Artikel von Cedric Gottschalk und Raphael Kienhöfer
Im Rahmen der Endabgabe der Vorlesung “Software Development für Cloud Computing” haben wir uns zum Ziel gesetzt, eine bereits bestehende REST API eines vorherigen Projektes in die Cloud zu migrieren. Dabei haben wir uns dafür entschieden, die Google Cloud zu verwenden. Im Zuge dieses Projektes haben wir uns auch mit Infrastructure as Code mittels Terraform beschäftigt.
Architektur
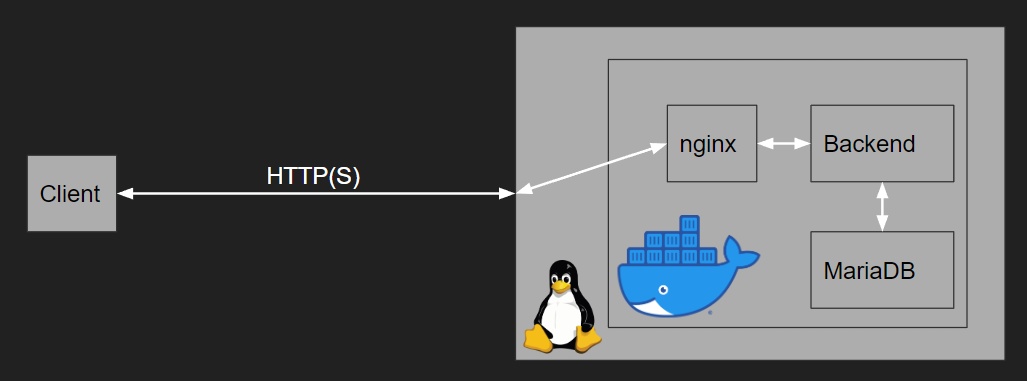
Vor dem Umzug in die Cloud lebte die API als Container auf einem einzelnen Server, der mittels Docker Compose verwaltet wurde. Hier wurde nginx als Reverse-Proxy eingesetzt, um die Übertragung mittels TLS zu sichern. MariaDB wurde als SQL-Datenbank eingesetzt. Die Verknüpfung der einzelnen Dienste gestaltete sich hier durch den gemeinsamen technischen Unterbau (Docker) sehr simpel.
Cloud SQL
Das Produkt “Cloud SQL” der Google Cloud bietet lediglich Microsoft SQL Server, PostgreSQL und MySQL an. Da MariaDB und MySQL binärkompatibel sind, konnte hier ohne Änderung von Anwendungscode migriert werden. Aufgrund der Konzeption von relationalen Datenbankmanagementsystemen sind verteilte, redundante Datenbanken nur schwer umsetzbar. Google verwendet hier einen Failover-Ansatz, wobei Anwendungsdaten regelmäßig auf einen Klon der Datenbank gespiegelt werden. Im Falle eines Ausfalls der Hauptdatenbank werden Anfragen automatisch an den Klon weitergeleitet. Der Cloud SQL Service ermöglicht außerdem einen relativ einfachen Zugriff auf eine Datenbank von anderen Google Cloud Services aus, wie z.B. GKE.
Google Kubernetes Engine (GKE)
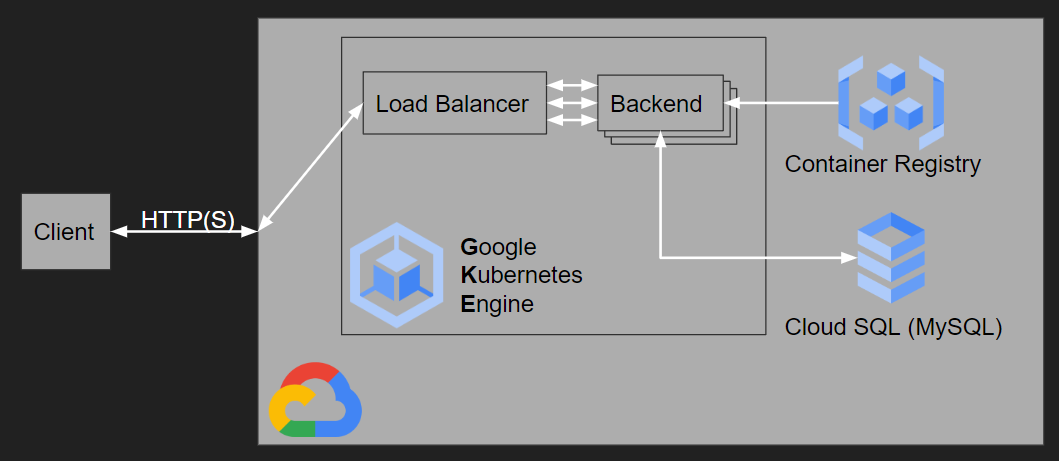
Um die Vorteile einer Cloudinfrastruktur zu nutzen, wurde Docker Compose durch Kubernetes (von Google unter dem Produktnamen “Google Kubernetes Engine” (GKE) angeboten) ersetzt. Hier wird das Backend in mehreren sogenannten Pods ausgeführt, die auf verschiedenen Nodes (Servern) verteilt gestartet werden und somit Redundanz bieten. Kubernetes übernimmt hierbei auch die Aufgabe des Load Balancing, also der gleichmäßigen Verteilung der Anfragen auf die einzelnen Pods, um jeweils bessere Performance zu erzielen.
Google Container Registry (GCR)
Da Kubernetes auf Containerisierten Anwendungen basiert, musste das Image des API-Servers für GKE zugänglich gemacht werden. Hierfür wurde die Google Container Registry verwendet, die wiederum ein Interface für Googles Cloud Storage ist.
