
While attending the lecture ‘Ultra Large Scale Systems’ I got introduced into the quite intriguing topic of high-performance data storage systems. One subject which caught my special attention were column-oriented database management systems (column stores) about which I decided to give a presentation. Being quite lengthy and intricate, I realized that the presentation left my colleagues more baffled than informed. So I decided to write a blog post to recapitulate the topic for all those who were left with unanswered questions that day and for all the rest out there who might be interested in such matters. I believe this article, even though depicting a quite technical and specialized topic, is nevertheless of general interest because it shows how a system can be optimized for performance by emphasizing on inherent design characteristics.
Introduction
So what are column stores and what do we need them for?
This may be the most eminent question that crosses the mind of people who hear the term ‘column stores’ for the first time. Well let me tell you what they aren’t, a euphonic buzzword which, once uttered, will capture the attention of every IT geek in close vicinity. However, a rather matured technology that has been around since the early 70s and which has been going through constant architectonic refinements that allowed it to establish a foothold on the field of data storage systems used for large scale systems or big data management [1, 2]. Nevertheless, because of their quite specific area of application, column stores still cover a rather opaque field of technical innovation. This article, therefore, tries to provide a brief overview of the subject by giving insights into the architecture, design concepts and current technical advancements concerning column stores.
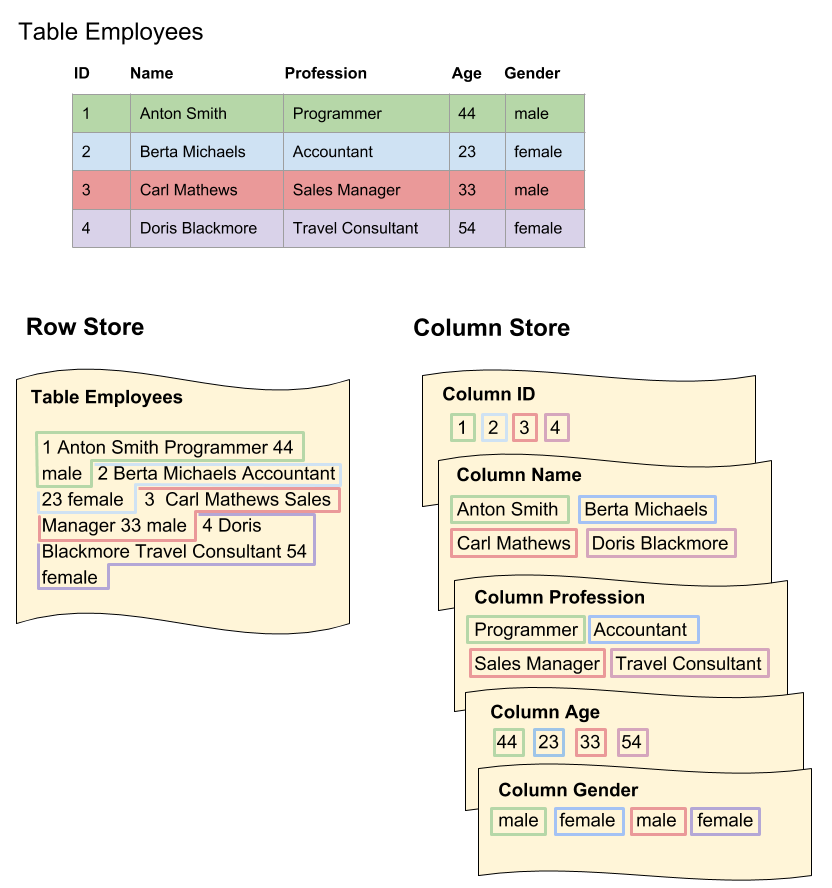
Most modern database management systems (DBMSs) rely on the N-ary Storage Model (NSM). Here records are contiguously stored starting from the beginning of each disk page while using an offset table at the end of the page to position the start of each tuple (record). Thus, within each page the tuples are stored in sequence until the maximum page length of the storage system has been reached and a new page has to be created (figure 1). Database systems centered on this model show good access times when executing queries that either insert or modify single tuples or that result in a projection of a limited number of complete tuples [3]. The major drawback of this model, however, is its poor cache performance because it often burdens the cache with unnecessary attributes [4]. In contrast, column stores follow an entirely different concept called Decomposition Storage Model (DSM) where tables are vertically fragmented storing each attribute in a separate column (figure 1). The different attribute values for each tuple can then be reassembled by correlating their absolute position within each page. Another approach is to use binary relations based on an artificial key (surrogate) that allows reconnecting the different attributes to generate a partial or complete reconstruction of the initial tuple [5]. The performance advantage of this model can be seen when executing queries that require operations on entire columns. Those include aggregation queries (where only subsets of the entire data are required) or scan operations. Furthermore, since the data composition of each column is very homogeneous with little entropy, much better compression ratios can be reached [6]. This becomes even more accentuated when increasingly larger datasets have to be processed.
