an article by Lucas Crämer and Jannik Smidt
DISCLAIMER
This post tries to keep the complexity manageable while making a point clear. We are not systems engineers/kernel developers, so feel free to point out any mistakes/misunderstandings. This post probably does not present anything new for people who are working in systems engineering and/or kernel development.
Why is that of any interest to an application developer?
Storage is getting faster and faster, while the performance of single CPU cores does not increase to the same degree. Blazingly fast NVMe Storage Devices have reached PCs, Smartphones, Gaming Consoles, and Server Systems in the Cloud. The importance of fast and low latency storage in the cloud can not be understated. AWS recently even went that far to develop and release their own SSDs (AWS Nitro SSD) based on the AWS Nitro System for specific EC2 instance types [1].
Many application developers are not particularly educated about storage hardware, kernels, and file system APIs. This post is basically what application programmers should know when programming with modern storage devices in mind.
Excursus
how file I/O is **usually** handled
User space programs in UNIX-like POSIX operating systems (such as GNU/Linux, BSD, or macOS) usually handle file system I/O via POSIX file system API, which defines a set of programming interfaces related to file system organization (files, directories, permissions, etc.). This programming interface is implemented in the form of a set of synchronous system calls (or alternatively libc wrappers for such system calls), which famously include:
- open: open files and get a file descriptor in return
- read: read bytes from a file descriptor
- write: writes bytes to a file descriptor
- close: close a file descriptor
- fsync: make sure that all buffers in the kernel and the device are flushed so that data is durable on the storage device.
- … various others such as fcntl, seek, fstat, fruncate, fdatasync, etc., which we will not talk about in this article.
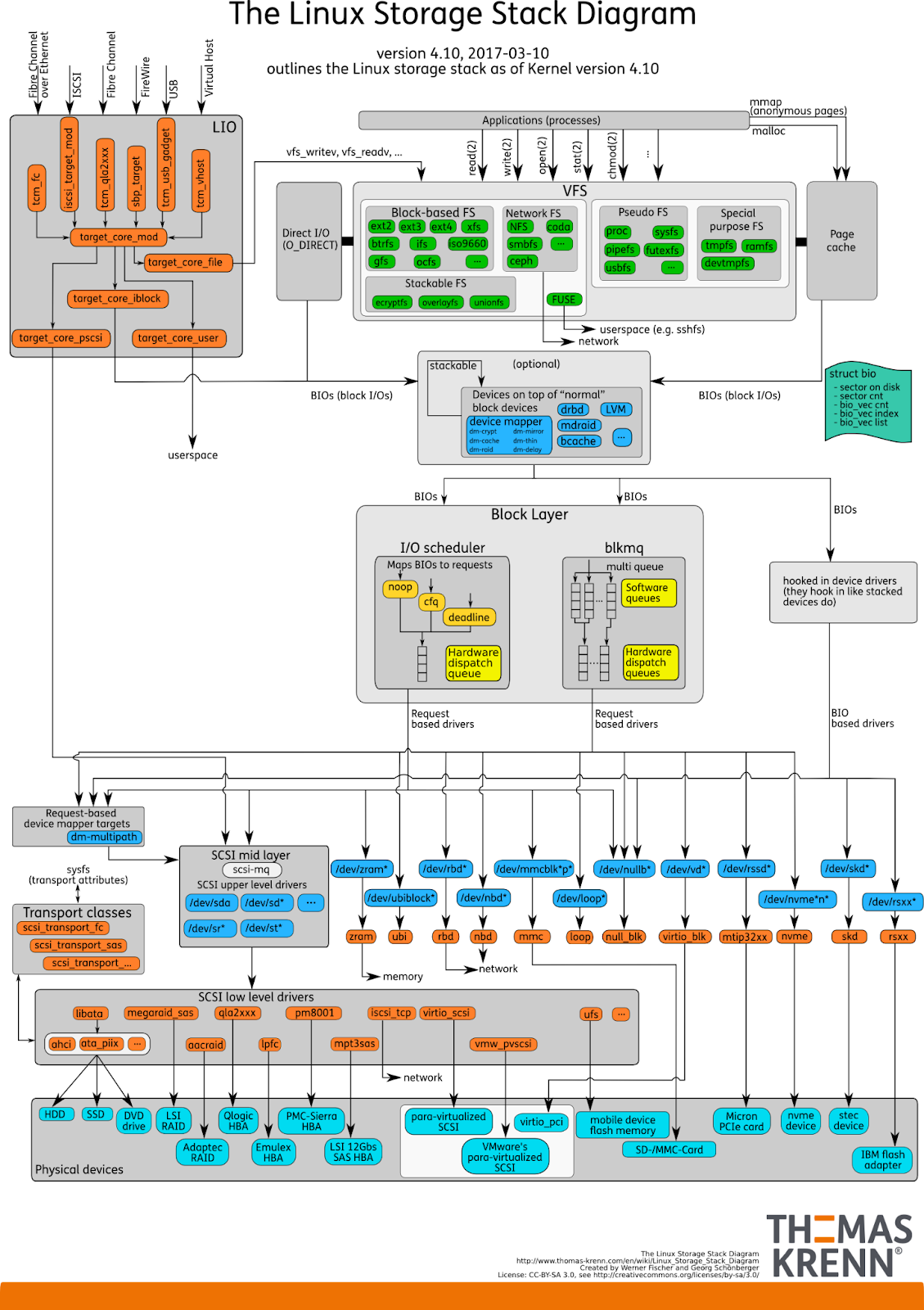
Digging Deep
To make further points clear this section takes a quick high-level glance at what happens within the kernel.