IAM
Die einzelnen Dienste in der Cloudumgebung unterscheiden sich in der technischen Umsetzung und sind auch alle auf eigenen VMs/Servern bereitgestellt. Daher ergibt sich hier ein neuer Sicherheitsaspekt. Während in der On Premises Architektur ein internes Netzwerk innerhalb des Docker-Hosts verwendet werden kann, muss die Kommunikation der einzelnen Komponenten mindestens zwischen Servern in einem Rechenzentrum, teilweise auch über das Internet, erfolgen.
Die dadurch notwendig werdende Berechtigungsverwaltung wird in der Google Cloud mittels “Identity and Access Management” (IAM) bereitgestellt. Hier kann man zum Beispiel weiteren Benutzern Zugriff auf die Infrastruktur bzw. deren Verwaltungstools geben. Außerdem können hier die Berechtigungen für sogenannte Service Accounts angepasst werden. Service Accounts werden von den Diensten der Google Cloud verwendet, um auf andere Dienste zuzugreifen. So verwendet beispielsweise GKE (beziehungsweise die Google Compute Engine, auf deren VMs GKE bereitgestellt wird) ihren Service Account, um sich gegenüber der Container Registry für den Download der Container-Images zu authentifizieren.
Durch die große Anzahl an Diensten und damit verbundenen Berechtigungen in der Google Cloud ist es durchaus herausfordernd, Probleme, die durch Berechtigungen (oder deren Abwesenheit) entstehen, zu lösen (dazu mehr im Abschnitt Probleme).
API
Bei der API handelt es sich um eine mit Express in Node.js realisierte REST API. Ihre Aufgabe ist die Verwaltung von Highscores für das Spiel “Squid Game” (hat trotz des gleichen Namens nichts mit der Serie des bekannten Streamingdienstes zu tun), das im Rahmen eines Projektes in früheren Semestern produziert wurde. Die API ist nicht spezifisch auf das Spiel ausgelegt und kann für allgemeines Score-Tracking für Zeit- oder Punktbasierte Minispiele verwendet werden. Auf einen Authentifizierungsmechanismus wurde während der Entwicklung verzichtet, um die Komplexität gering zu halten.
Die API realisiert (auch aufgrund der fehlenden Authentifizierung) kein vollständiges CRUD-Pattern. Um beispielsweise ein neues Minispiel zu erstellen, ist ein manueller Eingriff in die Datenbank notwendig. Da dieser Fall als üblicherweise einmaliger Ablauf beim initialen Aufsetzen der Datenbank angesehen wurde, wurde diese Funktion nicht implementiert.
Folgende Endpunkte sind in der API verfügbar:
GET /minigames
Gibt eine Liste aller existierenden Minispiele zurück.
GET /minigames/{id}
Gibt Details zu einem Minispiel zurück.
GET /minigames/{id}/scores
Gibt eine Liste von Punktzahlen eines Minispiels zurück.
POST /minigames/{id}/scores
Hinzufügen einer neuen Punktzahl zu einem Minispiel.
PATCH /minigames/{id}/scores
Verändern einer Punktzahl.
Infrastructure as Code
Die manuelle Konfiguration von Infrastruktur stellt eine potenzielle Fehlerquelle dar. Aus dieser Motivation hat sich das Konzept der “Infrastructure as Code” etabliert, bei der Infrastruktur in strukturierten Dokumenten formal definiert wird. Die konkrete Umsetzung dieses “Codes” in tatsächlich bereitgestellte VMs, Datenbanken, usw. wird anschließend von entsprechenden Tools übernommen.
Wir haben uns für das Tool Terraform entschieden, da Terraform einen besonderen Fokus auf Infrastruktur in der Cloud legt. Mit Terraform ließ sich die benötigte Infrastruktur einfach bereitstellen.
Die Terraform Konfiguration wurde für bessere Übersicht über mehrere Dateien verteilt:
main.tf
Hier ist die Version des Google Provider festgelegt. Außerdem werden hier Variablen und “Locals” deklariert. Locals unterscheiden sich von Variablen insofern, dass sie während der Ausführung von Terraform berechnet werden und nicht von außen vorgegeben werden oder Standardwerte haben.
google.tf
Hier befindet sich die Konfiguration für den Google Provider.
terraform.tfvars
Diese Datei ermöglicht es, Werte für Variablen festzulegen. Die Datei wird automatisch bei Ausführung von Terraform eingelesen. Dadurch spart man sich, alle Variablen über die Kommandozeile zu übergeben.
gke.tf
Die größte Datei enthält die Konfiguration für GKE. Hier wird zum einen das Cluster angelegt, zum anderen ein Node Pool hinzugefügt. Der Node Pool legt unter anderem die Art der VM, die für die Nodes verwendet wird, fest.
cloud_sql.tf
Cloud SQL wird mittels dieser Datei provisioniert. Hier werden auch Einstellungen für das Backup und die Redundanz festgelegt.
vpc.tf
Das VPC (Virtual Private Cloud) Netzwerk wird für die interne Kommunikation zwischen den Diensten verwendet. Es wird für die Provisionierung von Compute Ressourcen benötigt.
outputs.tf
In dieser Datei werden die Outputs des Terraform-State angegeben. Diese Outputs können dann von anderen Programmen und/oder weiteren Terraform Konfigurationen verwendet werden. Wir verwenden die Outputs hauptsächlich für das Shell-Skript. Ausgegeben werden von uns hier zum Beispiel die Projekt ID, die Namen der SQL Instanz und Datenbank, sowie der Name des Clusters. Falls benötigt (das Skript nutzt dies zur Zeit allerdings nicht) werden noch relevante IP Adressen (beispielsweise die der SQL Instanz) ausgegeben.
