
The world is enriched daily with the latest and most sophisticated achievements of Artificial Intelligence (AI). But one challenge that all new technologies need to take seriously is training time. With deep neural networks and the computing power available today, it is finally possible to perform the most complex analyses without need of pre-processing and feature selection. This makes it possible to apply new models to numerous applications. The only thing needed is tons of training data, a good model and a lot of patience during training.
But as progress demands, the complexity of the problems to be solved with Ai grows daily. Not even the problems to be solved have to become more difficult, the increase of features is enough to let complexity explode. The effect of the curse of dimensionality is best seen in a small example. A simple classifier should assign a grayscale photo with a resolution of only 50×50 pixels to the label “dog” or “cat”: The number of weights in the input layer is at 2500. By switching the input to RGB images, the dimension already grows to 7500.
No one wants to analyse images with the ridiculous resolution of 50x50px. Imagine the dimensions of analysing 360° images in 8K, high-precision weather data or millions of social media interactions. It’s obvious how fast the necessary computing power, memory and time requirements explode.
Autonomous cars

Autonomous driving is currently one of the most complex problems to solve, and one of the main reasons for this is the amount of data each car generates. Autonomous vehicles are equipped with numerous high-resolution cameras, lidar, GPS, radar and ultrasonic sensors. In addition, there are hundreds of vehicle sensors that measure the position of the steering wheel, speed, shock absorbers, etc. Adam Grzywaczewski (2017 Nvidia) tried to find out how complex an autonomous driving AI really is. Although it is very difficult to get information such as the used amount of training data, he was able to make an easy to understand estimation of the expected amount of data.
How much data are we talking about?
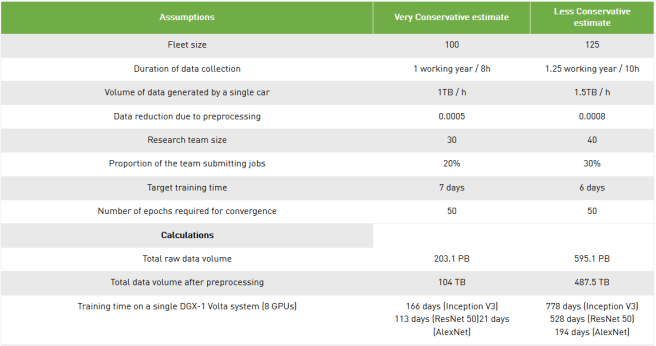
First, Grzywaczewski found out that companies like Waymo and Ford have a fleet of about 100 to 200 autonomous vehicles to collect training data from? (2016/2017). For further calculations, he assumes that data from only 100 vehicles, and no data from various simulations is used for training.
Next he calculates the time one car collects training data per year. With 260 working weeks and 8h working days he results at 2080 hours of training data per car and year.
Further step is to estimate how much data an autonomous vehicle actually collects per hour. He found out that a typical forward facing radar operating at 2800 MBits/s already generates more than 1.26TB of data per hour. A typical autonomous vehicle is expected to collect around 30 TB data per day. Since he found out little more about the sensors of autonomous vehicles, he simplified the problem enormously. He assumes that a vehicle has only five low resolution two megapixel cameras, which record images at 30fps and 1440 bits per second. With this setting he arrives at 24TB data per day captured by a single vehicle.
According to Grzywaczewski’s calculation, a car generates at least 1TB of new training data per hour. Finally, he reduces the training data by sampling the video by 30 times and by assuming an enormously high 70x data compression. This leads to a reduction factor of 0.0005, which is applied to the raw data.
1TB/h multiplied by 100 vehicles, each driving 2080h per year:
Total amount of raw data = 208 PB
on the raw data of 208PB the compression factor of 0.0005 is multiplied:
Total amount of compressed training data = 104TB
How long would training take?
To estimate how long training with a 104TB dataset would take, a lot of information of the structure of the AI used in autonomous cars is necessary. To keep the calculation simple Grzywaczewski compares the effort with simple image classifiers, where the average data flow can be measured with a smaller training data set. Thus he finds out that the well-known AlexNet achieves a data flow of ~150MB/s on a single Pascal GPU. Other more complex ones slow down the data flow up to 19MB/s. In his extrapolation he assumes that all 104TB training data are used at 50 epochs on a single Pascal GPU. He comes up with the following numbers:
- 9.1 years to train an Inception-v3-like network once.
