Why so serious? – Ein Artikel von Sarah Schwab und Aliena Leonhard im Rahmen der Vorlesung Systems Engineering and Management.
Die Idee, ein fiktives Interview zu erstellen, entstammt daraus komplexe Sachverhalte unterhaltsam und verständlich zu machen.

Wir sind heute zu Gast in der Tech-Sendung “Himbeer Tarte und harte Fakten”. Heute geht es unter Anderem um die Themen “Raspberry Pi”, “Infrastructure as Code” und “Ansible”. Vier Experten haben wir zu einer Diskussionsrunde eingeladen. Herzlich Willkommen, Frau Ann Sibel, Herr Kah Dreis, Herr Archie Tex-Ture und Frau Infra Struc-Ture.
Meine erste Frage geht an Herrn Archie Tex-Ture. Erzählen Sie uns bitte mehr zu Ihrem gemeinsamen Forschungsprojekt. Was war ihr Ziel und wie sind sie beim Aufbau des Projektes vorgegangen?
Herr Archie Tex-Ture
Guten Morgen, vielen Dank, dass ich in die Sendung eingeladen wurde und über unser Projekt sprechen darf. Es ging um die Bereitstellung eines K3s Clusters. Auf k3s geht mein Kollege sicher später noch näher ein. Ein Cluster würde ich mal versuchen zu beschreiben. Man kann es sich vorstellen wie mehrere Computer, die aneinander gesteckt werden und sich unter anderem ihre Ressourcen teilen können (Prozessor, Speicher, Grafikkarte etc.).
Solch ein Cluster wollten wir auf Raspberry Pi’s ausrollen. Raspberry Pi’s sind kleine Mini-Computer, meistens ohne Gehäuse. Sie können sich die so vorstellen, wie das innere ihres Handys – falls sie mal eines zerlegt haben. Ich gebe zu, gerade als Kind hab ich gern alte Radios auseinander geschraubt *lacht*. Ah meine Kollegin reicht mir hier auch ein Bild von so einem Raspberry Pi Computer:

Es war unser Ziel manuelle Arbeitsabläufe zu automatisieren. Besonders die Kollegen Infra Struc-Ture und Ann Sibel waren uns bei der Erreichung des Ziels sehr hilfreich.
Bei unserem Projekt haben wir uns unter anderem inspirieren lassen von den neuesten Buzz-Wörtern wie “Cloud”, “Kubernetes”, “Orchestrierung” und “DevOps”. Wissen Sie, gerade als angehende Fachexperten empfanden wir es von äußerster Wichtigkeit uns mit den neuesten Cloud-Technologien besser auszukennen. Und wir wollten mal bei den Basics anfangen.
Das klingt ja spannend. Wieso haben Sie sich dann für die Lösung mit den Raspberry Pi Computern entschieden?
Herr Archie Tex-Ture
Ja, gute Frage. Ich denke uns war es vor allem wichtig, eine neuere Generation – die Version 4B, um genau zu sein – von Raspberry Pi Computern zu verwenden und einfach mal zu schauen, was mit den Geräten möglich ist. Wir haben einen Artikel gefunden, der aufzeigt, wie man aus den Raspberry Pi Computern ein leistungsstarkes Cluster bauen kann. Und das fanden wir einfach super interessant. Wissen Sie, es gab – oder gibt unterschiedliche Raspberry Pi’s. Die ältere Version – Version 3 zum Beispiel – hat eine 32bit Architektur und daher kommt auch das 32bit Betriebssystem “Raspberry Pi OS”. Das bedeutet grob gesagt einfach nur, dass die Prozessoren der Computer weniger verarbeiten können als die der Raspberry Pi Computer mit der 64bit Architektur. Bisher kam die Firma Raspberry scheinbar noch nicht ganz hinterher das Betriebssystem für die 64bit Architektur in einer stabilen Version zu veröffentlichen. Sie befindet sich noch in der Beta Version. Die neueren Raspberry Pi Computer haben somit salopp gesagt einen schnelleren Prozessor. Es macht natürlich Sinn auch ein Betriebssystem auf dem Pi zu haben, das auf den Prozessor ausgelegt ist. Das Standard Betriebssystem von Raspberry ist jedoch auf 32bit ausgelegt. Die 64bit Variante ist – wie schon gesagt – noch in der Beta Version. Wir wollten dennoch so viel Power wie es nur geht aus unserem Cluster rausholen, weswegen wir uns für die 64bit Lite version ohne grafische Benutzeroberfläche entschieden haben. Spannend möchte ich meinen! Denn wir wussten nicht, ob alles stabil läuft. Für unseren Anwendungsfall hatten wir scheinbar Glück. Denn wir haben so gut wie keine Probleme mit der Beta Version. Erwähnenswert ist auch, dass wir uns aus Sparsamkeit für diese Version entschieden haben. Es macht nämlich fast 25% der Prozessor-Performance aus die 64bit Version zu verwenden statt der 32bit Version. Klar kommt es dann auch noch drauf an welchen internen Speicher (RAM) und welche lese/schreib-Geschwindigkeit die SD Karte hat, aber überlegen Sie nur mal! 25% der Power einfach so verschenken? Wissen Sie, die meisten in unserem Team sind Schwaben. Da denken wir nicht mal ans Verschenken, wenn es niemand anderen glücklich macht. Naja und die Ausnutzung des Speichers ist auch besser bei der Nutzung des dafür vorgesehenen Betriebssystems.
Außerdem, Hardware zu Hause zu haben ist schon was Feines. Wir haben Kabel verlegt, geschraubt, gesteckt und plötzlich lief es. Das ist ein tolles Gefühl. Mit einer Virtuellen Maschine hatte ich nie so ein Grinsen auf dem Gesicht. Das ist einfach was Anderes.
Da habe ich direkt eine Anschlussfrage: Gibt es denn keine Lösung, die weniger aufwendig gewesen wäre, als sich die Hardware zu bestellen?
Herr Kah Dreis
Wenn ich diese Frage beantworten dürfte: Es kommt immer ganz drauf an was Ihr Ziel ist. Wollen Sie beispielsweise nur ein Kubernetes Cluster aufsetzen, dann gibt es da viele andere Möglichkeiten wie beispielsweise “Kublet” direkt auf Virtuellen Maschinen auf einem Host laufen zu lassen. “Host” – so nennt man in der Fachsprache einfach ein System – kann auch Ihr Computer zu Hause sein. Bei uns war das Ziel ja eben auch uns mit der Hardware und Netzwerk-Technik zu beschäftigen. Wissen Sie, uns allen bis auf Infra Sctruc-Ture war da vieles neu. Zum Glück hatten wir sie immer wieder als Beraterin an unserer Seite.
Klar könnten Sie jetzt sagen: Ja aber wieso buchen Sie denn nicht einfach ganz stressfrei ein paar Server oder Ressourcen von Cloud Anbietern wie Azure und wie sie alle heißen?! An sich eine nette Frage. Aber haben wir dann wirklich etwas anschauliches über Cloud-Computing, Cluster und Orchestrierung gelernt? Ich für meinen Teil kann sagen, dass ich das im wahrsten Sinne des Wortes greifbarer erfassen kann, als auf irgendwelchen Dashboards von den Cloud anbietern, wo mit einem Knopfdruck neue Ressourcen dazu gebucht werden. Ich kann mir ehrlich gesagt – erst jetzt nach dem Projekt so richtig vorstellen, was das eigentlich bedeutet eine “Ressource dazu zu buchen”. Und denken Sie mal weiter. Wir alle haben so viele Gerätschaften zu Hause liegen, die im Endeffekt auch Ressourcen sind. Ich spreche hier von Spielekonsolen, alten Laptops, Computern – vielleicht mit alten Grafikkarten. Denken Sie mal im Sinne der Nachhaltigkeit: Wir würden solche Ressourcen im Endeffekt vernetzen – gerade im Bereich Gaming ist das ein großer Schritt. Und wir haben den ersten Schritt getan um genau darin Experten zu werden. Verstehen Sie?