Shell Skript
Für die Konfiguration der Datenbank und das Anwenden der Kubernetes Deployments haben wir ein Shell-Skript verwendet, das mit dem gcloud-CLI und kubectl die benötigten Einstellungen vornimmt. Wir verwenden auf unseren PCs Windows. Eine mögliche CI/CD Pipeline, die die Änderungen an der Infrastruktur automatisiert anstößt, würde jedoch auf Linux basieren. Daher wurde das Skript sowohl für die PowerShell als auch für Bash geschrieben. Die Konfiguration der Datenbank findet hierbei durch das Hochladen eines SQL-Skriptes und einen anschließenden Import in die Cloud SQL Instanz statt.
Kubernetes Deployment
Um die REST API auf unserem Kubernetes Cluster bereitzustellen, verwenden wir ein Kubernetes Deployment. Dieses ist in der Datei “squid-server.k8s.yaml” definiert.

Die Felder .metadata.name, .metadata.namespace und .metadata.labels definieren den Namen, den Namespace und Labels für das Deployment.
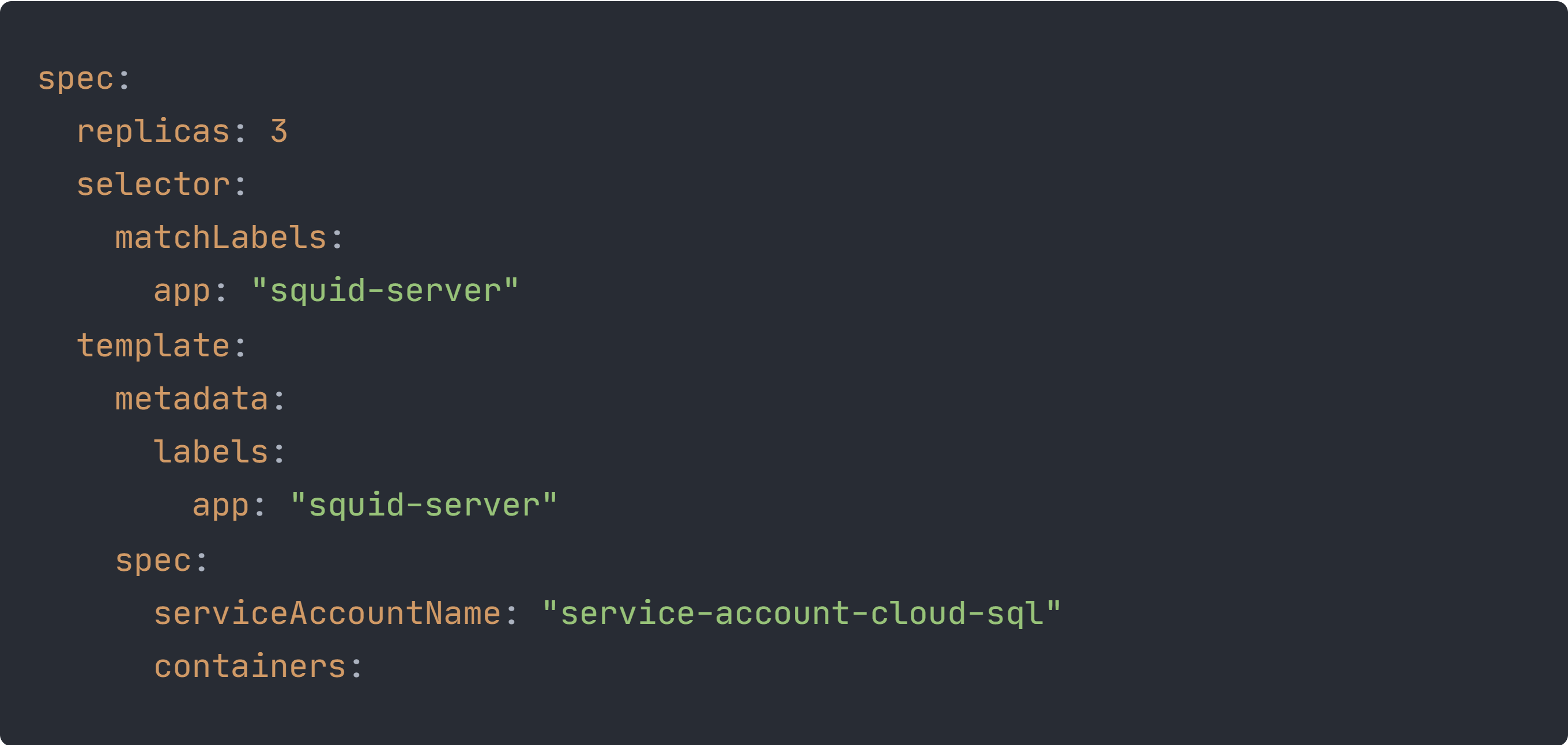
Im .spec.replicas Feld wird angegeben, wie viele Pods das Deployment erzeugen soll. In unserem Fall haben wir angegeben, dass die gewünschte Anzahl an Pods 3 sein soll.
Mit dem .spec.selector Feld wird mithilfe von Labels definiert, welche Pods das Deployment managen soll. Das .spec.template Feld enthält das Template für die Pods, die erzeugt werden sollen. Dabei müssen in dem Template dieselben Labels wie im Selector angegeben werden, damit das Deployment die Pods auch finden kann.