Reading and writing to files via the POSIX file system API goes through the page cache in the kernel by default. The same goes for file-backed memory mappings (mmap with a file descriptor)*.
The page cache is kept coherent with the file system by the kernel and serves as a caching layer for faster access of recently/already opened files and delivers read ahead for fast sequential access by default. When data is not ready in the page cache a page fault is generated. This is a trade-off design that trades in higher memory pressure, higher complexity, higher overall I/O latency (time until data is durable on the disk), and the system becomes overall less predictable (hitting and missing the cache defines the performance characteristics) for artificially improving I/O performance with lower throughput and much much higher latency spinning hard drives.
There is the ability to skip the page cache using the O_DIRECT flag when opening a file on Linux, but to this day this feature is mostly used by databases because they handle caching in user space on their own. Otherwise, this feature was notoriously ignored by many developers since it presumably decreases performance (more on that later) and because it is harder to use since the address of the buffer needs to be correctly aligned in memory.
The Linux Kernel has seen paradigm shifts within the block and driver layer of the I/O Subsystem to accommodate for fast storage devices.
NVMe storage devices have direct access to main memory (DMA) (usually via PCIe-Bus) and built-in DMA engines to read from and write to main memory. Commands/data between the main memory and the SSD are transferred asynchronously via submission and completion queues [2].
E.g. The kernel wants to read a block of data from the SSD. So the driver pushes a submission queue entry containing the necessary data (e.g. buffer address, size, parameters, etc.) into one of the submission queues. The DMA engine reads this entry, processes it, and pushes when all necessary data is read a completion queue entry into a corresponding completion queue, which then can later be read by the kernel, if necessary an interrupt is triggered. However, when constantly driving I/O in this manner it is usually more efficient to mask interrupts of the storage devices and poll the queues instead because handling (too many) interrupts can significantly decrease performance.
To further improve performance on multi-core systems there should be dedicated queues for each CPU core to avoid locking and/or complicated lock-free data structures and as a result, Amdahl’s Law kicks in [3]. Also keeping everything core local helps for better cache locality and less coherence overhead. The NVMe spec allows this with support for up to 216-1 queues and each having a queueing depth of up to 216-1 entries [4].
One more thing to consider is that different algorithms for I/O scheduling in the kernel have less effect on the performance characteristics of the system when using modern NVMe flash storage drives [5]. For example, reordering of I/O commands can deliver significant performance improvements for spinning hard drives due to the nature of the disk spinning and the head physically moving. However, for modern NVMe flash storage drives this provides little to no benefit at all.
To sum up this section, storage I/O within the Linux kernel is mostly asynchronous, highly parallel (while avoiding locks), copies are avoided, polling is used when it makes sense and the impact of I/O schedulers in the kernel has decreased.
Despite all of this the basic idea and paradigm behind the interface to the kernel has largely been untouched for the past 50 years since the invention of UNIX in the 1970s.
As already mentioned the UNIX (later POSIX) file system APIs are entirely synchronous ** and potentially blocking *** and have no support for batching, and polling, and rely heavily on the page cache, which implies a lot of potential copying.
Many systems which claim to do async I/O (such as Node.js’ libuv, Nginx, Tokio, etc.) make use of these synchronous (potentially blocking) system calls for file I/O under the hood. To emulate an asynchronous non-blocking behavior these kinds of I/O-heavy runtimes/applications usually create a thread pool dedicated to performing file I/O operations with the goal of not interfering with the event loop.