- 6.2 years for a ResNet-50-like network.
- 1.2 years for an AlexNet-like network.
To extend the example even further, he considers a second scenario in which he assumes a little more data from more vehicles, more camera inputs and more hours per day. He also adds less compression at the end. The result is more than 4 times the amount of training data, even though each characteristic was only slightly increased.
We need more power! ..?
In our example the training time of a very simple convolutional network was calculated, which has almost nothing in common with autonomous driving. Nevertheless, the net needs more time to train than data has been collected. Somehow we have to reduce the training time in order to maintain reasonably development. A training time of only a few hours would be an optimal and a more realistic duration would be one week . With a training time of one week, developers could still adjust the hyper parameters of the nets in a regular cycle to find the best parameters. To reduce the training time we need more computing power. The easiest way is to use a computer with more graphic cards. In the last line of the table above, Grzywaczewski has calculated the training time on a DGX-1 Volta with 8 GPUs. These machines, especially developed for artificial intelligence, improve the speed enormously. However, 166 days for an Inception V3 network is still a long way from our goal of 7 days, especially since we have to assume that autonomous driving networks are much more complex and therefore require more training time.
To further improve the speed, you can now calculate the network on multiple graphic cards on multiple machines. If you use 23 computers with 8 GPUs each, the time would be reduced to about 7 days. – Unfortunately not! As Uber, Facebook and many others realised quickly, the training duration is not linear to the added computing hardware.

Distributed Learning
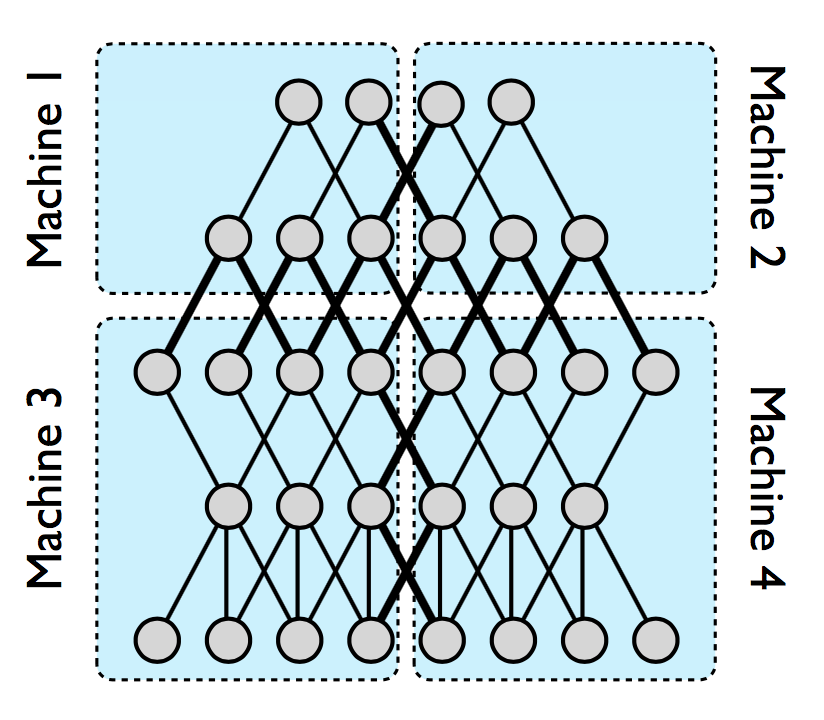
Distributed Learning describes the process of networking many machines to train a single neural network. There are basically two ways to distribute the calculation.
In model-based distributed learning, the network can be divided into different parts. Each subnet is located on its own server. In this option, all data is sent to all servers. Only the proprietary part of the network is trained on each individual server.