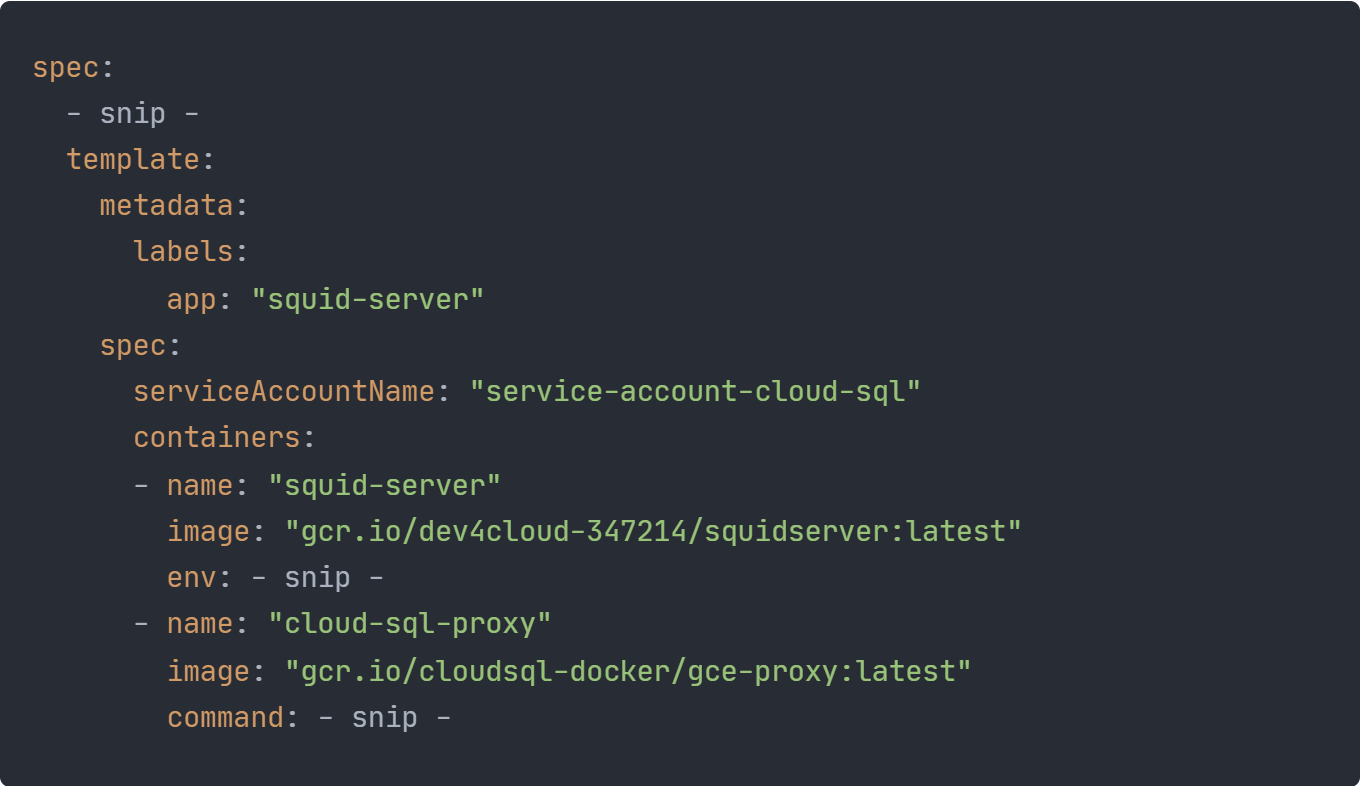
Damit die erzeugten Pods eine Verbindung zu der Cloud SQL Instanz aufbauen dürfen, ist im Feld .spec.template.spec.serviceAccountName ein von uns erstellter Kubernetes Service Account angegeben, den die Pods verwenden sollen. Im .spec.template.spec.containers Feld des Templates werden die Container, die in den Pods laufen sollen, definiert. In unserem Fall sind das zwei Container. Der erste ist das Backend und der zweite ein Cloud SQL Proxy, über den sich das Backend mit der Cloud SQL Instanz verbindet.
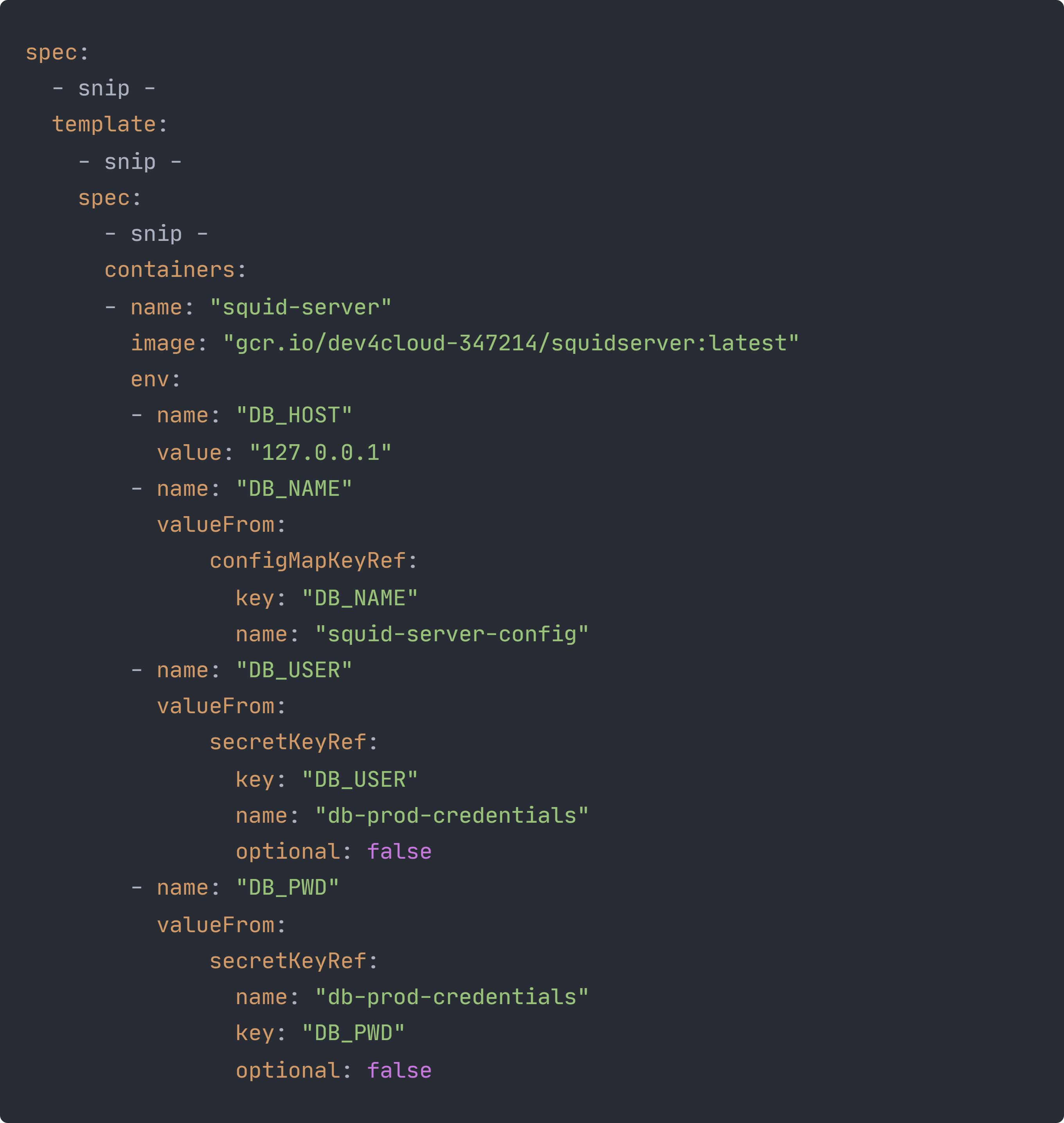
Für den Backend Container werden außerdem auch noch vier Umgebungsvariablen gesetzt. Bei der Definition der Umgebungsvariablen müssen ein Name und