
There is a lot to say about Twitters infrastructure, storage and design decisions. Starting as a Ruby-on-Rails website Twitter has grown significantly over the years. With 145 million monetizable daily users (Q3 2019), 500 million tweets (2014) and almost 40 billion US dollar market capitalization (Q4 2020) Twitter is clearly high scale. The microblogging platform, publicly launched in July 2006, is one of the biggest players in the game nowadays. But what’s the secret handling 300K QPS (queries per second) and provide a real-time tweet delivery? Read about how Redis Clusters and Tweet Fanouts revolutionized the user’s home timeline.
Sidenote: In the past Twitter used Ruby in their backend system. Because of the dysfunctional garbage collector and loosely typed syntax they switched to the functional and object-oriented programming language Scala.
1. Pull and Push (different timelines)
There are two different approaches at Twitter: Pull- and push-based delivery. While the pull approach needs the device to pull content from an API or service, the push approach delivers timelines to the device without the device having to pull permanently via a socket connection. Targeted timelines are personalized by people one’s following while queried timelines generally are based on specific search criteria. There are different services assigned to different approaches, as seen in figure 1.
For the sake of completeness, let’s have a quick look into Twitter’s different timelines.
- User timeline: Totality of all one’s (re)tweets
- Home timeline: Totality of all the (re)tweets people post or like one person follows
- Search timeline: Totality of tweets based on searches
This blog post focuses on the user’s home timeline (pull based, targeted). Check the linked sources below if you want to know more about the other timelines and pushed based services like push notifications and follow streams.

2. Architecture Overview
Challenge: Around 400 million daily tweets seem to be a lot, but especially Twitter’s read-write ratio is special. In general, there are a lot more reads to handle than writes. 300K QPS (queries per second) are spent reading timelines and only 6000 requests per second are spent on writes. Especially with celebrities, tweets must reach several million people in a few seconds. Furthermore, there are a lot of complex rules on which content will be displayed in which timeline and how retweets, replies and mentions are handled. To meet this challenge, Twitter rebuilt large parts of its architecture in 2013. And consequently, more work is now being put into reading instead of writing processes.
How it works: Let us dive in this in order to understand how Twitter is handling a tweet from the beginning to the followers home timelines within seconds. As seen in figure 2, there is an API called write API, which is hit by the tweet after clicking on the send button. A quick HTTP response (after eliminating duplicated tweets by watching for the business logic of a tweet format in the HTTP header) will be returned to the client within 50 milliseconds to confirm a successful call (200). Due to the asynchronous nature of the process there is no need to maintain a permanent connection.
Next up is the so-called fanout which is responsible for spreading out the tweet to all people following the author by inserting it to all their home timelines. For caching all the home timelines, a bunch of Redis Clusters are used. The in-memory key-value store is one of the most important parts of Twitter’s architecture to deliver in real-time and its ability to scale. This timeline cache allows twitter to move the hard work away from the device and the sorting and merging process to be done in advance in the upstream cache. The device only has to pull its new timeline with help of the timeline service. Within 5 seconds, all the new tweets are displayed in the user’s home timeline at once. Although the goal is 5 seconds it can take up to 5 minutes, especially when celebrities like Lady Gaga or Kylie Jenner tweet, retweet and mention each other. As a result, sometimes the reply can arrive before the actual tweet is received. As you can see, there is a lot more work to do in regards of reading instead of writing processes – especially for people with millions of followers.
At the same time (after hitting the API) the tweet is also saved in Manhattan, a persistent database Twitter is using. More precisely, only small content like text or emojis are saved in Manhattan, larger data like pictures or videos is saved in a database called Blobstore.
