ein Artikel von Nicolas Wyderka, Niklas Schildhauer, Lucas Crämer und Jannik Smidt

Projektbeschreibung
In diesem Blogeintrag wird die Entwicklung der Applikation- und Infrastruktur des Studienprojekts sharetopia beschrieben. Als Teil der Vorlesung System Engineering and Management wurde besonders darauf geachtet, die Anwendung nach heutigen Best Practices zu entwickeln und dabei kosteneffizient zu agieren
Bei sharetopia handelt es sich um eine Vermietungsplattform, in welcher Mieter und Vermieter von Produkten aller Art vermittelt werden. In der Anwendung kann ein Vermieter ein Produkt anlegen und es zur Vermietung freigeben. Der Mieter kann über eine Suche bestimmte Produkte finden und eine Mietanfrage an den Vermieter senden. Die Desktop-Webanwendung wurde dieses Semester im Rahmen der Vorlesung Web Application Architecture entwickelt. Dabei wurde als Framework im Frontend Vue.js und im Backend Spring verwendet.
Um eine zukunftssichere Anwendung für den Endbenutzer zur Verfügung zu stellen, ist eines unsere Hauptziele eine skalierbare und performante Lösung zu entwickeln. Dafür ist es das Ziel, ein Kubernetes Cluster für die einzelnen Services der Anwendung aufzubauen.
Zusätzlich soll eine effiziente CI/CD-Pipeline für dieses Cluster zur Verfügung stehen. Diese Pipeline soll nur beim erfolgreichen Absolvieren von Integrations- und Unit-Tests die Anwendung deployen. Zur bestmöglichen Unterstützung während der Anwendungsentwicklung, ist ein Ziel das Aufsetzen von Development, Staging und Production Environments, welche die CI/CD-Pipelines durchlaufen und anschließend in die Kubernetes-Cluster deployt werden sollen.
Um bei dem Deployment und der späteren Nutzung des Clusters eine übersichtliche Überwachung aller Vorgänge zu behalten, soll ebenfalls ein Logging Framework in die Anwendung integriert werden und diese Logs durch eine Logstash Pipeline weiterverarbeitet und analysiert werden können.
Da es sich bei dem Projekt um ein Studentenprojekt handelt, ist ein weiteres Ziel, die Kosten für die Infrastruktur möglichst gering zu halten und verschiedene Provider nach Kosten-Nutzung zu vergleichen.
Zusammengefasst ergeben sich folgende Ziele:
- Erstellung eines robusten Testing-Konzepts
- Deployment in einem Kubernetes Cluster
- Nutzung von CI/CD-Pipelines mit Environments
- Überwachung der Anwendung durch Monitoring und Logging Konzept
- Auswahl möglichst kosteneffizienter und standardisierte Technologien
Aufbau
Der folgende Blogartikel ist in die Kapitel Applikation und Infrastruktur aufgeteilt. Im ersten Teil wird zuerst auf die Architektur und die Auswahl der Technologien eingegangen. Dabei wird auch die Umsetzung des Testing-Konzepts beschrieben.
Im Kapitel Infrastruktur wird zuerst auf die Auswahl des verwendeten Cloud-Anbieters eingegangen und anschließend die Umsetzung der Infrastruktur-Ziele beschrieben. Dazu gehören der Aufbau einer CI/CD-Pipeline, das Aufsetzen eines Kubernetes Clusters, sowie die Umsetzung und Erstellung von Logging und Monitoring Konzepten zur Messung von Performance-Metriken.
Applikation
Architektur

Die Architektur der Webapplikation ist aufgeteilt zwischen einem Frontend und einem Backend. Diese zwei Komponenten kommunizieren mittels HTTP-Requests. Das Frontend besteht aus einer Multipage-Applikation, welche mit Vue.js erstellt wurde. Innerhalb des Frontends wird ebenfalls TailwindCSS verwendet, um ein Responsive Design zu ermöglichen. Innerhalb der Vue.js Applikation werden HTTP-Requests an das Backend gesendet, um Daten zu persistieren oder abzurufen. Das Backend setzt eine Microservice-Architektur um, welche mithilfe von Kubernetes verwaltet wird. Dies ermöglicht eine gute separation-of-concern zwischen den verschiedenen Services. Insgesamt gibt es vier verschiedene Services, den Product-Service, den Search-service, den User-Service und den Payment-Service. Jeder dieser Services ist ein separater Pod in dem Kubernetes-Cluster und kann unabhängig von den anderen Services verwaltet und gewartet werden. Die Services sind Java-Spring Applikationen und stellen die benötigten Endpunkte für das Frontend bereit. Für die Persistierung der Daten existieren zwei Datenbanken, eine NoSQL-Datenbank, um die Inserate der Benutzer zu speichern und eine SQL-Datenbank für Bezahlungen. Für eine schnelle Suche in der NoSQL-Datenbank wird ebenfalls ein ElasticSearch-Container gehostet.
Für die Authentifizierung wird der externe Service Cognito von AWS genutzt. Cognito stellt alle wichtigen Funktionen, sowie die Erstellung von Tokens für die HTTP-Requests bereit. Gleichzeitig stellt es die Sicherheit der Userdaten sicher. Rich Content und Mediendateien werden in einem S3-Bucket von AWS gespeichert.
Technologien
Frontend
Das Frontend wurde mit dem Framework Vue.js der Version 3.0 entwickelt. Als Programmiersprache wurde TypeScript verwendet. Vue.js ist ein clientseitiges JavaScript-Web-Framework. Es ist leicht zugänglich, leistungsfähig und ein sehr vielseitiges Framework für die Erstellung von Webanwendungen und Benutzeroberflächen. Dadurch eignet sich Vue.js nicht nur für die Erstellung von Single-Page-Webanwendungen, sondern auch für komplexere und vielschichtigere Webanwendungen. Dabei baut Vue.js auf HTML, CSS und Javascript auf und stellt dem Programmierer ein deklaratives und komponentenbasiertes Programmiermodell bereit.
Vorteile
Vue.js bietet sehr viele Vorteile für Entwickler, sowie auch für die Nutzer. Es ist sehr leichtgewichtig und hält die Dateigröße aller erstellten Build-Dateien nach dem Kompilieren sehr gering, wobei es aber sehr flexibel bleibt. Bei Änderungen auf einer Seite werden nur die Teile neu gerendert, welche sich auch geändert haben. Für Entwickler ist es einfach zu lernen und auch zu benutzen. Eine Typescript Dokumentation ist enthalten und dank der Composition API wird der Code sehr übersichtlich gehalten.
Nachteile
Bei unserer Entwicklung mit Vue.js hatten wir größtenteils positive Erfahrungen, dennoch lassen sich auch negative Punkte anmerken. Eines unserer Hauptprobleme war die rapide Weiterentwicklung des Frameworks. Gerade weil wir die neueste Version 3 von Vue.js genutzt haben, welche es erst seit wenigen Wochen gibt. Dadurch war die Dokumentation für neue Funktionen oft sehr mangelhaft oder veraltet und third Party Bibliotheken eher spärlich verfügbar. Am Ende des Semesters wurde dann von Vue eine komplett neue Dokumentation veröffentlicht, welche wir uns schon zu Beginn unseres Projektes gewünscht hätten.
Composition API
Durch die neu vorgestellte Composition API ergab sich eine neue Best Practice innerhalb von Vue.js. Es handelt sich dabei um die Nutzung der composition Functions (oder auch useFunctions genannt). Im Vergleich zu der herkömmlichen Options API können so große Teile der Logik in den Komponenten in die composition Functions ausgelagert werden. Dadurch können Logikabschnitte wiederverwendet werden und der Logikanteil in den Komponenten wird verkleinert. Vergleichbar ist dies mit den Services von Angular.
Komponenten
Vue.js verwendet Komponenten, welche es ermöglichen, benutzerdefinierte Inhalte und Logik zu kapseln. Prinzipiell ist eine Komponente eine Abstraktion, die es uns ermöglicht, umfangreiche Anwendungen zu erstellen, die aus kleinen, in sich geschlossenen und oft wiederverwendbaren Komponenten bestehen.

