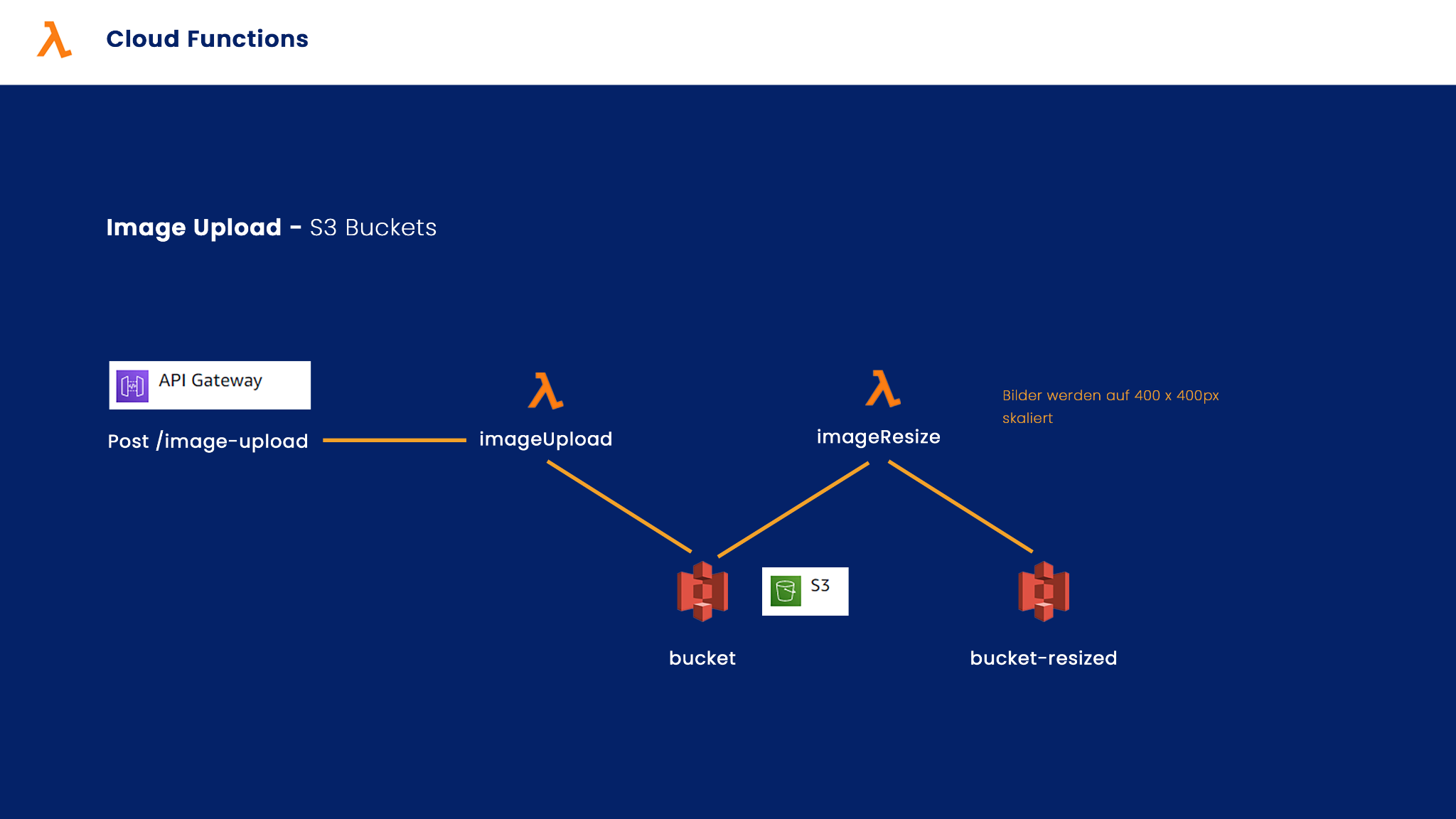
Per Post-Request wird zunächst die Lambda Funktion “imageUpload” aufgerufen, welche das Bild in dem S3 Bucket hinterlegt. Dann wird über einen Trigger automatisch die Lambda Funktion “imageResize” aufgerufen, welche die Bilder auf eine Auflösung von 400 x 400 Pixeln skaliert. Diese Bilder werden dann im Bucket für skalierte Bilder gespeichert. So können die Bilder im Feed gerade bei Mobilen Geräten schneller geladen werden.