Ja natürlich. Interessanter Aspekt. Frau Infra Struc-Ture, können Sie uns mehr zu Ihrer Haupttätigkeit und Ihren Aufgaben erzählen. Was bedeutet “Infrastructure as Code”?
Frau Infra Struc-Ture
Zu Beginn des Projektes – als ich noch nicht dabei war – wurden viele Tasks, wie das Einrichten der Raspberry Pi’s manuell vorgenommen. Unter dem manuellen Einrichten verstehen wir z.B. auch das setzen von statischen IP Adressen. Da das Team anfangs noch viel experimentieren musste, kam es öfter vor, dass die Pi’s neu aufgesetzt werden mussten. Dieser Vorgang war mühselig und zeitraubend, weshalb ich ins Team geholt wurde. Meine Aufgabe war es die soeben beschriebenen manuellen Abläufe zu automatisieren und das Team im Bereich “Infrastructure as Code” zu schulen. In unserer Familie sagen wir auch IaC zu “Infrastructure as Code” und als Code wird maschinenlesbarer Code verstanden. Das kann man sich so vorstellen, als würde man eine Software schreiben. Mithilfe des Codes wird die technische Infrastruktur definiert, zB. Speicher, Netzwerk oder Rechenleistung. Es gibt hier mehrere Tools die einem die Arbeit erleichtern. Diese IaC-Tools unterscheiden sich in ihrem Aufbau und ihrer Sprache voneinander. Verfahrenssprachen (Procedural languages) sind Systemadministratoren – also die Personen, die sich um die Server kümmern – mit Wissen über Skripte, vertrauter. Chef und Ansible verwenden eine prozedurale Sprache, in der sie Code schreiben, der Schritt für Schritt angibt, wie der gewünschte Endzustand erreicht wird. Hingegen verwenden Terraform, SaltStack und Puppet einen deklarativen Stil, bei dem Code geschrieben wird, der den gewünschten Endzustand angibt. Das IaC-Tool selbst bestimmt dann, wie dieser Zustand am effizientesten erreicht werden kann.
Bei IaC wird die komplette Infrastruktur über Skripte und Programmfiles definiert. Somit fällt der Overhead der manuellen Konfiguration weitestgehend weg. Das ist sehr praktisch.
Ich habe Ihnen hier mal eine Tabelle mitgebracht, in der Sie ein paar Open Source – also frei verfügbar, unter der Open Source Lizenz – Tools sehen können, die mich bei meiner Arbeit unterstützen. Alle Tools wurden mit einem bestimmten Zweck oder einer bestimmten Absicht entwickelt. Daher unterscheiden sie sich in ihrer Verwendung und den Anwendungszwecken. Im Laufe der Jahre haben sich die meisten Tools auch weiterentwickelt, um eine Vielzahl von Anwendungsfällen zu adressieren. Somit können sie die meisten IaC-Anforderungen problemlos erfüllen. Je nach Anforderung ist ein Tool möglicherweise besser geeignet als ein anderes.
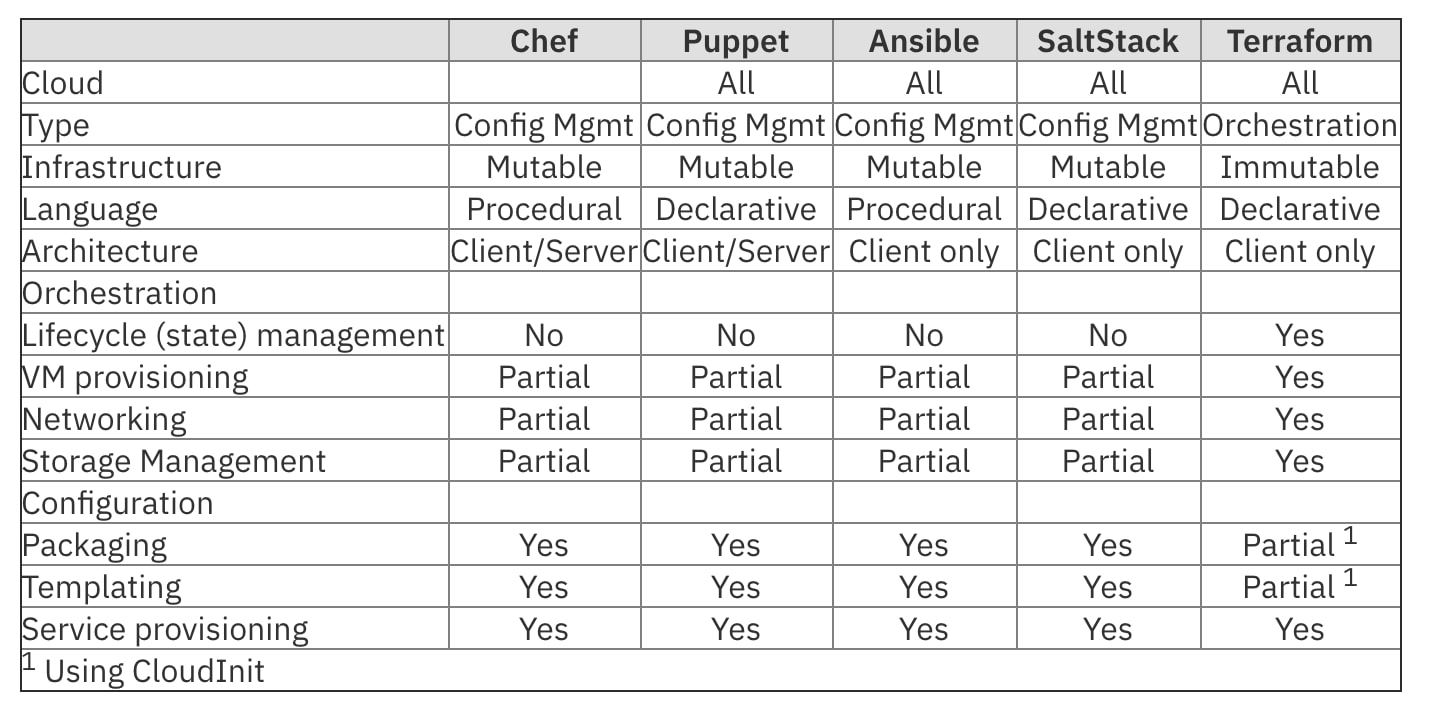
IaC-Tools können in zwei Typen unterteilt werden: Tools wie Ansible, Puppet, SaltStack und Chef gehören zum Typ “Configuration Management”. Sie wurden entwickelt, um Software auf vorhandene Server Instanzen – also Teile des Servers, oder “Kopien” davon – zu installieren und zu verwalten (z. B. Installation von Paketen, Skripten oder Konfigurationsdateien oder dem Starten von Diensten).
Orchestrierungs-Tools wie Terraform gelten hingegen als “Orchestratoren”. Solche Orchestrierungs-Tools sind so konzipiert, dass sie die Server Instanzen selbst bereitstellen und die Konfiguration dieser Server anderen Tools überlassen. Die Orchestrierung erfüllt die Anforderung an die Umgebungen auf einer höheren Ebene als das Konfigurationsmanagement es könnte. Der Fokus liegt hier auf der Koordination der Konfiguration über komplexe Umgebungen und Cluster hinweg.
