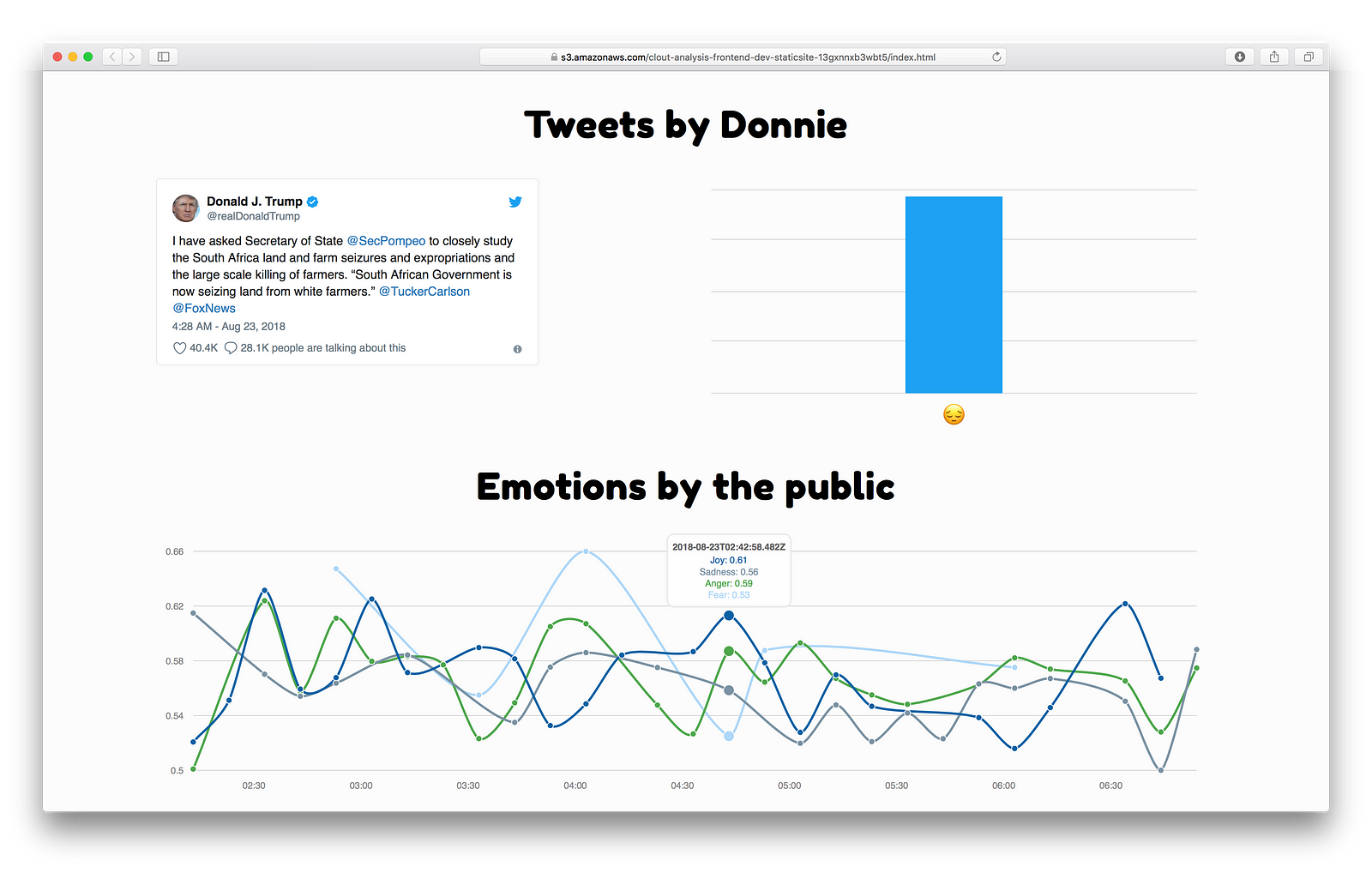
Thinking of Trumps tweets it’s pretty obvious that they are controversial. Trying to gain insights of how controversial his tweets really are, we created tweets-by-donnie.
“It’s freezing and snowing in New York — we need global warming!”
Donald J. Trump
You decide if it’s meant as a joke or not.
But wouldn’t it be nice to know whether the public is seeing this as a joke or whether it’s getting upset by it? That’s where our idea originated from. By measuring the emotions presented in the responses we can see what the public is thinking of Trumps posts throughout the day.
To generate such insights we decided to create a cloud architecture that can deal with a stream of tweets, enrich them and finish it all up with a simple API to query the results.
Easier said than done.
Home is where your IDE is, right? Writing code in the AWS console wasn’t a thing we felt good about. Also, it’s not reproducible in any way, which is why we chose the serverless framework. It bridges the gap from code in your IDE to the cloud. First we were overwhelmed by the technologies as these were our first steps building anything in the cloud. We never heard of AWS Cloudformation and never touched yaml files before but this seemed the way to go and it turned out to be very handy having all code and configurations checked in a repo. This way changing, recreating, or deleting code (or even the whole architecture) is a breeze. Check out our repo, fork it and try it yourself.