Improve your storage I/O performance today
Glauber Costa (seasoned Linux Kernel Developer & Database/Runtime Systems Engineer) thinks that we can and should do better and explains how to properly utilize modern NVMe storage drives in two blog posts “Modern storage is plenty fast. It is the APIs that are bad.” [6] and “Direct I/O writes: the best way to improve your credit score.” [7] In the following section, we will point out his core thesis mixed with some additional thoughts and findings:
Things have changed
It seems redundant to say this at this point in the article, but things have changed. The synchronous blocking POSIX file system APIs were always expensive but good enough since spinning hard drives are still much slower in comparison. However, modern NVMe flash storage devices are many orders of magnitude faster in terms of latency and throughput. This should lead us to rethink our mental model about handling file I/O and test whether these APIs still deliver acceptable performance for our use cases.
Common misconceptions
“Well, it is fine to copy memory here and perform this expensive computation because it saves us one I/O operation, which is even more expensive.”
Many developers would agree with statements like that. But did they actually run a test to prove that point? If they would test their claims some of them would even appear to be true at the first glance. Using modern NVMe storage drives to their full potential (which we will discuss later) is not super obvious, but if you do there is a chance the I/O operation might be cheaper or that the effect is not nearly as significant as you might have thought.
io_uring
Costa says that “io_uring” is going to revolutionize I/O on Linux. Why does he think so? While the Linux Kernel accommodated modern fast I/O devices, user space APIs have not changed as they should have. io_uring is a true game-changer in this regard.
But what exactly is io_uring? io_uring is on its way to becoming the new standard for asynchronous I/O operations in Linux. It was first introduced in upstream Linux kernel version 5.1 and thus is a relatively young API. Instead of improving the support for established Linux AIO, it introduces a completely new interface. The io_uring’s interface is designed around submission and completion queues. I/O operations that resemble the POSIX file system API can be pushed in the form of a submission queue entry (SQE) into the submission queue (SQ). On completion, their result is pushed by the kernel into a completion queue (CQ) in the form of a completion queue entry (CQE), so that the process can truly asynchronously retrieve the result [8].
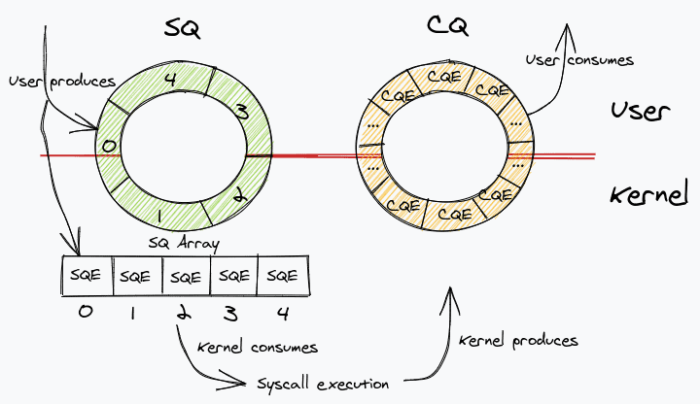
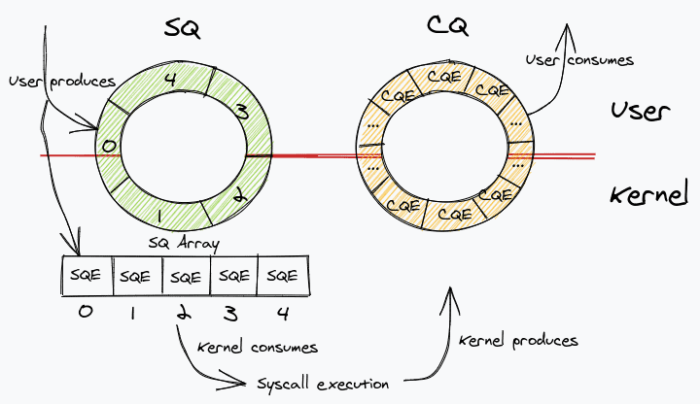{kind=link}
System calls were never free, but have become more expensive since the meltdown and spectre patches [9]. In I/O heavy applications system call overhead can become significant depending on the workload. io_uring’s queues are mapped into user and kernel space, so entries can be added to the submission queue and read from the completion queue completely from user space with no system call being required. That way io_uring significantly reduces the amount of system calls a process has to perform and can be set up to work in poll mode when constantly driving I/O. In this case, there is no need to perform any system calls at all. Both queues are implemented as single-producer, single-consumer ring buffers and work completely lock-free.
When using preregistered buffers with io_uring it is also possible to avoid copies to user space. Meaning there is only one copy from the device to the preregistered buffer.
If you have paid attention in previous sections you might have realized that io_uring closely resembles interfaces that have been part of the kernel’s I/O subsystem for years. This is not by accident. The main developer behind io_uring Jens Axboe has been involved in various parts of the Linux I/O subsystem for years and is the maintainer of the block layer.