Im Fall von unserem Projekt wurde zwischen drei verschiedenen Komponententtypen unterschieden. Die Screen-Komponenten geben das Layout der Seite vor, die Logik Komponenten erfüllen bestimmte Aufgaben wie z.B. ein Suchergebnis anzeigen und die UI-Komponente ist eine lediglich anzeigende Komponente ohne Logik wie z.B. ein Button.
Single File Components (SFC)
Eine weit verbreitete Best Practice von Vue ist die Nutzung der *.vue-Files, welche sowohl das Template (HTML), die Logik (JavaScript bzw. TypeScript) und CSS Code bündeln. Diese Files werden vom SFC-Compiler in ein Standard JavaScript (EC) Module pre-compiled, wodurch diese Files wie andere Module importiert werden können.
Lessons learned
Zu Beginn des Semesters erschien uns Vue.js in der Version 3 als die richtige Wahl, aufgrund der neuen Unterstützung für Typescript, sowie der neuen Composition API. Im Nachhinein kann jedoch gesagt werden, dass es auch Nachteile mit sich gebracht hat, diese zeitgleich mit dem Release von Version 3 zu verwenden.
Ein Nachteil dabei war, dass viele Third-Party-Libraries noch keine Unterstützung für die Version 3 lieferten, bzw. Typescript nicht unterstützt wurde. Ein Beispiel hierfür ist die DatePicker Komponente, welche die Third-Party-Library v-calendar nutzt. Bei dieser waren wir gezwungen, die Alpha-Version zu verwenden, weil noch keine stabile Version für Version 3 existiert. Aufgrund der nicht stabilen Version kam es auch zur Situation, dass die Komponente von einem auf den anderen Tag nicht mehr funktionierte. Glücklicherweise wurde sie in einer Wrapper-Komponente implementiert, wodurch die Third-Party-Library nur an einer Stelle ausgetauscht werden musste.
Ebenfalls war ein größeres Problem die fehlende und sich häufig ändernde Dokumentation des Frameworks. Dazu kam die sehr geringe Informationsdichte zu neuen Features des Frameworks in Foren wie Stackoverflow hinzu, welche das Entwickeln bei Problemen deutlich verlangsamt hat.
Backend
Spring
Spring ist ein populäres modulares Framework aus der Java Welt. Spring’s wichtigstes Feature ist hierbei die Dependency Injection. Dependency Injection ist ein Software Design Pattern, welches dem Inversion of Control Prinzip folgt. Inversion of Control verschiebt den Kontrollfluss, der für das Instanziieren von Klassen benötigt wird, vom eigentlichen Applikations-Code zum Framework. Dependency Injection im Fall von Spring sorgt dafür, dass Abhängigkeiten von einer Klasse zu anderen Klassen automatisch vom Framework aufgelöst werden. Dadurch kann “Glue-Code” für “Creational-Patterns” z. B. dem “Factory-Pattern” reduziert werden. Gleichzeitig wird das Testen der Anwendung dadurch eleganter: Unit-Tests von in der Applikation eigentlich abhängigen Klassen können dadurch einfach unabhängig durchgeführt werden. Eine abhängige Klasse kann von einer alternativen Klasse, die das gleiche Interface implementiert, mit Mock-Properties/Methoden im Dependency Container für den Unit-Test überschrieben werden. In Spring können derartige Abhängigkeiten zwischen sogenannten Beans (Objekte, die von Spring instanziiert werden) ganz einfach über die @Autowire Annotation deklariert werden.
Spring bietet darüber hinaus je nach Anwendungszweck noch zahlreiche weitere Module, die die sich idiomatisch in Spring’s Paradigmen einfügen und eine hohe Entwickler-Produktivität schaffen. In unserem Fall haben wir auf Spring Web gesetzt. Spring Web baut auf dem Tomcat Webserver auf und ermöglicht das Bauen von HTTP basierten APIs mit Spring. Hierbei liegt der Fokus in Tradition des Schichtenmodells auf der Trennung von Darstellung (-> Controller), Business (-> Service) und Daten (-> Repository) Logik. Spring bietet auch hierfür wieder praktische Annotations z.B. @RestController zum Erstellen eines Rest-Controllers für eine Ressource, dessen Methoden mit weiteren Annotations für Path/Method-Mappings dekoriert werden können.
Wir haben uns für den Product Service für Spring Boot Web mit Kotlin und Gradle entschieden. Grund hierfür ist, dass Spring Boot Web standardmäßig viele Funktionen bietet, die wir für den Product Service nutzen wollten. Dazu zählen unter anderem Dependency Injection, Rest Controller sowie die Möglichkeit zusätzliche Features aus entwickelten idiomatischen externen Bibliotheken nachzuinstallieren (z.B. Cognito Authentifizierung oder MongoDB Repositories). Da zuvor noch niemand von uns mit Spring gearbeitet hatte und wir eines der populärsten Frameworks aus der Microservice-Welt kennenlernen wollten, war dies ein weiterer Grund für die Auswahl von Spring. Eine valide Alternative mit ungefähr äquivalentem Feature-Set wäre zum Beispiel das populäre Node.js Framework NestJS gewesen, jedoch haben wir mit der ad-hoc type safety von TypeScript und dem allgemein teilweise mangelhaften TypeScript Support der Node.js Welt schlechte Erfahrungen gemacht. Deshalb haben wir uns lieber für eine Programmierumgebung mit nativer type-safety entschieden.
Bei Spring haben uns für Kotlin statt Java entschieden, da Kotlin ebenfalls von Spring nativ unterstützt wird und weil wir uns von Kotlin durch die elegantere Syntax eine höhere Entwickler-Produktivität versprochen haben. Kotlin ist eine relativ moderne Programmiersprache, die von den Entwicklern der IDE IntelliJ Jetbrains entwickelt worden ist und im Gegensatz zu Java mehr Syntactic Sugaring bietet. Weiterhin forciert sie im Vergleich zu Java die klassischen OOP Patterns nicht so stark. Kotlin ist interoperabel mit Java und kompiliert ebenfalls zu Bytecode für die JVM. Wir haben uns für Gradle statt Maven als Build Automation Tool entschieden, da uns Gradle bereits aus der Entwicklung von Android Apps bekannt war.
Nachfolgend ist die Schichtenunterteilung innerhalb unseres Spring-Projekts dargestellt, die dem bereits erwähnten Controller-Service-Repository Pattern folgt.
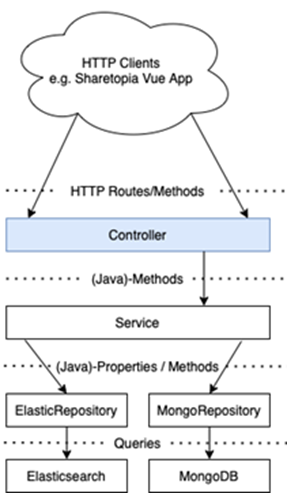
Die einzelnen Schichten übernehmen dabei die folgenden Aufgaben:
- Controller Layer: Stellt Funktionalität nach außen in Form einer HTTP-basierten API zur Verfügung, die von Clients, in Form unseres Frontends, aufgerufen werden kann
- Service Layer: Enthält die Businesslogik und wird durch den Controller aufgerufen
- Repository Layer: Dient als Abstraktion zum Speichern und Abrufen von Daten aus den Datenhaltungssystemen MongoDB und Elasticsearch. Wird vom Service Layer aufgerufen.
MongoDB
Als zentrale Datenbank für unsere Anwendung haben wir uns für die dokumentenorientierte NoSQL Datenbank MongoDB entschieden. Diese speichert sogenannte Dokumente und eignet sich besonders gut für das Speichern von denormalisierten Dokumenten mit fest definierten Access Patterns.
Ein zentraler Grund für die Verwendung von einer NoSQL DB wie MongoDB war, dass wir unseren Entwicklungsprozess eher agil gestalten wollten und unsere Daten daher nicht von Anfang an einem festen Schema unterliegen sollten, um so auf sich ändernde Anforderungen reagieren zu können. So konnten wir während der Entwicklung z.B. den Produkt-Inseraten unkompliziert neue Felder hinzufügen, ohne dabei durch ein Datenbankschema eingeschränkt zu sein.
Neben diesem Vorteil bietet MongoDB Sharding- und Replikations-Features, die es ermöglichen, dass MongoDB bei korrekter Nutzung (fast) unendlich horizontal skalieren kann und gleichzeitig eine sehr hohe Verfügbarkeit gewährleistet werden kann. Da es sich hierbei um ein studentisches Projekt handelt, war diese Tatsache zwar nicht direkt relevant, könnte in der Realität bei einem Betrieb einer solchen Anwendung von Bedeutung sein.
Letztendlich haben wir in unserer Anwendung keine eigenen Queries auf die MongoDB Datenbank definiert, sondern nutzen das mongo-spezifische Repository Interface von Spring, welches für uns die Implementierung der gewünschten Datenbank-Abfragen abstrahiert.
ELK Stack
In unserem Projekt kommen alle drei Komponenten des ELK Stacks zum Einsatz. Diese sind Elasticsearch, Logstash und Kibana. Die folgenden Use Cases für diese Technologien waren hierbei als Motivation für die Nutzung des ELK Stack ausschlaggebend:
Zentrale Suche innerhalb der Anwendung
Ein zentraler Bestandteil unserer Vermietungsplattform sollte eine Suchfunktion über die Titel der Produkt-Inserate und die Tags der Produkte sein. Eine Darstellung dieser Suche ist in der folgenden Abbildung zu sehen:

Zwar könnten wir hierbei bis zu einem gewissen Grad auch über die gespeicherten Produkte in unserer MongoDB Hauptdatenbank suchen, jedoch ist man im Vergleich zu speziell auf diesen Use-Case zugeschnittenen Lösungen doch eher eingeschränkt. Aus diesem Grund haben wir uns dazu entschieden Elasticsearch zu verwenden, was eine sehr populäre Search- und Analyseengine ist. Diese verspricht, große Datenmengen von Dokumenten nahezu in Echtzeit durchsuchen zu können und bieten viele weitere Features wie z.B. Fuzzy Search, die mit Typos umgehen kann oder Search-as-you type autocomplet Suchmöglichkeiten über einen Index. Die hohe Performance bei der Volltextsuche von Elasticsearch wird dabei dadurch erreicht, dass die abgespeicherten Dokumente nicht direkt durchsucht werden, sondern ein sogenannter invertierter Index gebildet wird. Dieser gibt für jeden Begriff an, in welchen Dokumenten dieser vorkommt, wodurch sehr performant die zur Suche passenden Dokumente gefunden werden können. Weiterhin können die Begriffe bei der Indizierung weiteren Operationen und Transformationen durch die Definition eines sogenannten Analyzers unterzogen werden. Dies könnte z.B. ein sogenannter Normalizer sein, der unterschiedliche Formen desselben Worts auf eine normalisierte Form abbildet, um dieses Wort später zuverlässiger finden zu können. Ein solcher Analyzer innerhalb unseres Projekts ist in der folgenden Abbildung zu sehen:

Eine wichtige Bedingung für die Nutzung von Elasticsearch war, dass diese neben der Volltextsuche datumsbasierte und geobasierte Abfragen unterstützt.
Diese Bedingung ergibt sich daraus, dass bei der Suche nach Produktinseraten auch ein Verfügbarkeitszeitraum und ein Suchradius um eine bestimmte Stadt angegeben werden können sollte. Da solche Abfragen durch Elasticsearch ermöglicht werden, deckt diese Searchengine alle unsere Anforderungen ab.
Damit die Suche immer auf dem aktuellsten Datenbestand der Produktinserate durchgeführt wird, haben wir uns dazu entschieden, die Daten konzeptuell von der MongoDB Hauptdatenbank stets in den entsprechenden Elasticsearch Index zu spiegeln. Da hierbei die kompletten Produktdaten im Elasticsearch Index gespeichert werden, wird für die Suche selbst keine Beteiligung der MongoDB benötigt.
Wie auch bei MongoDB nutzen wir hier auch wieder das Elasticsearch spezifische Repository Interface ElasticsearchRepository, das durch Spring bereitgestellt wird und den Zugriff auf den Index abstrahiert. Nur für einzelne sehr komplexe Queries greifen wir in unserem Code via Elasticsearch-Syntax auf den Index zu.
Verarbeitung von Logs
Basierend auf dem zuvor beschriebenen Use Case waren wir uns schon relativ zu Beginn des Projekts sicher, dass wir Elasticsearch verwenden möchten. Da Elasticsearch Teil des ELK-Stacks ist, lag für uns die Idee nahe, auch die anderen Komponenten des ELK Stacks im Rahmen der System Engineering und Management Vorlesung einzubeziehen und zu überprüfen, wie diese uns beim Analysieren der Anwendungs-Logs unterstützen können und mit welchem Aufwand der Aufbau einer solchen Pipeline verbunden ist.
Im Speziellen stehen das L und K innerhalb des ELK-Stacks dabei für die Data-Processing-Pipeline Logstash und die auf Elasticsearch aufbauende Analyseplattform Kibana. Im Prinzip können wir mit Logstash die Logs unserer Anwendung weiterverarbeiten und durch Filterung besser auswerten, da wir die enthaltenen Felder separat parsen. Da wir diesen Output dann in Elasticsearch speichern, können wir die entsprechenden Indizes mit Kibana analysieren und so unsere Log-Daten besser verstehen.
Wie wir diese beiden Tools eingebunden und verwendet haben, zeigen wir dabei im Infrastruktur-Kapitel unter dem Punkt “Logging” genauer.
Testing
Backend
Beim Testing im Backend haben wir uns an die von Ham Vocke abgeleiteten Prinzipien aus der Testing-Pyramide von Mike Cohn orientiert.[10]

Diese Prinzipien lauten wie folgt:
- Schreibe Tests mit unterschiedlicher Granularität
- Je mehr “High-Level” die Tests sind, desto weniger Tests sollten auf diesem Level vorhanden sein
Daraus haben wir abgeleitet, dass wir für unsere Anwendung sowohl Integrations-Tests (in Pyramide als Service Tests bezeichnet) und lower-level Unit-Tests schreiben wollen. Wie durch die Prinzipien definiert, soll die Anzahl der isolierten, schnell auszuführenden Unit-Tests dabei größer sein als die der eher langsamen und aufwendigen Integration-Tests.
Initial haben wir uns zuerst auf das Schreiben von Integrations-Tests fokussiert.
Aus unserer Sicht lässt sich bei dieser Testart das größte Vertrauen in die korrekte Funktionsweise der Anwendung gewährleisten, da hierbei alle Komponenten der Anwendung instanziiert und verwendet werden. Die API wird dann durch tatsächliche HTTP-Requests abgefragt. Dadurch, dass hierbei nur wenige Teile der Daten als Setup für die Tests im Voraus modelliert werden müssen, wird eine Überspezifikation der Tests vermieden und so nah wie möglich an den „Realbedingungen“ der Anwendung getestet. Implementiert man solche (positive und negative) Integration-Tests für alle Routen, erhält man einen fundierten Überblick darüber, ob die Anwendung den Nutzern die gewünschte Kernfunktionalität zur Verfügung stellen kann oder ob eventuelle Fehler dies behindern.
Mit der Annotation @SpringBootTest für unsere Test-Klasse stellt uns Spring komfortabler Weise einen speziellen Application-Context für das Testing bereit. Somit können wir wie gewünscht alle Layer unserer Anwendung analog zum Produktivbetrieb nutzen und das korrekte Zusammenspiel dieser sicherstellen. Als Testing-Framework wurde an dieser Stelle JUnit 5 verwendet, welches Teil der spring-boot-test-starter Dependency ist.Ein beispielhafter Integrationstest für die Route in unserem ProductController im Spring-Projekt, welche ein neues Produkt-Inserat erstellt, ist in den nachfolgenden zwei Abbildungen gezeigt.


Zuerst nutzen wir einen Testuser, um uns bei der Anwendung anzumelden, d.h. einen Access-Token zu erhalten. Dieser steht allen Testmethoden zur Verfügung. In der eigentlichen Funktion „should create new product” wird durch prepareProductRequest()ein DTO-Produkt-Objekt (DTOs = Data Transfer Objects) zur Verfügung gestellt, welches durch die Route in der Anwendung gespeichert werden soll. Anschließend wird der HTTP-Header und die HTTP-Entity erzeugt, welche den erwähnten Access-Token für die Autorisierung des Nutzers verwendet. Mit den genannten Daten wird der Endpunkt für das Erstellen eines Produktes aufgerufen. Für die erhaltene Response werden dann verschiedene Bedingungen für ein erfolgreiches Testergebnis überprüft, wie z.B. dass die Daten im zurückgegebenen (in der Datenbank gespeicherten) Produkts den übergebenen Daten des DTOs entsprechen.Auch wenn unser initialer Fokus wie bereits angemerkt auf solchen Integrations-Tests lag, wollten wir ja entsprechend der Test-Pyramide und der daraus abgeleiteten Prinzipien unserem Projekt weitere Tests mit einer anderen Granularität hinzufügen.
Daher haben wir für unsere unter den Controllern liegenden Service-Klassen Unit-Tests mit JUnit 5 als Testing-Framework geschrieben. Diese Service-Klassen kapseln einen Teil der Business-Logik unserer Anwendung und stellen Methoden bereit, auf welche die Routen zugreifen können, um den entsprechenden Request abzuarbeiten. Einige dieser Methoden enthalten nur relativ wenig eigene Logik, da durch das Repository und die zugehörige Datenbankabfrage bereits die passenden Daten für die gewünschte Response zurückgeliefert werden. Das unten stehende Code-Snippet zeigt eine solche Funktion im ProductService:

An diesen Stellen erscheint uns das Schreiben von Unit-Tests für diese Services als eher redundant, da durch den Integrations-Test bereits sichergestellt ist, dass die Response den Anforderungen entspricht.
Bei Funktionen, welche eine komplexere Logik implementieren, können solche Tests unserer Ansicht nach durchaus sinnvoll sein. Man kann in diesen Fällen eine Vielzahl von Test-Cases für einzelne Funktion schreiben (z.B. um mögliche Randfälle abzudecken), ohne dabei jedes Mal die gesamte Anwendung zu starten und wirklich einen Request senden zu müssen. Dadurch sind diese Tests deutlich schneller und weniger aufwendig in der Ausführung.
Das isolierte Testing wird dabei durch das Mocking beteiligter externer Komponenten (z.B. Repositories) erreicht. Hierfür haben wir in unserem Projekt das Mocking-Framework Mockito verwendet. Durch die Unit-Test-Cases kann dann sichergestellt werden, dass sich die einzelnen getesteten Funktion stets erwartungskonform verhalten und Fehler können durch das Testen solcher einzelnen Einheiten schneller identifiziert werden.
Der Nachteil ist an dieser Stelle, dass diese komplexeren Funktionen in den Service-Klassen häufig mehrere Funktionen anderer Services und/oder Repositories verwenden und diese, wie bereits angemerkt, gemockt werden müssen. Dadurch ist tendenziell mehr Code für das Setup der Tests nötig als bei den Integration-Tests. Ein beispielhafter Unit-Test für die save() Funktion ist in dem untenstehenden Code-Ausschnitt gezeigt.