Alternatively, you can save the same model on all computers with the data based model. The training data is only send randomly to one of those computers. On each machine the network is trained with this batch of data. The weight adjustments are then synchronized with all other servers via a parameter server.
| Model parallelism | Data parallelism |
|---|---|
 |  |
|
|
With the help of the very simple overview of Distriibuted Learning above, it quickly becomes clear that the training of the networks is slowed down by the communication between the different servers. I could present many different optimizations of Distributed Learning, with the aim to minimize the necessary communication between servers and how the transfer rates are increased to 300GB/s with new connections like the NVLInk. But I was wondering if this actually solves the problem described above?
What issues do we have?
- Calculation: In spite of all the optimizations, the linear relationship between additional hardware and training is the only thing that can be approached. However, the curse of dimensionality shows an exponential increase in complexity. Some high-resolution input data already cause an immense increase in necessary computing power.
- Data Transfer: No matter how the distributed systems for calculation improve, the necessary training data still needs to be transferred between different machines. And with increasing resolution and more vehicles, the training data to be transferred will increase immensely. The huge amount of data can hardly be send via mobile radio networks, but instead has to be transmitted manually. An AI that adapts in real time is therefore not realizable.
- Privacy: Imagine, in a few decades all cars will drive autonomously, equipped with several high-resolution cameras, which permanently capture the 360° image around the car. For privacy reasons this is quite disturbing. Are such images allowed to be transmitted to a server at all? Even if they are “only” used for training?
Move knowledge – no Data!
Classical distributed learning is centrally structured, so training data must first be transferred to a server, from where it is forwarded to individual servers or calculation clusters. This can lead to problems for two reasons. First, the creator of the data may not want to share it or may not be allowed to use it for privacy reasons. Secondly, we have already noticed that the amount of data to be transferred can explode quickly, making data transfer very slow and expensive.
The solution could be Federated Learning, which describes a completely opposite concept. In a nutshell, the data in federated learning will never be transferred to a server. The training itself should not take place on large server farms. Instead, each client device should carry out the training itself and only transfer the newly acquired knowledge to a server. The only thing needed is enough computing power to adapt the weight of the network with optimization algorithms like the Stochastic gradient descent SGD. In addition, a technique is needed to merge the local networks learned on different clients to one global network.
Federated Learning
In federated learning, devices can be divided into nodes and servers. The nodes describe the devices on which the artificial intelligence is used. A globally trained network is stored on the server. The training itself takes place on the individual nodes. The resulting model of a single node is transmitted to the server and averaged there:
- A subset of existing nodes is selected, each of which downloads the current model.
- Each client in the subset computes an updated model based on their local data.
- The model updates are send from the selected clients to the server.
- The server aggregates these models (typically by averaging) to construct an improved global model.

Let us look at federated learning using the example of autonomous vehicles. A vehicle could download the latest global model in the morning. Throughout the day, the vehicle collects a large amount of data. When the vehicle is back in the garage in the evening, the car could use the new data and the computing power of itself to improve the network. The vehicle would then transfer its locally improved network back to the server. On the server, all locally optimized networks would be averaged together. Next morning, a slightly improved global model would be available to all vehicles. Google described Federated Learning using the Android keyboard “Gboard”, as an example. For training, the hardware of the individual smartphones is used. In order to not negatively influence the user experience, the training is only carried out if the mobile phone is connected to the power grid and the mobile phone is connected to a free Wlan network.
Privacy – Secure Aggregation Protocol
We have solved the problem of data transmission with Federated Learning. However, the privacy problem remains. We do not transfer raw image data, but the weight adjustments can be used to reconstruct the input data. Google has developed a new protocol to solve this problem, which is described in the paper “Practical Secure Aggregation for PrivacyPreserving Machine”. This protocol encrypts the weight adjustments. The server cannot decrypt the sum until hundreds or thousands of encrypted
weight adjustments have been added up. However, the server can no longer calculate the input of a single node.

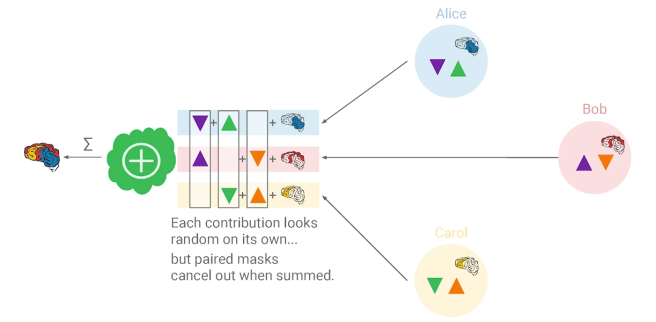
We need random antiparticles!
