
Introduction
“How do you turn a trained model into a product, that will bring value to your enterprise?”
In recent years, serving has become a hot topic in machine learning. With the ongoing success of deep neural networks, there is a growing demand for solutions that address the increasing complexity of inference at scale. This article will explore some of the challenges of serving machine learning models in production. After a brief overview of existing solutions, it will take a closer look at Google’s TensorFlow-Serving system and investigate its capabilities. Note: Even though they may be closely related, this article will not deal with the training aspect of machine learning, only inference.
Inference and Serving
Before diving in, it is important to differentiate between the training and inference phases, because they have completely different requirements.
- Training is extremely compute-intensive. The goal here is to maximize the number of compute operations in a given time. Latency is not of concern.
- Inference costs only a fraction of the computing power that training does. However, it should be fast. When you query the model, you want the answer immediately. Inference must be optimized for latency and throughput.
There are two ways to deploy a model for inference. Which one to use largely depends on the use case. First, you can push the entire model to client devices and have them do inference there. Lots of ML features are already baked into our mobile devices this way. This works well for some applications e.g. for Face-ID or activity-detection on phones, but falls flat for many other, large-scale industrial applications. You probably won’t have latency problems, but you are limited to the client’s compute power and local information. On the other hand, you can serve the model yourself. This would be suitable for industrial-scale applications, such as recommender systems, fraud detection schemes, intelligent intrusion detection systems and so forth. Serving allows for much larger models, direct integration into your own systems and the direct control and insights that come with it.
Serving Machine Learning at Scale
Of course, it’s never that easy. In most “real-world” scenarios, there isn’t really such a thing as a “finished ML model”. Consider the “Cross-industry standard process for data mining”:
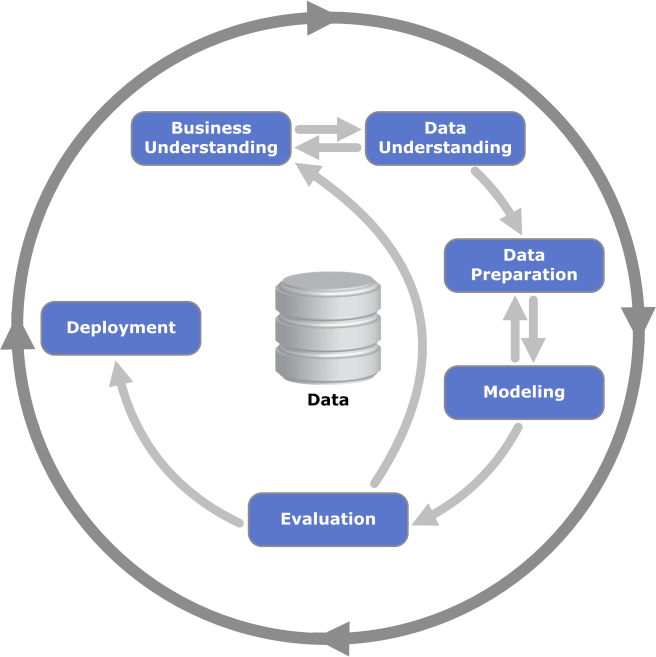
{kind=link}
It might be ancient, but it describes a key concept for successful data mining/machine learning: It is a continuous process [12]. Deployment is part of this process, which means: You will replace your productive models, and you will do it a lot! This will happen for a number of reasons:
- Data freshness: The ML model is trained on historical data. This data can go stale quickly, because new patterns constantly appear in the real world. Model performance will deteriorate, and you must replace the model with one that was trained on more recent data, before performance drops too low.
- Model revision: With time, retraining the model might just not be enough to keep the performance up. At this point you need to revise the model architecture itself, perhaps even start from scratch.
- Experiments: Perhaps you want to try another approach to a problem. For that reason you want to load a temporary, new model, but not discontinue your current one.
- Rollbacks: Something went wrong, and you need to revert to a previous version.