Parallel dazu wird in der DynamoDB Tabelle ein Eintrag angelegt. Auch hier wird ein Trigger aufgerufen der seinerseits die Funktion “changeText” aufruft. Diese ersetzt in Anlehnung an den Namen “Ynstagram” alle “i” in Beschreibung und Titel durch “y”. Hierbei handelt es sich lediglich um eine Spielerei die aus unserem Interesse entstand verschiedenste Trigger und Einsatzmöglichkeiten von Lambda Funktionen auszuprobieren.
CI/CD Pipeline
Interessant war es für uns zudem erstmals wirklich Erfahrung mit einer CI/CD Pipeline zu sammeln. Wir planten dabei die strikte Unterteilung in eine Entwicklungsumgebung und einer dieser prinzipiell gleichen finalen Umgebung. So dass der aktuelle Stand schon unter realistischen Bedingungen getestet werden kann bevor er letztlich veröffentlicht wird.
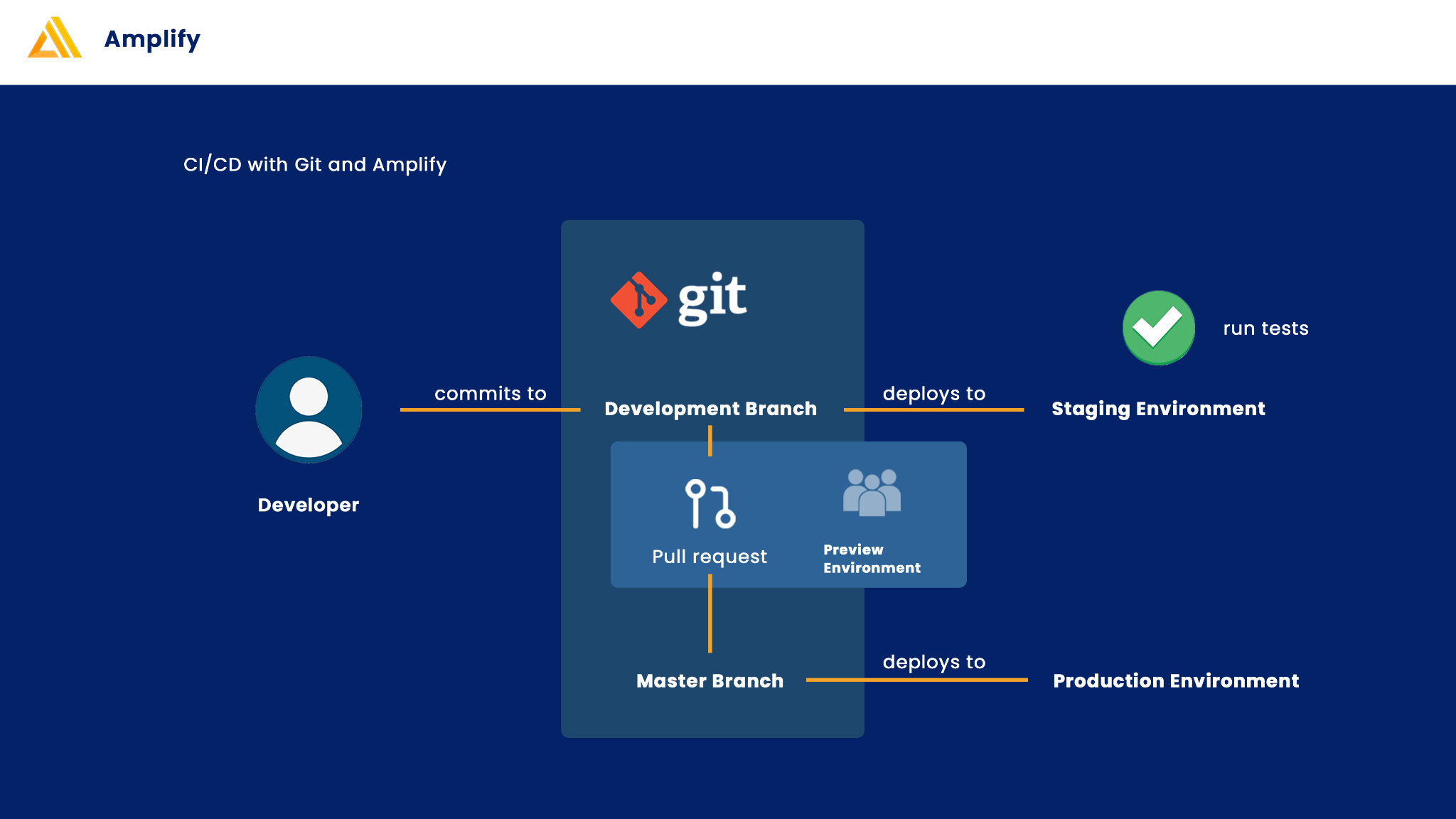
Diese CI/CD Pipeline haben wir mit AWS Amplify und Github Actions umgesetzt. Dabei wird zunächst stets auf einen Development Branch gepusht, welcher dann automatisch auf eine Entwicklungsumgebung auf Amplify hochgeladen wird. So können zunächst alle Tests durchgeführt werden, bevor dann mit einem Pull request die Änderung auf den Master Branch übertragen werden. Wenn dies geschehen ist, werden diese ebenfalls automatisch in die Produktionsumgebung übernommen bzw. deployed.
