The renowned computer scientist Leslie Lamport once stated, “A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable.” This quote encapsulates the complexity and difficulties in constructing large-scale distributed systems. Particularly when it comes to maintaining data consistency across multiple nodes, today’s big tech giants with their globally operating and highly available, data-sensitive systems, need to have a very well managed data storage system, as its availability or consistency is business critical.
Database characteristics
First, we should perhaps build a common understanding of why distributed database systems are difficult to manage. For this, it is worth having a look at the CAP theorem, that was first introduced in the early 2000s and quickly became a cornerstone of distributed systems design. The theorem states, that it is impossible for a distributed system to simultaneously provide all three properties of Consistency, Availability, and Partition tolerance (the cluster continues to function even if there is a communication break). The CAP theorem therefore presents a framework for understanding the fundamental limitations of distributed systems and serves as a guiding principle for system architects when making design decisions.
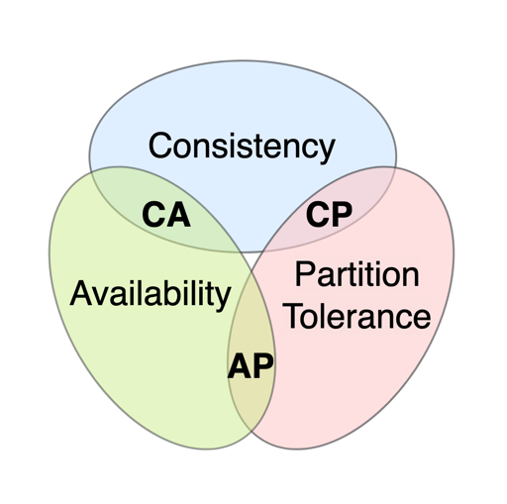
When it comes to distributed databases, the two real choices are only AP or CP combinations because if we do not stick to the partition tolerance, we do not have a reliable distributed database. So, the choice is simpler: do you want the database to be highly available, but answering with possibly old/bad data (AP)? Or should it stop responding unless you can get the absolute latest data (CP)?
In addition to the trade-off between the properties of the CAP theorem, it’s important to understand the difference between ACID (Atomicity, Consistency, Isolation, Durability) and BASE (Basic Availability, Soft state, Eventual consistency) properties when comparing SQL and NoSQL databases. SQL databases provide ACID guarantees, meaning that transactions are atomic, the database remains consistent with every transaction, each transaction is independent of any other transaction, and all transaction results are permanently preserved. However, ACID compliance in a distributed environment on SQL databases can lead to availability issues and therefore performance problems, which need to be minimized by complex database-design and -maintaining tasks.
In contrast, most NoSQL databases provide BASE guarantees, meaning that data is available most of the time, replicas are not consistent all the time but data will become consistent at some point in time, with no guarantee when. NoSQL databases sacrifice a degree of consistency, but can therefore increase their availability.
NewSQL: What is Google Spanner?
So that’s what we all learned at university. Yet that’s not all about databases. There is another system emerging on the market, which you may not have heard of: NewSQL databases. These systems combine the horizontal scalability and lock-free reads of NoSQL (without the huge sharding and normalization costs of traditional SQL databases) while still aligning to the ACID properties, especially its consistency. In the following, we will have a look at the market leader Google Spanner and elaborate on how it manages to provide a highly distributed, ACID-aligned database system while ensuring large transaction throughput throughout a clever concurrency control system.
Google Spanner implements its consistency requirements in a very classical way: It uses the Paxos consensus algorithm for replicating state machines and synchronizing nodes, two-phase locking to provide a serializable isolation between transactions, and a two-phase commit to ensure atomic commitment. These mechanisms are also complex in themselves but are used in the same way by other database systems already. Where Spanner differs from other consistent & globally distributed database systems is in its ability to provide lock-free read-only transactions (which optimize the response times of the database) on every node through providing linearizability.
Google Spanner avoids locking in read-only transactions by allowing the transactions to read from a consistent snapshot of the database. The snapshot is maintained using multi-version concurrency control (MVCC). Here, we assign a commit timestamp to every transaction, so every row is tagged with the timestamp of the transaction that wrote it. When an object is updated, a new version of it will be stored, instead of just overwriting the old value. This allows the read-only transaction to read the most recent version of each object that temporarily precedes it, while ignoring any versions with a greater timestamp. While that’s still a standard procedure, Spanner’s USP is the way it assigns these timestamps to its transactions, ensuring that snapshots are consistent with causality in a distributed system: In general, the MVCC method requires the timestamp of transaction T1, if happened before transaction T2, to be smaller than that of T2. This means that each transaction must appear in that order in which they arose in real-time. But there is a problem with clocks and time in distributed systems: Each node in a system has its own view of the current time, given by its own oscillating clock. Since these clocks are very unlikely to be synchronized across multiple nodes, it can be possible that a transaction T2 on node 2, which is performed later than transaction T1 on node 1, will get an earlier timestamp (from its lagging clock on node 2) than T1.
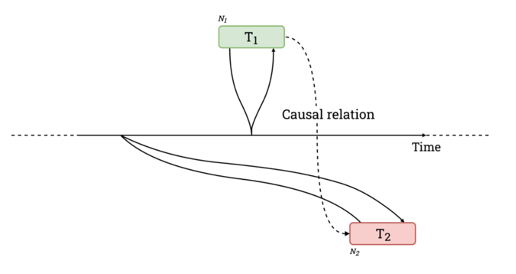
This is a problem, when we want to provide serializability in distributed databases, as MVCC requires that temporal and causal correlation are aligned. To face this problem, one could consider a designated server, which is responsible for assigning time stamps to transactions. This however is not a solution for widely distributed systems, as it would be both a single point of failure and massively increase the response times due to possibly very long round-trip times in case of distant servers. Therefore, a less centralized approach is required.