Ich versuche das Ganze nochmal zu abstrahieren: Stellen Sie sich gern mal ein großes Event mit mehreren Sinfonie-Orchestern vor. Ein Gast Dirigent soll alle diese Orchester bei einem Stück anleiten. Es soll außerdem möglichst harmonisch klingen. Terraform fungiert als der Gast-Dirigent. Er leitet die Organisation vieler Orchester, sodass alle gut zusammenarbeiten können an. Üben müssen die MusikerInnen jedoch innerhalb ihres Heimat-Orchesters selbst mit ihrem Dirigenten. Den Heimat-Dirigenten wiederum kann man sich als “Configurations Manager” vorstellen. Er sagt wo jede Person sitzen soll und bringt sein Orchester dazu harmonisch zu spielen. Damit alle Orchester gleichermaßen gut spielen braucht es jedoch den Gast-Dirigenten auf dem Event.
Ein weiterer Punkt, den es bei der Auswahl des richtigen Tools zu beachten gilt, ist die Anforderung an die Infrastruktur. Die Frage: “Soll eine Umgebung / ein Server veränderlich – “mutable” – oder unveränderlich – “Immutable” – sein? Herkömmliche Serverumgebungen sind veränderlich, wenn sie nach der Installation immer wieder geändert werden können. Administratoren nehmen ständig Optimierungen vor oder fügen Code hinzu. Kleine Helferlein wie Konfigurationsmanagement-Tools – so genannte CM-Tools – wurden entwickelt, um die Komplexität zu vereinfachen und Ordnung in die Konfiguration und Aktualisierung von mehreren Servern zu bringen. Für die Administratoren ist das dann etwas übersichtlicher.
Eine unveränderliche Infrastruktur beinhaltet Server, die nach ihrer Bereitstellung nicht mehr geändert werden. Wenn sie dennoch aktualisiert oder geändert werden müssten, werden neue Server aus einer Vorlage mit den gewünschten Änderungen neu erstellt. Bedeutet es gibt wie eine Art vorgefertigte Schablone, nach der dann ein neues Abbild erstellt und das alte verworfen wird. Dieses Vorgehen ist üblich für Umgebungen – als Umgebungen bezeichnet man einfach eine größere Menge an Servern oder Computern innerhalb eines Netzwerkes -, die mittels Terraform aufgesetzt wurden. Neue Server ersetzen die bestehenden Server. Ähnlich ist das Vorgehen auch beim Aufsetzen und Verwalten von Containern.
[6], [7], [8], [9], [10], [11], [12], [13], [14], [15], [16]
Können Sie erklären, was sie mit “Containern” meinen?
Frau Infra Struc-Ture
Container können Sie sich wie echte Container auf einem Frachtschiff vorstellen. Vielleichte kennen Sie auch bereits die Analogie des Containerschiffes von Docker? Die Container auf den Schiffen sind quasi in sich geschlossene Anwendungen, die sich untereinander erst einmal nicht sehen. Sie enthalten einen Microservice oder eine App und alles, was zu deren Ausführung erforderlich ist. Der gesamte Inhalt eines Containers wird in einem Image abgebildet. Dies ist eine codebasierte Datei, die alle Libraries und Abhängigkeiten enthält. Da sie den Kernel des Host Systems benutzen und kein eigenes Betriebssystem mitbringen, sind sie viel leichtgewichtiger als virtuelle Maschinen.
Vielen Dank für die Beispiele. Ich denke das konnte man ganz gut verstehen. Nun aber mal ganz unter uns: Wieso haben Sie Ann Sibel überhaupt mit in ihr Team genommen?
Herr Archie Tex-Ture
Ausschlaggebend bei der Wahl der neuen Kollegin war die von uns verwendete Architektur. Viele Tools tendieren zu einer Server Client Architektur die bei uns jedoch eher schlecht funktioniert hätte. Uns war es wichtig, dass wir nicht erst noch einen Client auf den Raspberry Pi’s installieren müssen. Das hätte ja auch einfach wieder unnötig Ressourcen verschenkt. Das IaC-Tool sollte demnach das komplette Setup übernehmen. Ansible benötigt keinen Client, um eingesetzt zu werden. Von einem externen Host – in unserem Fall einfach ein Laptop -, können die Setup-Playbooks gestartet werdet. Vielleicht fragen Sie sich jetzt: Hä? Was sind Playbooks? Das ist nicht irgendein Mandala-Ausmalbuch, wie ich zunächst dachte, sondern das kann man sich wie ein Kochrezept vorstellen, das die Abfolge unseres Projektes beinhaltet. Ansible baut dann eine Verbindung zu den Ziel Hosts – also unseren Raspberry Pi Computern – auf und führt die konfigurierten Befehle über eine sichere Netzwerkverbindung (SSH) aus. SSH bedeutet “Secure Shell” und ist ein Netzwerkprotokoll. Mehr ist an der Stelle nicht wichtig zu wissen. Man kann bei den Raspberry Pi Computern SSH ganz einfach aktivieren, indem man eine leere Datei mit dem namen “.ssh” in ihr root Verzeichnis legt. Aber das nur am Rande.
In der Tabelle, die Kollegin Infra Struc-Ture ihnen vorhin gezeigt hat ist SaltStack zwar ebenfalls als “Client only” System aufgezählt, jedoch entsprach dieses Setup nicht ganz unseren Vorstellungen. Ohne zu weit in ein anderes Gebiet einzutauchen: Saltstack verwendet im Normalfall eine so genannte Master/Minions Architektur. Und nein ich spreche nicht vom gleichnamigen Universal Pictures Film. Bei einer solchen Architektur ist eine Komponente ein so genannter “Master” – er überblickt und überwacht alle ihm zugeordneten “Minions” oder auch “Nodes”. Kann man sich jedoch ähnlich wie in dem Trickfilm vorstellen – viele, viele wunderbare Mitarbeitenden, die Minions (“Nodes”) und einen Manager, Gru (“Master”). *lacht* Jetzt müsste man vermutlich den Film auch noch gesehen haben…
Das Gegenteil wäre eine masterless Architektur, bei der die Konfigurationsverwaltung von Salt für einen einzelnen Rechner genutzt werden kann – also ist der Rechner quasi gleichzeitig Master und Minion. Somit hätten wir wieder etwas manuell einrichten müssen, bevor wir das automatische Setup vornehmen können.
Jetzt haben wir einiges über Salt und Ansible gehört. Mich würde nun genauer interessieren wie Sie Frau Ann Sibel die Arbeit Ihrer Kollegen erleichtern konnten.
