
*zumindest im Bereich georeplizierter Datenbanken
Wir leben in einer globalisierten Welt, in welcher wir Anwendungen auf der ganzen Welt nutzen können. Egal wo wir gerade sind, können wir auf diese Programme und Daten zugreifen. Doch diese Möglichkeit stellt Softwaresysteme heutzutage vor große Herausforderungen. Nutzer möchten so schnell wie möglich auf Daten zugreifen und gehen davon aus, dass die Daten, die sie bekommen auch korrekt und auf dem richtigen Stand sind. Um die Verfügbarkeit der Daten für die Nutzer zu erhöhen, werden moderne Datenbank- und Softwaresysteme repliziert. Das heißt es werden Kopien derselben Daten hergestellt und regelmäßig abgeglichen, um die Daten auf dem gleichen Stand zu halten. Moderne Anwendungen replizieren Daten also über geografische Regionen hinweg. Jedoch zwingen bestehende Datenbanksysteme, welche geografische Replikationen unterstützen, die Nutzer auf mindestens eines der folgenden Merkmale zu verzichten, um eine hohe Verfügbarkeit zu erreichen:
- Strict Serilizability: Bei strikter Serialisierbarkeit scheinen die Operationen in einer bestimmten Reihenfolge zu erscheinen, die mit der Echtzeit-Reihenfolge der Operationen übereinstimmen. Das heißt wenn zum Beispiel Operation A abgeschlossen ist, bevor Operation B beginnt, sollte A in der Serialisierungsreihenfolge vor B erscheinen. Die Serialisierbarkeit ist der Ausführungsplan für die parallele Ausführung mehrere Transaktionen. Es gibt die Reihenfolge vor, in welcher die einzelnen Operationen der Transaktion ausgeführt werden und es verhält sich wie ein System, das auf einer einzigen Maschine läuft und die Transaktionen sequenziell verarbeitet.
- Low-latency writes: Um strikte Serialisierbarkeit zu erreichen muss auf Schreibvorgänge mit geringer Latenz verzichtet werden. Um die strenge Serialisierbarkeit in georeplizierten Datenspeichern zu garantieren, muss es mindestens ein Koordinationsprotokoll geben, um einen Schreibvorgang auf alle Replikate zu übertragen. Genau diese Koordination ermöglicht zwar die strikte Serialisierbarkeit, erhöht aber die Latenzzeit bei jedem Schreibvorgang. Je weiter die Regionen voneinander entfernt sind, desto länger dauert es einen Schreibvorgang abzuschließen.
- High transaction throughput: Im Allgemeinen wird die Geschwindigkeit eines Datenbanksystems anhand des Transaktionsdurchsatzes gemessen, ausgedrückt als Anzahl der Transaktionen pro Sekunde. In replizierten Datenbanken kann es zu einer bereichsübergreifenden Koordinierung kommen, das heißt wenn bei Lese- und Schreibvorgängen auf eine weiter entfernte Region zugegriffen werden muss. Normalerweise sind die mit dem Nutzer verbunden Daten stark auf den physischen Standort des Nutzers ausgerichtet. Beliebige Transaktionen können jedoch auf mehrere Datenelemente zugreifen, wobei jedes Datenelement in einer anderen Region verwaltet wird. Hier muss schließlich wieder eine regionsübergreifende Koordinierung stattfinden, dies ist zeitaufwändig. Das Zeitfenster in den kollidierenden Transaktionen nicht ausgeführt werden können ist groß und der Transaktionsdurchsatz verringert.
Um die Probleme zu lösen, die sich zur Erfüllung der genannten Eigenschaften ergeben, gibt es unterschiedliche Ansätze. Ein Ansatz ist Determinismus. Was das genau heißt und wie es genau funktioniert wollen wir an dem System „SLOG“ genauer betrachten. SLOG ist laut dem Paper von Run et al. „SLOG: Serializable, Low-Latency, Geo-Replicated Transactions“ der erste Systementwurf, welcher alle drei genannten Eigenschaften erfüllt.
Nachdem im Folgenden die Probleme georeplizierter Datenbanken noch einmal genauer betrachtet werden, wird der Begriff Determinismus vor allem im Kontext von modernen Datenbanksystemen geklärt und das Prinzip wird anhand des Systems SLOG noch einmal genauer erläutert.
Was ist das Problem?
Die Probleme, die uns in replizierten Datenbanken begegnen, erschließen sich bereits aus der vorangegangenen Erklärung der drei Eigenschaften moderner Anwendungen. Im Folgenden wird das Ganze noch einmal Schritt für Schritt genauer betrachten und es wird klar, warum es zu diesen Problemen kommt.
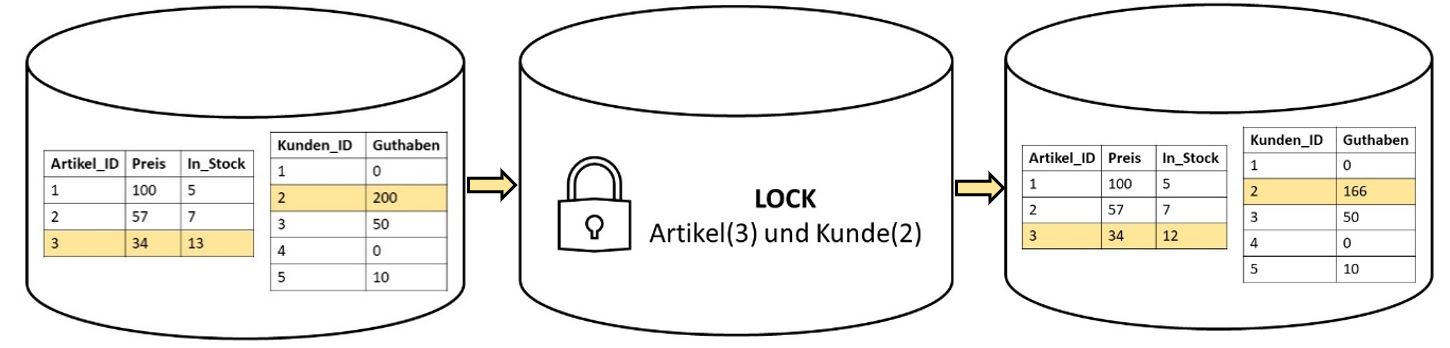
Single-Node-Datenbanken – Datenbanken, die für eine einzige Maschine konzipiert wurden – funktionieren sehr gut. Wenn Kunde 2 den Artikel 3 kaufen möchte, werden diese zwei Items gelocked und erst dann sind die Änderungen möglich (vgl. Abbildung 1). In einem einfachen Datenbanksystem ist die Serialisierbarkeit also ohne großes Zutun garantiert und über die anderen zwei Eigenschaften muss sich gar nicht gekümmert werden, da diese in diesem Kontext noch gar nicht wirklich relevant sind.