ein Wert angegeben werden. Der Wert für die Umgebungsvariable kann direkt angegeben werden, wie bei der DB_HOST Variablen zu sehen ist. Andere Möglichkeiten, den Wert für eine Umgebungsvariable zu definieren, sind eine ConfigMap oder ein Secret. Dabei werden die Werte als separate Objekte im Kubernetes Cluster verwaltet und können dadurch unabhängig vom Deployment geändert werden.
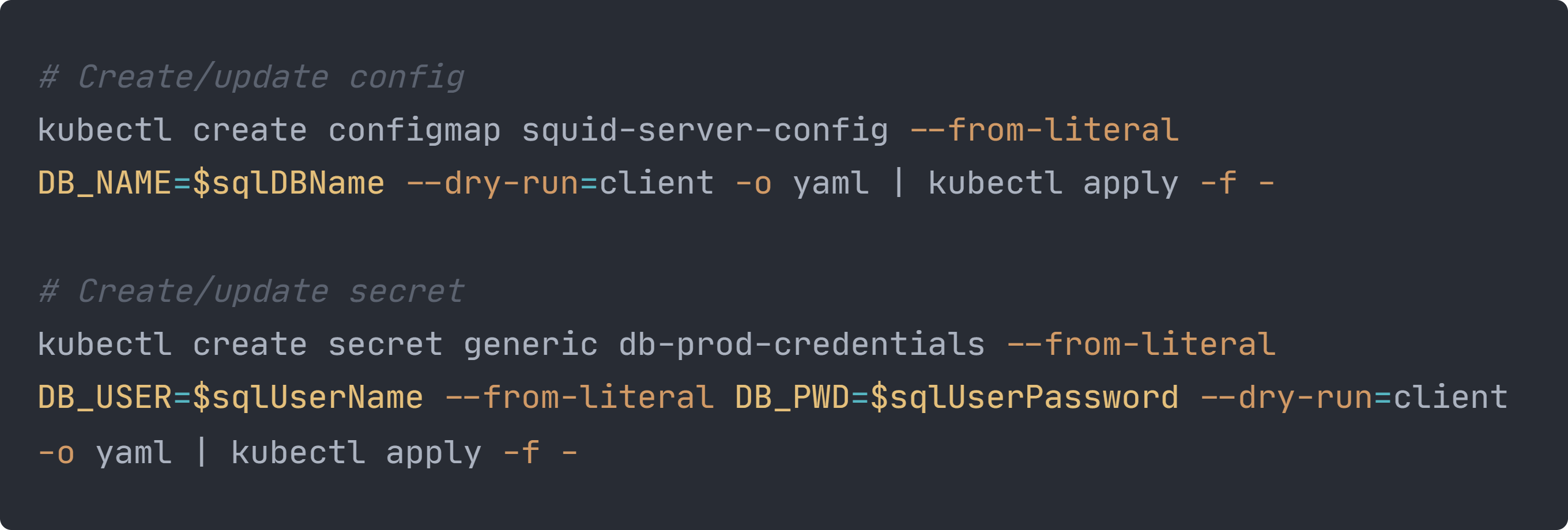
Die ConfigMap “squid-server-config” und das Secret “db-prod-credentials” für unser Deployment werden über unser Shell-Skript erstellt, bevor das Deployment gemacht wird. Dabei werden in der ConfigMap der Wert für die Variable DB_NAME und in dem Secret die Werte für die Variablen DB_USER und DB_PWD gespeichert.