Wir erstellen zuerst einen User der gespeichert werden soll. Anschließend definieren wir, was der Rückgabewert der save() Funktion des gemockten UserRepository sein soll. Nun folgt mit userService.save(…) der eigentliche Aufruf der zu testenden Funktion. Da diese Funktion das Ergebnis der save() Funktion des gemocketen UserRepository direkt zurückgibt, sind wir hier nicht unbedingt daran interessiert den Rückgabewert mithilfe von Assertions zu überprüfen. Stattdessen verifizieren wir mit dem verify Aufruf, dass innerhalb der userService.save() Funktion das Repository genau einmal mit den richtigen Parametern aufgerufen wird. Ist dies gegeben, wird der User also korrekt an das Repository für die Speicherung in der Datenbank weitergegeben.
Bei Funktionen, bei denen der Rückgabewert nicht einfach das Ergebnis einer Repository-Funktion ist, haben wir dagegen vor allem wieder auf Assertions bezüglich des Rückgabewerts gesetzt, um die korrekte Funktionsweise zu testen.
Frontend
Da wir eine komplette Test Coverage für unser Projekt erreichen wollten, haben wir nicht nur alle Backend Funktionen testen wollen, sondern auch unser Vue.js Frontend. Für das Testen im Frontend gibt es insgesamt drei Arten von Tests mit stark ansteigender Komplexität.
Die einfachsten, schnellsten und am häufigsten angewendeten Tests sind auch hier wieder die Unit Tests. Wie bereits im Backend werden mit den Unit Tests die Eingaben in eine bestimmte Funktion, Klasse, oder auch Fall von Vue.js auch in eine Composable Function, auf die erwarteten Ausgaben und Seiteneffekte überprüft.
Die nächste Stufe sind die Component Tests. Component Tests überprüfen, ob die Components von Vue.js richtig gemounted und gerendert werden. Zusätzlich dazu überprüfen sie, ob mit der Component interagiert werden kann und ob sie sich bei der Interaktion wie erwartet verhält. Man merkt hier aber direkt, dass die Component Test deutlich komplexer sind als die Unit Tests und mehr Code importieren müssen. Daraus folgt auch ein größerer Zeitaufwand bei der Ausführung.
Die letzte Testart und auch die aufwändigste sind End-to-End Tests. Diese überprüfen Funktionen, die sich über mehrere Seiten erstrecken und echte Netzwerkanfragen an produktive Vue Anwendungen stellen. Außerdem benötigen End-to-End Tests häufig schon aufgesetzte Datenbanken und ein laufendes Backend.
Mit dem Wissen über die möglichen Arten des Testings im Frontend, haben wir uns dazu entschieden, unseren Fokus auf die Unit und Component Tests zu legen. Diese Entscheidung wurde daher getroffen, da sich zur Zeit der Entwicklung noch kein laufendes Backend zur Verfügung stand und End-to-End Test zu aufwändig für ihren letztendlichen Nutzen für die Entwicklung sind.
Da die Businesslogik einer Webanwendung hauptsächlich im Backend bzw. auf Serverseite befinden soll, war die Anzahl der zu testenden Funktionen im Frontend eher gering. Ebenfalls verfolgt Vue.js das Model-View-Viewmodel (MVVM) Pattern, wobei Vue.js die Viewmodel Schicht repräsentiert. Dadurch sollen die Vue Components lediglich die View dynamisch aktualisieren und den Input verarbeiten, aber keine größere Logik beinhalten.
Um unseren Code in Vue.js testen zu können, wird noch ein zusätzlich Javascript-Test-Framework benötigt. Wir haben uns dafür drei unterschiedliche Testsuites angeschaut und miteinander verglichen.
Das erste Test-Framework war Jest, welches seinen Fokus auf Einfachheit und Schnelligkeit gelegt hat. Jest bietet auch eine einfache Integration in alle üblichen Javascript Frameworks wie React, Angular und Vue an, sowie einen Typescript Support.
Jest bietet ebenfalls einen integrierten Custom Resolver für Imports im Code an, was ein einfaches Mocking von Funktionen und Packages ermöglicht. Es funktioniert sehr gut auch ohne Konfiguration und die Entwickler stellen eine saubere und gepflegte Dokumentation bereit.
Das zweite Test-Framework war Mocha. Mocha ist ein feature-rich Test-Runner, der auf Node.js läuft. Da Mocha ein Test-Runner ist, benötigt es andere Bibliotheken für das eigentliche Testen. Dadurch bietet es aber auch ein hohes Maß an Flexibilität bei der Testentwicklung. Eine der am häufigst verwendeten Bibliotheken mit Mocha ist Chai, eine assertion library ebenfalls für Node.js.
Das letzte Test-Framework namens Vitest stammt direkt aus dem Hause Vue. Vitest basiert wie das CLI Tool create-vue ebenfalls auf VITE und kann dadurch dieselbe Konfiguration- und Transformation-Pipeline direkt von Vite nutzen. Da es wie bereits erwähnt direkt von dem Vue und Vite Team entwickelt wird, lässt es sich mit minimalem Aufwand in Vue.js integrieren und ist dadurch auch sehr schnell. Da Vitest speziell für Vue entwickelt wird, sind die bereitgestellten Tools für das Testen der Composables und Components sehr gut angepasst. Der große Nachteil von Vitest war aber, dass es erst im Dezember 2021 in einer sehr frühen Alpha Version erschienen ist und zum Start unseres Projektes noch nicht verfügbar war.
Nachdem wir die drei Frameworks miteinander verglichen haben, wäre unsere erste Wahl auf Vitest gefallen. Da Vitest aber wie erwähnt noch nicht released war und erstmal in eine sehr frühe Alpha Phase kam, haben wir uns für unsere zweite Wahl entschieden: Jest. Unsere Entscheidung ging hauptsächlich von dem Punkt aus, da Jest bereits alle relevanten Funktionen in einem Framework beinhaltete und für uns wichtige Mock Funktionen bereits beinhaltet sind.