Bei Multi-Node-Datenbanken wird das ganze schon etwas schwieriger und es braucht ein bisschen mehr Anstrengung. Man spricht hierbei auch von einem Scalability Problem. Die Kunden und die Artikel sind nicht mehr wie im Single-Node-Beispiel auf einer Maschine, sondern auf vier Maschinen aufgeteilt. Jede Maschine nutzt nur den Code welcher relevant für ihn ist. Jedoch muss es irgendeine Kommunikation zwischen beiden Maschinen geben, die den Maschinen gegenseitig bestätig, dass jede Maschine das getan hat, was sie auch tun soll. Jede Maschine muss ihren Part der Transaktion eigenständig durchführen. Diese Kommunikationsproblem kann durch Locking oder auch durch eine Two-Phase-Commit-Protokoll gelöst werden (vgl. Abbildung 2). Hierbei ergibt sich jedoch aufgrund dieser Protokolle wieder ein neues Problem. Durch das gesamte Protokoll muss gelockt werden. Dies führt zu einer Reduzierung der Geschwindigkeit unserer Transaktionen, da die Zeiträume, über die die Locks gehalten werden müssen, lange sind.
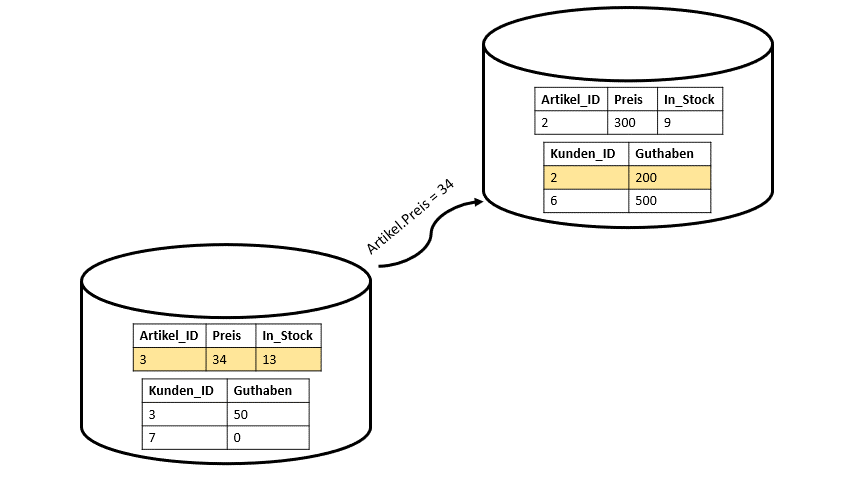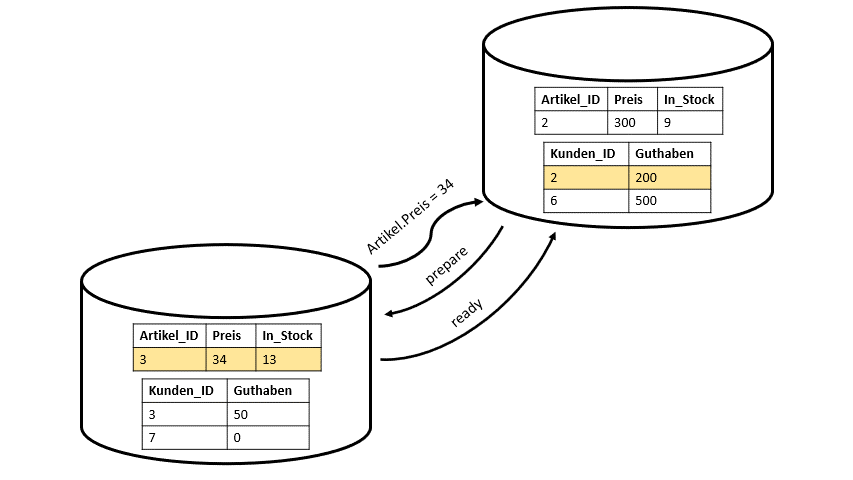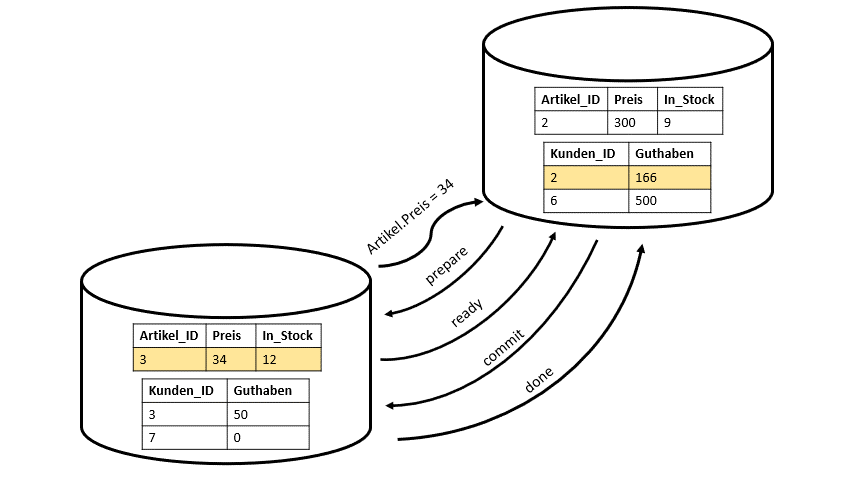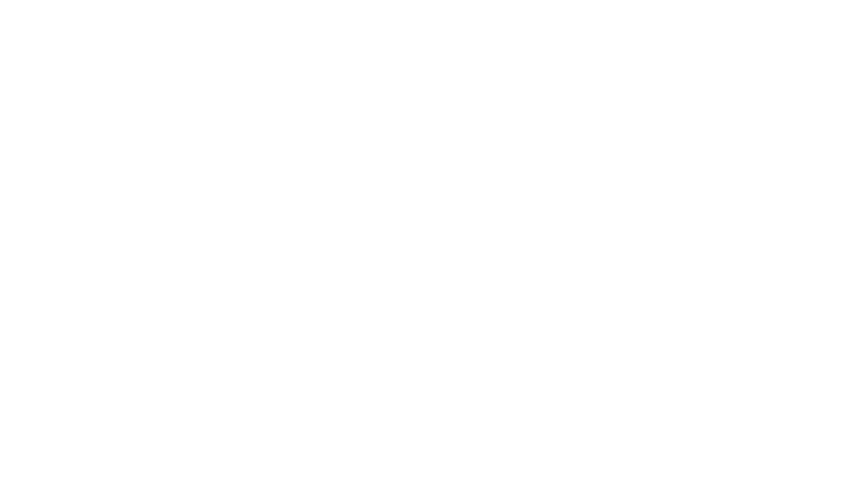
Wenn wir jetzt aber repliziere Datenbanken haben, also Kopien der Datenbank auf der ganzen Welt verteilt, müssen solche Locks noch viel länger gehalten werden, was noch mehr Zeit benötigt.
Durch das Nutzen von replizierten Datenbanken an verschiedenen Locations wird Nähe zu den Nutzern erreicht und um dadurch die Verfügbarkeit zu steigern. Hierbei wird eine Transaktion erst in der eigentlichen Location durchgeführt und danach – genauer gesagt nach dem das Commit-Protokoll durchgeführt wird – wird die die Datenbank synchron in allen Locations auf der ganzen Welt repliziert (vgl. Abbildung 3). Das Problem ist hier, wie bereits erwähnt, dass die Locks sehr lange gehalten werden müssen, bis die Replikation abgeschlossen ist.