The serverless.yml file acts as your main description of your architecture. It can go from a single lambda function to a whole directory containing separate yaml files for different purposes like functions, resources, roles… you name it.
Speaking of roles it’s easy to maintain the least privilege principle with serverless. You can create a role per serverless.yml or go as far as creating a role per function.
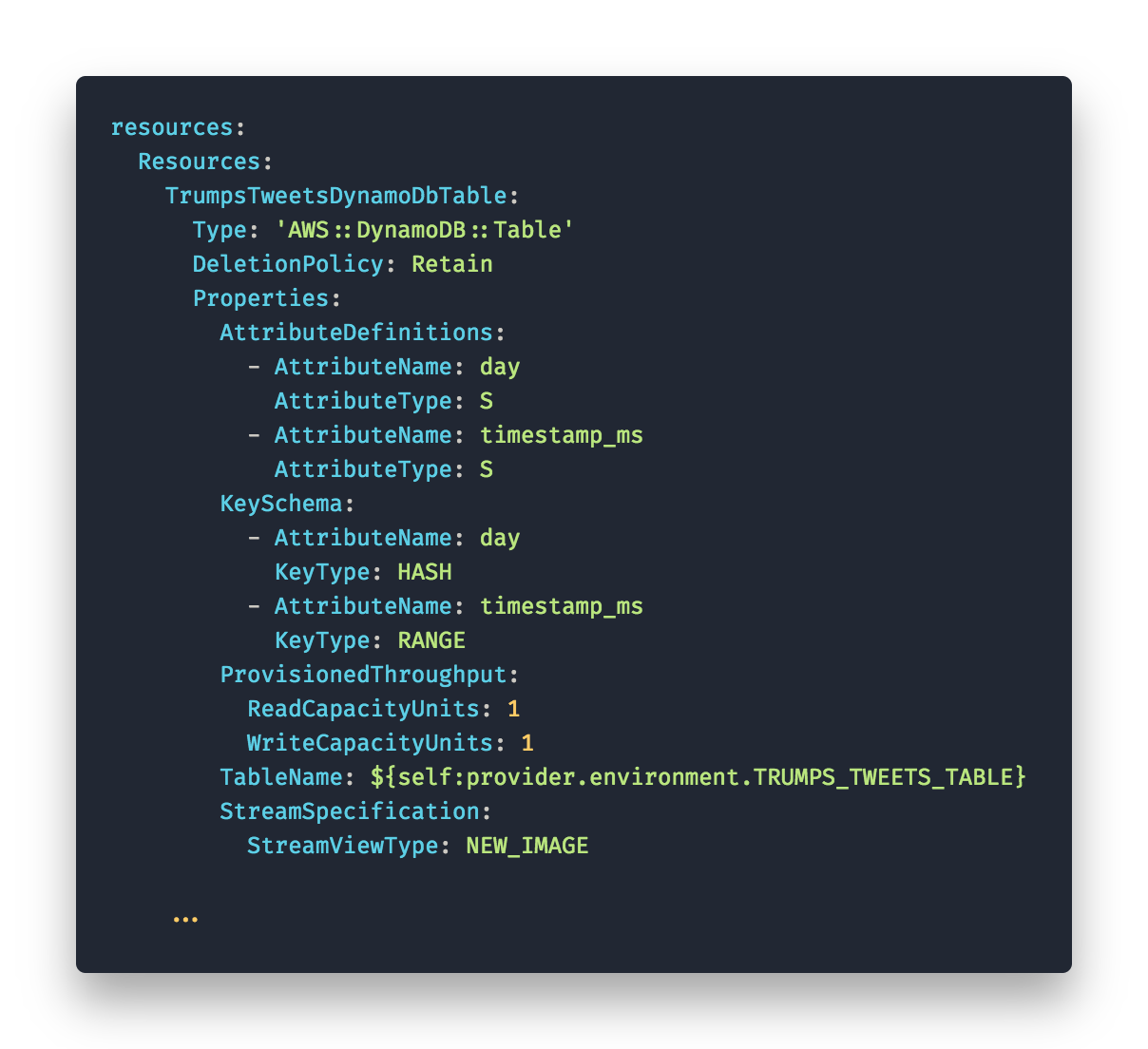
Another good thing was creating the Resources on the fly. We needed some DynamoDB tables.
On a side note: DynamoDB needs some time to get used to. Deliberately select the right set of primary and sort key for your tables because you don’t want to waste time scanning through big tables. In our case we had tweet id’s but that’s not what we’re querying. We are querying for time and as our data is time sequenced, so we chose the day (yyyy-mm-dd) as our primary key and a timestamp as the sort-key. This way we can query for days and sort by timestamp or filter for a time frame of the day.
You can add resources like this.