Infrastruktur
Auswahl Cloud-Anbieter
Bevor auf die Auswahl des Cloud-Anbieters eingegangen wird, wollen wir kurz beschrieben, wieso wir Container und Orchestrierung genutzt haben.
Als Entwickler möchte man seine Anwendung möglichst zuverlässig und portabel auf einer breiten Masse von Computern deployen können. Hierbei helfen Tools zum “Packagen” der Anwendung. Dieses Package sollte hierbei alle nötige Software enthalten, die benötigt wird, um die Anwendung auszuführen. So kann man zum Beispiel ein VM Image mit der Anwendung und aller benötigter Software vorinstalliert erstellen oder alternativ ein Container Image mit der Anwendung und aller benötigter Software bauen.
Container haben den Vorteil, dass sie im Vergleich zu VM Images hardware-unabhängiger deployed werden können, weil sie keinen Linux Kernel mit Treibern etc. beinhalten. Container-Engines, wie Docker, nutzen stattdessen Linux Kernel Funktionalität wie CGroups und Namespaces zum Zuweisen und Isolieren von Ressourcen.
Die meisten Systeme bestehen jedoch aus mehreren Anwendungen. Das aktuell populäre Micro-Service Architektur Pattern verstärkt diesen Effekt noch weiter. Diese Services benötigen Zugriff auf unterschiedliche Ressourcen, es bestehen unterschiedliche Erwartungen an die Verfügbarkeit, Services müssen untereinander kommunizieren können und sich gegenseitig finden etc. Container Orchestrator nehmen hierbei mithilfe von Software-Layern und Abstraktionen viel administrative Arbeit ab, die normalerweise benötigt werden würde, um Cluster aus Containern manuell zu betreiben.
Da sich Kubernetes quasi als offener Industriestandard für Container-Orchestrierung etabliert hat und sich einfach auch lokal für Entwicklungszwecke mit z.B. Minikube installieren lässt, wollten wir unsere Anwendung auch in einem Kubernetes Cluster deployen.
Damit unsere Anwendung auch im Internet und nicht nur lokal verfügbar ist, mussten wir uns für einen Cloud-Anbieter entscheiden, was sich als schwieriger herausgestellt hat als anfangs angenommen.
Die Entscheidung für den Anbieter hierfür sollte anhand von finanziellen Faktoren, objektiver Leistung sowie Soft-Factors gefällt werden.
Für uns kamen in der Vorauswahl als Cloud-Anbieter AWS (Amazon Web Services) und GCP (Google Cloud Platform) in Betracht, da wir in unserer Gruppe mit beiden Anbietern bereits in Berührung gekommen sind, beide einen managed Kubernetes Service anbieten, beide Anbieter verbreitet und etabliert sind und einiges an Tooling und Lehrmaterialien für diese existiert. AWS’ Service trägt den Namen EKS (Elastic Kubernetes Service) während GCP’s Service GKE (Google Kubernetes Engine) heißt.
Beim Betrachten der Preise fällt auf, dass es komplex ist, auf den ersten Blick zu beurteilen, bei welchem Anbieter monatlich die geringeren Kosten entstehen.
Dazu kommt, dass es sich zwar um relativ ähnliche, aber immer noch unterschiedliche Leistungen handelt und somit nicht feststeht, ob ein Nutzer bei beiden Deployments auch eine äquivalente User Experience hinsichtlich z. B. Latenzen, Verfügbarkeit etc. bekommt.
Man kann aus unserer Stichprobe allerdings ein paar Trends entnehmen. Für den einfachen Betrieb eines Kubernetes Cluster ohne Nodes verlangen beide Anbieter den gleichen Betrag von $0.10 pro Stunde. Hier ist kein Gewinner auszumachen.
Beim Betrieb der Nodes im Cluster wird die Entscheidung allerdings kompliziert. AWS bietet zum Betrieb von Nodes die AWS Fargate Compute Engine zum direkten deployen von Containern ohne Management von VMs. GCP bietet alternativ den Cloud-Autopilot an, für $0.10 zusätzlich pro Stunde, der nach unserem Verständnis das Kubernetes Cluster und dessen Ressourcen, wie Nodes, autonom managed und skaliert. Dadurch müssen bei der Nutzung des Cloud-Autopilots ebenfalls keine VMs manuell gemanaged werden. Interessanterweise sind hier die Preise für Ressourcen bei beiden Anbietern annähernd gleich für vCPU per hour und RAM usage per hour.
Alternativ kann man aber bei beiden Cloud Providern dem Kubernetes Cluster dedizierte VMs als Nodes zuteilen. Hierbei greifen beide Kubernetes Services auf die jeweiligen VM Services des Cloud-Anbieters (EC2 bei AWS und GCP VM bei GCP) zurück und es gelten die entsprechenden Preise. Sowohl bei einem Cluster aus “schwachen” Nodes, als auch bei einem Cluster aus “stärkeren” Nodes ist GCP signifikant günstiger als AWS.
Beim Egress Network Traffic und persistentem SSD Storage wiederum ist AWS signifikant günstiger.
Soft-Faktoren haben eher für EKS von AWS gesprochen, da AWS der Marktführer und etablierter als GCP ist. Weiterhin hatten unsere Entwickler bisher mehr Erfahrung mit AWS gesammelt. Ein weiterer Soft-Faktor der für EKS spricht ist, dass AWS mit CloudWatch ein für uns interessantes Produkt zum Auswerten von Application Metrics bietet, für das GCP unseres Wissensstandes nach keinen äquivalenten Dienst als Ersatz anbietet.
Für den Betrieb eines minimal funktionalen Prototyps unseres Clusters benötigen wir mindestens 5 Container (Product Service, ElasticSearch, Logstash, Kibana und MongoDB) pro Environment. Jeder dieser Container benötigt ungefähr mindestens 1GB RAM, da es sich bis auf MongoDB ausschließlich um JVM Anwendungen handelt, die unserer Erfahrung nach im lokalen Betrieb viel RAM konsumieren. Im Fargate Betrieb des Elastic Kubernetes Services von AWS kommen wir mit 5 Containern mit jeweils 0.25 vCPUs und 1GB RAM auf ca. $60.30 monatlich. Gehen wir davon aus, dass wir insgesamt im Cluster mindestens 5GB RAM benötigen, müssen in dem Cluster alternativ 3 schwache dedizierte VM Instanzen (jeweils 2GB RAM) verfügbar sein. Der Preis würde sich hier bei AWS auf $57.30 im Monat belaufen und bei GCP auf $36.18. Da wir aber die Ergonomie einer Container Compute Engine wie Fargate bevorzugen, haben wir uns für den EKS Service von AWS entschieden, da der Google Cloud Autopilot von GCP aufgrund des hohen Preises ausscheidet und die Soft-Faktoren für EKS sprechen. Wenn wir die Preise für Netzwerk Traffic und Storage mit einbeziehen, die für unser Studentenprojekt, aber erstmal vernachlässigbar sind, bewegt sich die Tendenz weiter zu AWS.
| AWS EKS | GCP GKE | |
| Betrieb | $0.10($72 per month) | $0.10($72 per month) |
| Nodes | Fargate: per vCPU: $0.04656 per hour per GB: $0.00511 per hour EC2: Smallest recommended node t2.small (burst CPU, 2GB RAM): $0.0268 per hour($19.30 per month) General purpose medium x64 node m5a.2xlarge (8vCPU AMD EPYC, 32GiB): $0.416 per hour($299.52 per month) | Google Cloud Autopilot (Additional $0.10 per hour): per vCPU: $0.0445 per hour per GB: $0.0049225 per hour GCP VM: Smallest recommended node e2-small (burst CPU, 2GB RAM): $0.016751 per hour($12.06 per month) General purpose medium x64 node e2-standard-8 (8vCPU AMD EPYC, 32GiB): $0.345336 per hour($248.64 per month) |
| Data Transfer Out | Within one AZ: no charge Within region: $0.01/GB Across regions: $0.01-0.02/GB To Internet:$0.09/GB (first 10 TB) | Within one AZ: no charge Within region: $0.01/GB Across regions: $0.01-0.15/GB To Internet: $0.12-0.23/GB (first 1 TB) |
| Storage | EBS (SSD) per GB: $0.0952 per month | Persistent Disk (SSD) per GB: $0.204 per month |
Alle Preise gelten für die Region Frankfurt [12-14].
Serverless Dienste
Amplify ist ein Produkt von AWS, welches eine Sammlung von Werkzeugen und Funktionen mit sich bringt. Unter anderem können so auf einfachem Weg AWS-Services erstellt und eingebunden werden. In sharetopia wurde mithilfe von Amplify der Authentifizierungs-Service Cognito und ein S3 Bucket von AWS eingebunden. Diese werden mithilfe der AWS CLI dem Projekt hinzugefügt.
Der Vorteil in der Verwendung von Amplify besteht darin, dass man durch die Serverless Architektur kaum Entwicklungsressourcen aufwenden muss, um Cloud-Infrastruktur zu pflegen und man ohne tiefgreifende Cloud Kenntnisse zurechtkommt. Es ist sozusagen das Backend-As-A-Service-Produkt von AWS.
CI/CD Pipelines
Continous Integration, Continous Delivery und Continous Deployment sind Praktiken, welche von Softwareentwickler-Teams, für eine kontinuierliche Automatisierung und Überwachung über den gesamten Anwendungs-Lifecycle, genutzt werden. Dabei sind alle drei Praktiken zusammenhängend und werden oft auch als CI/CD-Pipeline bezeichnet [1]. Das weiterführende Konzept hinter CI/CD kann unter [1] nachgelesen werden.
In einer CI/CD Pipeline beschreibt Continous Integration die erste Phase. In dieser werden regelmäßig die neuen Codeänderungen erst geprüft und anschließend in einem gemeinsamen Repository zusammengeführt. Von Jez Humble wurden dabei drei Prinzipien einer idealen Verwendung von Continous Integration beschrieben [2]:
- Tägliche Commits auf den Master-Branch
- Automatische Builds und Tests nach jedem Commit
- Bei Auftritt eines Fehlers muss dieser in 10 Minuten behoben werden können.
Die folgende Phase (Continuous Delivery) beschreibt die automatisierte Freigabe des validierten Codes an ein Repository. Nach dieser Phase müssen alle Code-Änderungen auf Bugs getestet und in einem Repository hochgeladen sein, von wo aus jederzeit eine Produktivversion bereitgestellt werden kann [1].
Continous Deployment ist die abschließende Phase, welche das automatisierte Bereitstellen des produktionsreifen Builds in die Produktivphase beschreibt [1].
Da CI/CD Pipelines heutzutage in vielen modernen Softwareteams genutzt werden, wurde im Rahmen dieses Projekts die Gelegenheit genutzt, eigene CI/CD Pipelines zu entwickeln. Bis dato war im Team nur wenig Erfahrung über CI/CD Pipelines vorhanden. Da Frontend & Backend Team jeweils ein eigenes Repository hatten, wurden separate Pipelines aufgesetzt.
Bevor näher auf die einzelnen Pipelines eingegangen wird, wird nachfolgend kurz die Entscheidung für Github Actions zusammengefasst. Die CI/CD Pipelines wurden mit Github Actions entwickelt, um von den Vorteilen der Open-Source Actions profitieren zu können. In dem Blogeintrag von Jonas Hecht [4] sind die für dieses Projekt ausschlaggebenden Argumente für die Nutzung von Github Actions genannt. In diesem werden drei Wellen von unterschiedlichen CI/CD Pipeline beschrieben, angefangen mit der ersten Welle, welche von der Jenkins Plattform dominiert wurde. Heute noch ist die Open-Source-Software Jenkins weit verbreitet. Jedoch muss Jenkins selbst gehostet werden, und bedarf viel Konfigurationsaufwand, weshalb dies keine Option für dieses Projekt war.
Zur Diskussion stand jedoch Gitlab CI/CD, als Alternative für Github Actions. Beide nutzen das Pattern Pipeline-As-Code, durch welches laut dem Blogartikel von Jonas Hecht die zweite Welle von CI/CD Plattformen eingeleitet wurde (auch Jenkins 2.0 nutzt dieses Pattern). Kurzgefasst beschreibt das Pattern das Definieren von Pipelines in einer Codedatei. Diese spezifiziert die verschiedenen Phasen, Jobs und Aktionen, welche von einer Pipeline ausgeführt werden sollen. Diese Codedatei ist meist eine .yml Datei, kann aber auch in einer anderen Sprache geschrieben sein. Der Vorteil gegenüber Konfigurations-GUIs ist, dass sie im Code-Repository gespeichert wird und damit versioniert ist. Mehrere Entwickler können so an der Pipeline arbeiten und Änderungen leicht rückgängig gemacht werden. Außerdem sind Änderungen an der Pipeline für andere Entwickler direkt sichtbar.
Nach längerer Internetrecherche kann man einige Meinungen lesen, welche entweder Pro Gitlab oder Pro Github sind. Im Blogartikel von Bruno Amaro Almeida [5] werden alle Konkurrenten aufgelistet und beschrieben. In seinem Fazit schreibt er, dass alle Anbieter genutzt werden können, um eine funktionierende Pipeline zu entwickeln, jedoch variiert der operative Overhead und der Aufwand. Dasselbe wird auch in [4] beschrieben. Dieser operative Overhead ist bei Github Actions geringer, weshalb zuletzt auch die Entscheidung auf diesen Pipeline-Anbieter fiel. Durch den Release von Github Action in 2020 kam ein neuer Konkurrent auf den Markt, durch welchen nun alle großen Git-Repository Anbieter wie Gitlab, Bitbucket und Github eigene Lösung für CI/CD Pipelines anbieten. Der Vorteil von Github Actions sind zum einen die 2000 Runner Minuten im kostenlosen Plan (im Vergleich zu 400 Minuten beim kostenlosen Plan von Gitlab) und zum anderen der Marketplace der Actions. In [4] wird dies als die neue dritte Welle der CI/CD Plattformen bezeichnet. Actions sind Open-Source-Software, welche wie Lego Blöcke in der Pipeline-Beschreibung genutzt und kombiniert werden können. Will man beispielsweise eine bestimmte Aktion, wie das deployen eines Frontends in Firebase in der .yml Datei definieren, dann kann man eine von Google erstellte Action zum deployen in Firebase nutzen, welcher man lediglich die notwendigen Tokens und ID’s übergeben muss. Dadurch wird der Codeumfang reduziert und das Entwickeln von Pipelines vereinfacht. Durch Actions wird das Wiederverwenden von pipeline-spezifischem Code ermöglicht. Die Actions selbst können dabei entweder von der Community, Github oder von Firmen entwickelt und gepflegt werden. Dies war der ausschlaggebende Grund für die Nutzung von Github Actions. Wie auch schon in [4] erwähnt, kann so in kleinen Teams eine Pipeline aufgesetzt werden, ohne dabei ein eigenes Team haben zu müssen, welches nur für die Pflege von Pipelines zuständig ist. Allerdings entsteht so auch der Nachteil, dass das Wissen über die genaue Funktionsweise der einzelnen Actions verloren geht. Baut man selbst eine Pipeline, so ist man sich im Klaren, welcher Schritt nach welchem ausgeführt wird. Bei den einzelnen Actions fehlt das Wissen, bzw. muss man sich hierfür die Beschreibung der Action genauer ansehen.
Frontend
Im Frontend Team wurden CI/CD Pipelines genutzt, um automatisiert Tests und den Build-Prozess durchzuführen, mit anschließendem Deployment in den verschiedenen Environments. Dazu wurden folgende Environments festgelegt: Development, Staging und Production. In der folgenden Abbildung ist der Prozess von Development bis zu Production abgebildet.