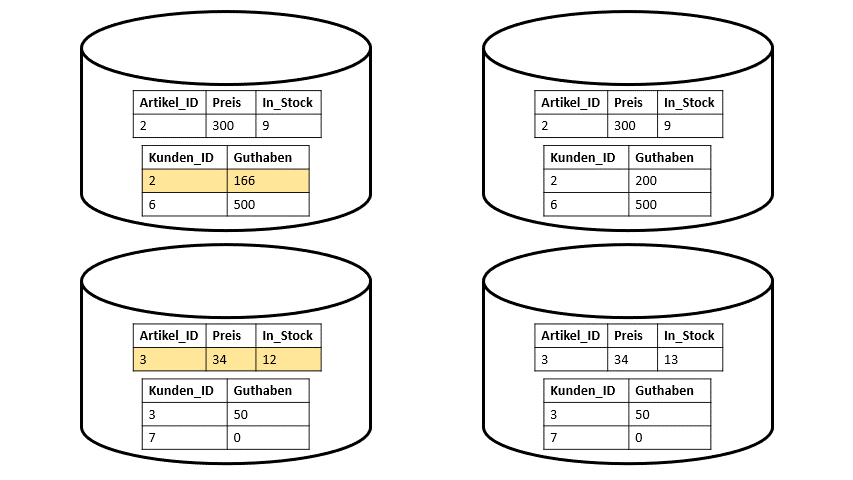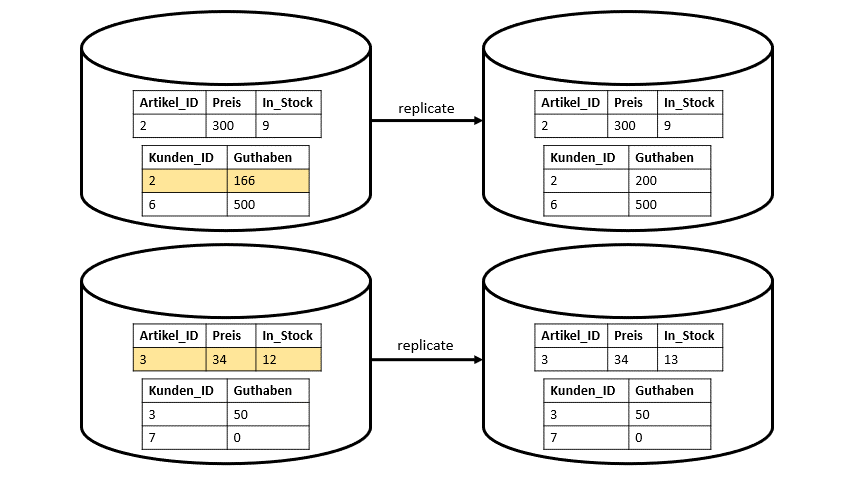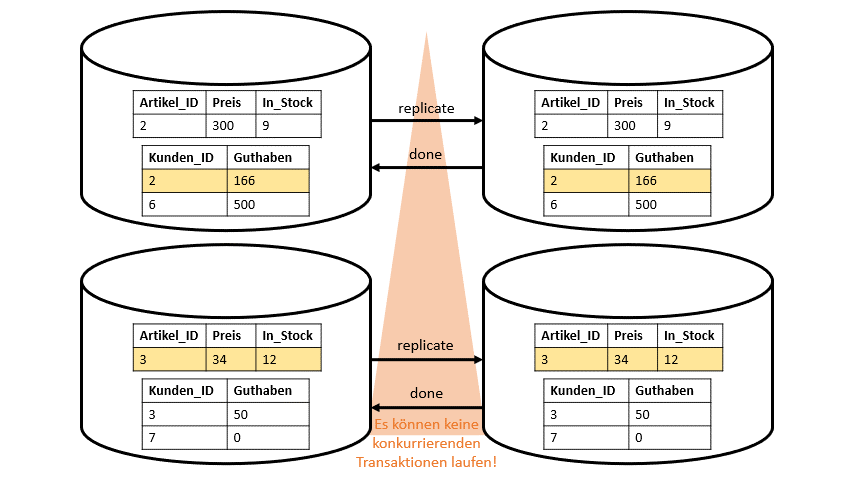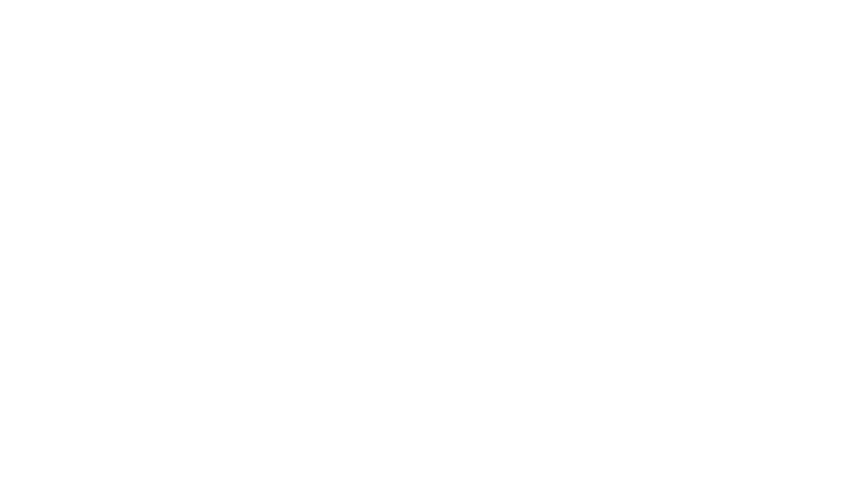
War es bei den Multi-Node-Datenbanken noch so, dass die Latenz vom Commit-Protokoll das Problem war, ist es bei replizierten Datenbanken nun die Latenz unseres Replikationsprotokolls. Beide Protokolle verursachen Latenzen durch das Halten von Locks.
Genau diese Herausforderung kann durch Determinismus gelöst werden.
Was ist Determinismus im Kontext von Datenbanken?
Determinismus gibt es in allen möglichen Fachgebieten, wie z.B. der Linguistik, der Biologie oder auch der Theologie. Laut Wikipedia ist „der Determinismus (von lateinisch determinare ‚festlegen‘, ‚Grenzen setzen‘, ‚begrenzen‘) die Auffassung, dass alle – insbesondere auch zukünftige – Ereignisse durch Vorbedingungen eindeutig festgelegt sind.“ Diese Definition trifft es im Zusammenhang mit verteilten Datenbanksystemen eigentlich schon ganz gut. Denn das ist was versucht wird in deterministischen Systemen zu erreichen. Genauer gesagt, wenn zwei getrennte Kopien des Systems die gleiche Eingabe sehen, dann sind sie in der Lage diese Eingabe unabhängig voneinander zu verarbeiten und aufgrund des Determinismus garantiert die gleiche Ausgabe (den gleichen Endzustand) zu ergeben.
Lange war die stärkste Garantie in Datenbanksystemen die Serialisierbarkeit. Hierbei wird sichergestellt, dass der Endzustand des Datenbanksystems auch bei der gleichzeitigen Verarbeitung vieler Transaktionen, dem entspricht, als hätte es alle Transaktionen seriell verarbeitet. Jedoch wird hierbei keine Garantie übernommen, in welcher seriellen Reihenfolge die Transaktionen verarbeitetet werden. Bei deterministischen Systemen wird aber die Äquivalenz einer seriellen Reihenfolge garantiert. Es gibt also eine Verarbeitung von Transaktionen in einer einzigen vorbestimmten seriellen Reihenfolge. Dadurch gibt es nur einen möglichen Zustand, in dem sich das System befinden kann, trotz des Vorhandenseins von potenziell nicht-deterministischem Code in der Transaktionslogik.