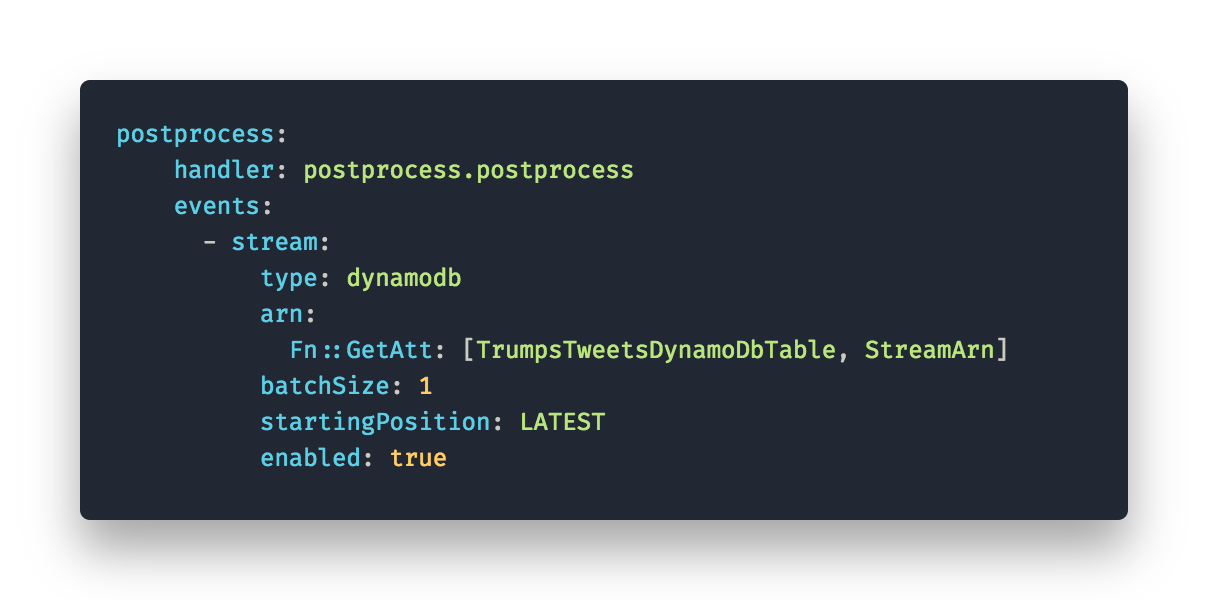
Referencing these resources in other parts of the serverless.yml is quite handy too. For example to trigger a lambda function from a new input to a table we need the stream ARN in our event trigger.
With ‘Fn::GetAtt:[TrumpsTweetDynamoDBTable, StreamArn]’ the Attribute is automatically resolved when deploying.
If you’re ever in need of examples or documentation have a look at the following links, they were rather helpful in the learning process.
Now there is a catch with having our configuration files in source control — secrets. We don’t want them in any repository. So we had to think of storing secrets such as api keys and passwords elsewhere. There are multiple ways to do this in a secure