Frau Ann Sibel
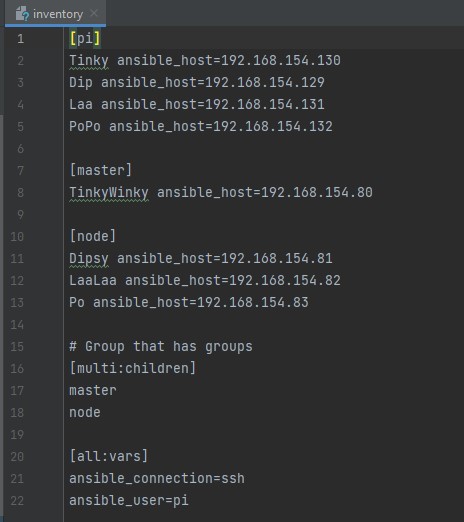
Ich habe mich von Anfang an einfach sehr wohl gefühlt in der Gruppe. Gerade mit der Hardware Komponente der Raspberry Pi’s bin ich ja sowieso vertraut und hab mich dann auch echt gern der Aufgabe angenommen. Mein Lebensmotto ist das strukturierte Unterteilen von Aufgaben in klar definierte Klassen und Objekte. Ich Unterteile daher gern alle meine Aufgabenbereiche in Inventory, Playbooks, Tasks, Module, Handler und Rollen. Zumindest in diesem Projekt. *lacht* Natürlich gibt es hier noch viel mehr, was ich aufzählen könnte, aber das sind auf jeden Fall mal die Wichtigsten. In der Datei “Inventory” halte ich alle Knoten fest auf die zugegriffen werden sollen. Sie enthält IP-Adressen und oder Namen der verfügbaren Hosts. Ebenfalls können diese Einträge auch gruppiert werden. Das kann man sich vorstellen, wie in einem Mehrfamilienhaus. Es gibt verschiedene Parteien, in der unterschiedliche Personen oder Familien wohnen. Und das “Inventory” ist quasi die Sammlung der Klingelschildern am Eingang. Wenn jetzt Parteien umziehen sollen, dann weiß ich ganz genau Bescheid wohin und kann die Adressen bzw. Klingelschilder entsprechend anpassen. Hier habe ich Ihnen noch einen Ausschnitt aus unserem Projekt mitgebracht. Finden Sie nicht auch, dass das Inventory so schön aufgeräumt ist?! Ich freue mich immer wieder aufs Neue, wenn ich einen Blick darauf werfen kann.
Mal ehrlich, was hilft uns denn jetzt das Wissen über die IP-Adressen der Ziel-Hosts? Wieso der Aufwand?
Frau Ann Sibel
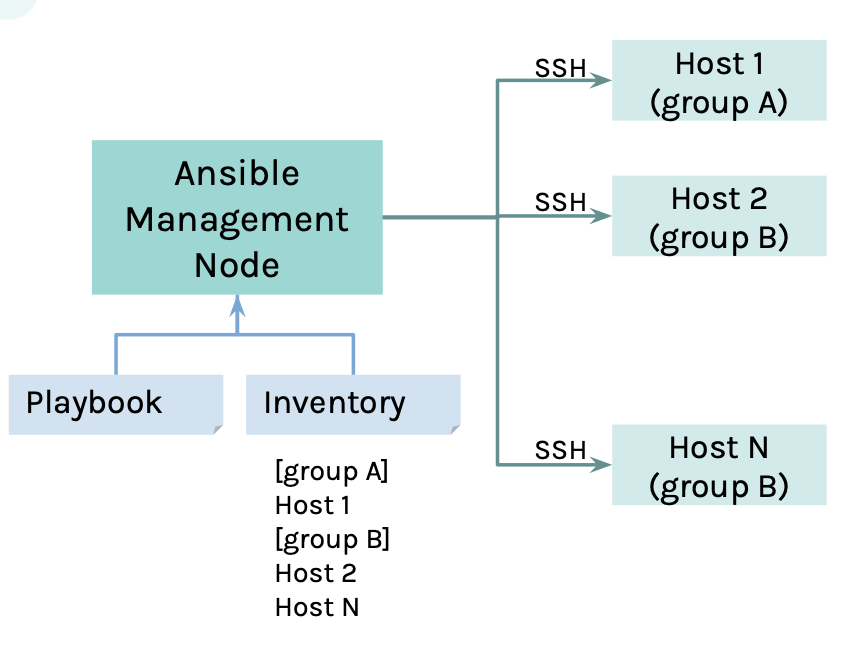
Sie wollen jetzt sicher genauer wissen, wie sie uns bei der Automatisierung helfen. Ganz einfach: Mithilfe der IP-Adressen können wir uns mittels SSH auf die Hosts verbinden. Dort verteilen wir kleine Programme, die sogenannten “Ansible-Module” – die wir vorher selbstverständlich in den Playbooks beschrieben haben. Anschließend werden diese Module ausgeführt und nach Fertigstellung wieder entfernt. Auch hier habe ich Ihnen mal eine Zeichnung zur Veranschaulichung mitgebracht.
Mein Kollege hatte ja bereits die Playbooks erwähnt. Ein Playbook enthält mehrere Aufgabenbeschreibungen – so genannte Tasks – und ist eine einfache yaml-Datei – YAML ist das Dateiformat, abgekürzt .yml -, die in einer prozeduralen Sprache geschrieben ist. Die prozedurale Programmierung ist eine Art der strukturierten Programmierung. Mit ihr wird eine Gesamtaufgabe, die softwaremäßig gelöst werden soll, in kleinere Teilaufgaben unterteilt
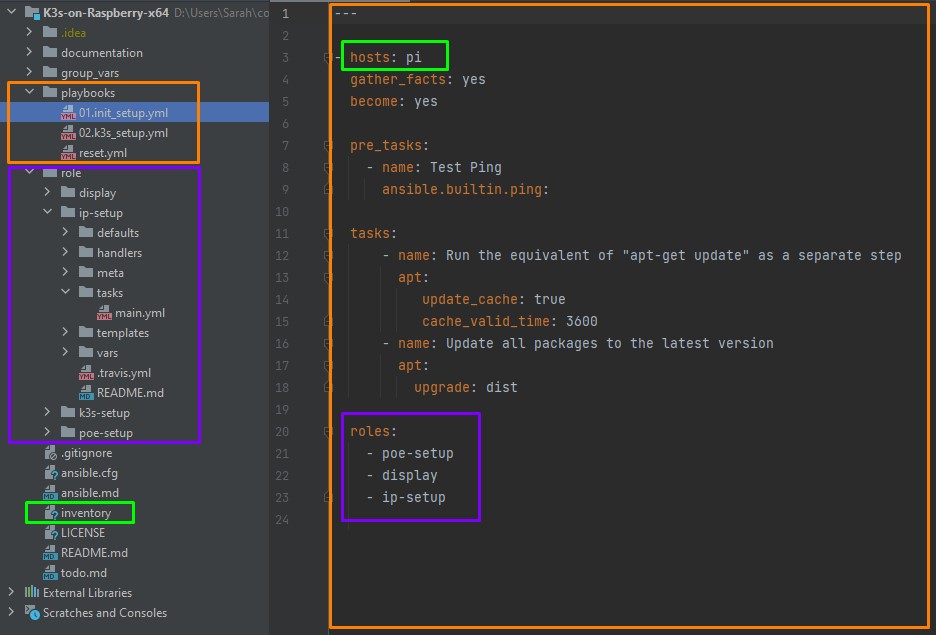
Playbooks sind dafür da, die Einrichtung eines Systems zu dokumentieren. Ein Task dient dabei immer einem bestimmten Ziel, z. B. der Einrichtung eines Webservers oder der Bereitstellung einer Anwendung. Die Aufgaben werden in der gleichen Reihenfolge ausgeführt, in der sie in einem Playbook definiert sind. Also wie ein Kochrezept. Sie befolgen es von oben nach unten. Ich habe mal ein Playbook aus unserem Projekt mitgebracht (Abbildung 1 orangener Kasten). Wie Sie sehen befinden wir uns hier in der Datei “01.init_setup.yml”. Die Zeile 3 definiert die Hostgruppe aus der Inventory Datei, auf der das Playbook ausgeführt werden soll. In unserem Fall sollen die Tasks auf allen Hosts (bei uns sind das die Raspberry Pi Computer) der Gruppe “pi” ausgeführt werden. Neben Tasks gibt es auch noch Pre-Tasks welche, wie der Name schon suggeriert, vor den Aufgaben, die in der .yml-Datei genannten sind, ausgeführt werden sollen.