Um nur einen möglichen Endzustand zu erreichen, müssen moderne deterministische Datenbanksysteme bei einem Anfangszustand und einer definierten Eingabe in das System, die Eingaben vorverarbeiten.
Normalerweise arbeiten verschiedene Kommunikations-Threads, die es in bestehenden nicht-deterministischen Datenbanksystemen gibt, unabhängig voneinander. Für deterministische Datenbanksysteme ist diese Architektur nicht praktikabel, da Determinismus nur garantiert werden kann wenn es eine klare, allgemeine vereinbarte Eingabe gibt. Um diese Garantie aber zu erfüllen, muss eine Aufzeichnung der Eingabe erstellt werden, nach der sich das gesamte System richten kann. In einer Ein-Maschinen-Architektur zum Beispiel kann dies erreicht werden, in dem alle Transaktionen durch einen Thread geleitet werden, der die Eingabetransaktionen in der Reihenfolge aufzeichnet, in der er sie beobachtet.
Für die Erstellung eines solchen deterministischen Ausführungsplans für mehrere replizierte Datenbanksysteme im Vergleich zu herkömmlichen nichtdeterministischen Systemen ist mehr Wissen über die Transaktion erforderlich, bevor sie verarbeitet werden kann. Vor allem aber muss die gesamte Transaktion während des Planungsprozesses vorhanden sein. Außerdem erfordert die Vorausplanung in der Regel Kenntnisse darüber, auf welche Daten eine Transaktion zugreifen wird. Dieses Wissen wird entweder statisch aus der Inspektion des Transaktionscodes abgeleitet, durch konservative Schätzungen vorgenommen oder es werden Teile der Transaktion spekulativ ausgeführt. In georeplizierten, hochskalierbaren Systemen kann dies zum Beispiel durch ein Protokoll wie Paxos geschehen. Hierbei werden alle Transaktionen vor der Verarbeitung durch dieses Protokoll geleitet, um einen Konsensus über das System hinweg zu erzielen. Dies hat jedoch den Nachteil, dass jede Transaktion die regionsübergreifende Latenzzeit für die Ausführung von Paxos über die Regionen hinweg bezahlen muss.