manner. We chose a method where we store the secrets in a separate yaml file (serverless.env.yml) which is then referenced in the actual serverless.yml. You can reference to other files with ‘${file(path/to/file)}:some.key’. This way we can gitignore the serverless.env.yml containing our secrets but keep the serverless.yml checked in without accidentally committing them to a repo.
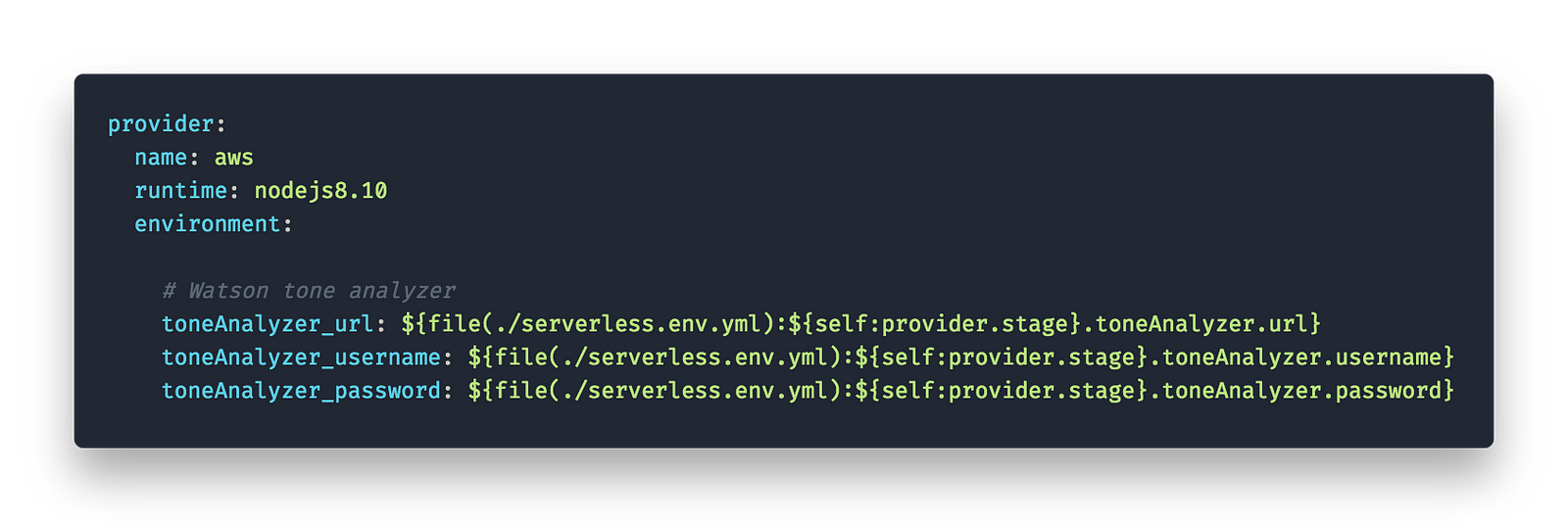
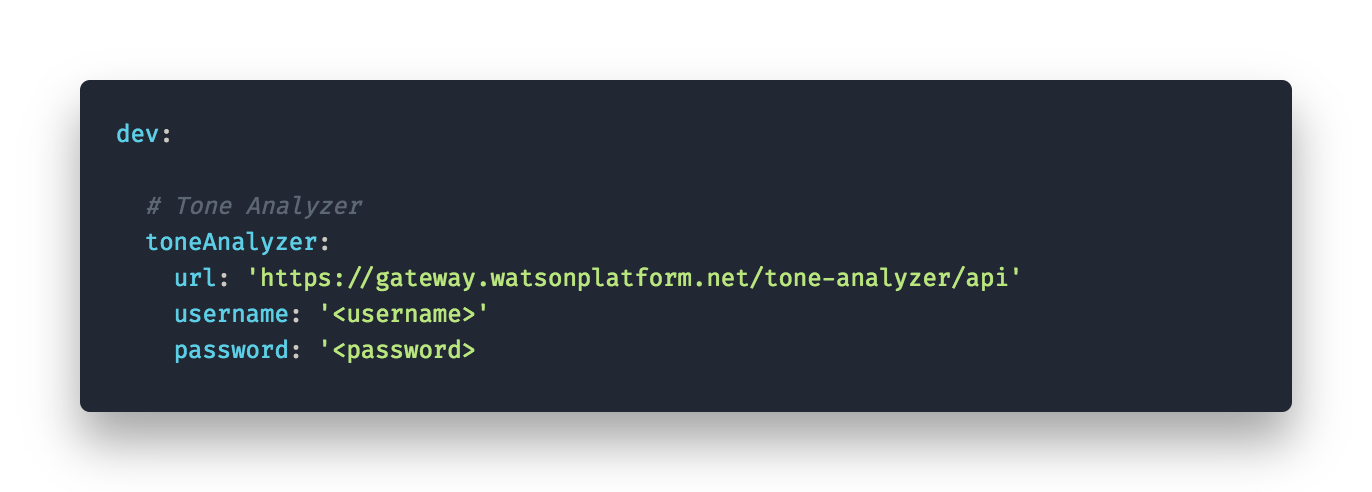
This method seemed feasible for this rather uncritical POC but if you are planning a bigger projects read the following.
Having deployment out of the way let’s get started with the nitty gritty.
Architecture
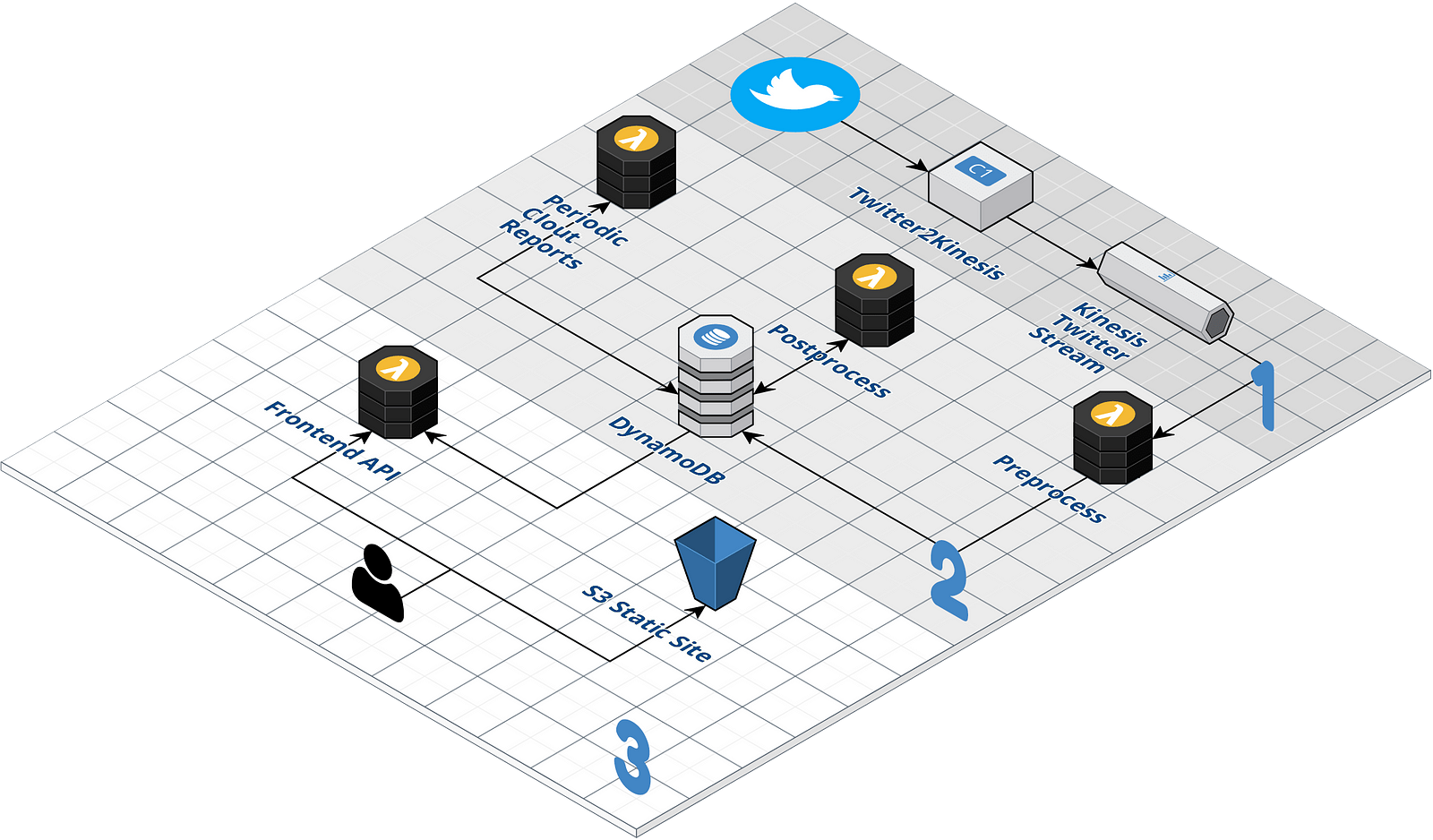
Our architecture consists of three main parts.