Die eben bereits angesprochenen Module sind Befehle, die etwas tun (z. B. eine Rechtsinstanz erstellen, sicherstellen, dass ein Verzeichnis vorhanden ist, ein Paket aktualisieren usw.). Sie sind einzelne Code Einheiten, die über die Befehlszeile oder in einem Playbook-Task verwendet werden können. Tatsächlich gibt es bereits mehr als 2000 Module die für alle frei verfügbar sind. Ich hab Ihnen hier mal den Link zu meiner Seite mitgebracht: https://docs.ansible.com/ansible/2.9/modules/list_of_all_modules.html Wir verwenden sie bei uns im Projekt in unseren Playbooks. Zum Beispiel das Modul “shell/command”. Man kann es verwenden, um alle Befehle auszuführen, für die kein Modul existiert. Ich, Ann Sibel, führe jedes Modul in der Regel auf dem entfernten Zielknoten aus und sammle die Rückgabewerte ein. Ein Modul, welches wir unter anderem in unserem Projekt verwendet haben, ist das Modul “ansible.builtin.ping”. Dies ist ein Bestandteil des Ansible-Core – also quasi eine Standardfunktion. Mit ihr wird eine Verbindung zum Ziel-Host aufgebaut. Wir klopfen also einmal an und schauen ob jemand zuhause ist. Konnte der Host erreicht werden wird ein “pong” als Rückgabewerte zurückgegeben. Das ist ganz praktisch um zu kontrollieren ob wir eine valide IP haben, ein Host korrekt hochgefahren und erreichbar ist.
Um doppelten Code zu Vermeiden können so genannte Rollen verwendet werden. Diese nennt man Kapsel-Konfigurationen für wiederverwendbare Aufgaben. Einzelne Rollen stehen auch hier wieder frei zur Verfügung. Hier bietet meine Cousine Ansible Galaxy über 4000 Rollen die integriert werden können an. Auch hier mal der Link zu ihrer Seite: https://galaxy.ansible.com
Nicht zu vergessen sind Handler. Handler Aufrufe befinden sich genau wie die normalen Tasks (Aufgaben) in einem meiner Ansible-Playbooks. Diese Aufgaben werden jedoch nur dann ausgeführt wenn eine Änderung an einem Rechner vorgenommen wurde. Eine Aufgabe also zwingend notwendig ist. Als Beispiel: Ich muss einen Host neu starten, weil ich zuvor eine wichtige Konfiguration abgeändert habe. Was wichtig und zu beachten ist: Handler-Aufgaben werden nur ausgeführt wenn die Handler mittels “notify” benachrichtigt werden. Die einzelnen Tassk befinden sich dann in der zugehörigen Handler Datei (siehe blaues Kästchen). Handler werden immer am Ende einer Playbooks ausgeführt, auch wenn diese bereits am Anfang benachrichtigt werden. Ist das zu spät kann mittels “meta: flush_handlers” das Ausführen des Handlers zu einem früheren Zeitpunkt erzwungen werden.
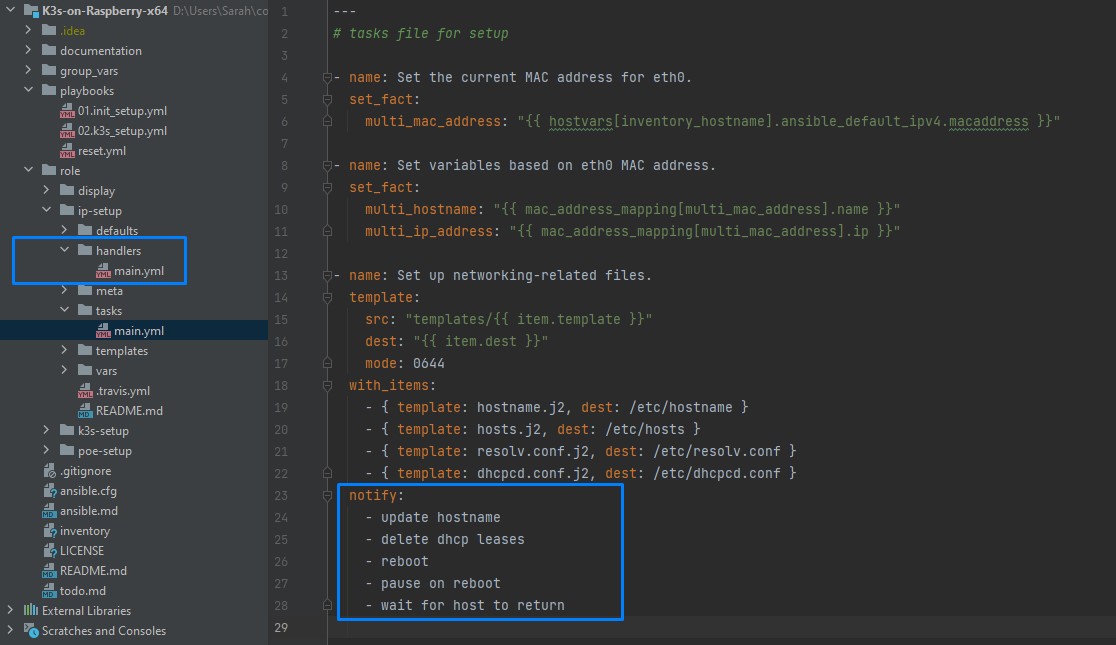
In unserem Projekt haben wir also Playbooks geschrieben und diese haben für uns dann die Raspberry Pi’s konfiguriert. Es waren keine manuellen Anpassungen an der Hardware mehr notwendig. Alles automatisiert.
Klasse! Nochmal zu dem Projekt: Wir haben vorhin am Rande gehört, dass eins der Ziele die Bereitstellung eines K3s Clusters war. Können Sie Herr Kah Dreis uns hierzu mehr erzählen?
Herr Kah Dreis
Natürlich sehr gerne. Wie Sie bereits erwähnten war eines unserer Ziele das Ausrollen eines K3s Clusters. Um genau zu sein, war es uns anfangs jedoch erst einmal nur wichtig ein Container Orchestrierungs Tool auf unseren Raspberry Pi’s zu haben. Für uns haben sich also die Fragen gestellt: Was ist das geeignete Tool? Was läuft performant? Und vor allem – Was lässt sich gut ausrollen?
Aber ich möchte nochmal mehr auf das Thema “Container Orchestrierung” eingehen: In modernen Entwicklungsprozessen werden Anwendungen nicht mehr monolithisch programmiert. Es gibt also meist nicht mehr nur eine riesige Anwendung sondern Aufgaben sind in kleine Anwendungen aufgeteilt. Sie setzen sich somit aus mehreren hunderten von lose miteinander verknüpften und in Containern enthaltenen Komponenten zusammen. Damit die Anwendung in der gewünschten Weise funktioniert, müssen alle Komponenten zusammenarbeiten.
Container Orchestration bezieht sich auf den Prozess des Organisierens der Funktionsweise einzelner Komponenten und der Anwendungsebenen. Ähnlich wie ein Dirigent der im Orchester dafür sorgt, dass ein harmonisches Zusammenspiel aller beteiligten Musiker das gewünschte Ergebnis erzeugt. Es sorgt also immer dafür, dass der definierte Endzustand erreicht wird. Bedeutet, fällt beispielsweise ein Container aus, und es wurde definiert, dass immer ein Container laufen muss, wird ein neuer erstellt. Auch das Bild des Steuermanns, der auf Griechisch “Kubernetes” genannt wird, verdeutlicht die Funktion dieser nützlichen Tools. Die Open Source Software “Kubernetes” ist mittlerweile der Quasi-Standard der Container-Verwaltung.