Diving into the internals
Trying to determine whether to use a row-oriented or a column-oriented storage system will inevitably result in pondering about the pros and cons of the above-mentioned architectures. It is clear that both systems have their strengths and weaknesses and the choice, like so many times, entirely depends on the problem to be solved. This may be elaborated by taking a closer look into the subject using an example. Let’s take the table depicted in figure 1 and imagine a row-oriented database system stored information about company employees in a similar manner. In that case, queries resulting in key lookups and extraction of single but complete records of employees would be executed with high performance by the system. This could be, for example, the search for a record of a specific employee by its ‘ID’ or ‘Name’. This process could even be improved by putting indexes on high cardinality columns like the ‘ID’, for example, which would further speed up the search. Thus, an application or service operating on the database soliciting requests of that classification would definitely benefit from the advantages provided by a row-oriented storage system.
However, what about a request to determine the average age of all male employees stored in the database. This kind of analytical query could in the worst case result in a complete scan of the entire table and would generate a completely different strain on the system [7]. Even though it could be mitigated by the use of composite indexes which, however, are only feasible when the table contains a small number of columns. Latter on the other hand is not the case in many big data storage systems where rather hundreds of columns per table are the norm. Working with composite indexes here will sooner or later produce an immense processing overhead which in the long run would consume substantial system resources [8]. This ultimately means, that for systems containing tables with sizes in the range of several hundred gigabytes, many analytical queries could potentially initiate sequential scans of the entire dataset. For this scenario, column stores represent a better option because the query execution would, by design, be limited to only those attributes required for the final projection. This would spare computation resources by avoiding the necessity to scan large amounts of irrelevant data and, as a result, lead to overall better performance of the system. Consequently, the right choice of the database system should, therefore, be guided by the demands posed by the services operating on it, because they ultimately define the predominant query structure processed by the system.
Query processing models
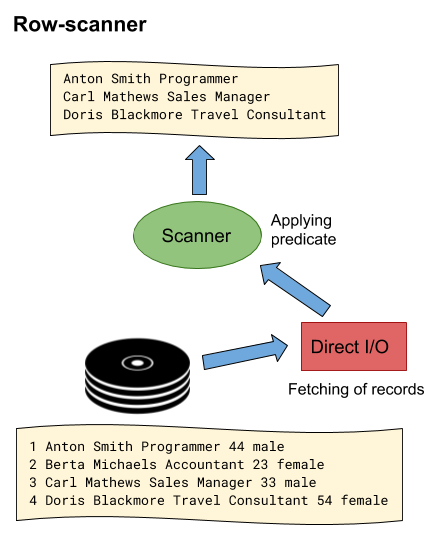
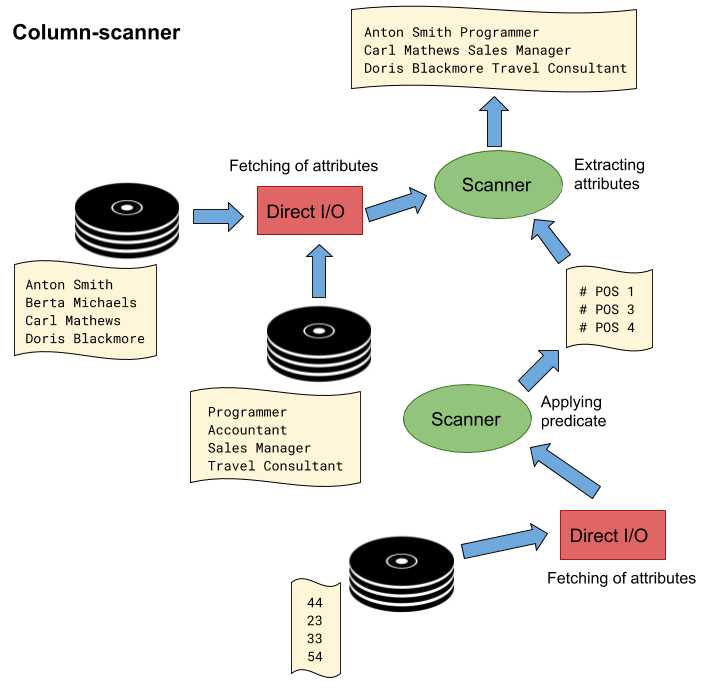
To understand the subjects in the sections that follow, some principle design aspects on how row and column stores execute queries have to be elaborated. Thus, when comparing the implementations of query execution between the two systems, fundamental differences become obvious. Capitalizing on the previous example, let’s observe the execution of the following simple SQL query “SELECT Name, Profession FROM Employees WHERE Age > 30”. The expected result from the query would be a list of the names and professions of all employees being older than 30 years. The request leads to low-level database operations where scanning processes on the corresponding table will be performed to gather the necessary datasets. In the center of every query execution are scanners that apply predicates on tuples, generate projections and provide their parent operators with the corresponding output data.