Before individual nodes transmit their weight adjustment to the server, they form a group. Within this group each node generates antiparticles. These are pairs of a randomly generated vector and its negative one. Each node transfers one of the two vectors to another node. As soon as all vectors have been distributed, the random vectors are added to their weight adjustments. The sum of the vectors and the adjustments are transferred to the server. Everything is summed on the server. The input data of a single node can therefore no longer be reconstructed because they have been manipulated with random vectors. Only in sum the random vectors cancel each other out and the real sum of the weight adjustments is obtained.
Conclusion
Federated Learning is a concept that can become very interesting in the future. It allows to distribute computing power to the end user, to better adapt networks to localities and to improve them in real time. The necessary data transfer can be reduced drastically, since the data remains with the user and only a weight adjustment, which already contains significantly more information, is transmitted. A side effect is that the privacy of the customers can be better taken into account. However, the method also has disadvantages, which I have not mentioned so far. Federated Learning can only be used to train very specific networks. These are networks that do not require labelled data.
These can be, for example, reinforcement networks where the user only sporadically gives feedback to the algorithm. In the case of autonomous driving, an example would be the intervention by the user. Another example are auto-encoder networks, in which an optimal representation of the surrounding images is learned in order to compress the training data as well as possible. A further problem is the additional energy consumption of the end devices due to the calculations.
Similar to the Gboard, it is necessary to define specific conditions from case to case under which training is allowed. However, most users will accept the increased energy demand if they receive an improved AI and better privacy in return. Since the resolution of input data will continue to increase in the future and the computing power of end-user devices such as smartphones, cars and IoT devices will increase enormously at the same time, it is obvious that the data should be processed directly by the user. Federated learning is therefore in no way to be understood as a replacement for distributed learning, but will nevertheless be able to scale computing power significantly better in corresponding applications.
Related Sources and further reading
- Distributed Machine Learning by Pooyan Jamshidi: https://pooyanjamshidi.github.io/mls/lectures/mls05.pdf
- Technologies behind Distributed Deep Learning: AllReduce by Yuichiro Ueno: https://preferredresearch.jp/2018/07/10/technologies-behind-distributed-deep-learning-allreduce/
- Distributed Training Framework by Apache SINGA: https://svn.apache.org/repos/infra/websites/production/singa/content/v0.1.0/frameworks.html
- Training AI for Self-Driving Vehicles: the Challenge of Scale by Adam Grzywaczewski: https://devblogs.nvidia.com/training-self-driving-vehicles-challenge-scale/
- Federated Learning: Collaborative Machine Learning without Centralized Training Data by Brendan McMahan and Daniel Ramage: https://ai.googleblog.com/2017/04/federated-learning-collaborative.html
- What’s New in Deep Learning Research: Understanding Federated Learning by Jesus Rodriguez: https://towardsdatascience.com/whats-new-in-deep-learning-research-understanding-federated-learning-b14e7c3c6f89
- An introduction to Federated Learning by Mike Lee Williams: http://vision.cloudera.com/an-introduction-to-federated-learning/
- Simulation of a federated predictive model by Cloudera Fast Forward Labs: https://turbofan.fastforwardlabs.com/
- Federated learning: distributed machine learning with data locality and privacy by Mike: https://blog.fastforwardlabs.com/2018/11/14/federated-learning.html
- Federated Learning by Jose Corbacho: https://proandroiddev.com/federated-learning-e79e054c33ef
- Google DistBelief paper: Large Scale Distributed Deep Networks by Murat Demirbas; http://muratbuffalo.blogspot.com/2017/01/google-distbelief-paper-large-scale.html
- Large Scale Distributed Deep Networks by
Jeffrey Dean etc.: https://papers.nips.cc/paper/4687-large-scale-distributed-deep-networks.pdf - Practical Secure Aggregationfor Privacy-Preserving Machine Learning by Keith Bonawitz etc.: https://eprint.iacr.org/2017/281.pdf
Leave a Reply
You must be logged in to post a comment.