1. Getting a stream of tweets to the point they can be processed by lambda
2. Processing the tweets (filter, enrich)
3. Presenting the results
1. Streaming tweets to AWS Kinesis
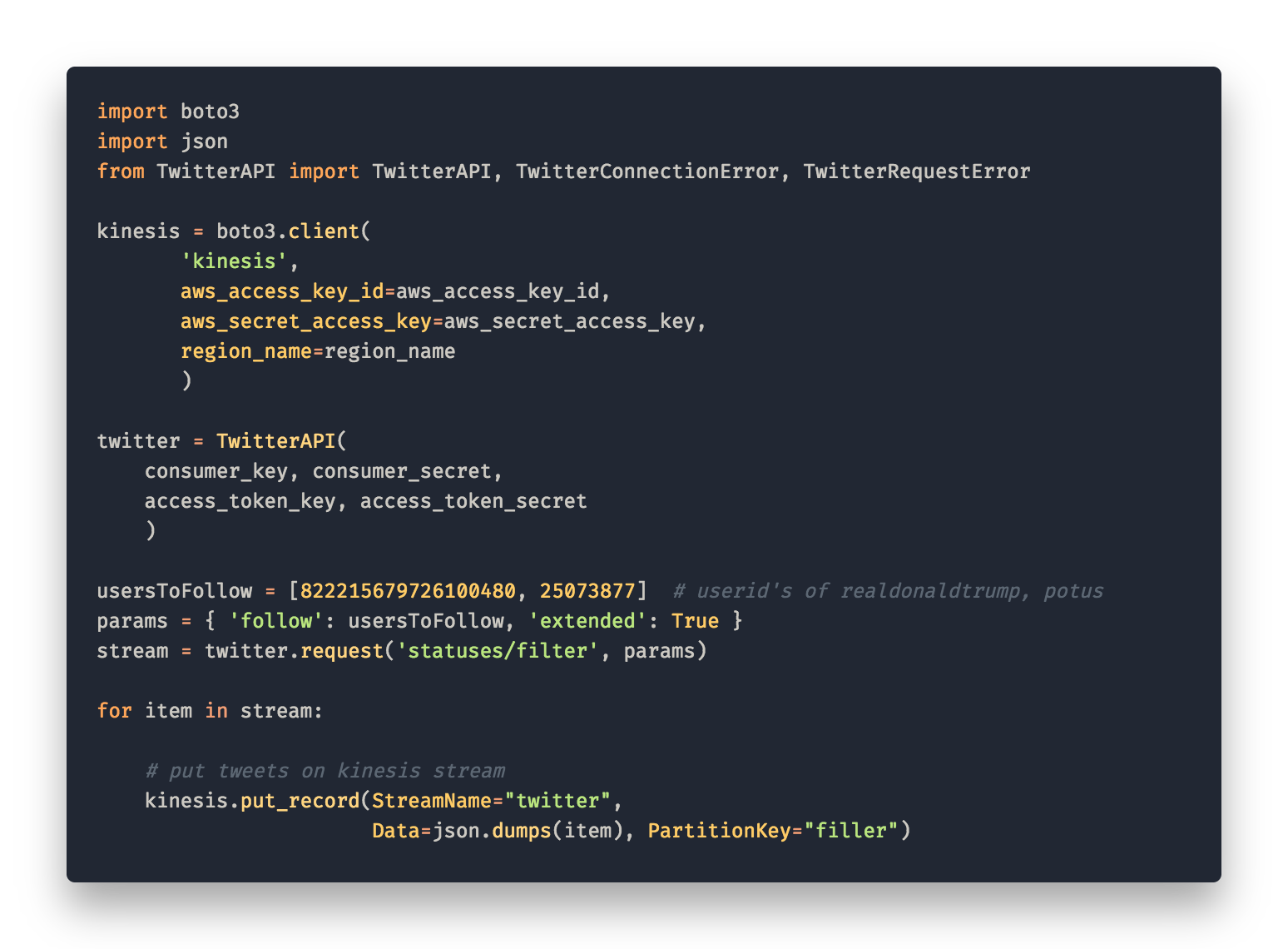
Getting the stream of tweets from twitter into AWS we need a consistently running script that puts each tweet on to the Kinesis stream. First we tried deploying a flask app to heroku. What we didn’t know was that a free tier instance on heroku will be idled after 30 mins inactivity ? (no requests to the server). Finding this we decided to deploy an EC2 compute instance that we are in full control of. You can find the code for this flask server here. Deploying it is described fairly detailed in the readme.