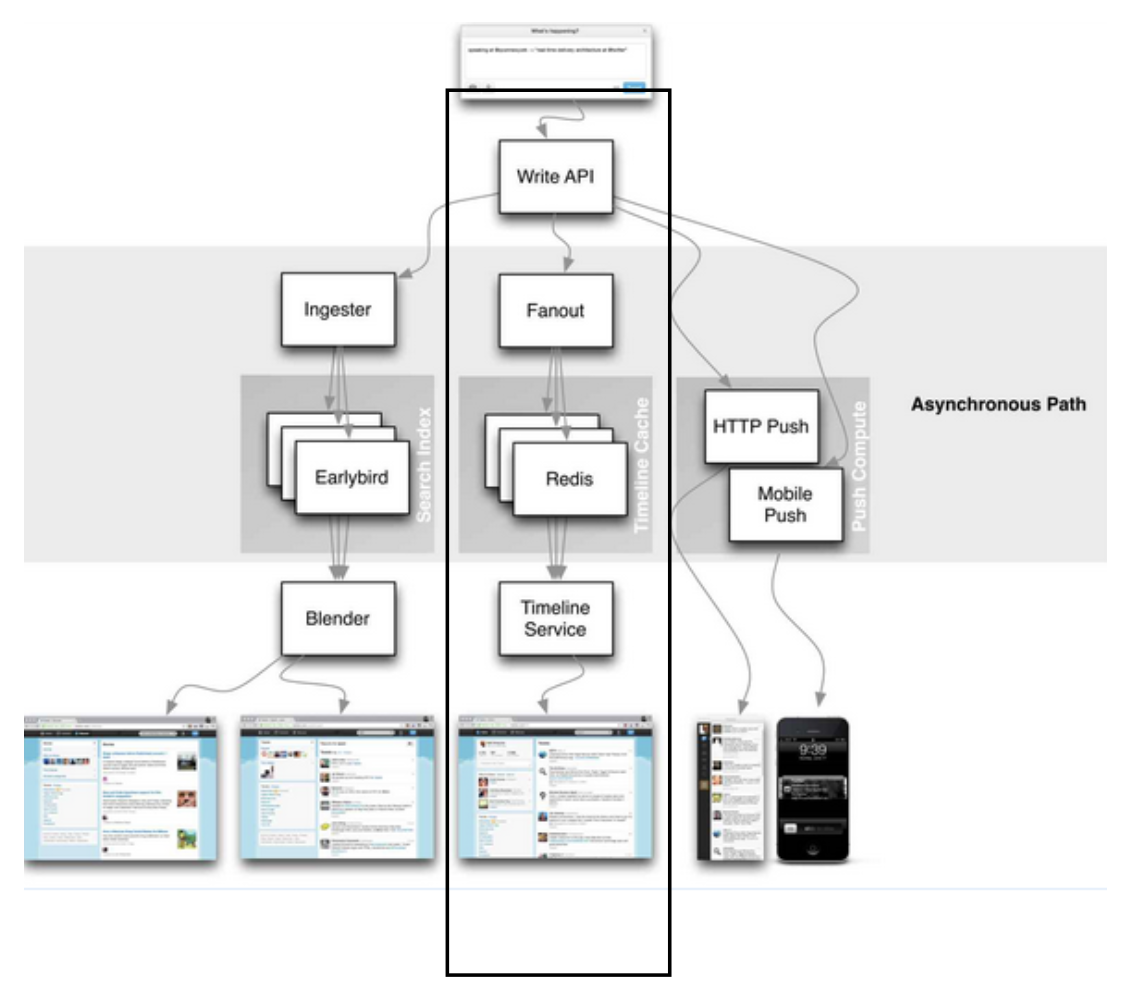
3. Fanout
After getting a first overview of the architecture, let’s have a closer look at the fanout logic and data caching. In the past Twitter has used Memcached servers to cache the tweet upstreams before delivering them to the users. Now they are using Redis Clusters for the caching process. Memcached, known as a key-value store, deals in binary blobs without further structured information. In contrast, Redis Clusters deal in structured data, which helps to be way faster and more efficient. Especially when it comes to appending new tweets to the home timeline, the native list structure of Redis is a perfect fit because parsing is expensive.
The user’s home timeline is stored three times in the clusters because of fault tolerance and redundancy reasons. In total around 300 tweets per timeline are held in cache, sorted by user ids. To check the relations in order to insert the tweet in the right home timelines, a social graph is used. The social graph contains information about users’ connections and relationships and is realized by a service called FlockDb (GraphDb). In general, FlockDb maintains the follower and followings lists. With the help of this tree-structured graph, it’s possible to filter out all the people following the tweet’s author.