In the case of the row-scanner implementation (figure 2), the execution process is quite straightforward. Here the data is fetched from the storage layer in the form of record batches on which the scanner will perform filter operations. The data will then be forwarded to the parent operator which aggregates the data to assemble the final projection [9]. Now in case of the column store, the process looks considerably different. As illustrated in figure 3, operations are executed based on single columns rather than entire tables. Here the initial scan operation is performed on a single column containing the data on which the predicate has to be applied. Hence, in the first step, values are filtered by submitting them to predicate evaluation, leaving only a subset of the original dataset. However, instead of returning the values directly, only a list of their corresponding column positions is returned. In the steps that follow, the positions are correlated with the columns containing the requested attributes to extract the corresponding values which are then aggregated to assemble the projection [9]. Thus, the example already indicates why analytical queries may perform better on column stores than on row stores. Instead of scanning the entire table to generate an output consisting of only a small subset of all attributes of the extracted records, operations are limited to that subset of attributes from the beginning, resulting in a significant reduction of the operational overhead.
Bound to be optimized
Simply storing data in the form of columns will not bring the improvements that can be expected from column stores. Actually, with few exceptions, they usually get outperformed by row stores in most scenarios. Consequently, a number of optimization techniques have been adopted over the past years yielding significant performance enhancements. This allowed column stores to be successfully utilized in areas where large datasets have to be handled like, for example, data warehousing, data mining or data analytics [4]. Therefore, the following section will give a brief overview of a selected number of optimization techniques which have been integrated into many modern column store systems today.
Compression
Given the characteristics of columnar data, using compression on such structures seems to be the most obvious approach to reduce disc space usage. Indeed, values from the same column tend to fall into the same domain and, therefore, display low information entropy and more value locality [10]. Those qualities allow compressing one column at a time while even permitting different compression algorithms for individual columns. In addition, if values are sorted within a column, which is common for column store systems, that column will become remarkably compressible [6]. Another technique is ‘frequency partitioning’ where a column is reorganized in such a way, that each page of the column shows as low information entropy as possible. To accomplish this, certain column stores reorganize columns based on the frequency of values that appear in the column and allow, for example, frequent values to be stored together on the same page [11]. The improvements of such methods are apparent and investigations suggest that while row stores allow average compression ratios of 1:3, column stores usually achieve ratios of 1:10 or better. Finally, in addition to lowering disk space usage, compression also helps to improve query performance. If data is compressed, then less time is spent in I/O operations during query execution because of reduced seek times, increased buffer hit rates and less transfer time of data from disk into memory and from there to the CPU [6, 10].
Dictionary Encoding
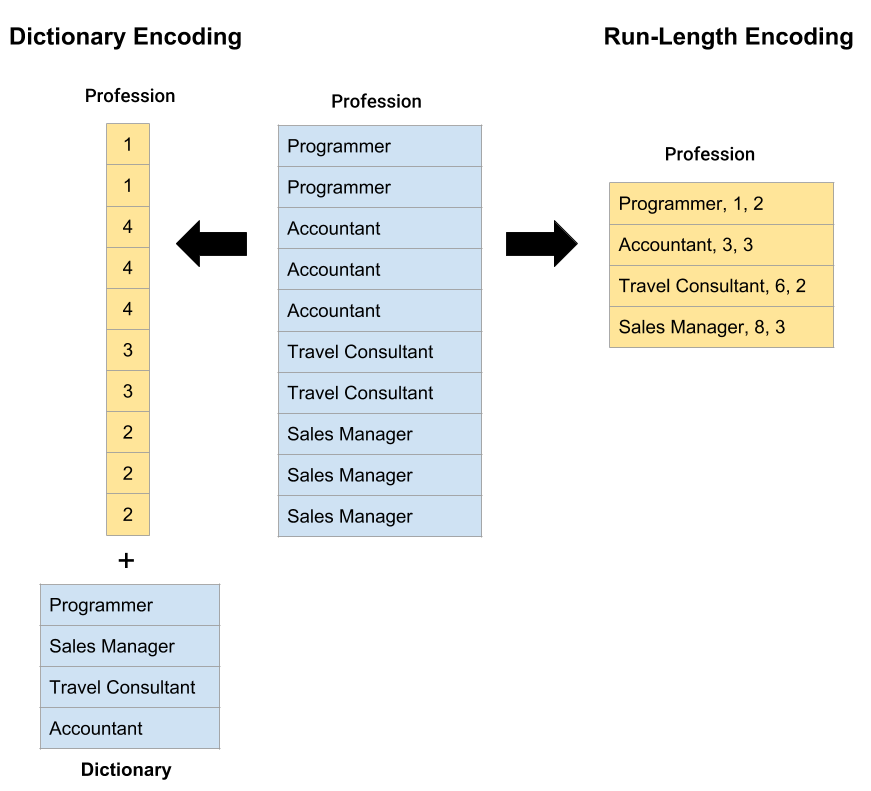
This form of compression works fine on data sets composed of a small number of very frequent values. For each value appearing in a column, an entry is created in a dictionary table. The values in the column are then represented by integer values referencing the positions in this table. Furthermore, dictionary encoding can not only be applied to single columns but also to entire blocks [12]. Another advantage of dictionary compression is that it allows working with columns of fixed length if the system keeps all codes of the same width. This can further maximize data processing speeds in systems that rely on vectorized query execution.