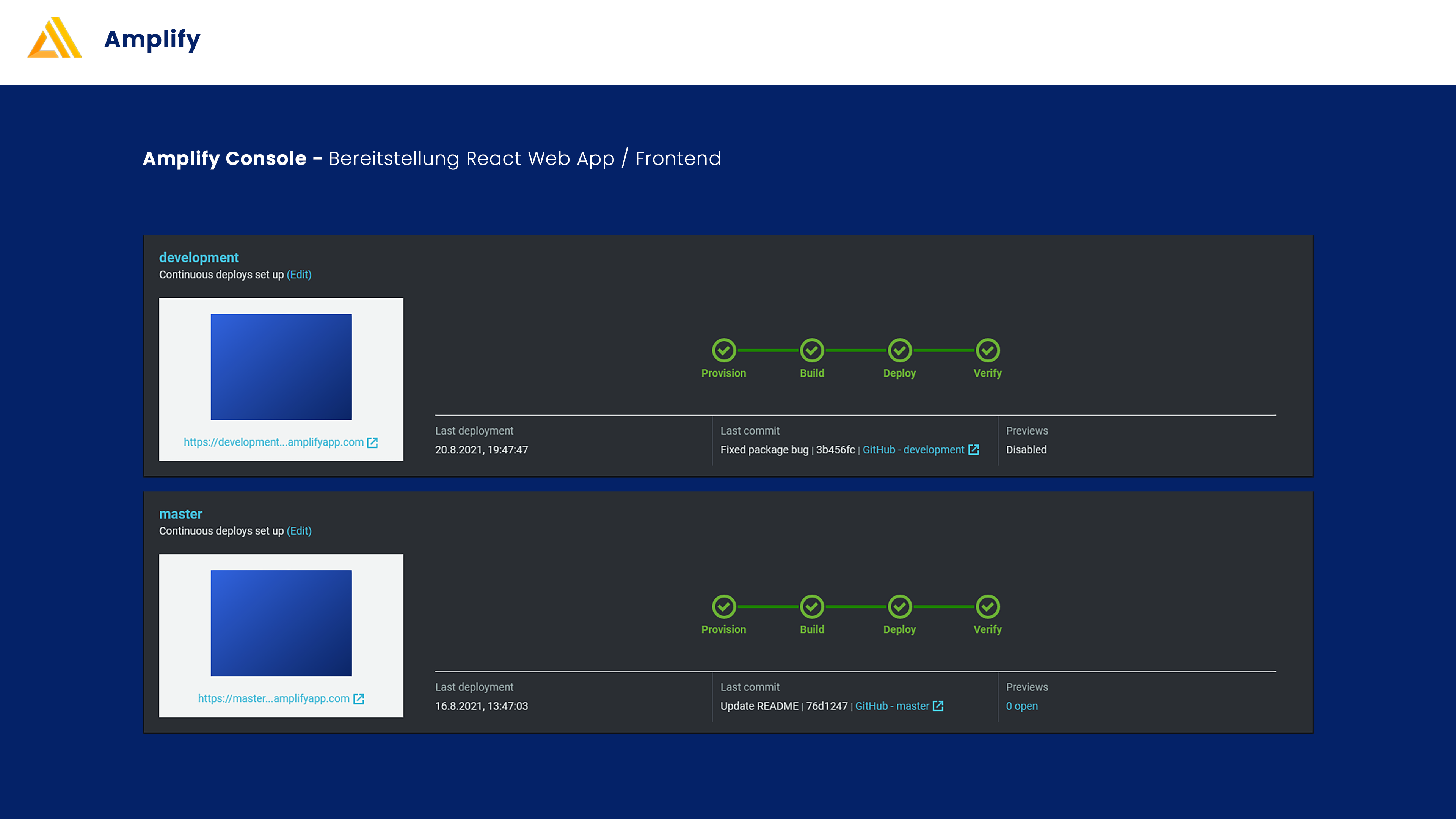
Hier wird neben den durch Github Actions durchgeführten Tests auch überprüft ob die Web Anwendung auch auf verschiedenen Geräten richtig skaliert und damit überprüft ob die UI für den Nutzer funktionsfähig angezeigt wird. Der aktuelle Stand wird dabei selbstverständlich nur übernommen, wenn alle Tests erfolgreich abgeschlossen werden.