Version control and lifecycle management aren’t exactly new ideas. However, here they come with a caveat: Since artificial neural networks are essentially “clunky, massive databases” [5], loading and unloading them can have an impact on performance. For reference, some of the most impactful deep models of recent years are a few hundreds of megabytes in size (AlexNet: 240MB, VGG-19: 574MB, ResNet-200: 519MB). But as model performance tends to scale with depth, model size can easily go to multiple gigabytes. That might not be much in terms of “Big Data”, but it’s still capable of causing ugly latency spikes when implemented poorly. Besides ML performance metrics, the primary concerns are latency and throughput. Thus, the serving solution should be able to [4]:
- quickly replace a loaded model with another,
- have multiple models loaded at the same time, in the same process,
- cope with differences in model size and computational complexity,
- avoid latency spikes when new models are loaded into RAM,
- if possible, be optimized for GPUs and TPUs to accelerate inference,
- scale out inference horizontally, depending on demand.
Serving Before “Model Servers”
Until some three years ago, you basically had to build your ML serving solution yourself. A popular approach was (and still is) using Flask or some other framework to serve requests against the model, some WSGI server to handle multiple requests at once and have it all behind some low-footprint web-server like Nginx.
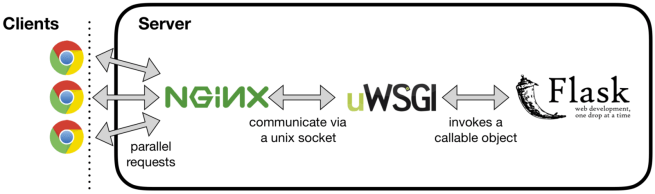
However, while initially simple, these solutions are not meant to perform at “ultra large” scale on their own. They have difficulty benefiting from hardware acceleration and can become complex fast. If you needed scale, you had to create your own solution, like Facebook’s “FBLearnerPredictor” or Uber’s “Michelangelo”. Within Google, initially simple solutions would often evolve into sophisticated, complex pieces of software, that scaled but couldn’t be repurposed elsewhere [1].
The Rise of Model Servers
Recent years have seen the creation of various different model serving systems, “model servers”, for general machine learning purposes. They take inspiration from the design principles of web application servers and interface through standard web APIs (REST/RPC), while hiding most of their complexity. Among simpler deployment and customization, model servers also offer machine learning-specific optimizations, e.g. support for Nvidia GPUs or Google TPUs. Most model servers have some degree of interoperability with other machine learning platforms, especially the more popular ones. That said, you may still restrict your options, depending on your choice of platform.
A selection of popular model serving and inference solutions includes:
- TensorFlow Serving (Google)
- TensorRT (Nvidia)
- Model Server for Apache MXNet (Amazon)
- Clipper
- MLflow
- DeepDetect
- Skymind Intelligence Layer for Deeplearning4j
TensorFlow-Serving
By far the most battle-tested model serving system out there is Google’s own TensorFlow-Serving. It is used in Google’s internal model hosting service TFS², as part of their TFX general purpose machine learning platform [2]. It drives services from the Google PlayStore’s recommender system to Google’s own, fully hosted “Cloud Machine Learning Engine”. TensorFlow-Serving natively uses gRPC, but it also supports RESTful APIs. The software can be downloaded as a binary, Docker image or as a C++ library.
Architecture
The core of TensorFlow-Serving is made up of four elements: Servables, Loaders, Sources and Managers. The central element in TensorFlow Serving is the servable [3]. This is where your ML model lives. Servables are objects, that TensorFlow-Serving uses for inference. For example, one servable could correspond to one version of your model. Servables can be simplistic or complicated, anything from lookup-tables to multi-gigabyte deep neural networks. The lifecycles of servables are managed by loaders, which are responsible for loading servables to RAM and unloading them again. Sources provide the file system, where saved models are stored. They also provide a list of the specific servables, that should be loaded and used in production, the aspired versions. Managers are the broadest class. Their job is to handle the full life cycle of servables, i.e. loading, serving and unloading the aspired versions. They try to fulfill the requests from sources with respect the specified version policy.