Run-Length Encoding
The encoding is well suited to compress columns containing repeating sequences of the same value by reducing them to a compact singular representation. Here, the column entries are replaced by triple values describing the original value, its initial start position and its frequency (run-length). Hence, when a column starts with 20 consecutive entries of the value ‘male’ than these entries can be reduced to the triple (‘male’, 1, 20). This compression form works especially well on sorted columns or columns with reasonable-sized runs constituted of the same value [10].
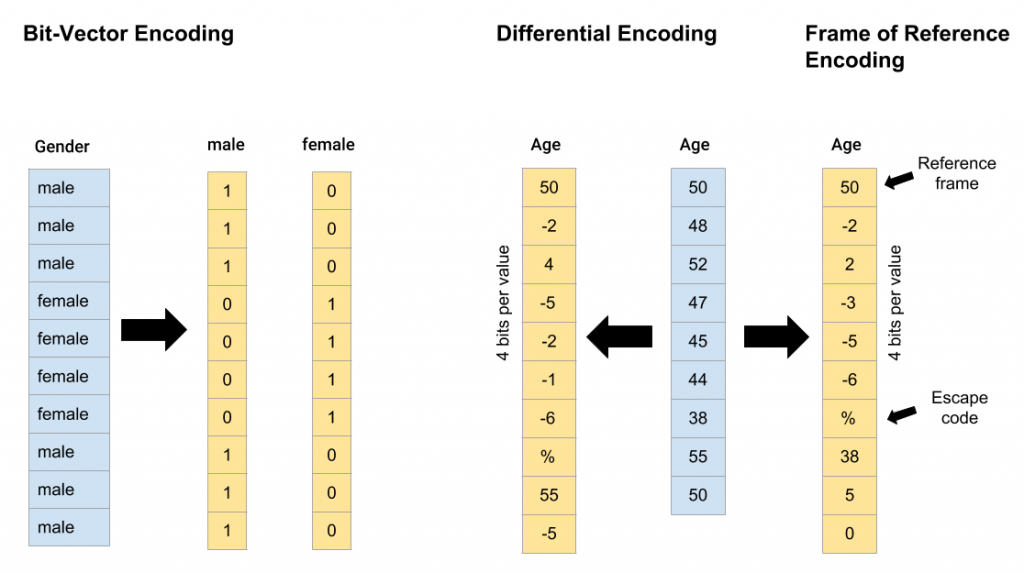
Bit-Vector Encoding
In this type of encoding for each unique value in a column, a bit-string with the same length as the column itself is generated. The string contains only binary entries designating a ‘1’ if the value the string is associated with exists at the corresponding position in the column, or a ‘0’ otherwise. ‘Bit-Vector’ encoding is frequently used when columns have a limited number of unique data values. In addition, there is also the possibility to further compress the bit-vector allowing to use the encoding even on columns containing a larger amount of unique values [10].
Differential Encoding and Frame of Reference Encoding
‘Differential’ encoding expresses values as bit-sized offsets from the previous value. A value sequence beginning with ’10, 8, 6, 12′ for example, can be represented as ’10, -2, -2, 6′. The bit-size for the offset value, however, is fixed and cannot be changed once established. Therefore, special escape codes have to be used to indicate values whose offset cannot be represented with the specified bit-size. The encoding performs well on columns containing sequences of increasing or decreasing values, thus, demonstrating value locality. Those can be inverted lists, timestamps, object IDs or sorted numeric columns. As a variation of the concept, there is also the ‘Frame of Reference’ encoding which works in a very similar way. The main difference here is that the offsets do not refer to the direct predecessor but to a reference value within the set. For example, the previous sequence ’10, 8, 6, 12′ would be represented as ’10, -2, -4, 2’ with ’10’ being the reference value [13].