In der Definition des Cloud SQL Proxys wird über den Befehl, der beim Starten des Containers ausgeführt wird, festgelegt, für welche Cloud SQL Instanzen der Proxy sein soll.
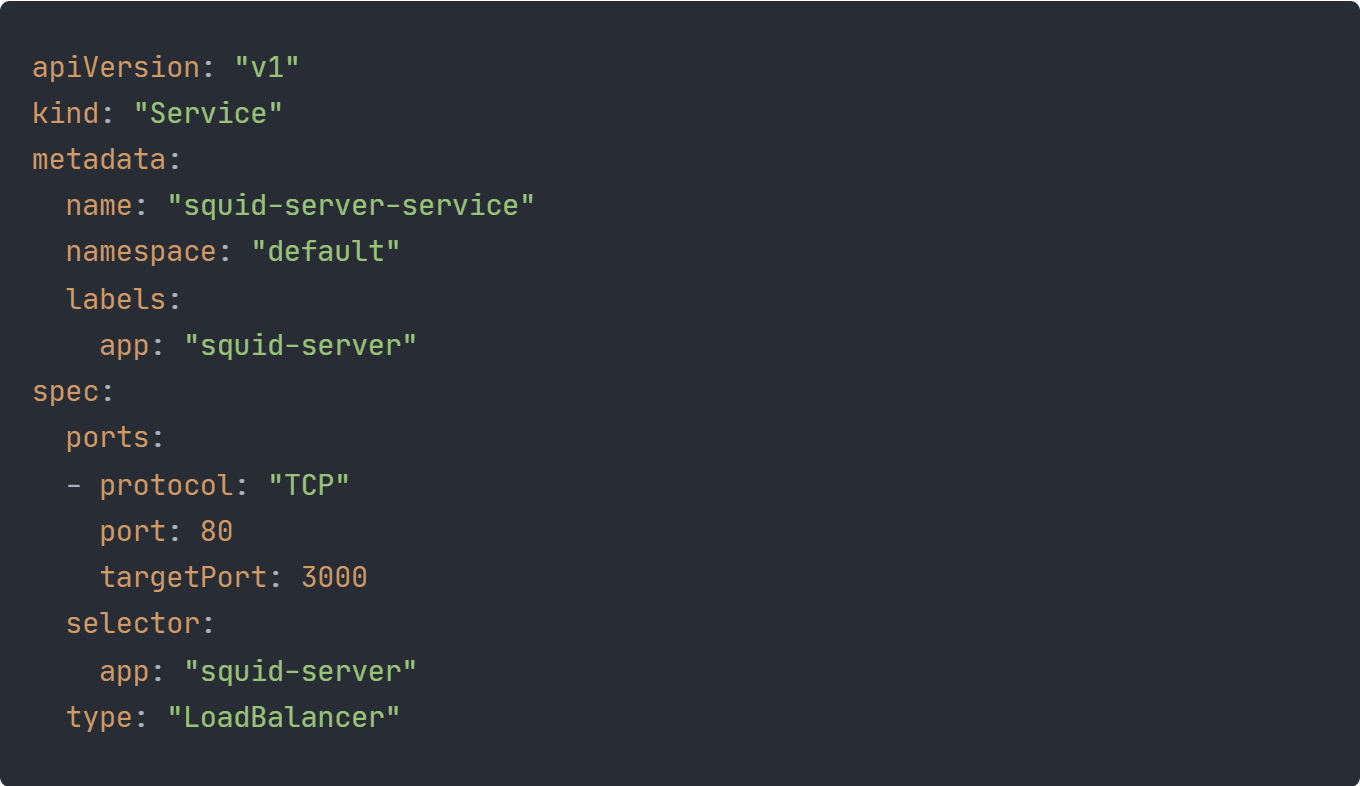
In der Datei “squid-server.k8s.yaml” wird außerdem ein Load Balancer definiert, der Anfragen von außen entgegen nimmt und diese an die Pods verteilt.
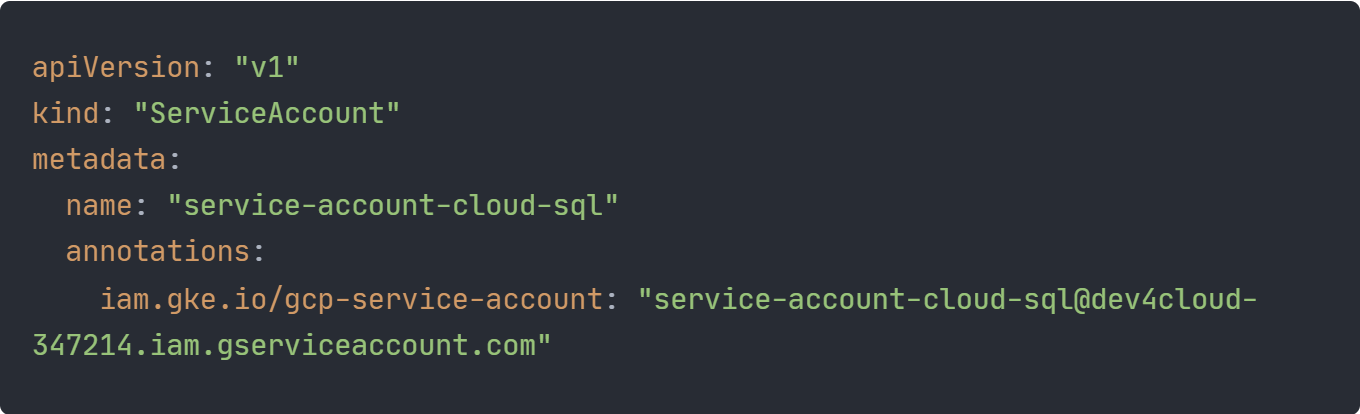
In der Datei “service-account.k8s.yaml” wird der schon erwähnte Kubernetes Service Account definiert. Dieser wird mit der E-Mail Adresse des IAM Service Accounts annotiert. Wenn die im Abschnitt Probleme beschriebenen Schritte zur Einrichtung von Workload Identity durchlaufen wurden, haben die Pods, die den Service Account nutzen, die Berechtigung, auf die Cloud SQL Instanz zuzugreifen.