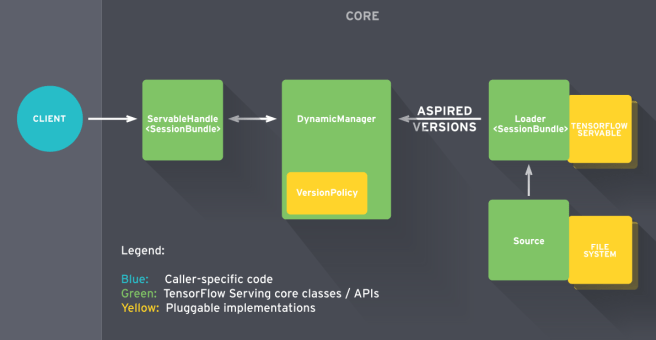
When a servable is elevated to an aspired version, its source creates a loader object for it. This object only contains metadata at first, not the complete (potentially large) servable. The manager listens for calls from loaders, that inform it of new aspired versions. According to its version policy, the manager then executes the requested actions, such as loading the aspired version and unloading the previous one. Loading a servable can be temporarily blocked if resources are not available yet. Unloading a servable can be postponed while there are still active requests to it. Finally, clients interface with the TensorFlow-Serving core through the manager. Both requests and responses are JSON objects.
Simple Serving Example
Getting started with a minimal setup is as simple as pulling the tensorflow/serving Docker image and pointing it at the saved model file [16]. Here I’m using a version of ResNet v2, a deep CNN for image recognition, that has been pretrained on the ImageNet dataset. The image below is encoded in Base64 and sent to the manager as a JSON object.

The prediction output of this model consists of the estimated probabilities for each of the 1000 classes in the ImageNet dataset, and the index of the most likely class.

Performance
Implementing and hosting a multi-model serving solution for an industrial-scale web application with millions of users, just for benchmarks, is slightly out of scope for now. However, Google provides some numbers that should give an idea of what you can expect TensorFlow-Serving to do for you.
Latency
A strong point of TensorFlow-Serving is multi-tenancy, i.e. serving multiple models in the same process concurrently. The key problem with this is avoiding cross-model interference, i.e. one model’s performance characteristics affecting those of another. This is especially challenging while models are being loaded to RAM. Google’s solution is to provide a separate thread-pool for model-loading. They report that even under heavy load, while constantly switching between models, the 99th percentile inference request latency stayed in the range from ~75 to ~150 milliseconds in their own TFX benchmarks [2].
Throughput
Google claims that the serving system on its own can handle around 100,000 requests per second per core on a 16 vCPU Intel Xeon E5 2.6 GHz machine [1]. That is however ignoring API overhead and model complexity, which may significantly impact throughput. To accelerate inference on large models with GPUs or TPUs, requests can be batched together and processed jointly. They do not disclose whether this affects request latency. Since late February (TensorFlow-Serving v1.13), TensorFlow-Serving can now work directly in conjunction with TensorRT [14], Nvidia’s high-performance deep learning inference platform, which claims a 40x increase in throughput compared to CPU-only methods [15].
Usage and Adoption
In their paper on TFX (TensorFlow Extended), Google presents their own machine learning platform, that many of its services use [2]. TFX’ serving component, TFS², uses TensorFlow-Serving. As of November 2017, TensorFlow-Serving is handling tens of millions of inferences per second for over 1100 of Google’s own projects [13]. One of the first deployments of TFX is the recommender system for Google Play, which has millions of apps and over a billion active users (over two billion if you count devices). Furthermore, TensorFlow-Serving is also used by companies like IBM, SAP and Cloudera in their respective multi-purpose machine learning and database platforms [2].