Operations on compressed data
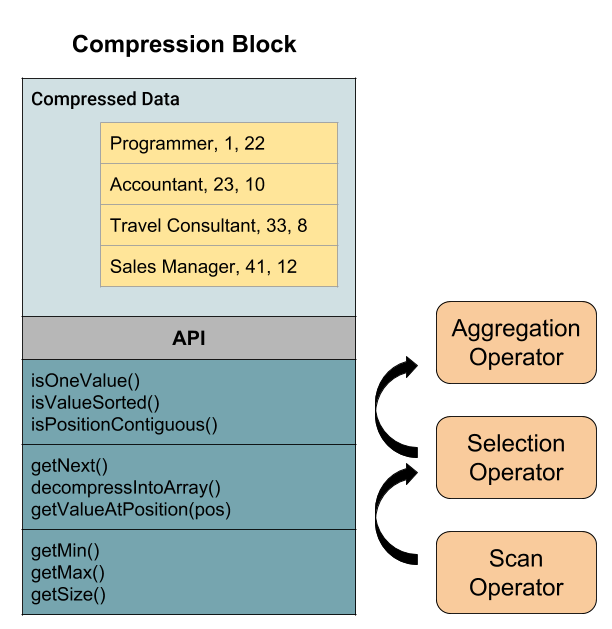
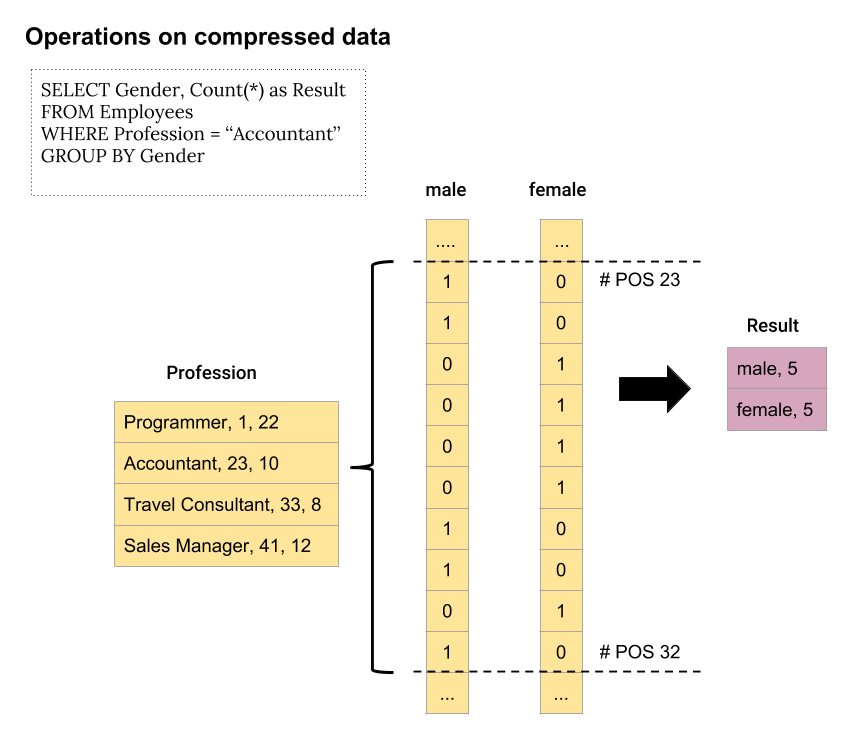
Performance gains through compression can be maximized when operators are able to directly act on compressed values without the need for prior decompression [14]. This can be achieved through the introduction of buffers that consist of column data in a compressed format providing an API which allows query operators to work directly on the compressed values. Consequently, a component wrapping an intermediate representation for compressed data termed a ‘compression block’ is added to the query executor (figure 6). The methods provided by the API can be utilized by query operators to directly access compressed data without having to decompress and iterate through it [6, 10]. The illustration in figure 7 should exemplify the design by showing how a query execution on compressed data would look like. The query is aimed to determine the number of male and female employees who work as accountants. In the first step, a filter operation is performed on the sorted and ‘Run-length’ encoded ‘Profession’ column by calling the corresponding API method which returns the index positions of those values passing the predicate condition (Profession = ‘Accountant’). The positions can then be used to delimit the corresponding region within the ‘Bit-Vector’ encoded ‘Gender’ column. Finally, the number of males and females working as accountants can be calculated using a corresponding API method that sums up all occurrences of the value ‘1’ within the interval. As seen, for none of the operations any decompression of the scanned data was necessary.