Serverless
Um der Unübersichtlichkeit der AWS Weboberflächen aus dem Weg zu gehen und um Elemente leichter und reproduzierbar, über Git verwaltet anlegen zu können haben wir uns für Serverless entschieden. Hier werden alle AWS Komponenten in einem “serverless.yaml” File angelegt.
Variablen
Es gibt dabei zum Beispiel auch die Möglichkeit unkompliziert Environment Variablen anzulegen:

Welche wir wiederum über eigene custom Variablen, welche an verschiedenen Stellen genutzt werden definiert haben:

Dies bringt den Vorteil mit sich, dass Namen flexibel verändert und direkt überall übernommen werden, sprich sowohl in AWS als auch im Code über die Environment Variablen.
Functions

Gleichermaßen einfach lassen sich auch die Lambda Functions anlegen. Diese werden jeweils über einen “handler” referenziert und werden dann durch ein “event” aufgerufen, was entweder API Aufrufe oder eben bspw. DynamoDB / S3 Trigger sein können.
Resources
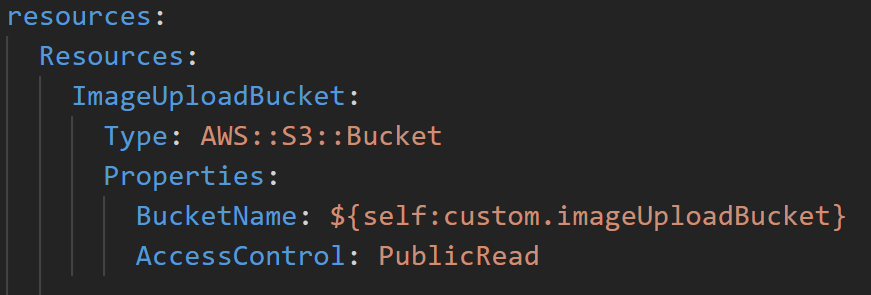
Auch alle Buckets und Tabellen sind im .yaml File definiert. So können insbesondere neue Elemente sehr einfach angelegt werden, da man direkt auf zuvor definierte Konfigurationen zurückgreifen kann.