Zu sehen ist, dass man sich während der Entwicklung im Environment Development befindet. Dort findet alles lokal auf dem eigenen Rechner statt und es wird in einem separatem Branch gearbeitet. Sobald die Entwicklung in diesem Branch abgeschlossen ist, wird ein Pull Request in den Master gestellt. Dieser Pull Request triggert dabei die erste Pipeline, welche in der Datei “pull-request.yml” (https://github.com/Sharetopia/Frontend/blob/main/.github/workflows/pull-request.yml) beschrieben ist. Diese führt zuerst die Tests aus, baut anschließend das Frontend und deployt es zum Schluss auf surge.sh.
Die anderen Teamkollegen haben nun die Möglichkeit zum einen den Pull Request zu reviewen und zum anderen die Staging Version auf surge auszuprobieren. Anschließend, nachdem der Pull Request genehmigt und gemerged ist, wird die zweite Pipeline, welche in der Datei “push-main.yml” (https://github.com/Sharetopia/Frontend/blob/main/.github/workflows/push-main.yml) beschrieben ist, getriggert.
Auswahl der Hostinganbieter
Für das Staging-Hosting wurde surge.sh verwendet, aufgrund der einfachen und kostenlosen Nutzungsmöglichkeit. Surge.sh bietet einen kostenlosen Plan an, bei welchem man unbegrenzt Versionen veröffentlichen kann, was im Staging Fall sehr nützlich ist [6]. Alternativ dazu wäre auch Github Pages infrage gekommen, jedoch müsste man hierfür entweder einen bezahlten Plan nutzen oder das Repository öffentlich machen.
Interessanter war die Auswahl des Production-Hostings. Dort standen drei unterschiedliche Hosting Anbieter zur Auswahl: AWS Amplify, Firebase und Netlify. Dabei wurden zuerst die Kosten verglichen.
Wenn man davon ausgeht, dass man 30.000 Seitenaufrufe im Monat hat, wobei 1 Seitenaufruf ca. 2 MB Daten vom Hosting Anbieter (Bilder werden separat im S3 Bucket geladen) transferiert und 1 GB Hosting Speicher benötigt, ergibt sich folgendes Kostenmodell pro Monat:
| AWS Amplify | Firebase | Netlify | |
| Preismodell | Pay-as-you-go | Pay-as-you-go | Festbetrag (Starter |
| 60 GB Datentransfer pro Monat | 9,00$ | 7,50$ | 0,00$ |
| 1 GB Hosting | 0,02$ | 0,00$ |
Geht man von 200.000 Seitenaufrufen aus, ergibt sich folgendes Modell:
| AWS Amplify | Firebase | Netlify | |
| Preismodell | Pay-as-you-go | Pay-as-you-go | Festbetrag (Pro) |
| 400 GB Datentransfer pro Monat | 60$ | 58,50$ | 19$ |
| 1 GB Hosting | 0,02$ | 0,00$ |
Zum Veranschaulichen des Skalierungseffekt wird nun angenommen, dass man 1.000.000 Aufrufe im Monat hat:
| AWS Amplify | Firebase | Netlify | |
| Preismodell | Pay-as-you-go | Pay-as-you-go | Festbetrag (Pro) |
| 2000 GB Datentransfer pro Monat | 300$ | ≈300$ | 339$ |
| 1 GB Hosting | 0,02$ | 0,00$ |
Vergleich [7] [8] [9]
Zu sehen ist, dass die beiden Pay-as-you-go Anbieter sich in den Kosten relativ ähnlich sind, während Netlify zu Beginn deutlich günstiger ist, und erst bei extrem vielen Seitenaufrufen schnell teuer wird. Da es sehr unrealistisch ist, so viele Seitenaufrufe zu bekommen, wäre Netlify die richtige Wahl.
Da dies jedoch ein Studentenprojekt ist und nicht zur wirklichen Veröffentlichung gedacht ist, reichen die beiden kostenlosen Pläne von Firebase und Netlify aus. Die Nutzung von Firebase würde die kostenlose Nutzung von Google Analytics mit sich bringen, was bei der Analyse der Seitennutzung wiederum sehr hilfreich sein kann. Leider wird für die kostenlose Nutzung von Amplify eine Hinterlegung der Kreditkarte vorausgesetzt, weshalb AWS nicht genutzt werden kann. Für die Entscheidung zwischen Netlify und Firebase wurde zuletzt noch die Art und Weise des Deployments hinzugezogen. Während Netlify darauf baut, selbst den Build durchzuführen (wo wiederum nur 300 Minuten inklusive sind), kann bei Firebase eine Github Action genutzt werden (dort sind 2000 Minuten inklusive). Aus diesem Grund wurde Firebase als Production Hosting ausgewählt, da es ermöglicht, das Deployment in die CI/CD Pipeline mit einzubauen und die kostenlose Nutzung von Google Analytics inbegriffen ist.
Aufbau Pipeline
In der folgenden Abbildung ist die push-main.yml zu sehen. Diese beschreibt zwei Jobs: “test” und “build_and_deploy”. Beide Jobs nutzen Github Actions aus dem Marketplace.
In den beiden blauen Kästen wird zuerst der aktuelle Code mithilfe von “actions/checkout@v2”ausgecheckt und anschließend mithilfe von “actions/setup-node@v2” eine Node Umgebung auf der Ubuntu Instanz aufgesetzt. Anschließend werden alle npm Packages mit dem Befehl “npm ci” installiert.
Der rote Kasten beschreibt das Ausführen der Tests mit dem Befehl “npm run test:unit”, nachdem alle Dependencies geladen sind.
Der gelbe Kasten beschreibt das Ausführen des Build Prozesses mit dem Befehl “npm run build”.
In dem grünen Kasten ist beschrieben, dass der fertige Build zu Firebase hochgeladen werden soll. Hierfür wurde die Github Action “FirebaseExtended/action-hosting-deploy@v0” von Firebase selbst genutzt. Diese benötigt als Konfiguration den “repoToken” und “firebaseServiceAccount”, welche als Secrets im Repository hinterlegt sind.

main.yml File
Pipeline Optimierungen
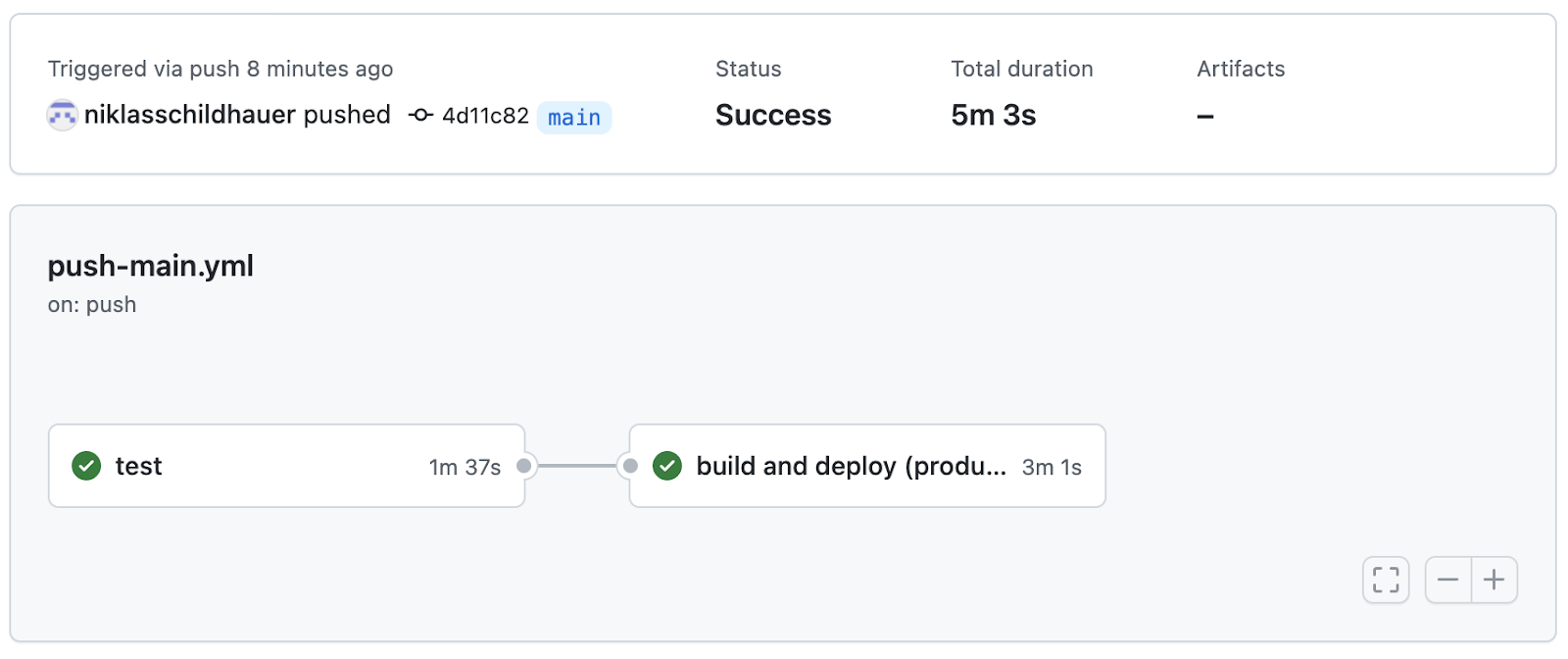
Bei der Erstellung der Pipeline traten einige Fehler auf, wie beispielsweise, dass das “working-directory” nicht richtig gesetzt wurde, oder falsche Testbefehle (ohne “:unit”) genutzt wurden. Diese Fehler zu beheben war recht simpel, jedoch war es zeitaufwendig, da die Pipeline wieder erneut gestartet werden musste. In der folgenden Abbildung ist ein Durchlauf vor der Optimierung der Pipeline zu sehen.

Aufgefallen ist, dass besonders der Befehl “npm ci” lange Zeit benötigt, da dieser bei jedem neuen Durchlauf erneut alle Node-Modules herunterlädt. Um diesen Schritt zu optimieren, wurde für die Node-Modules ein Cache verwendet, um diese nicht immer alle erneut laden zu müssen. Hierfür bietet die Github Action “actions/setup-node@v2” die Möglichkeit, die Node-Modules zu cachen. Durch Aktivieren des Caches (siehe blauer Kasten) wurde der Durchlauf der Pipeline um 1 Minute und 30 Sekunden beschleunigt, was in der folgenden Abbildung zu sehen ist.
Backend

Analog zum Frontend nutzen wir im Backend ebenfalls drei Environments (Development, Staging und Production).
Das Development Environment kann entweder in einem lokalen Kubernetes Cluster minikube oder über docker-compose gestartet werden. Das Staging und Production Environment wird in ein Kubernetes Cluster in der Cloud (EKS von AWS) deployed. Wir deployen für die unterschiedlichen Environments ein Cluster und trennen diese via Kubernetes Namespaces, anstatt unabhängige Cluster für jedes Environment zu nutzen. Vadim Eisenberg nennt in einem Blogartikel dafür mehrere Gründe [11], die uns dazu bewegt haben auf ein Cluster zu setzen, darunter fallen reduzierter administrativer Aufwand und geringere Kosten. Er nennt aber auch Beweggründe, wieso man mehrere Cluster einsetzen sollte, darunter fallen verbesserte Sicherheit, dass man unterschiedliche Kubernetes Versionen in den Environments haben kann und dass Cluster (für uns sehr ferne) Limitierungen in der Skalierbarkeit haben.
Ebenfalls analog zum Frontend sorgen Github Actions für das Continuous Deployment in das Kubernetes Cluster. Die Actions wechseln zuerst auf den für das Environment spezifischen Branch z. B. Production.