Vectorized execution
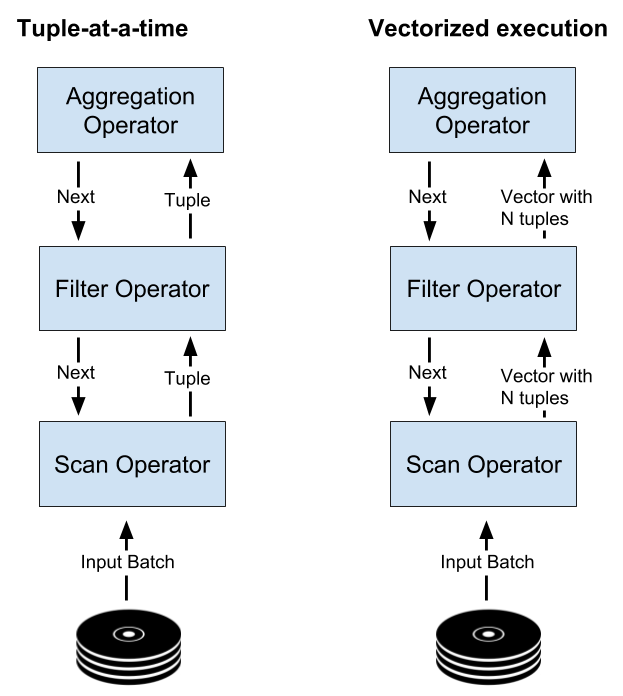
Most of the traditional implementation strategies for the query execution layer are based on the ‘iterator’ or ‘tuple-at-a-time’ model where individual tuples are moved from one operator to another through the query plan tree [10]. Each operator normally provides a next() method which outputs a tuple that can be used as input by a caller operator from further up the execution tree. The advantage of this approach is that the materialization of intermediate results is minimal. There is, however, another alternative called ‘vectorized execution’ where in contrast to the ‘tuple-at-a-time’ model, each operator returns a vector of N tuples instead of only a single tuple (figure 8). This approach offers several advantages [6]:
- Reduction in interpretation overhead by limiting the amount of function calls through the query interpreters.
- Improved cache locality by being able to adjust the vector size to the CPU cache.
- Better profiling by allowing operators to execute all expression evaluation work in a vectorized fashion (i.e. array-at-a-time), keeping the overhead for measurements of individual operations low.
- Taking advantage of the columnar format by reading larger data batches of N tuples at a time allowing array iteration with good loop pipelining techniques, so that operations can repeatedly be executed within one function call.
Early vs. late materialization
One fundamental problem when designing the execution plan of queries for column stores is to determine when the projection of columns should occur. In a column store, information of a logical entity or object is distributed over several column pages on the storage medium. As a result, during the execution of most queries, several attributes of a singular entity have to be accessed. In many cases, however, database outputs are expected to be entity-based and not column-based. Consequently, during every execution, the information scattered over multiple columns has to be reassembled at some point, to form ‘rows’ of information about the entity. This joining of tuples is a process very common for column stores and has been coined with the term ‘materialization’ [15]. In this context, there are principally two design concepts that address the problem of column projection called ‘Early Materialization’ and ‘Late Materialization’. During query execution, most naive column stores first select the columns of relevance, construct tuples from their component attributes, and then execute standard row store operations on the resulting rows. This approach of constructing tuples early in the query plan called ‘Early Materialization’ will in many cases result in better performance for analytical queries when compared to those seen in typical row stores, however, much of the potential of column stores will still be left untouched.
Modern column stores adapted the concept of ‘Late Materialization’ where operations are performed on the basis of single columns as long as possible and projection of columns occurs late in the query plan. From this rises the necessity to work with intermediate ‘position lists’ to join operations that have been conducted on individual columns. This lists can be represented as a simple array of bit strings or as a set of ranges of positions. Those position representations can then be intersected to extract the values of interest which then confluent into the final projection [15]. Thus, the concept of ‘Late Materialization’ offers several advantages that result in significant performance boosts which can be attributed to the following characteristics:
- Given specific selection and aggregation operations, it is possible to completely skip the materialization of some tuples.
- Decompression of data for the reconstruction of tuples can be avoided which allows the continuous operation on compressed data in memory.
- Cache performance can be improved while operating directly on column data because irrelevant attributes for given operations can be omitted.
- Efficient CPU usage through operations on highly compressible position representations which, given their structure, are well suited for CPU processing.