Jedes System sieht in einem deterministischen System durch ein Konsensus-Protokoll wie Paxos dieselbe Eingabetransaktion, und solange sie dieselbe Eingabe sehen, werden sie in denselben Endzustand gelangen. Die einzige Koordination, die in einem deterministischen Datenbanksystem noch stattfinden muss, ist die Kommunikation, die erforderlich ist, um sich über die Eingabe in das System zu einigen. Jegliche andere Kommunikation wie zum Beispiel Locking oder Two-Phase-Commit-Protokolle werden dann nicht mehr benötigt und Determinismus verringert dadurch die Latenzzeit und verbessert den Durchsatz.
Die einzige Latenz, die wir jetzt noch haben ist die des Konsensus-Protokolls. Dies kann mit dem System SLOG gelöst werden, welches noch diesen Schritt weiter geht und versucht die Latenz, verursacht durch das globale Konsensus-Protokoll, zu entfernen.
Wie funktioniert SLOG?
SLOG ist nicht der einzige deterministische Ansatz. Jedoch ist SLOG der einzige Ansatz, welcher den globalen Konsensus eliminiert und dadurch alle drei Eigenschaften garantieren kann. Dieses System entfernt den globalen Paxos-Prozess, um die Latenzzeit zu verringern. Im Folgenden wollen wir SLOG oberflächlich betrachten und sehen wie SLOG diesen Schritt im Vergleich zu herkömmlichen deterministischen Ansätzen weitergeht.
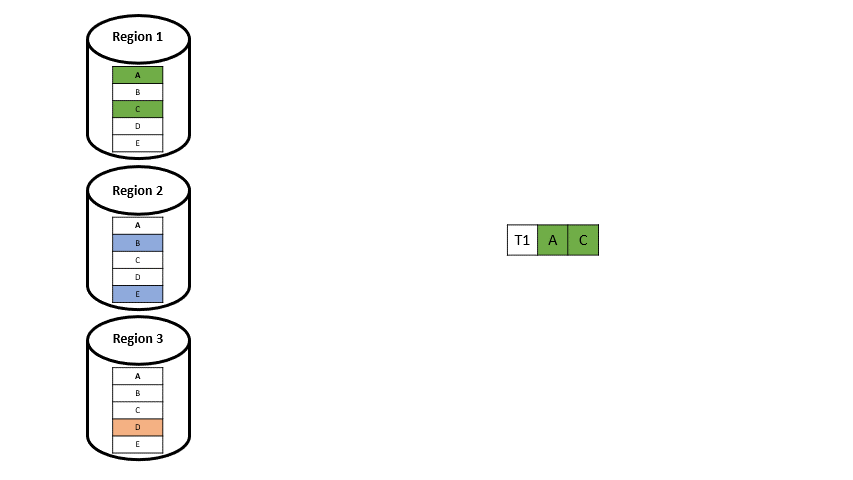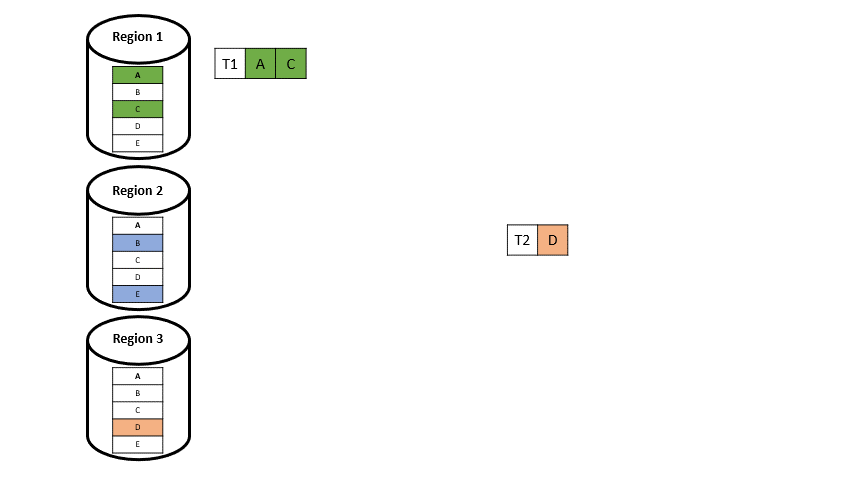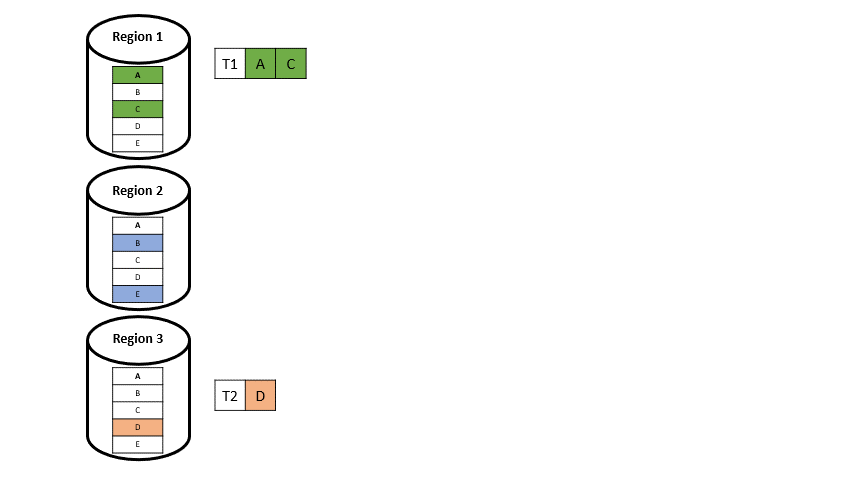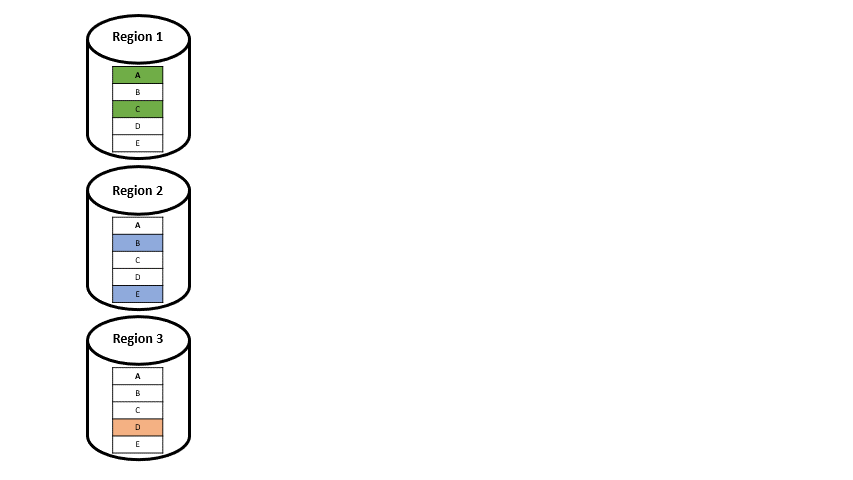
Wie schafft es SLOG nun dieses Konsensus-Protokoll abzuschaffen? SLOG verwendet eine Master-orientierte Architektur. Hierbei wird jedes Datenelement in einer sogenannten „Home“-Region oder Heimatregion verwaltet, was bedeutet, dass jeder Datensatz einen primären Speicherort besitzt. Schreib- und linearisierbare Lesevorgänge eines Datenelements müssen an seine Heimatregion gerichtet sein und am primären Speicherort verarbeitet werden. Eine Region in SLOG ist eine Gruppe von Servern, die über ein Netzwerk mit niedriger Latenz verbunden sind. Jede SLOG-Region enthält eine Reihe von Servern, auf die die in dieser Region gespeicherten Daten aufgeteilt (und repliziert) werden. Ein Teil dieser Daten wird von dieser Region beherrscht (sie ist die Heimatregion für diese Daten) und der Rest ist eine Kopie von Daten aus einer anderen Heimatregion. Jedes Datenelement hat also seine primäre Location (Heimatregion), was so viel bedeutet wie Nutzer in Berlin haben ihre primäre Location in Berlin, Nutzer in Sydney haben ihre primäre Location in Sydney. Wenn ich als Berliner nun Daten aus Sydney lesen möchte, muss ich die Daten auch aus der Region Sydney lesen, weil diese Up-to-date sind.