Ah stimmt, uns ist zu Ohren gekommen, dass Sie Herr Kah Dreis (k3s) mit Kubernetes (k8s) verwandt sind. Stimmt das?
Herr Kah Dreis
Das ist richtig. Wir unterscheiden uns in unseren Grundfunktionen nicht. Jedoch kann ich von mir behaupte, dass ich Anwendungen wesentlich schneller bereitstellen kann. Ebenfalls gelingt es mir Cluster schneller hochzufahren. Ich wurde zudem speziell ausgebildet um als leichtgewichtiger Container-Orchestrierer zum Ausführen von Kubernetes auf Bare-Metal-Servern zu agieren. “Bare Metal” aus dem Englischen quasi “blankes Metall”. Kubernetes ist hingegen eher ein Allzweck-Container-Orchestrierer. Ein weiterer Punkt der uns unterscheidet ist unser Einsatz von “Kubelet”. “Kubelet” ist ein Agent, der auf jedem Kubernetes-Knoten ausgeführt wird. Er stellt sicher, dass Container in einem “Pod” ausgeführt werden. Pods kann man sich vorstellen wie die Hülle um Erbsen. In ihr können ein oder mehrere Container laufen. Diese teilen sich dann dieselben Ressourcen wie Speicher.
Dieser Agent wird bei Kubernetes innerhalb eines Containers ausgeführt. Ich hingegen führe Kubelet direkt auf dem Hostcomputer aus und verwendet den Planungs Mechanismus des Hosts, um Container auszuführen. Auch hier können Sie sehen, dass ich wesentlich besser mit den mir zur verfügung stehenden Ressourcen umgehe. Aufgrund meiner geringen Größe bin ich also bestens geeignet um auf IoT-Geräten wie Raspberry Pi’s zu arbeiten. Kubernetes wäre auf einem Raspberry Pi nicht lauffähig. Außerdem kann ich auf verschiedenen Prozessor-Architekturen wie AMD64, ARMv7 und ARM64 eingesetzt werden.
Ich muss aber auch ehrlich sein: Es gibt vieles in dem Kubernetes besser ist als ich. Oder besser gesagt, es kommt auf den Anwendungszweck an. Mit Kubernetes kann Workload beispielsweise in mehreren Umgebungen ausgeführt werden, während ich lediglich Workloads hosten kann, die in einer einzigen Cloud ausgeführt wird. Ich wäre einfach nicht stark genug die Arbeitslast auf mehreren Clustern aufrecht zu halten.
Herr Archie Tex-Ture – Mich interessiert nun Ihre Meinung zu Ihrem Kollegen Kah Dreis – Gab es auch noch andere Kandidaten die als Container-Orchestrierer infrage kamen?
Herr Archie Tex-Ture
Um ehrlich zu sein, ja. Heutzutage gibt viele Tools die ein vollwertiges Kubernetes Cluster mehr oder weniger gut ersetzen können. Jedes dieser Tools hat seinen speziellen Einsatzzweck und somit auch seine Vor- und Nachteile im Vergleich zu dem jeweiligen Use Case. Es war am Ende ein knappes Rennen zwischen “Minikube”, “kind” und “k3s”. Ich glaube der Charakter von Kah Dreis hat uns schließlich überzeugt. *lacht*
Wie Sie auch der Tabelle, die ich ihnen hier mitgebracht habe, entnehmen können wurde “Minikube” speziell für Virtuelle Maschinen (VM’s) entwickelt. Es wird eine VM erzeugt, die im Wesentlichen ein K8s-Cluster – K8s ist quasi unser Spitzname für “Kubernetes” – mit einer Node ist. Der Einsatz von parallelen Instanzen (mehrer Cluster nebeneinander) ist hier problemlos möglich.
“Kind”, damit ist nicht etwa mein Sohn, sondern ein Cluster welches in Docker-Containern läuft, gemeint. Hier müssen im Vergleich zu Minikube keine Virtuelle Maschinen gestartet werden und daher hat “Kind” eine wesentlich schnellere Startgeschwindigkeit. Auch hier ist die Bereitstellung mehrerer parallel laufender Instanzen möglich.
Wie er schon selbst gesagt hat ist Kah Dreis (K3s) eine Mini-Version von Kubernetes. Es wurde im Gegensatz zu den beiden anderen Tools, welche Kubernetes SIGs Projekte sind, von “Rancher Labs” entwickelt. Das ist eine andere Firma. Durch das Entfernen von Funktionen, und dem Verwenden leichtgewichtiger Komponente, wie der standardmäßig verwendeten SQLite Datenbank anstatt einem “etcd” (verteilter Key-Value-Store) konnte eine deutliche Verkleinerung erreicht werden. Neben einer SQLite Datenbank unterstützt K3s PostgreSQL, MySQL, MariaDB und etcd. K3s wurde entwickelt um nativ auf mehreren Hosts zu laufen. Die Anwendung sieht eine Server Agent Architektur vor. Der Server fungiert hierbei als Manager während sich die Agents wie die Worker bei Kubernetes um den eigentlichen Workload kümmern. Natürlich kann der Server, sowie die Agents auch in VMs oder Containern laufen. In diesem Fall ist auch K3s in der Lage mehrere Instanzen parallel laufen zu lassen.Das war jetzt doch recht fachlich, falls Sie da aber nochmal mehr dazu wissen wollen empfehle ich Ihnen diesen Link: https://rancher.com/docs/k3s/latest/en/installation/datastore/ Zudem habe ich auch nochmal eine Vergleichstabelle mitgebracht.
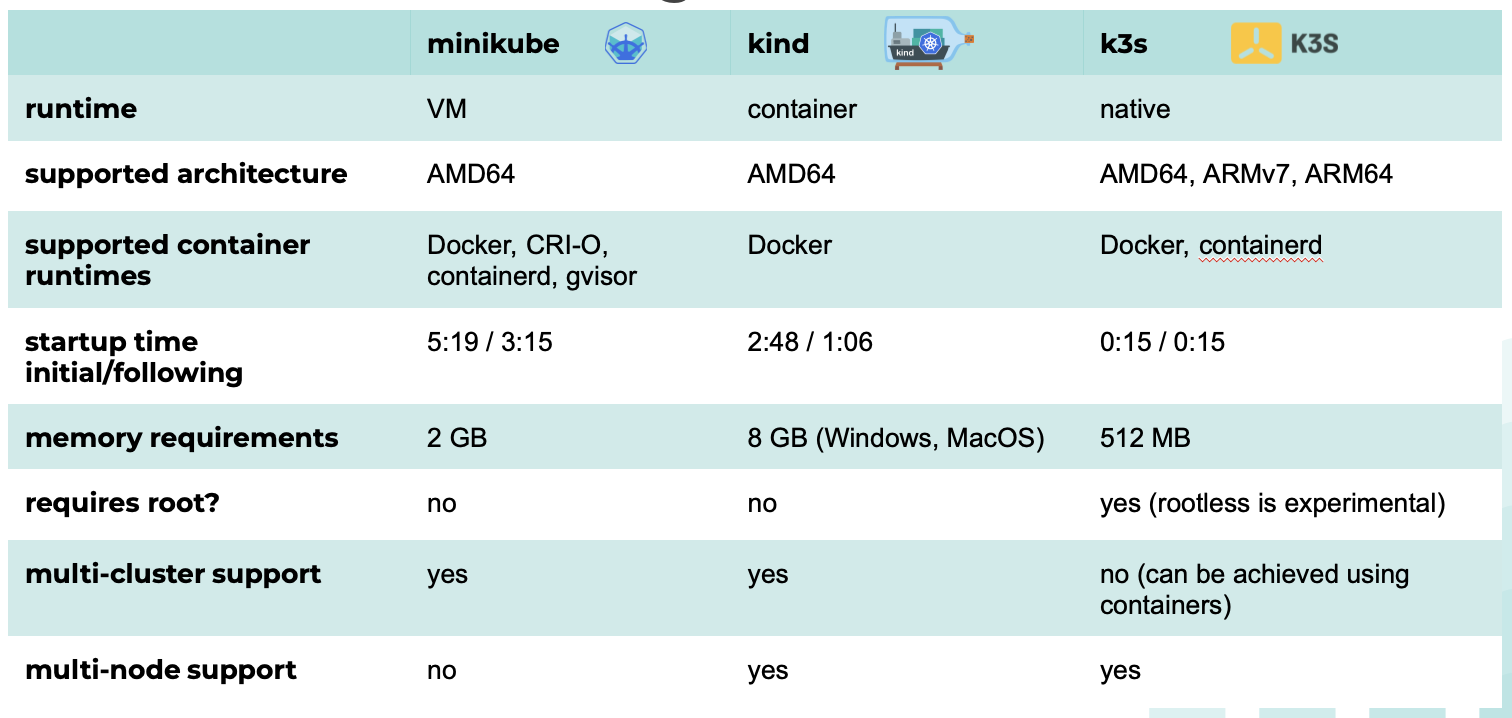
Was uns vor allem für unser Projekt überzeugt hat, war neben der geringen Anforderung an Speicherkapazität, die native ARM64 Unterstützung. Und jetzt läuft auch echt alles super.