In the following, a typical query execution using late materialization as implemented in modern column store systems will be described. Here the query consists of a simple SQL-statement aimed to determine the number of all female employees over 30 years of age ordered by professions (figure 9). In this example, the intermediate lists are expressed in the form of bit-vectors representing the positions of those values that passed the predicates and on which bit-wise ‘AND’ operations can be executed.
The query execution illustrated in figure 10 is a select-project operation where essentially two columns of a table (Employees) are filtered, while subsequently a sum aggregation is performed to generate the projection. Thus, in the first step, the two predicates are applied to the ‘Age’ and ‘Gender’ columns which results in two bit-vectors representing only those values which passed the predicates. These are then intersected by applying a bit-wise ‘AND’ operation and the resulting bit-vector then used to extract the corresponding values from the ‘Profession’ column. In the last step, the results are aggregated to assemble the projection by grouping and summing the values from the previous operation.

Virtual IDs
A possible way to structure columns within a column store is to associate individual columns with an identifier like, for example, a numeric primary key. Adding an identifier in such an explicit fashion, however, unavoidably introduces redundancy and increases the amount of data to be stored on the disk. To solve this problem, modern database systems try to avoid additional columns containing solely IDs by substituting them with virtual identifiers which represent the position (offset) of the tuple in the column [5]. The design can be further enhanced by implementing columns composed of fixed-width dense arrays. This allows storing attributes of an individual record at the same position across all the columns of a table. In combination with offsets, the design permits to significantly improve the localization of individual records. A value at the i-th position of a table EMP, for example, could be located and accessed by just calculating ‘startOf(EMP)+i*width(EMP)’.
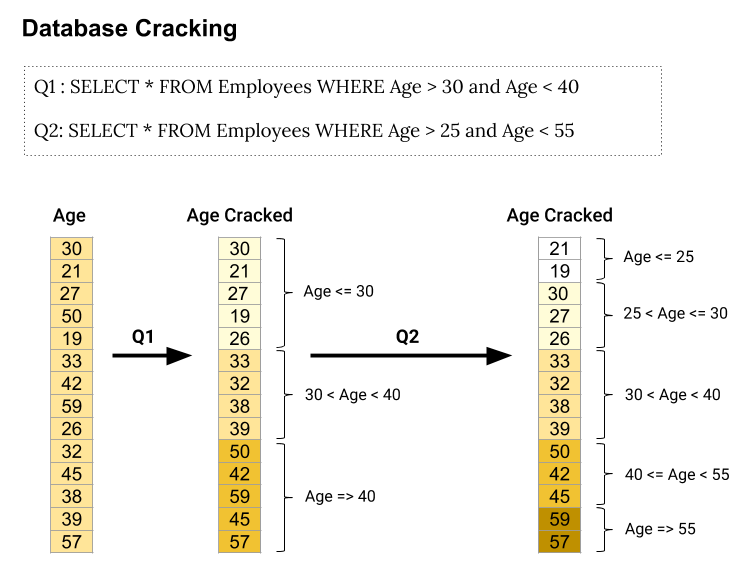
Database cracking
Sorted columns are a helpful measure to significantly improve the performance of column stores, including the realization of high compression ratios. However, common approaches require a complete sorting of columns in advance, demanding idle time and workload knowledge. More dynamic approaches have brought forward architectures aiming to perform such tasks incrementally by combining them with query execution. The principal motivation is to continuously change the physical data store with every executed query. Sorting is consequently done adaptively in a continuous manner and limited to the accessed sections of a column [16]. Therefore, each query performs a partial reorganization of all processed columns making subsequential access faster. This process is called ‘Database cracking’ which allows using the database system immediately once data is available. It is an interesting approach to adaptive indexing because on every range-selection query, the data is reorganized and compartmentalized using the provided predicates as pivots. In that manner, the optimal performance is achieved incrementally without the prior need to analyze the expected workload, tune the system and create indexes. Thus, figure 11 shows an example of a search request where two consecutive queries search and ‘crack’ a column (‘Age’). The first query subdivides the column into three pieces while the second query further improves the partitioning process. The final result is a column that is partially sorted and comprised of five value ranges. Consequently, the structure of the column data represents a reflection of the query structure and thus constitutes an adaption to the data requirements of the applications (services) accessing the database.