Die Transaktionen in SLOG werden basierend auf dieser Aufteilung in Heimatregionen in zwei Kategorien eingeteilt:
- Single-Home: Die Daten, auf die zugegriffen werden soll, haben ihr Home-Replika in derselben Region
- Multi-Home: Die Daten, auf die zugegriffen werden soll, haben ihr Home-Replika in unterschiedlichen Regionen
Lese- und Schreibzugriffe auf nahe gelegene Daten erfolgen schnell und ohne regionsübergreifende Kommunikation. Für Lese- und Schreibvorgänge auf entfernte Daten sowie für Transaktionen, die auf Daten aus mehreren Regionen zugreifen, einer Multi-Home-Transaktion, fallen jedoch regionsübergreifende Kommunikationskosten an. Die Ausführung von Multi-Home-Transaktionen stellen auch das technisch schwierigste Problem bei der Entwicklung von SLOG dar. Das Ziel besteht darin, strenge Serialisierungsgarantien und einen hohen Durchsatz bei einer potenziell großen Anzahl von Multi-Home-Transaktionen aufrechtzuerhalten, auch wenn diese auf konkurrierende Daten zugreifen und eine Koordinierung über physisch entfernte Regionen hinweg erfordern.
Auch SLOG verwendet ein Koordinationsprotokoll, um denselben Endzustand zu erreichen und nutzt einen solchen deterministischen Ausführungsrahmen wie oben beschrieben, um Skalierbarkeits- und Durchsatzbeschränkungen zu überwinden. Jedoch ersetzt SLOG das globale Protokoll durch ein regionales Protokoll. In SLOG wird der globale, auf Paxos-basierte, Log entfernt und durch ein lokales Log-Protokoll, welches ebenfalls auf Paxos basiert, ersetzt. Jede Region unterhält ein lokales Eingabeprotokoll, das über Paxos auf ihren Servern implementiert wird. Dieses lokale Protokoll enthält nur Transaktionen, die voraussichtlich Daten verändern, die in dieser Region verwaltet werden. Dieses Eingabeprotokoll wird in Batches an alle anderen Regionen gesendet. Jeder Batch ist mit einer Sequenznummer gekennzeichnet und die anderen Regionen verwenden diese Sequenznummer, um sicherzustellen, dass sie keine Chargen aus dieser Region übersehen haben. Auf diese Weise ist jede Region schließlich in der Lage das vollständige lokale Protokoll von jeder anderen Region zu rekonstruieren