Wenn Sie jetzt sagen, dass alles läuft. Wie beweisen Sie das? Haben Sie irgendwelche Testverfahren eingesetzt um das zu überprüfen?
Herr Archie Tex-Ture
Ich antworte einfach nochmal: Naja, sie müssen beachten, dass Ansible-Ressourcen Modelle sind, die einen gewünschten Zustand definieren. Es sollte daher nicht notwendig sein irgendetwas speziell zu testen. Wenn Dienste gestartet, Pakete installiert oder andere Dinge erfolgt sind, dann teilt uns Ann Sibel das direkt bei der Ausführung ihres Playbooks mit. Ann Sibel ist das System, das sicherstellt, dass diese Dinge deklarativ wahr sind. Hierzu werden die Rückgabecodes von Befehlen automatisch überprüft. Konnte beispielsweise ein User nicht angelegt werden, wird die Ausführung des Playbooks sofort gestoppt.
Es ist sinnvoller die Anwendung, welche bereitgestellt wird, zu testen. Kann der Webserver nach der Einrichtung das Systems erfolgreich angesprochen werden? Ist das K3s Cluster erreichbar und gesund? Oder wollten Sie auf diese Fragen etwa hinaus?
Ja genau. Erzählen Sie uns gern mehr darüber.
Frau Ann Sibel
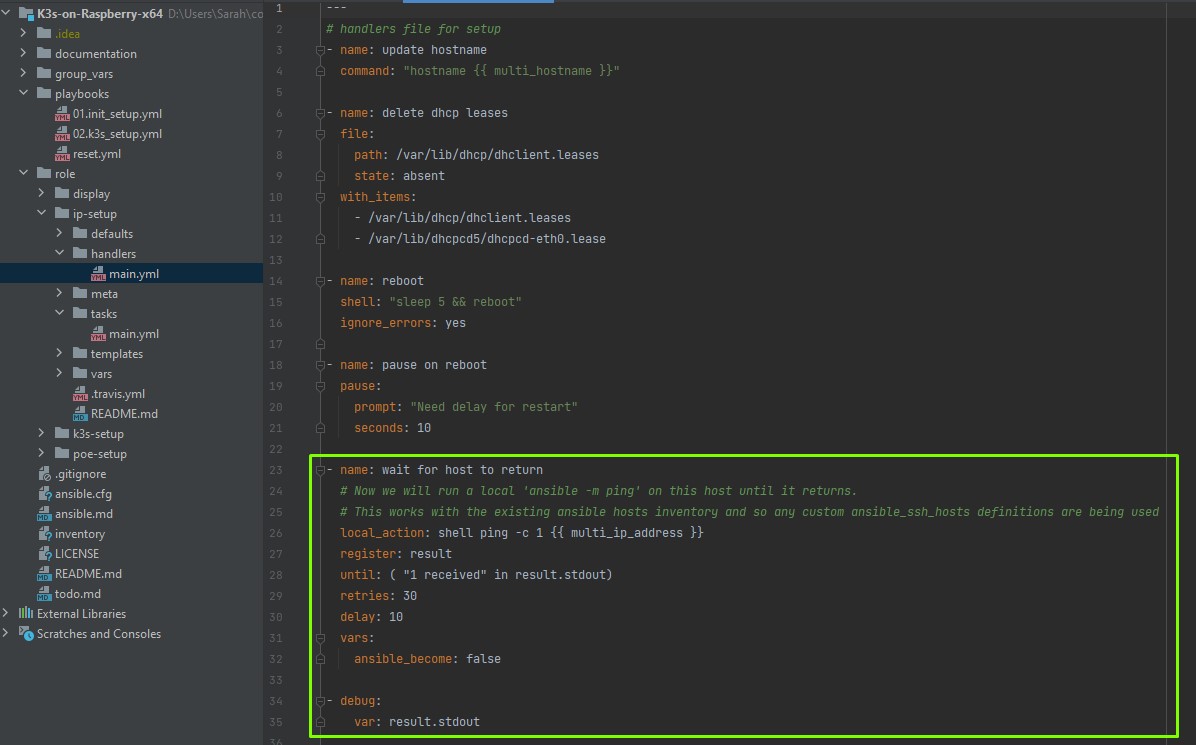
Diesmal antworte ich, denn ich habe Ihnen sogar einen Auszug aus unserem Quellcode mitgebracht. Hier sehen wir ein Beispiel für einen Test den wir in unserem Projekt durchgeführt haben. Zu sehen sind Handler, welche nach der Umstellung auf eine statische IP-Adresse ausgeführt werden. Interessant ist der Task “wait for host to return” und der anschließende “debug”-Task, der das Ergebnis unseres Tests beinhaltet.
Nachdem die statische IP-Adresse konfiguriert und die Nodes neu gestartet wurden, sind die Hosts nicht mehr unter der alten IP-Adresse erreichbar. Wir pingen also die IP’s der im Inventory definierten Gruppe “multi” an. Ein solcher Neustart kann ein wenig Zeit beanspruchen. Damit keine Fehler entstehen, haben wir ein retry (Wiederholungszyklus) von 30 Sekunden angegeben, mit einem jeweiligen delay (Verzögerung) von 10 Sekunden. Konnte eine Verbindung aufgebaut werden – oder der Wiederholungszyklus ist erschöpft – so bricht der Task ab und speichert sein Ergebnis in die Variable “result”. Dieses geben wir mittels “result.stdout” in der Konsole aus. Und voila! Wir können sicherstellen, dass die Umstellung der IP-Adressen erfolgreich war.
Interessant. Aber sagen Sie: Mit Sicherheit gab es auch Probleme, auf die Sie bei ihrem Projekt gestoßen sind, oder? Wie haben Sie diese gelöst?