2. Processing tweets
To process the tweets we used three lambda functions and DynamoDB to store the results.
Preprocess
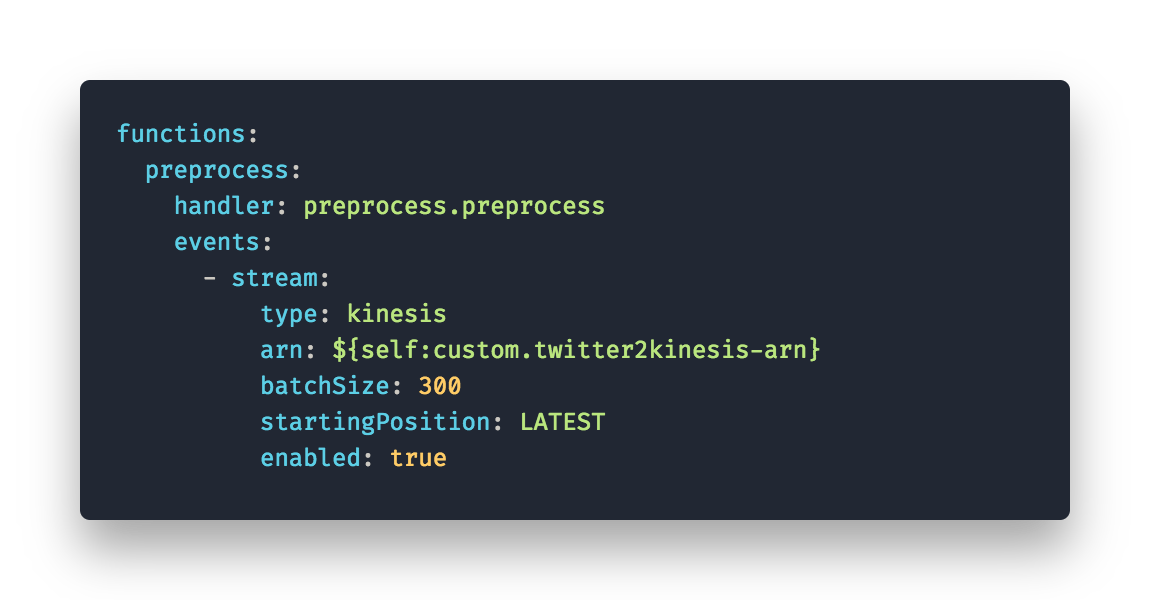
The preprocess function is triggered by incoming items on the kinesis stream. It takes 300 items of the stream and removes retweets and media only tweets. Also, it’s separating tweets from Donald Trump and responses to those into two different DynamoDB tables. (This way the postprocess function is only triggered when saving tweets by D. Trump). CODE
Postprocess
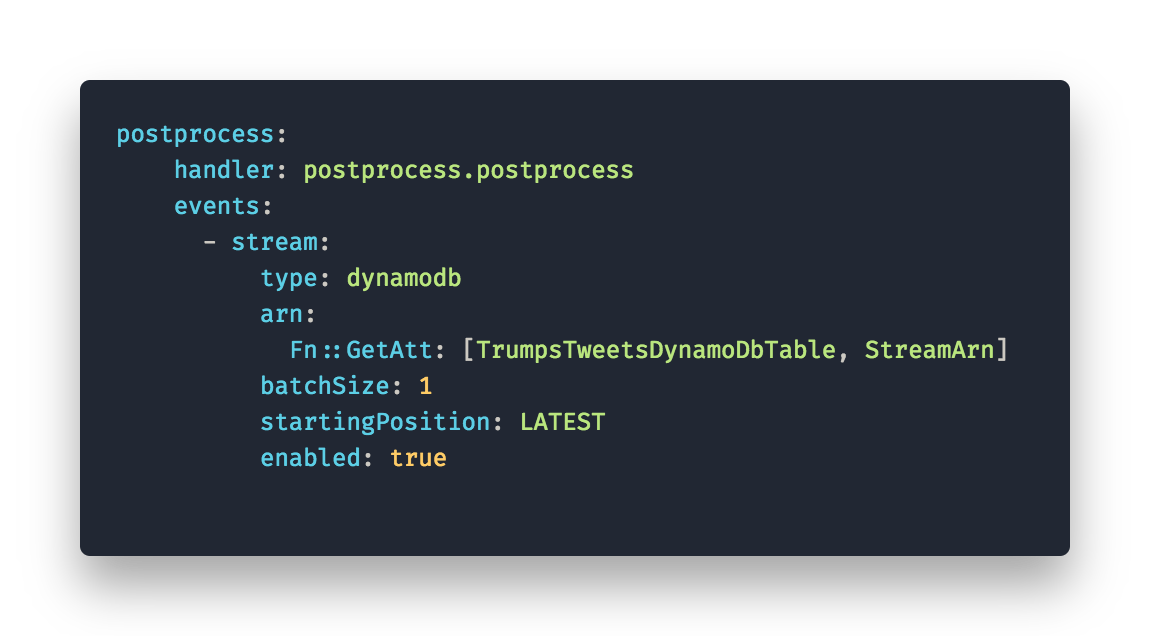
Postprocess takes care of enriching trumps tweets with tone analysis generated by Watson Tone Analyzer. It’s triggered by each write to the table containing only trumps tweets. CODE
PeriodicReports
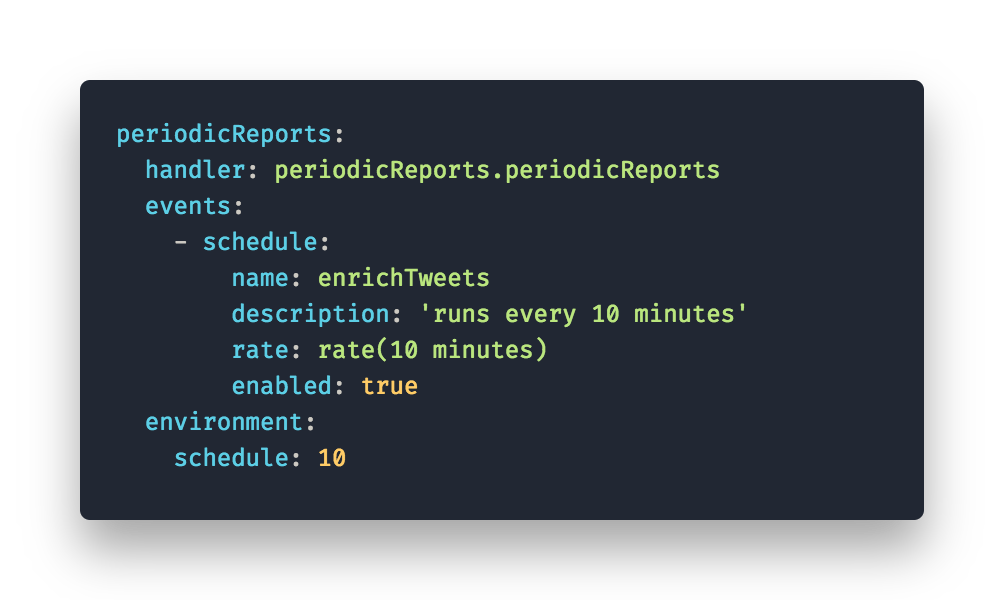