Conclusion
The column store concept, albeit nearly half a century old, has received considerable attention during the last decade. This is due to the fact that column stores exceed when it comes to performing analytical-style processing of large datasets [9]. This has made them the storage system of choice especially for applications operating with OLAP-like workloads which rely on very complex queries often involving complete datasets. Investigations have shown, however, that substantial improvements of the basic concept of column stores are necessary to truly reap the benefits such an architecture may provide. Therefore, several optimizations have been introduced over the past years, some of which have been discussed here. Those include compression, API-based compression buffers, vectorized processing, late materialization, virtual IDs and database cracking. All of which aim to significantly improve the processing time by tackling performance issues from different angles. When adding such optimization techniques column stores outperform row stores by an order of magnitude on analytical workloads [8]. This also indicates that the architectural design will be of interest even in the years to come because of the ever-growing number of large-scale, data-intensive applications with high workload. Those include scientific data management, business intelligence, data warehousing, data mining, and decision support systems.
Finally, there are also still directions for future developments that are worth investigating like, for example, hybrid systems that are partially column-oriented. Those could be realized in the form of architectures that store columns grouped by access frequency or that adapt to access patterns allowing to switch between column-oriented and row-oriented table structures when needed. Another issue to be addressed are the loading times of column stores, which still do not perform well when compared with row stores, especially if there are many views to materialize. Thus, studies on possible new algorithms that could alleviate the problem by substantially improve read performance would surely be an interesting field for future investigations.
References
[1] S. Melnik, A. Gubarev, J. J. Long, G. Romer, S. Shivakumar, M. Tolton and T. Vassilakis, Dremel: Interactive Analysis of Web-scale Datasets, Proceedings of the VLDB Endowment, VLDB Endowment, 2010, Vol. 3(1-2), pp. 330-339.
[2] D. J. Abadi, P. A. Boncz and S. Harizopoulos, Column-oriented database systems, Proceedings of the VLDB Endowment, VLDB Endowment, 2009, Vol. 2(2), pp. 1664-1665.
[3] D. Bößwetter, Spaltenorientierte Datenbanken, Informatik-Spektrum, Springer, 2010, Vol. 33(1), pp. 61-65.
[4] A. El-Helw, K. A. Ross, B. Bhattacharjee, C. A. Lang and G. A. Mihaila, Column-oriented Query Processing for Row Stores, Proceedings of the ACM 14th International Workshop on Data Warehousing and OLAP, ACM, 2011, pp. 67-74.
[5] S. Idreos, F. Groffen, N. Nes, S. Manegold, K. S. Mullender and M. L. Kersten, MonetDB: Two Decades of Research in Column-oriented Database, IEEE Data Engineering Bulletin, 2012, Vol. 35(1), pp. 40-45.
[6] D. J. Abadi, Query execution in column-oriented database systems, Massachusetts Institute of Technology, 2008.
[7] D. J. Abadi, Column Stores for Wide and Sparse Data, CIDR, 2007, pp. 292-297.
[8] D. J. Abadi, S. R. Madden and N. Hachem, Column-stores vs. row-stores: how different are they really?, Proceedings of the 2008 ACM SIGMOD international conference on Management of data, 2008, pp. 967-980.
[9] S. Harizopoulos, V. Liang, D. J. Abadi and S. Madden, Performance tradeoffs in read-optimized databases, Proceedings of the 32nd international conference on very large data bases, 2006, pp. 487-498.
[10] D. Abadi, S. Madden and M. Ferreira, Integrating compression and execution in column-oriented database systems, Proceedings of the 2006 ACM SIGMOD international conference on management of data, 2006, pp. 671-682.
[11] V. Raman, G. Swart, L. Qiao, F. Reiss, V. Dialani, D. Kossmann, I. Narang and R. Sidle, Constant-Time Query Processing, IEEE 24th International Conference on Data Engineering (ICDE ’08), IEEE Computer Society, 2008, pp. 60-69.
[12] P. Raichand, A short survey of data compression techniques for column oriented databases, Journal of Global Research in Computer Science, 2013, Vol. 4(7), pp. 43-46.
[13] J. Goldstein, R. Ramakrishnan and U. Shaft, Compressing relations and indexes, Proceedings 14th International Conference on Data Engineering, IEEE, 1998, pp. 370-379.
[14] O. Polychroniou and K. A. Ross, Efficient lightweight compression alongside fast scans, Proceedings of the 11th International Workshop on Data Management on New Hardware, 2015, pp. 9.
[15] D. J. Abadi, D. S. Myers, D. J. DeWitt and S. R. Madden, Materialization strategies in a column-oriented DBMS, IEEE 23rd International Conference on Data Engineering, 2007, pp. 466-475.
[16] S. Idreos, M. L. Kersten and S. Manegold, Self-organizing Tuple Reconstruction in Column-stores, Proceedings of the 2009 ACM SIGMOD International Conference on Management of Data, ACM, 2009, pp. 297-308.
Leave a Reply
You must be logged in to post a comment.