Angenommen wir haben eine Transaktion, welche nur auf Datenelemente aus einer Region zugreift (Single-Home-Transaktion), sieht das ganze wie in der folgenden Abbildung 4 aus:
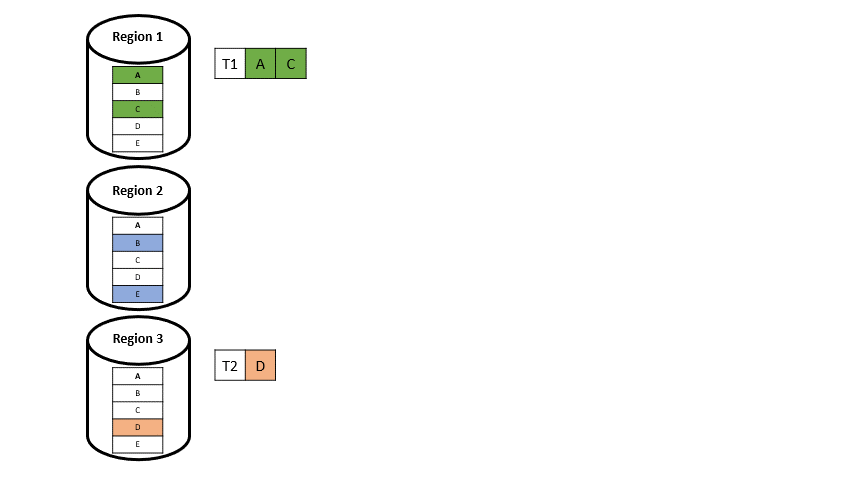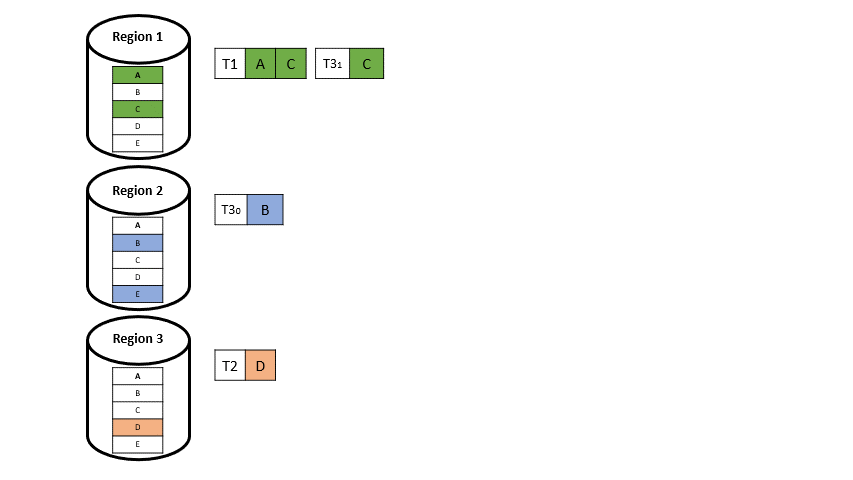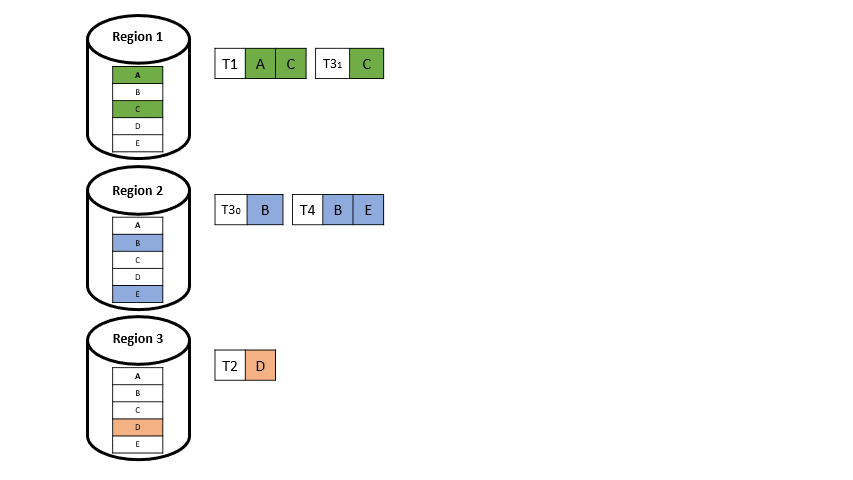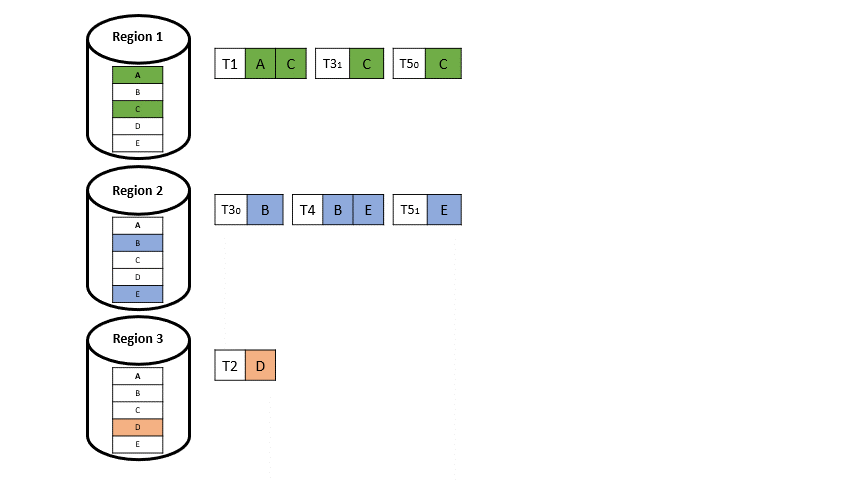
Wenn nun eine Transaktion auf Datenelemente aus zwei verschieden Regionen auftritt (T3 und T5 in Abbildung 5), wird diese aufgeteilt. Man spricht dann von einer Multi-Home-Transaktion:
Das globale Paxos-Log, welches zuvor in anderen deterministischen Ansätzen für Multi-regionale Datenbanken vorhanden war, weicht einer lokalen Version eines solchen Paxos-Protokolls pro Region, welches nur noch asynchron an die anderen Regionen repliziert wird (vgl. Abbildung 6).
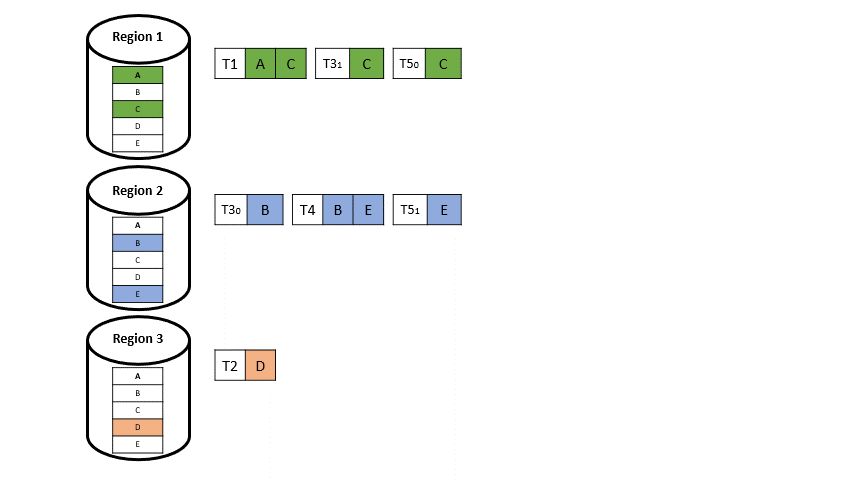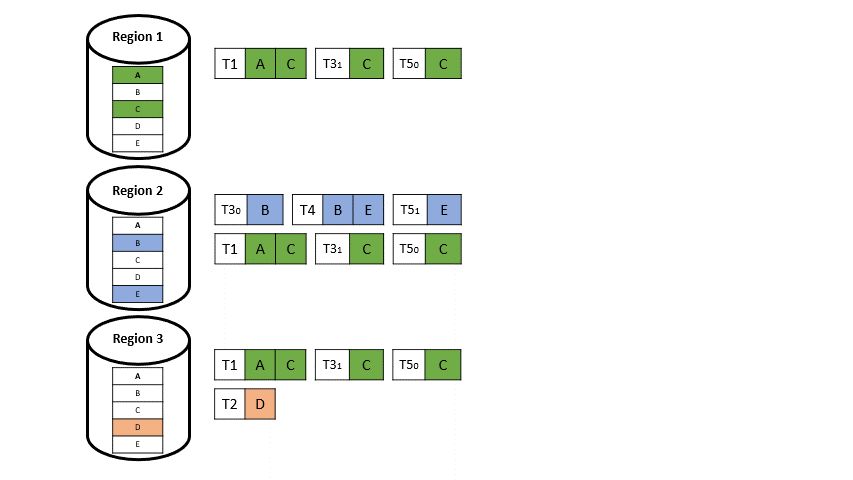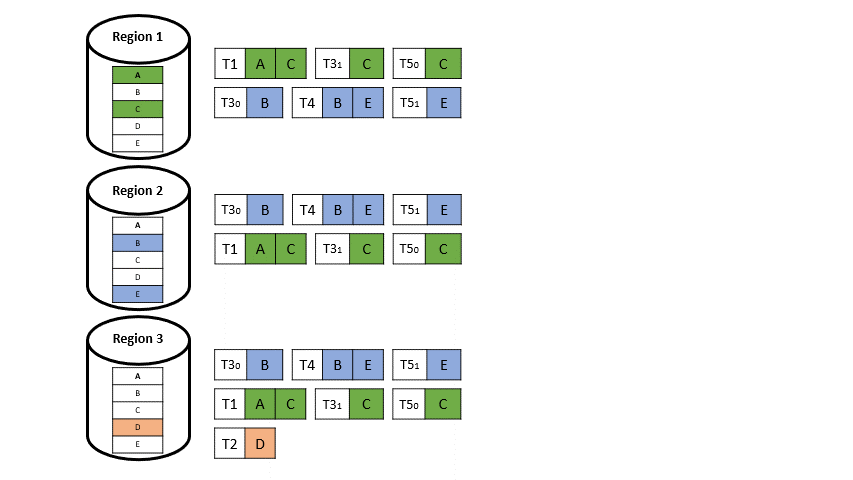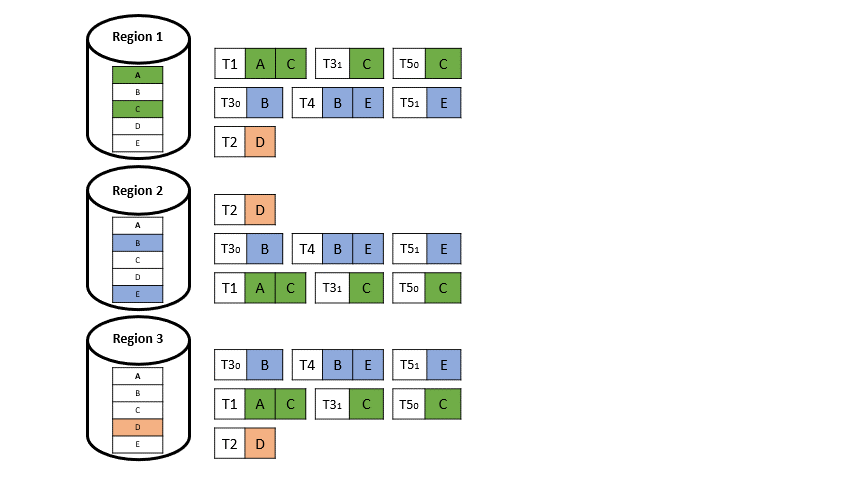
Die lokalen Protokolle werden in jede andere Region repliziert und sind unterschiedlich verschachtelt, was dazu führt, dass T3 zum Beispiel in jeder Region anders angeordnet ist (vgl. Abbildung 7), was aber nicht weiter problematisch ist, da die Daten disjunkt sind.
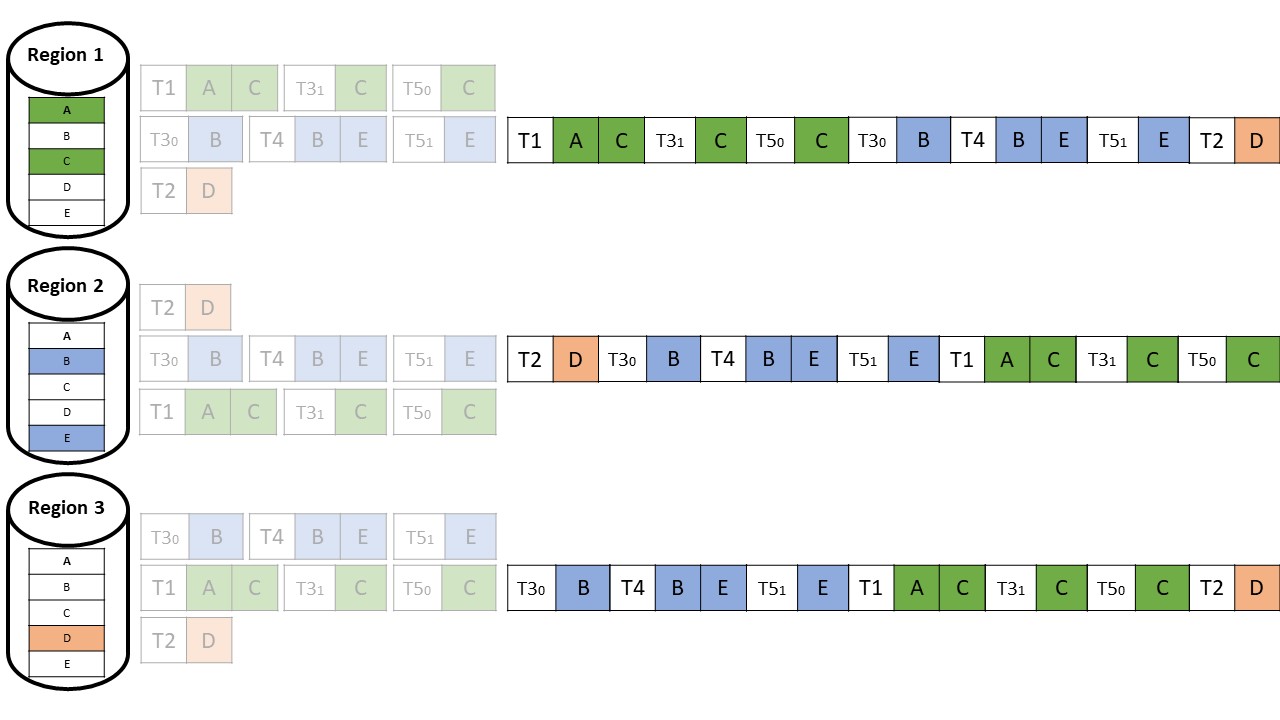
Die Regionen weichen nicht voneinander ab, da
- das globale Protokoll in jeder Region die ursprüngliche Reihenfolge der lokalen Protokolle, die es verschachtelt, beibehält.
- lokale Protokolle aus verschiedenen Regionen auf disjunkte Daten zugreifen.
- die deterministische Verarbeitungsmaschine sicherstellt, dass die Transaktionen so verarbeitet werden, dass das Endergebnis dem Ergebnis der Verarbeitung in der seriellen Reihenfolge entspricht, die im globalen Protokoll der jeweiligen Region vorliegt.
Single-Home-Transaktionen (T1, T2, T4) werden übertragen, sobald sie in ihrer Primärregion abgeschlossen sind.