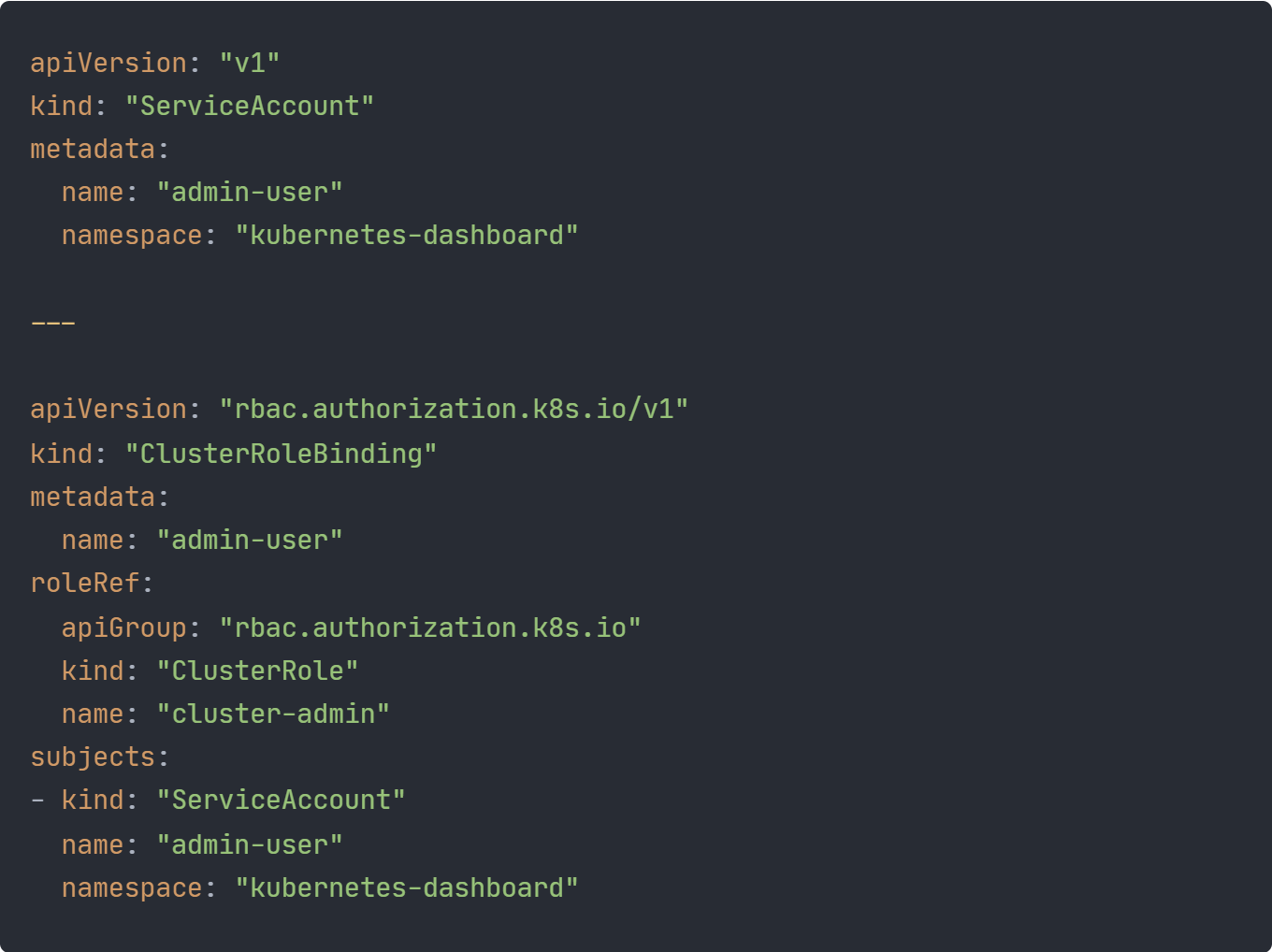

Separat von unserem Deployment wird mit dem Shell-Skript auch noch ein Kubernetes Dashboard auf dem Cluster deployed. Die yaml-Datei für das Deployment kommt dabei von dem GitHub Repository des Kubernetes Dashboards. Um sich bei diesem anmelden zu können, muss außerdem noch ein Admin-Account erstellt werden. Dieser ist in der Datei “admin-account.k8s.yaml” definiert.
Probleme
Nach der Erstellung der Terraform-Dateien für die Infrastruktur stellten wir fest, dass die Ersteinrichtung der SQL Datenbank und ein Deployment auf ein Kubernetes Cluster nicht mit dem Terraform Provider für die Google Cloud möglich ist. Als Lösung hierfür haben wir das oben beschriebene Shell-Skript geschrieben.
Ein weiteres Problem bestand darin, dass die Pods (des Backends) nicht mit der Datenbank kommunizieren durften. Um dieses Problem zu lösen, haben wir dem Kubernetes Deployment einen weiteren Container, den Cloud SQL Proxy, hinzugefügt, über den das Backend auf die Cloud SQL Instanz zugreifen kann. Wir stellten jedoch schnell fest, dass das bloße Verwenden des Proxies das zugrundeliegende Berechtigungsproblem nicht löst. Um dieses Problem zu lösen, mussten wir Workload Identity einrichten. Dies wird mit den folgenden drei Befehlen, mit denen ein IAM Service Account erstellt und mit einem Kubernetes Service Account verbunden wird, erreicht.