However, one should keep in mind that the io_uring API is still relatively fresh and still under active development.
direct I/O
When scanning files it is recommended to use direct I/O and exploit parallelism by keeping many I/O requests in-flight. For example, reading a file at different offsets or alternatively multiple files in parallel into multiple buffers. This has the advantage of exploiting the parallelism of the NVMe storage drive (remember NVMe storage drives typically have multiple queues) and the CPU. However, one should keep in mind read amplification. The Linux Kernel can only read in page granularity of 4kb and a read-ahead is performed with a default value of 128kb. Say you want to read 1kb split into two files 512 bytes each, the kernel is reading 256kb to serve 1kb, effectively wasting 99%. Especially when performing random I/O operations this effect can have a significant negative impact on performance [6].
When writing with direct I/O fsyncing data becomes much cheaper and more predictable. Since the page cache is skipped data has already reached the drive once fsync is called. From our experience, there are in practice very few scenarios where you can actually live with possibly losing several seconds of data. If fsyncing is required direct I/O has again a clear edge over keeping a page cache for each file [7]. Also, most persistent data structures in distributed systems nowadays are append-only (e.g. LSM trees), so sequential write performance matters most and written data usually does not need to be immediately retrieved again, rendering the positive aspects of a page cache useless.
One more advantage is that direct I/O generally consumes less CPU time overall (user + kernel).
In conclusion, you should probably use direct I/O for reads and writes when dealing with fast NVMe drives, because it makes the whole system more predictable and delivers more consistent results, which is a factor that can not be understated especially when designing web services (watch your tail latencies!), using direct I/O leads to less memory pressure, less use of memory bandwidth, less overall CPU utilization and when applying a few tricks possibly (much) faster read/write speeds.
io_uring and direct I/O save the day
Thanks to io_uring’s preregistered buffer feature, direct I/O, and poll mode, it is essentially possible to push a batch of I/O requests into io_uring’s submission queues on multiple threads, constantly polling for I/O completion events without performing a single system call or copy to user space. These are degrees of I/O efficiency and capabilities that were unthinkable in user space just a decade ago **** but essentially pretty much what Glauber’s Costa’s thread-per-core I/O runtime glommio implements.
More considerations
Use parallelism when it makes sense. Generally speaking, that means parallelism that scales. This is usually achieved by sharing no/very little mutable state across threads (avoid locks, complicated thread-safe data structures) for optimal scaling on multicore systems. This is the essence of thread per core architectural paradigm that costa is preaching about.
We advise against using mmap for file I/O even with large files that outgrow main memory we could never measure any benefits. In best-case scenarios, it was on par with using classic POSIX read/write system calls, while consuming much more CPU time in user and kernel space. Interestingly enough the recently published paper “Are You Sure You Want to Use MMAP in Your Database Management System?” [10] also advises very much against using mmap in the storage engines of DBMS. We recommend watching this short entertaining YouTube Video, which summarizes the main points of the paper: https://www.youtube.com/watch?v=1BRGU_AS25c
Also, I am currently working on an easy-to-understand storage benchmark which was created as a side project while we were researching for this article. The benchmark implements a large variety of I/O mechanisms and parameters. Currently, my todos are implementing read functionality and io_uring support. Its goal is to be a mini version of the fio (flexible I/O) benchmark for educational purposes. It also presents minimal easy-to-understand examples of how to use file system APIs.
https://github.com/lc0305/storage_bench
* Thanks to virtual memory you can map entire files into a user space process by creating a file-backed memory mapping. This is implemented by mapping the VFS page cache into the user space process. When a byte is not present in the page cache this triggers a page fault. This sounds convenient, but we would advise against using mmap for file I/O for reasons, which are mentioned later on.
** POSIX AIO is just a user space implementation that emulates asynchronous I/O file operations using the synchronous blocking POSIX file system API. Linux AIO (io_submit system call family) comes with lots of caveats e.g. Linux-specific, the unloved child that is hated by Linus Torvalds, only direct I/O supported, still potentially blocking, etc.
*** Blocking in this context means that after the context switch to kernel space triggered by the system call data is not immediately present, so the task is waiting until the I/O operation succeeded and the data is available.
**** There was the possibility to have the driver itself run in user space before, but this comes with a lot of caveats, making it impractical for most applications.
Sources
[2] https://elixir.bootlin.com/linux/v3.3/source/drivers/block/nvme.c
[3] https://en.wikipedia.org/wiki/Amdahl%27s_law
[5] https://www.oreilly.com/library/view/linux-system-programming/9781449341527/ch04.html
[6] https://itnext.io/modern-storage-is-plenty-fast-it-is-the-apis-that-are-bad-6a68319fbc1a
[7] https://itnext.io/direct-i-o-writes-the-best-way-to-improve-your-credit-score-bd6c19cdfe46
[8] https://kernel.dk/io_uring.pdf
Leave a Reply
You must be logged in to post a comment.