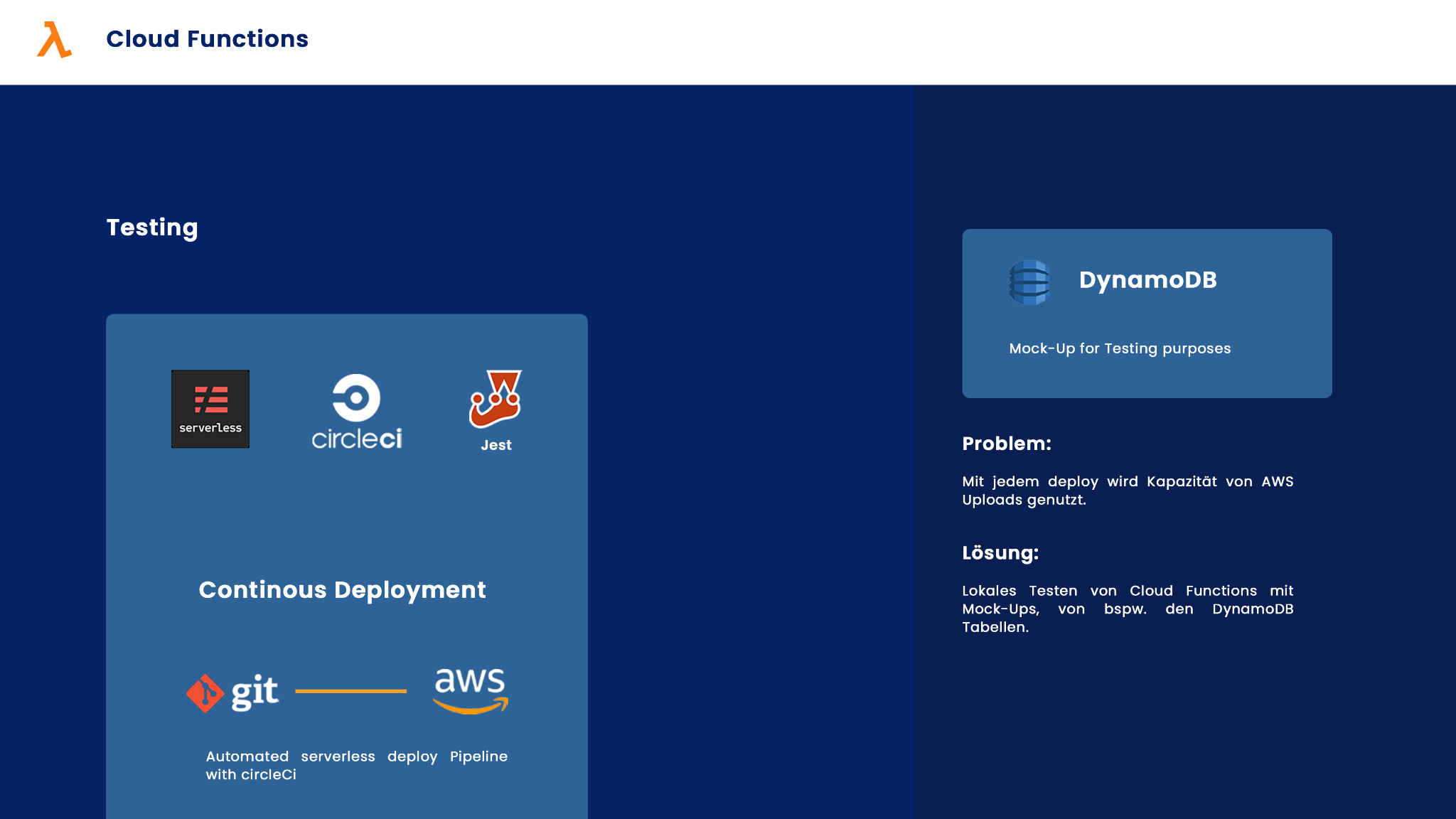
Testing
Beim Testen haben wir uns vor allem auf die API Aufrufe und die grundsätzlichen Funktionen fokussiert. Grundsätzlich werden unsere Tests über die im Abschnitt “CI/CD Pipeline” dargestellte Pipeline mit Github Actions ausgeführt. Diese sind auch Bestandteil des Amplify Deployment Prozesses. Zusätzlich dazu haben wir CircleCi implementiert um die Serverless Komponenten automatisch zu deployen. Für das Testing nutzen wir allgemein ein lokales Mock-Up unserer DynamoDB da wir hier schnell auf das Problem gestoßen sind, dass unsere freien AWS Kontigente aufgebraucht waren.
Ausblick / Fazit
Die größten Schwachstellen des Projektes liegen aktuell in nicht abgesicherten API Aufrufen, diese ließen sich über die Verwendung von API Keys schützen. Dabei sollten perspektivisch auch die Zugriffe auf DynamoDB sowie S3 über IAM Role verwaltet werden.
Für die Accountverwaltung wäre es sinnvoll die Multifaktor Authentifizierung einzurichten. Der Funktionsumfang ließe sich selbstverständlich noch deutlich ausbauen, wobei besonders die Nutzung von KI Komponenten für uns interessant wäre.
Insgesamt konnten wir, ausgehend von keinerlei Grundkenntnissen im Bereich Cloud Computing, uns mit Hilfe der Umsetzung des Projektes im Rahmen der Vorlesung einen Überblick und ein Grundverständnis für die Welt des Cloud Computings erarbeiten, welche eine solide Basis bieten um zukünftig die vorliegenden Ansätze noch wesentlich weiter zu vertiefen.
Leave a Reply
You must be logged in to post a comment.