Frau Infra Struc-Ture
Eines unsere Hauptprobleme war die Beschaffung der Raspberry Pi’s. Aufgrund des, zu dieser Zeit vorherrschenden Chipmangels, wurden pro Person jeweils nur 2 Pi’s verkauft. Hier mussten wir ein wenig tricksen, was jedoch mit höheren Kosten verbunden war als noch ein halbes Jahr zuvor. Das ist schade aber am Ende bekamen wir nach einer längeren Wartezeit dann auch unsere Hardware. Es war wie ein zu frühes Weihnachtsgeschenk. Außerdem hatten wir uns zu Anfang auf Grundlagen eines Tutorials verlassen. Das ist nicht immer empfehlenswert. Bis zu einem gewissen Punkt hat es uns gut geholfen in die Themen hinein zu kommen, aber es wurde viel zu viel Vorwissen vorausgesetzt und für selbstverständlich genommen. Das war zum Teil wirklich frustrierend. Wir mussten vieles selbst nachforschen, da die Dokumentation des Tutorials unzureichend waren. Und der Hammer war dann, dass etwa Befehle verwendet wurden, die längst veraltet und auf “deprecated” gesetzt waren. Das war eine doofe Erkenntnis. Aber auch erleichternd, denn so haben wir Ann Sibel ins Team bekommen – uns mit ihren Playbooks selbst beschäftigt – und dann ein echt cooles Projekt auf die Beine gestellt. Außerdem wurden wir in das Thema “Netzwerktechnik” quasi hinein geworfen. Das stellte sich auch als erfrischend raus. Wir wissen jetzt besser Bescheid als zuvor und es hat Spaß gemacht mal im eigenen Haus ein bisschen “Systemadministratorin” zu spielen. Ein weiteres Problem war, da stand ich wirklich wie die Kuh vor dem Berg, wie man auf seine Pi Computer zugreifen kann. Zum Glück gab es die Möglichkeit sich mit mini-USB einen Bildschirm und Tastatur anzuschließen – und nach weiterer Recherche kamen wir dann auch auf den “Trick” mit SSH. Was auch problematisch war, war die Wahl des Betriebssystem für den Raspberry Pi. Wir wussten, die Prozessor Architektur ist ein x64 Prozessor aber konnten offiziell nur das 32bit Betriebssystem von Raspbian finden. Nach unserer Recherche haben wir dann das sich in der Beta-Version befindliche Bullseye x64 Lite gefunden. Für unser Projekt hat das zum Glück relativ gut geklappt und es gab wenige Probleme. Wir haben viel Debugging betrieben um die Fehler herauszufinden, wenn es welche gab. Unser letztes, größeres Problem war, dass wir davon ausgegangen sind, dass “Power over Ethernet” (PoE) – damit wir uns die Kabel für die Stromversorgung zu den einzelnen Pi’s sparen können – dasselbe ist wie PoE+. Oder besser gesagt uns war nicht bewusst, dass es da mehrere Versionen gibt. Es stellt sich heraus, dass PoE+ mehr Strom und daher eine andere Form von Netzwerk-Switch benötigt. Das war uns zuvor noch nicht ganz klar. Wir hatten also Hardware, die nicht miteinander harmoniert hat.
Wenn Sie das Projekt noch einmal machen würden, was würden Sie anders machen?
Frau Infra Struc-Ture
Die Anlaufphase von Projekten kann recht langwierig sein. Bis man sich in einem Team einig ist, welche Ziele verfolgt werden wollen, können schon ein paar Wochen ins Land gehen. Besser ist es zum Schluss jedoch allemal – denn es macht einfach mehr Spaß – gemeinsam zu arbeiten und was auf die Beine zu stellen!
Von Projekt-Seite her würde mich persönlich nur interessieren, ob alles klappen würde, wenn wir mehr nodes – also noch mehr Raspberry Pi Computer – in unser Cluster mit aufnehmen und anschließen würden. Und vielleicht wäre auch spannend zu sehen, welche Ressourcen konkret verbraucht werden – zB. die Implementierung eines Dashboards zur Überwachung oder so. Fragen wie: Wie warm wird das Ganze? Wann brauche ich einen Lüfter/Wasserkühlung um mehr Leistung aus dem Cluster zu holen? Und zu guter Letzt würden wir uns im Team alle freuen, wenn das x64 Bullseye Betriebssystem von Raspberry noch in einer stabilen Version veröffentlicht würde. Dann gäbe es auch hoffentlich etwas weniger zu debuggen.
Ich bedanke mich im Namen des gesamten Interview-Teams recht herzlich bei Ihnen für das Interview und wünsche Ihnen für ihre weitere Zukunft alles Gute.
Quellenverzeichnis
[1] Bild zu Raspberry Pi: https://www.heise.de/select/make/2019/4/1566295759078064
[2] Raspberry Pi: https://www.raspberrypi.com/products/raspberry-pi-4-model-b/
[3] Prozessor Architektur Pi: https://raspberrytips.com/raspberry-pi-os-64-bits-vs-32-bits/
[4] Kubelet: https://kubernetes.io/docs/reference/command-line-tools-reference/kubelet/
[5] IONOS: https://cloud.ionos.de/managed/kubernetes
[6] Infrastructure as Code: https://www.cloudcomputing-insider.de/
was-ist-infrastructure-as-code-iac-a-917671/
[7] Procedural Language
[8] Chef: https://docs.chef.io/server/install_server_ha/
[9] Ansible: https://www.ansible.com
[10] Terraform: https://www.terraform.io
[11] SaltStack: https://saltproject.io
[12] Puppet: https://puppet.com
[13] Tabelle – Vergleich: IaC Tools https://www.ibm.com/
cloud/blog/chef-ansible-puppet-terraform
[14] Configuration-Management: https://www.atlassian.com/de/continuous-delivery/principles/configuration-management
[15] Orchestrierung: https://www.redhat.com/de/topics/containers/what-is-container-orchestration
[16] Mutable vs. Immutable: https://www.bridge-global.com/blog/mutable-vs-immutable-infrastructure/
[17] Container: https://www.dev-insider.de/was-sind-docker-container-a-597762/
[18] SSH: https://www.ionos.de/digitalguide/server/tools/secure-shell-ssh/
[19] Minions Film: https://www.illumination.com/movie/minions/
[20] Zeichnung Ansible Management: http://www.opslib.com/2020/04/what-is-ansible-how-ansible-works_23.html
[21] Ansible Galaxy: https://galaxy.ansible.com
[22] k3s – Lightweight Kubernetes: https://k3s.io
[23] Orchestrierung: https://www.hpe.com/at/de/what-is/container-orchestration.html
[24] Kubernetes: https://kubernetes.io
[25] Vergleich k3s vs. k8s: https://www.p3r.one/k8s-vs-k3s
[26] Minikube: https://minikube.sigs.k8s.io
[27] Kind: https://kind.sigs.k8s.io
[28] Rancher: https://rancher.com/docs/k3s/latest/en/installation/datastore/
[29] Tabelle – Minikube vs Kind vs k3s: https://www.jambit.com/aktuelles/toilet-papers/minikube-vs-kind-vs-k3s-welches-lokale-kubernetes-cluster-eignet-sich-am-besten/
[30] Ansible Test Strategies: https://docs.ansible.com/ansible/latest/reference_appendices/test_strategies.html
[31] Chipmangel 2021: https://www.zeit.de/news/2021-12/13/wie-der-chipmangel-entstanden-ist?utm_referrer=https%3A%2F%2Fwww.google.com%2F
[32] Tutorial geerlingguy: https://github.com/geerlingguy/ansible-role-kubernetes
[33] PoE vs. PoE+: https://community.fs.com/de/blog/poe-switch-types.html
Leave a Reply
You must be logged in to post a comment.