Googles TrueTime API
Googles TrueTime is a decentralized system of GPS and atomic clocks, which is part of every of Googles datacenters. You might ask: How do they ensure, that these precise clocks are perfectly in sync? The answer is: They don’t. At least they are not perfectly in sync. Instead of returning a single timestamp, Googles TrueTime API returns an uncertainty interval. Google is synchronizing every node’s quartz clock with the designated atomic clock every 30 seconds and assumes its nodes to drift at a maximum of 200ppm. This drift defines – together with the static 1 millisecond (round-trip time to the clock server + uncertainty of the clock server) – the uncertainty interval. This results in an uncertainty interval that increases from 1 millisecond to 7 milliseconds within 30 seconds and then decreases back to 1 millisecond.

Before a node is allowed to report that a write-transaction has been committed, it must wait for this uncertainty interval, while still holding its transaction specific locks.

This waiting ensures, that the timestamp of a transaction is less than the true physical time at the moment the transaction commits. So, the timestamp intervals of T1 and T2 do not overlap, even if the transactions are executed on different nodes. This effective implementation of a distributed MVCC system enables point-in-time consistency, which in turn provides serializable data, which enables lock-free read-only transaction on all nodes. This allows us to perform large analytical queries over a distributed database and get fast, repeatable and consistent results. To sum up, Google does not get rid of the overhead produced by two-phase commit but provides a way to “simulate” global clock synchronization, by just waiting an average of 4 milliseconds on write-transactions and thus enabling serialized data. In comparison: using NTP for clock synchronization is likely to take somewhere between 100ms and 250ms.
Other NewSQL databases
So after all that being said, you ask yourself if there is another option to use a highly performant consistent and distributed NewSQL databases for your business without being trapped in Googles pricing model or fearing a vendor lock-in.
Foremost, we have to state that as soon as multicloud deployment and a vendor-independent system should be made possible, we unfortunately can currently not assume that nowadays datacenters provide atomic clocks and their own TrueTime-like service. This makes it very hard to compete for other distributed newSQL databases.
But there are some open source approaches that try to develop a highly distributed and yet consistent database system without dedicated hardware. In the following, we will briefly look at the three most common newSQL alternatives: (CockroachDB, VoltDB and YugabyteDB). These alternatives also use consensus-solving protocols (CockroachDB & YugabyteDB use Raft, VoltDB its own protocol). In general, both systems are very similar to Google’s and partly imitate it. CockroachDB was even founded by former developers of Google Spanner. Now, however, the problem of clock synchronization comes to the surface and, as we have seen above, this synchronization can take long times with the standard NTP protocol, so that the database would become unusably inperformant. But here’s the interesting thing: all manufacturers claim that they have found a software solution to fix this problem. In open source systems, it is always convenient that a second authority can look over and verify the claims of the manufacturers. The Jepsen test has developed as a quasi-standard for testing databases, which has also examined these alternative newSQL databases:
- It turned out that CockroachDB does not provide any external consistency and thus, with a high clock offset between two nodes, transactions could get consistent. ⁵
- With VoltDB, it also became clear that the claims to be strictly serializable could not be fulfilled. So for example, dirty reads were possible in the test. ⁶
- Also, when testing the last alternative, YugabyteDB, it became apparent that there can be consistency problems with clock skews larger than the configured clock skew threshold. ⁷
But does that mean that Google is the only alternative on the market? Yes and no. There is currently no provider that offers such a high level of performance and consistency in terms of a newSQL database. But you have to keep in mind that these high SLAs are only needed in a few cases. For small to medium-sized companies, a traditional SQL database system with shards or a or noSQL database is the best option. In this respect, there are many different vendors and thousands of references to go by. However, Spanner remains an interesting option for ultra-large-scale systems that need to work on huge, structured amounts of data and rely on high availability, which Google claims to be 99.999% party also due to their huge and reliable network.
Conclusion
Last but not least, it is necessary to revalidate the negative connotation that might have arisen in this article about newSQL alternatives: The mentioned Jepsen reports state, that the developments of these projects have been very positive in the last years and more and more error sources could be eliminated by releasing new versions. Jepsen research affirms, that they are very excited about the new versions. So, in the end these new approaches are a trade-off: We avoid a vendor lock-in with Google, but in return we get a highly available and performant database that is almost consistent (almost fulfill the ACID properties) and has definitely less consistency problems than a standard noSQL database.
And maybe in the future, one or the other cloud provider will come along with its own true-time service in its data centers and possibly even expose its API to its customers. This would bring back some momentum, competition and disruption in the development of newSQL databases.
Sources
¹ image-source: https://en.wikipedia.org/wiki/CAP_theorem
² image-source: https://www.cockroachlabs.com/blog/living-without-atomic-clocks/
³ image-source: https://www.cl.cam.ac.uk/teaching/2122/ConcDisSys/dist-sys-notes.pdf
⁴ image-source: https://www.cl.cam.ac.uk/teaching/2122/ConcDisSys/dist-sys-notes.pdf
⁵ https://jepsen.io/analyses/cockroachdb-beta-20160829
⁶ https://aphyr.com/posts/331-jepsen-voltdb-6-3
⁷ https://jepsen.io/analyses/yugabyte-db-1.3.1
Leave a Reply
You must be logged in to post a comment.