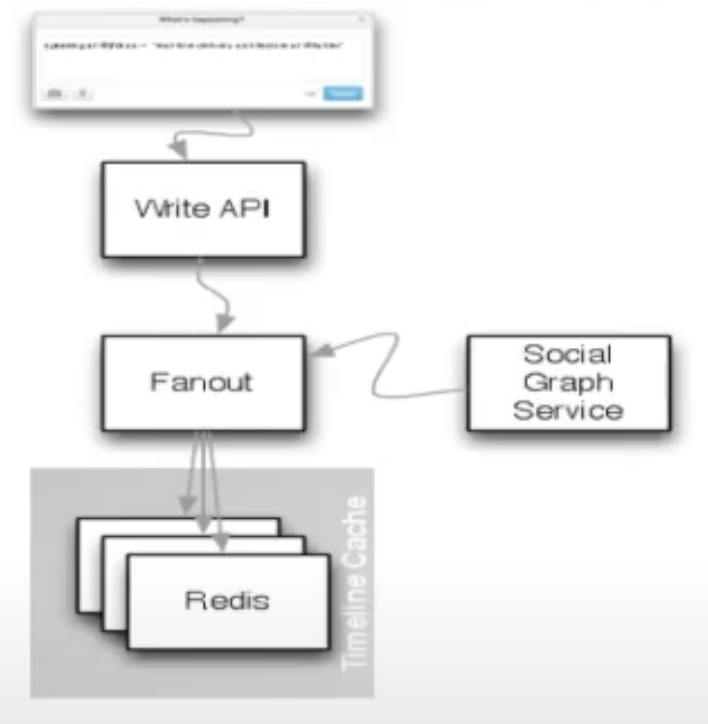
Every tweet is stored only by its unique tweet id, the author’s id and some additional bits to reduce unnecessary data and increase performance. Appropriately, Redis is really good at storing variable-length entries, so there’s no need for all these records to actually be the same length. Before pulling the updated home timeline to the device, the Timeline Service (in interaction with other services) is responsible for the final hydration.
Hydrated tweets are processed and ready for delivery. Regularly, the service composes the tweet from its user id, user icon, tweet text, geoinformation etc. within 50 milliseconds. If the user is inactive the process can take up to 3 seconds. Speaking of inactive users, the in-memory Redis Clusters only store home timelines of active users in the cache to save storage. So they act like LRU (least recently used) caches and throw out old data. In general, an active user is someone who was logged in within the last 30 days. If this is not the case, the process of reassembling and reconstructing the home timeline usually takes around 3 seconds. By querying the social graph service, Twitter checks which people the inactive user is following and subsequently hits the disk for every single one of them and shoves their home timeline back into Redis. Inactive users aren’t stored in RAM to keep latency low, too.
Good to know: In case your tweet is actually not a tweet but a retweet, Twitter can append the id of the original tweet to your retweet. When you retweet, you’re generating a new tweet with it’s own id behind the scenes, but it’s linked to the retweeted one.
4. Lessons learned
Although Twitter’s home timeline is only one part of Twitter’s real-time tweet delivery architecture, its impact is huge. This central part of the platform is one of the most important things in order to be able to scale, efficiently and to deal with the millions of users. Consequently, we can learn a lot about the way twitters engineers think and which decisions have been made. According to the principle „best of bread“ Twitter does not think much of standardized procedures but adapts itself actively to the circumstances and chooses the technology that fits the best. The need for bleeding edge scalability certainly supports this attitude.
Main learnings from the real-time tweet delivery architecture summarized:
- Be clear about your most important goal. Speed? Reliability? Correctness of data? Often you can’t get it all at once, especially when you scale.
- Check your write-read ratio before designing your architecture. Where do you need to put work in?
- Don’t get too attached to technologies or standards if they do not fit your problem (anymore).
- Consider exactly which data from which users really MUST be kept in the cache instead of simply storing everything.
- Think about high value users like celebrities etc. – They often show you the limits of your current infrastructure. Ask yourself how do you want to deal with those?
5. Conclusion
Obviously, Twitter did not scale from the beginning. Real time delivery always requires continuous adaptation and improvement to keep up with growing numbers. And sometimes it’s not real-time at all when Lady Gaga’s Tweets need to be received by 80 million followers. Also, it’s not that rare that tweet replies are delivered faster than the tweet itself. However, this is accepted in order to guarantee real-time delivery as good as possible. In conclusion, you can say that Twitter as one of the big player knows exactly where to put work in. This is the only way to guarantee Twitter’s unique selling proposition, which brings different people together to discuss topics from all over the world. Its extremely broad variety of topics, great user experience and easy way to tweet helps to stay up to date and connect, without losing focus and speed – the ultimate goal today and in future.
6. Main Sources
[1] http://highscalability.com/blog/2013/7/8/the-architecture-twitter-uses-to-deal-with-150m-active- users.html
[2] https://www.businessofapps.com/data/twitter-statistics/
[3] https://blog.twitter.com/engineering/en_us/topics/infrastructure/2017/the-infrastructure-behind-twitter-scale.html
[4] www.youtube.com/watch?v=J5auCY4ajK8 / http://www.infoq.com/presentations/Twitter-Timeline- Scalability
[5] https://stackshare.io/twitter/twitter
Leave a Reply
You must be logged in to post a comment.