Multi-Home-Transaktionen (T3, T5), die auf Daten in mehreren Regionen zugreifen, müssen auf die asynchrone Replikation des Eingabeprotokolls warten, bevor sie die Transaktion festschreiben können (sie müssen auf das Eintreffen des Protokolls warten). Die Transaktion wird verarbeitet, sobald die entsprechenden Protokollsätze in jeder lokalen Region vorhanden sind.
Durch die Aufteilung in Single-Home und Multi-Home wird realisiert, dass die meisten Transaktionen schnell sind (Single-Home). Auch wenn die Transaktionen in mehreren Regionen etwas langsamer sind, verschlechtern sich die Latenzen und der Durchsatz nicht so stark.
Fazit
Determinismus verringert die Latenzzeit und verbessert den Durchsatz, in dem es die Möglichkeit lokaler Deadlocks ausschließt und verteilte Commit-Protokolle wie z.B. Two-Phase-Commit reduziert, beziehungsweise gänzlich eliminiert. Experimente haben gezeigt, dass der Durchsatz bei deterministischen Systemen im Vergleich zu nicht-deterministischen Systemen bei zunehmender Konkurrenz deutlich besser performt (vgl. Abbildung 8).
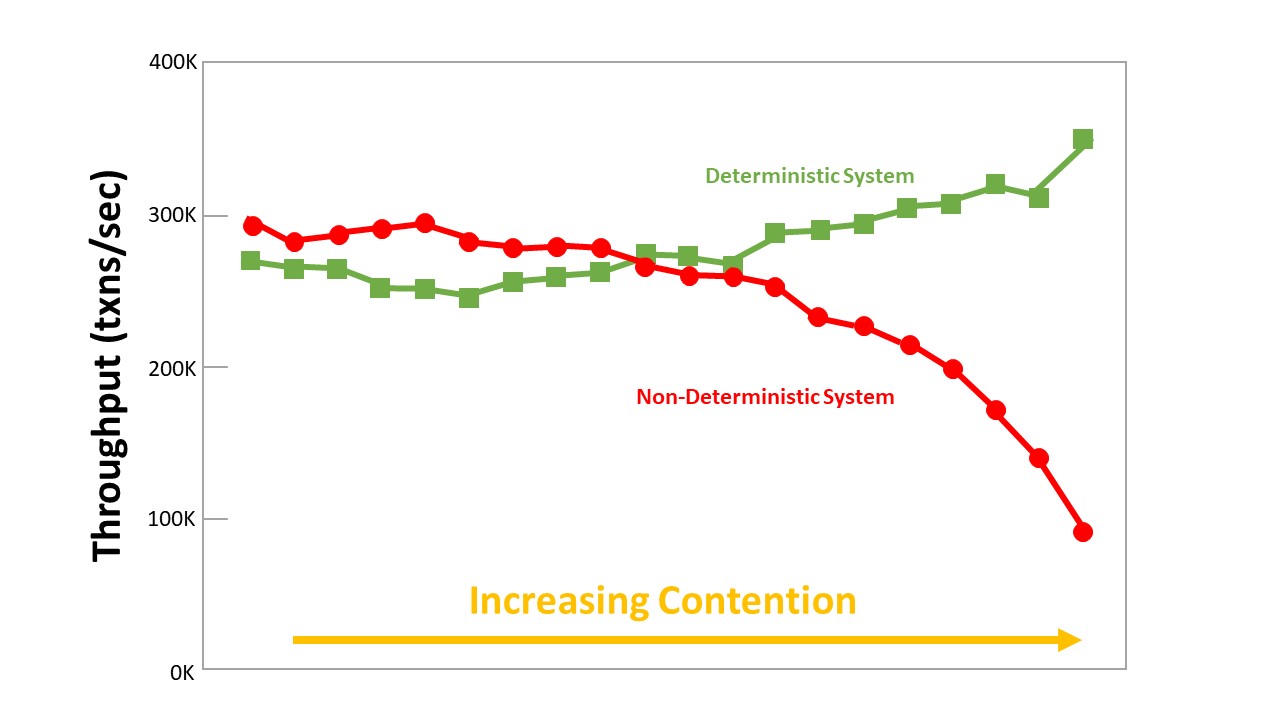
Herkömmliche deterministische Systeme haben zwar weiterhin mit Latenzen (bzgl. des Konsensus-Protokolls) zu kämpfen, jedoch gibt es Systeme wie SLOG, die versprechen auch diese Latenz zu verringern oder sogar zu eliminieren, um alle drei in der Einleitung genannten Eigenschaften zu erfüllen.
Für Datenbankreplikationen ist der offensichtlichste Vorteil deterministischer Datenbanksysteme die Gewährleistung, dass, solange alle Replikate denselben Input erhalten, diese nicht voneinander abweichen. Weitere Vorteile in der deterministischen Architektur sind auf jeden Fall die Skalierbarkeit, die Modularität und die Gleichzeitigkeit. Nicht-deterministische Ausfälle führen in einem deterministischen System nicht zu einem Transaktionsabbruch, da die Datenbank ihren Zustand zum Zeitpunkt des Absturzes immer wiederherstellen kann, was diese Systeme auch robuster gegen Fehler macht.
Auf den ersten Blick scheinen deterministische Architekturansätze in verteilten Datenbanken die Lösung für viele bekannte Probleme, doch leider ist dieser Ansatz nicht für alle Datenbankanwendungen praktikabel. Da für den Planungsprozess die gesamte Transaktion vorhanden sein muss, sind deterministische Datenbanksysteme schlecht geeignet für ORM-Tools und andere Anwendungen, die Transaktionen nur in Teilen an die Datenbank übermitteln.
Deterministische Datenbanksysteme haben sich als vielversprechender Weg zur Verbesserung der Skalierbarkeit, Modularität, des Durchsatzes und der Replikation von transaktionalen Datenbanksystemen erwiesen. Leider bieten alle neueren Implementierungen nur begrenzte oder gar keine Unterstützung für interaktive Transaktionen, so dass sie in vielen bestehenden Implementierungen bisher nicht eingesetzt werden können.
Quellen
Abadi, Daniel J. „SLOG: Serializable, Low-Latency, Geo-Replicated Transactions“. Gehalten auf der CMU Database Group – Vaccination Database Tech Talks (2021), CARNEGIE MELLON UNIVERSITY, 1. Februar 2021. https://www.youtube.com/watch?v=TAdiilOOvNI&t=645s.
„Determinismus“. In Wikipedia, 25. Dezember 2021. https://de.wikipedia.org/w/index.php?title=Determinismus&oldid=218485694.
Faleiro, Daniel J. Abadi, Jose M. „An Overview of Deterministic Database Systems“. Zugegriffen 15. März 2022. https://cacm.acm.org/magazines/2018/9/230601-an-overview-of-deterministic-database-systems/fulltext.
Ren, Kun, Dennis Li, und Daniel J. Abadi. „SLOG: Serializable, Low-Latency, Geo-Replicated Transactions“. Proceedings of the VLDB Endowment 12, Nr. 11 (Juli 2019): 1747–61. https://doi.org/10.14778/3342263.3342647.
„Strict Serializability“. Zugegriffen 23. März 2022. https://jepsen.io/consistency/models/strict-serializable.
„Transaction throughput“. Zugegriffen 23. März 2022. https://docs.oracle.com/cd/E17276_01/html/programmer_reference/transapp_throughput.html.
Leave a Reply
You must be logged in to post a comment.