Finally, we need to aggregate the public responses and analyze their tone. For this function we chose to create a report every 10 minutes. The function get’s the latest tweets since it last ran, concatenates the text and runs tone analyzer on them. After it saved the report to DynamoDB we are ready to query the reports and present them. CODE
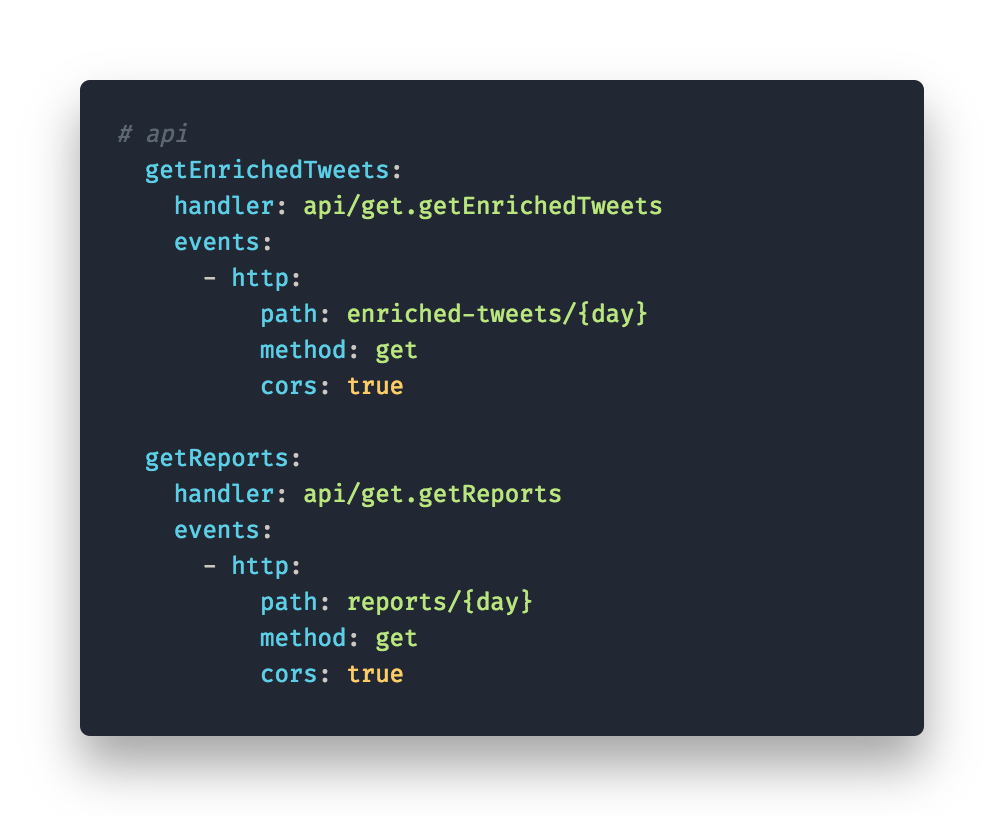
3. Presenting Results
To present our results we chose to create a lambda function that acts as a public API to query the reports and the enriched tweets. As we already knew how to query DynamoDB we only had to prepare the queries and wrap them into lambda functions. In this case we had to set HTTP as a trigger event for our functions. This way we have a path for each function. CODE
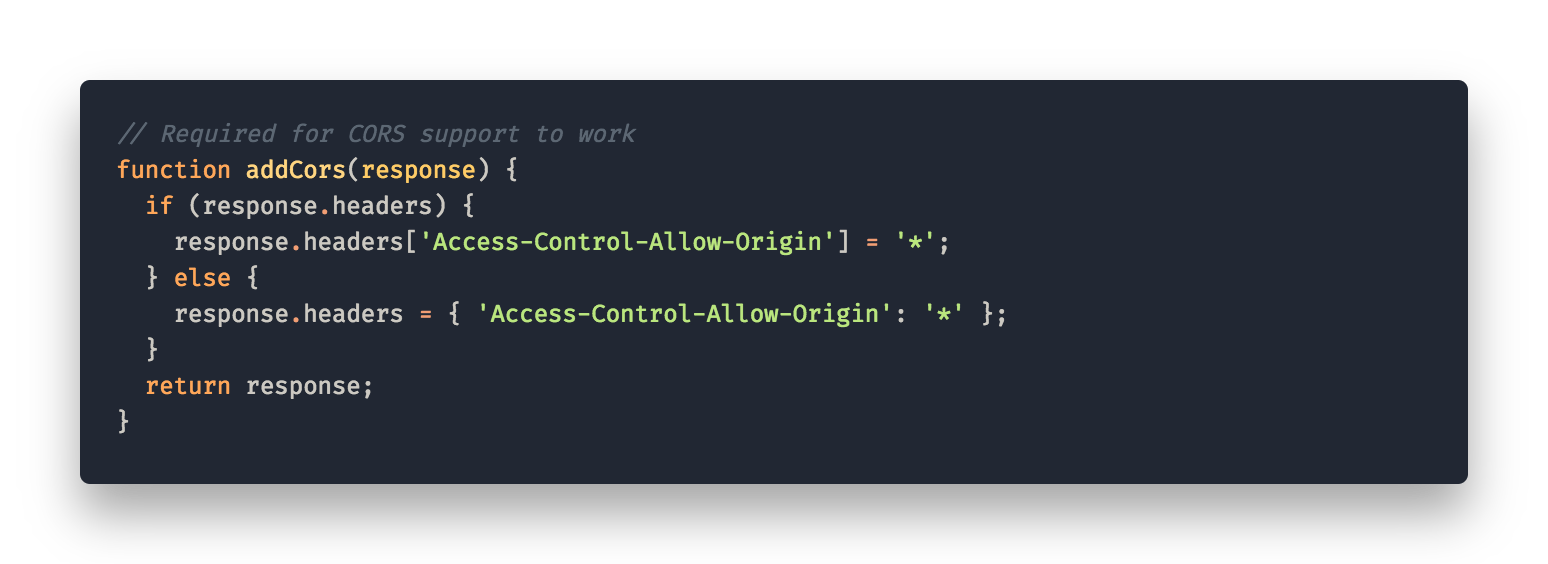
Having CORS enabled for the lambda we first thought it should be working out of the box. But when we tried to call the API from our frontend we still got CORS errors. To get CORS right we had to set the header ‘Access-Control-Allow-Origin: *’for all possible responses from our lambda function including errors.
Lastly we created a Static Website that calls the API for a given day and displays the tweet + enrichments and a graph for the reports. CODE
Summary
This project was all about taking our first steps in the cloud. We learned a lot and there are things we would like to have tested e.g. to use elastic beanstalk instead of deploying an EC2 instance for our flask server or make use of more text analysis… Still, we’re proud of what we created starting from zero and in this limited amount of time. It’s really refreshing to create an application in the cloud. If done right we think you can definitely save some money and headaches from maintaining your own server. It just takes some time to get used to.
Written by Daniel Rotärmel, Paul Fauth-Mayer
Leave a Reply
You must be logged in to post a comment.