<PROJECT_ID> durch die Projekt-ID des Google Cloud Projektes zu ersetzen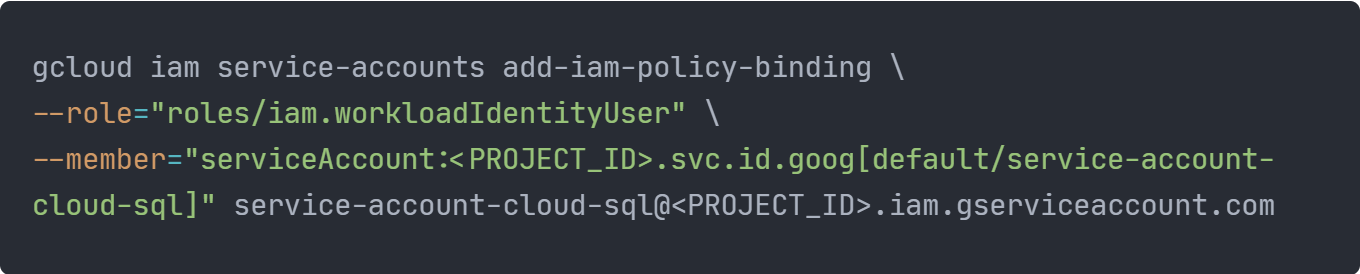
Außerdem muss die Verwendung von Workload Identity in der Konfiguration des GKE Clusters aktiviert werden. Hierzu haben wir unsere Terraform-Definition des Clusters um folgenden Abschnitt ergänzt:

Alternativen
Alternativ zu unserem Ansatz, ein Kubernetes Cluster bzw. die Google Kubernetes Engine zu verwenden, hätten wir auch eine Serverless-Architektur verwenden können. Dabei muss man sich nicht selbst um Infrastruktur kümmern und kann sich auf seine Anwendung konzentrieren. Außerdem bezahlt man hier lediglich pro Anfrage (beziehungsweise für deren Laufzeit) und muss die einzelnen Infrastrukturkomponenten nicht unterhalten. Dazu kann in der Google Cloud z.B. der Cloud Run oder der Cloud Functions Service verwendet werden.
Eine Alternative zur Google Container Registry (GCR) wäre die Google Artifact Registry gewesen, welche einige Vorteile gegenüber der GCR bietet. Zu diesen gehört z.B. dass Berechtigungen nicht nur auf Registry Host Ebene, sondern auch für einzelne Repositories vergeben werden können. Außerdem hat die Artifact Registry eigene IAM Rollen, um Zugriffsberechtigungen zu verwalten.
Trotz der vielen Vorteile der Artifact Registry haben wir uns dazu entschieden, die Container Registry zu verwenden. Dazu haben wir uns entschieden, da wir die Vorteile der Artifact Registry für unser Projekt nicht benötigt haben und die Container Registry nur minimalen Konfigurationsaufwand benötigt. Außerdem wollten wir nur ein einziges eigenes Docker Image in der Google Cloud verwenden, weshalb es nicht nötig war, Berechtigungen auf Repository Ebene vergeben zu können.
Anstatt mithilfe unseres Shell-Skripts hätten wir auch Terraform für die Kubernetes Deployments verwenden können. Dies war uns zu Beginn jedoch nicht bewusst, weshalb wir dafür auf ein Shell-Skript umgestiegen sind. Da wir allerdings auch lernen wollten, wie man die kubectl-CLI verwendet, um Kubernetes Deployments zu machen, hätten wir uns auch mit dem Wissen, dass es mit Terraform doch möglich ist, für ein Shell-Skript entschieden.
Erweiterungen
Um das volle Potenzial der Cloudinfrastruktur nutzen zu können, sind Erweiterungen und umfangreiche Anpassungen möglich.
Im Moment ist das Backend nur durch HTTP (nicht TLS gesichert) erreichbar. Da das Backend keinerlei Authentifizierung verwendet und lediglich öffentlich zugängliche Daten speichert, ist eine Sicherung der Übertragung mittels TLS auch nicht zwangsläufig notwendig. Da jedoch in manchen Systemen (zum Beispiel für Android Apps) nur Verbindungen über HTTPS erlaubt sind, ist eine Verschlüsselung der Verbindung wünschenswert. Durch eine umfangreichere Konfiguration des GKE Clusters kann die Kommunikation mittels HTTPS ermöglicht werden.
Da die Verwendung einer klassischen relationalen Datenbank nicht vollständig mit dem (global) verteilten Modell der Cloud vereinbar ist, kann die Datenbasis des Backends beispielsweise in eine NoSQL-Datenbank oder eine auf verteilte Infrastruktur spezialisierte relationale Datenbank (zum Beispiel Google Spanner) überführt werden.
Lessons Learned
Während unseres Projektes haben wir viel Erfahrung mit Cloud-Diensten der Google Cloud gesammelt. Zu diesen gehören Cloud SQL, Google Kubernetes Engine (GKE), Google Container Registry und Identity and Access Management (IAM). Um unsere Cloudinfrastrukur mittels Infrastruktur als Code zu konfigurieren, haben wir uns außerdem viel mit Terraform und der Verwendung des Google Cloud SDK (bzw. dem gcloud-CLI) und kubectl-CLI in einem Shell-Skript beschäftigt.
Leave a Reply
You must be logged in to post a comment.