Limitations
Today’s machine learning applications are very much capable of smashing all practical limits: DeepMind’s AlphaGo required 1920 CPUs and 280 GPUs running concurrently in real-time, for inference, for a single “client” [6]. That example might be excessive, but the power of deep ML models does scale with their size and compute complexity. Deep learning models today can become so large that they don’t fit on a single server node anymore (Google claims that they can already serve models up to a size of one terabyte in production, using a technique called model sharding [13]). Sometimes it is worth investing the extra compute power, sometimes you just need to squeeze that extra 0.1 percent accuracy out of your model, but often there are diminishing returns,. To wrap it up, there may be a trade-off between the power of your model versus latency, throughput and runtime cost.
Conclusion
When you serve ML models, your return on investment is largely determined by two factors: How easily you can scale out inference and how fast you can adapt your model to change. Model servers like TensorFlow-Serving address the lifecycle of machine learning models, without making the process disruptive in a productive environment. A good serving solution can reduce both runtime and implementation costs by a significant margin. While building a productive machine learning system at scale has to integrate a myriad different steps from data preparation to training, validation and testing, a scalable serving solution is the key to making it economically viable.
References and Further Reading
- Olston, C., Fiedel, N., Gorovoy, K., Harmsen, J., Lao, L., Li, F., Rajashekhar, V., Ramesh, S., and Soyke, J. (2017). Tensorflow-serving: Flexible, high-performance ML serving.CoRR, abs/1712.06139
- Baylor, D., Breck, E., Cheng, H.-T., Fiedel, N., Foo, C. Y., Haque, Z., Haykal, S., Ispir, M., Jain, V., Koc, L., Koo, C. Y., Lew, L., Mewald, C., Modi, A. N., Polyzotis, N., Ramesh, S., Roy, S., Whang, S. E., Wicke, M., Wilkiewicz, J., Zhang, X., and Zinkevich, M. (2017). Tfx: A tensorflow-based production-scale machine learning platform. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’17, pages 1387–1395, New York, NY, USA. ACM.
- TensorFlow-Serving documentation – https://www.tensorflow.org/tfx/guide/serving (accessed 11.03.2019)
- Serving Models in Production with TensorFlow Serving (TensorFlow Dev Summit 2017) – https://www.youtube.com/watch?v=q_IkJcPyNl0 (accessed 11.03.2019)
- Difference Inference vs. Training – https://blogs.nvidia.com/blog/2016/08/22/difference-deep-learning-training-inference-ai/ (accessed 11.03.2019)
- Challenges of ML Deployment – https://www.youtube.com/watch?v=JKxIiSfWtjI (accessed 11.03.2019)
- Lessons Learned from ML deployment – https://www.youtube.com/watch?v=-UYyyeYJAoQ (accessed 11.03.2019)
- https://hackernoon.com/a-guide-to-scaling-machine-learning-models-in-production-aa8831163846 (accessed 11.03.2019)
- https://medium.com/@maheshkkumar/a-guide-to-deploying-machine-deep-learning-model-s-in-production-e497fd4b734a (accessed 11.03.2019)
- https://medium.com/@vikati/the-rise-of-the-model-servers-9395522b6c58 (accessed 11.03.2019)
- https://blog.algorithmia.com/deploying-deep-learning-cloud-services/ (accessed 11.03.2019)
- https://the-modeling-agency.com/crisp-dm.pdf (accessed 11.03.2019)
- https://ai.googleblog.com/2017/11/latest-innovations-in-tensorflow-serving.html (accessed 12.03.2019)
- https://developer.nvidia.com/tensorrt (accessed 12.03.2019)
- https://medium.com/tensorflow/optimizing-tensorflow-serving-performance-with-nvidia-tensorrt-6d8a2347869a (accessed 12.03.2019)
- https://medium.com/tensorflow/serving-ml-quickly-with-tensorflow-serving-and-docker-7df7094aa008 (accessed 12.03.2019)
- https://www.slideshare.net/shunyaueta/tfx-a-tensor-flowbased-productionscale-machine-learning-platform (accessed 12.03.2019)
Leave a Reply
You must be logged in to post a comment.