Anschließend wird mit docker build das Container Image gebaut und in das Amazon ECR (Elastic Container Registry) geschoben. ECR ist ein AWS Service, der sozusagen ein privates Docker Hub bereitstellt für die private Cloud Umgebung.

Anschließend nutzen wir die “kodermax/kubectl-aws-eks” Action zum deployen ins Kubernetes Cluster. Diese Action wrapped im Prinzip lediglich das Command Line Program kubectl konfiguriert auf das AWS EKS Cluster. Voraussetzung hierfür ist die Konfiguration von für das Cluster essenziellen Credentials in den Github Secrets.
Im ersten Step des Deployments wird das zuvor gebaute Image über rollout deployed. Im zweiten Schritt wird das deployment verifiziert.

Container & Container Orchestrierung


Für die lokale Entwicklung haben wir das Tool docker-compose und später minikube zum Orchestrieren der Container verwendet.
Wir haben das Programm kompose-convert verwendet, um für jeden Container aus der docker-compose.yml eine deployment und service yml Datei für Kubernetes zu erzeugen. Die deployment Dateien beschreiben einen Satz an identischen Pods (Pods sind eine Einheit aus ein oder mehreren Containern in der Kubernetes API) und deren Konfiguration. Die service Datei beschreibt das Networking für jedes der deployments. Anschließend konnten wir mittels dieser Dateien unsere Anwendung einfach in einem lokalen minikube cluster deployen und die Github Actions zum deployen ins Kubernetes Cluster nutzen. Beim testweisen Deployen eines EKS Clusters mittels eksctl fiel auf, dass das default EKS Cluster Node Groups bestehend aus VMs aus der m5 Familie dem Cluster hinzufügen möchte. Hier ist Obacht geboten, wenn man das Cluster preiswert für Test- und oder Bildungszwecke betreiben möchte, dass die Kosten nicht außer Kontrolle geraten.
Observability
Metriken
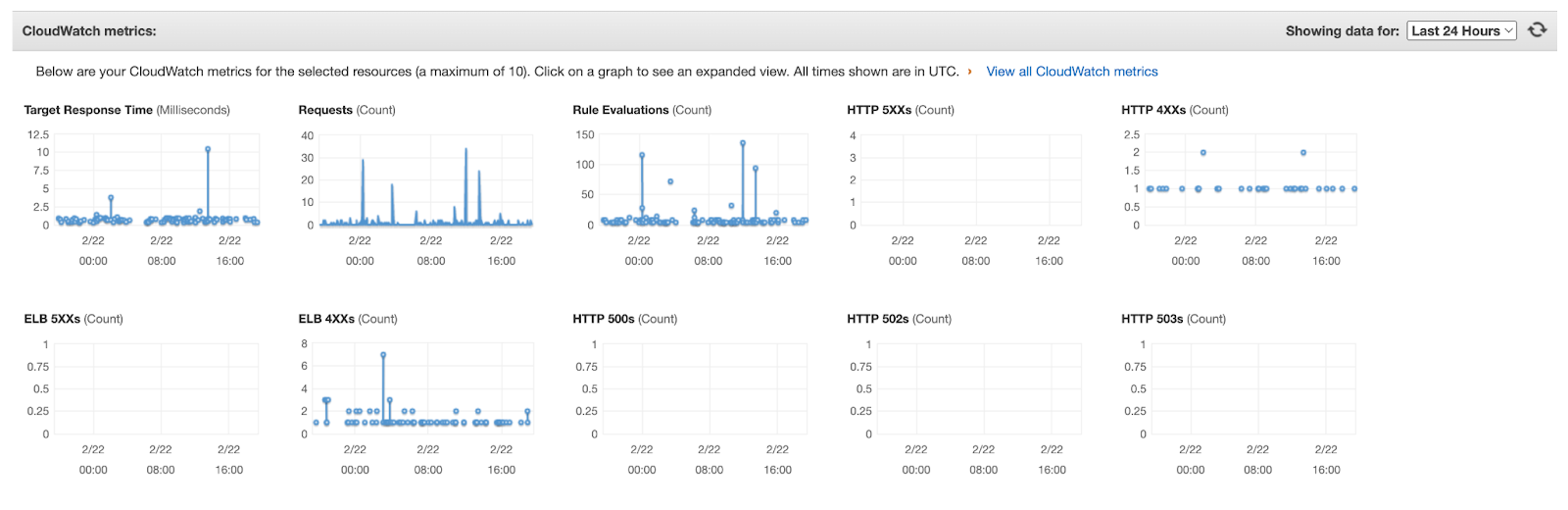
Zum Überwachen der User Experience der Services im Cluster haben wir CloudWatch Metrics verwendet. CloudWatch Metrics kann wichtige Metriken von AWS Ressourcen wie z. B. dem AWS ALB (Application Load Balancer) speichern und anschaulich darstellen.
Für die User Experience wichtig sind hierbei Metriken wie zum Beispiel die Response Times oder auch HTTP Errors (hier besonders der 500 Internal Server Error), denn die User Experience kann unter langwierigen API Requests und Bugs stark leiden. Bei den Response Times sollte beim Beobachten vor allem auf die Ausreißer (hohe Perzentile z. B. p95, p99, …) geachtet werden.
Auch interessant zu betrachten ist, ob und wie weit zuvor antizipierte Request Counts und deren Verteilung sich mit realen Zahlen decken.
Logging
Unsere Spring-Anwendung verwendet Logback als Logging-Framework, welches auch durch den Default Logger von Spring Boot verwendet wird. Als Facade für Logback nutzen wir SLF4J (Simple Logging Facade for Java) in unserem Code. Dadurch erhalten wir eine generische API, die unabhängig vom spezifischen Logging-Framework ist. Die log-spring.xml Datei für die Konfiguration von Logback sieht wie folgt aus:
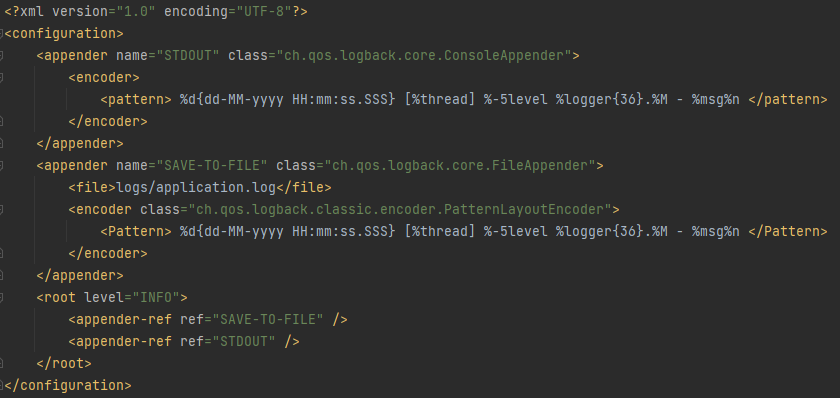
Hier definieren wir zwei Appender, welche jeweils die Aufgabe haben, Logs auf gewisse Weise auszugeben. Der erste Appender definiert dabei, wie die Logs auf der Standardausgabe ausgegeben werden sollen. Hierfür wird ein Pattern definiert, welchem diese Logs entsprechen sollen. Der zweite Appender definiert, dass die Logs in eine Datei namens application.log geschrieben werden sollen. Durch die Referenz auf diese beiden Appender innerhalb von <root> geben wir an, dass diese an den Root-Logger angehängt werden.
Wie zuvor erwähnt, wollen wir unsere Logs mit einer Logstash Pipeline weiterverarbeiten. Zusammengefasst soll diese dabei den folgenden Ablauf unterstützen:

Dieser Aufbau lässt sich grob wie folgt erklären: Im ersten Teil werden, wie in der gezeigten log-spring.xml definiert, die Logs in die entsprechende Datei geschrieben. Wird eine Zeile an diese Datei angehängt, wird diese als Input an Logstash weitergegeben. Logstash verarbeitet diese Logs dann nach bestimmten definierten Regeln und speichert diese als Output in Elasticsearch. Die in Elasticsearch gespeicherten Daten können dann mit Kibana näher analysiert werden. Im folgenden Teil soll dieser Ablauf noch etwas detaillierter erklärt werden.
In der unteren Abbildung ist die logstash.config dargestellt, welche zur Konfiguration der Logstash-Pipeline dient. Der erste wichtige Teil dieser Datei ist in der folgenden Abbildung dargestellt:

Hier sieht man die Definition des Input-Filters, der festlegt, welche Daten den Input der Pipeline bilden. Hier geben wir also den Pfad unserer application.log-Datei an.
Der nächste Schritt wäre jetzt eigentlich, diese gesammelten Logs in Elasticsearch zu speichern, um diese anschließend mit Kibana visualisieren zu können. Vorher sind aber noch gewisse Vorverarbeitungsschritte für die einzelnen Logs innerhalb unserer Pipeline notwendig. Eine Log-Zeile der Spring Anwendung nach dem Start der Anwendung sieht z.B. so aus:
11-02-2022 00:47:32.952 [main] INFO d.s.p.ProductServiceApplicationKt.logStarted – Started ProductServiceApplicationKt in 9.947 seconds (JVM running for 10.945)
Da wir später die einzelnen Felder wie z.B. das Log-Level (hier INFO) analysieren können wollen, müssen wir ein solches Statement in seine einzelnen Bestandteile zerlegen. Hierbei kommt erschwerend hinzu, dass beispielsweise unsere eigenen Log-Statements im Code beim Aufruf unserer Routen einen leicht veränderten Aufbau haben:
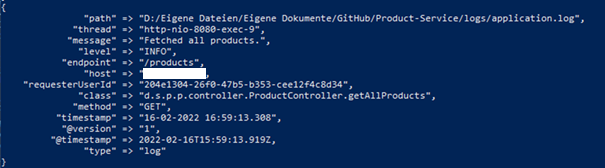
16-02-2022 16:59:13.308 [http-nio-8080-exec-9] INFO d.s.p.p.controller.ProductController.getAllProducts – Fetched all products. {method=GET, endpoint=/products, requesterUserId=204e1304-26f0-47b5-b353-cee12f4c8d34}
Wie man sehen kann enthalten unsere eigenen Log-Statements zusätzlich noch Schlüssel-Werte Paare in spitzen Klammern, die wir auch separat erfassen möchten. Um diese Informationen aus Logs parsen zu können, stellt Logstash den sogenannten grok parser zur Verfügung. In unserer Config-Datei haben wir hierfür folgende Definitionen eingefügt:

filter gibt hierbei an, dass Definitionen bezüglich der Verarbeitung der eingehenden Log-Daten folgen. Mit grok definieren wir den erwähnten grok-parser. In diesem definieren wir wiederum unsere zwei Patterns, in die der String zerlegt werden soll. Durch die Reihenfolge wird festgelegt, dass zuerst auf unser eigenes spezifischeres Pattern überprüft und falls dieses nicht geparst werden kann, das generischere Pattern angewendet werden soll. Erwähnenswert ist außerdem in der obigen Abbildung die Definition von kv. Dies ist ein Filter-Plugin, mit dem wir den RequestParam parameter (sofern vorhanden) in key-value Paare splitten können. Der große Vorteil hierdurch ist, dass es keine Rolle spielt wie viele oder welche key-value Paare in RequestParam vorhanden sind. So können wir je nach der Funktion oder Route, in der wir unsere Log-Statements einfügen, unterschiedliche zusätzliche Parameter loggen. Die Zerlegung des obigen Logs aufgebaut nach dem spezifischeren Pattern sieht nach dem Anwenden der gezeigten Parsing-Regeln wie folgt aus:
Im letzten Teil unserer Config-Datei definieren wir anschließend noch, wo der Output unserer Logstash-Pipeline hingeleitet werden soll:

Der obige Screenshot zeigt, dass der Output zum einen an die Standardausgabe von Logstash weitergeleitet wird. Zusätzlich werden die Daten in einem tagesaktuellen Elasticsearch Index gespeichert. Insgesamt war dieses Einrichten der Pipeline auch ohne Vorerfahrung unkompliziert und ohne allzu großen Aufwand möglich. Die größte Herausforderung war, mit den verschiedenen Patterns der Logs umzugehen.
Die durch Logstash in Elasticsearch gespeicherten Logs konnten wir anschließend mit Kibana weiter analysieren. Dafür haben wir ein Index-Pattern in Kibana erstellt, welches alle Indizes mit dem Präfix „sharetopia-logs-“ einbezieht. Basierend auf unseren geparsten Feldern lassen sich dann verschiedene hoch individualisierbare Visualisierungen erstellen und einem Dashboard hinzufügen. Im folgenden Screenshot ist Teile eines solchen Dashboards zu sehen. Dies enthält z. B. ein Kreis-Diagramm, welches die Aufteilung der Logs auf die verschiedenen Log-Levels darstellt oder die Menge der Logs pro Tag in Form eines Balkendiagramms. Da die Anwendung allerdings nie wirklich im Live-Betrieb verwendet wurde, hält sich die Menge der gesammelten Daten und damit die Aussagekraft natürlich in Grenzen.

Fazit & Lessons Learned
Aus der Vorlesung und dem dazugehörigen praktischen Projekt haben wir einiges an Wissen und Erfahrungswerten mitgenommen, so viel, dass wir natürlich kaum alles in diesem Fazit festhalten können. Im Folgenden wollen wir jedoch gerne auf ein paar Punkte eingehen, die in ihrer Wirkung einen besonderen Aha-Effekt auf uns hatten und die wir deshalb besonders hervorheben möchten.
Ein wichtiger Punkt war Napkin Math zum ungefähren Überschlagen benötigter Ressourcen (Compute Power, Network, Storage, etc.) und Vergleichen von Anbietern hinsichtlich Leistung, finanziellen Aspekten und Soft Faktoren. Hierbei fiel uns vor allem auch auf, dass die Preisgestaltung der Cloud-Anbieter sehr intransparent ist und man sehr genau hinsehen muss, um eine halbwegs akkurate Schätzung der Kosten treffen zu können. Dabei haben wir auch festgestellt, dass unser mentales Modell von Cloud-Preisen öfters nicht der Realität entsprach. Leistungen, die man zuerst für günstig hält, sind in der Realität teurer und wiederum sind andere Leistungen, die man für teuer hält, eigentlich verhältnismäßig günstig.
Wir haben viel gelernt über Kubernetes und managed Kubernetes Services in der Cloud sowie dem Aspekt Observability und Logging. Dies sind Aspekte, die bis jetzt öfters bei Studienprojekten in der Vergangenheit eher vernachlässigt wurden.
Wir haben auch einige Learnings aus diesem Projekt mitgenommen, die wir gerne in unser nächstes Projekt mitnehmen wollen und Punkte, die wir in unserem nächsten Projekt gerne anders machen wollen. Während der Entwicklung fiel uns auf, dass unser Code relativ abhängig vom Spring Framework ist und die Einbettung des Codes in ein anderes Framework vermutlich mit einem relativ hohem Aufwand verbunden wäre. In der realen Welt kann es jedoch erforderlich sein, das Framework zu wechseln (oder den Code ganz ohne Framework zu verwenden). Gründe hierfür könnten sein, dass ein Framework nicht mehr weiterentwickelt wird, das Framework größere API-breaking Versionssprünge macht oder neue Features benötigt werden, die nicht Bestandteil des Frameworks sind. Weitere mögliche Gründe wären, dass der Code in einer anderen Anwendung benötigt wird oder dass der Business Case es erforderlich macht auf ein anderes Framework zu setzen. Ein Weg den Code im nächsten Projekt Framework-unabhängiger zu machen, wäre zum Beispiel, die gesamte Business Logik stattdessen in einer Library zu implementieren und dann aus dem Framework nur noch diese Library aufzurufen.
In der begleitenden Vorlesung haben wir die TDD (Test Driven Development) Methode zum Entwickeln von Code kennengelernt, die wir gerne in unserem nächsten Projekt anwenden würden. Wir denken, dass TDD uns dabei helfen könnte schneller kleine funktionale Code Bausteine zu entwickeln. Außerdem macht man sich vor der Implementierung schon Gedanken über die Schnittstellen für die Implementierung, was auch beim kollaborativen Arbeiten im Team von Vorteil sein kann, da Kollaborateure wissen, gegen welche Schnittstellen sie programmieren müssen.
Wir haben in unserem Projekt nicht jeden Tag auf den Master committet, was natürlich in der Realität in einem Studienprojekt auch schwer ist, da man nicht jeden Tag daran arbeitet, jedoch hätten wir in unserem Projekt durchaus öfter auf den Master committen können. TDD hätte hier sicherlich auch gestützt. Eigentlich ist es nach Martin Fowler [15] auch Teil von Continuous Integration jeden Tag auf den Master zu committen.
Ein weiterer Punkt für unser nächstes Projekt wäre, unsere Infrastruktur als Code zu implementieren (Infrastructure as Code). Hierfür könnten wir unser Kubernetes Cluster und dessen Node Groups, sowie andere verwendete Cloud Ressourcen z. B. über Terraform definieren.
Es wäre auch von Vorteil, wenn wir für unser nächstes Projekt einen Cloud Playground von der Uni z. B. in Form von Educational Accounts gestellt bekommen würden. In diesem Projekt mussten wir mit privaten Accounts (die unsere privaten Kreditkarten potenziell belasten) arbeiten, was die kollaborative Arbeit am Projekt erschwert hat und weshalb wir unsere Infrastruktur immer schnell wieder heruntergefahren haben, um keinen bzw. nur einen geringen Kostenaufwand zu haben. Wir hätten auch gerne mehr Fokus auf die Hochverfügbarkeit der Services gelegt (z. B. durch Replikation von Services), eine Implementierung hätte hier jedoch den Kosten- und Zeitrahmen für dieses Studienprojekt gesprengt. Wir haben in diesem Projekt auch keinen größeren Fokus auf die Security der Infrastruktur und Software-Implementierungen gelegt. Beides wären interessante Anknüpfpunkte für ein Folgeprojekt, basierend auf der existierenden Arbeit.
Quellen
[1]: https://www.redhat.com/de/topics/devops/what-is-ci-cd
[2]: https://martinfowler.com/bliki/ContinuousIntegrationCertification.html
[3]: https://dev.to/flippedcoding/difference-between-development-stage-and-production-d0p
[4]: https://blog.codecentric.de/en/2021/03/github-actions-nextgen-cicd/
[5]: https://blog.thundra.io/the-ci-cd-war-of-2021-a-look-at-the-most-popular-technologies
[6]: https://surge.sh/
[7]: https://firebase.google.com/pricing
[8]: https://aws.amazon.com/de/amplify/pricing/?nc=sn&loc=4
[9]: https://www.netlify.com/pricing/
[10]: https://martinfowler.com/articles/practical-test-pyramid.html#TheTestPyramid
[11]: http://vadimeisenberg.blogspot.com/2019/03/multicluster-pros-and-cons.html
[12]: https://aws.amazon.com/ec2/pricing/on-demand/
[13]: https://cloud.google.com/compute/vm-instance-pricing
[14]: https://cloud.google.com/vpc/network-pricing
[15]: https://martinfowler.com/articles/continuousIntegration.html
Leave a Reply
You must be logged in to post a comment.