
With the advancement of technology and the gradually increasing use of artificial intelligence, new markets are developed. One of such is the market of Voice AI which became a commercial success with voice bots such as Alexa or Siri. They were mainly used as digital assistants who could answer questions, set reminders and they could generally tap into various databases to provide the aid and service that they were ask to provide. Although the popular use case seems to be primarily domestic, we have long since experienced other applications for Voice AI in areas such as UI speech control, voice recognition and replication and in use within entertainment media.
Faced with the ever-present but ever-growing interest in artificial intelligence which continue to further their influence on society, industry and the commercial landscape, my post will strive to demonstrate and inspect the technologies surrounding the application of Voice AI but also the concurrent obstacles it needs to overcome. However, before we can dive deeper into the topic, it is important to introduce the concept of Voice AI and its general technological workings.
About Voice AI
The definition of Voice AI is not yet set in stone and it can vary based on the scope of application. What we can most likely agree on is that Voice AI is a component of conversational AI which the users can interact with. With a combination of machine learning and natural language processing, Voice AI can analyze language and speech in order to produce sound.[1] It can provide the user with a way to interact with the system in an auditory way as the system tries to interpret the human speech via voice recognition. In other cases the Voice AI technology can be used to generate human-like speech which is either pre-written by the user as a text-to-speech approach or as a result of trained AI that systematically responds with generated answers.[2] In either case, the Voice AI technology is bound to be a service that the users can make use of. This is especially true if we take into account the aspects of embedded system and enabling a hands-free user experience. For the purpose of keeping this blog post concise and on point, this post will demonstrate and inspect one application of Voice AI that is publicly available.
Voice AI Synthesis via VALL-E
AI TTS, also known as neural text-to-speech, makes use of neural networks and machine learning technologies. In a nutshell, the speech engine analyzes the audio input of a human voice via automatic speech recognition (ASR), and then try to understand the meaning of the words it has collected via natural-language generation (NLG). With the inclusion of neural networks, the artificial intelligence is able to learn the style of how people communicate with one another including response patterns and conversational flow. After the generation of the text that is intended to be converted into speech, a speech synthesis model is used to articulate and read the text.[3]
Right this moment the world is confronted with countless AI-generated voice-overs of popular figures which are flooding the internet. The infusion of AI and deep learning has revolutionized the TTS (text-to-speech) synthesis procedure to produce lifelike speech variations and severely decrease the “robotic”-like inflexion and pronunciation.[4] In a demonstration shown below, you will find a user-created conversation between two Voice AI models that were taught with voice samples of real media figures in order to perfectly mimic voice, inflexion and tone that is fitting for conversation:
The act of simulating a voice and utilize that synthesized voice to speak a provided text can be termed as Voice Cloning. The key is that the system is capable of gaining knowledge via speaker encoder to learn the intricacies of the input voice data. The resulting Voice AI model is then capable of altering any given voice input waveform by decoding it.[5] In concern to the generation of a Voice AI model, Microsoft for example has released a TTS AI model called VALL-E that is essentially a neural codec language model which is capable of simulating a person’s voice after being trained with only a few seconds of audio samples. The main selling point of this particular TTS Voice AI model is its ability to preserve the speaker’s emotion and acoustic environment that was present in its audio samples. This feat is achieved through a combination of generative AI models like GPT-3 and coupled with speech editing and content creation and including 60.000 hours of English speech data.[6]
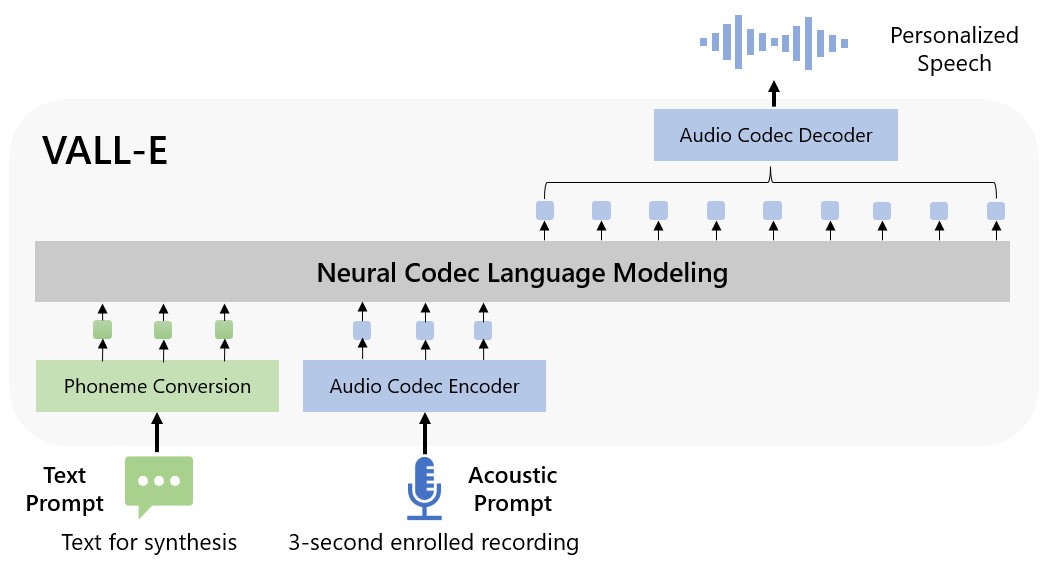
A github page was published to show the features of VALL-E’s advanced speech synthesis and speech generation methods for research demonstration purposes. These include:
- Synthesis of Diversity: Synthesizing sample with various and differing speech pattern
| VALL-E Sample 1 | VALL-E Sample 2 |
- Acoustic Environment Maintenance: Preserving the acoustic environment of voice sample
| Voice sample | VALL-E sample |
- Speaker’s Emotion Maintenance: Preserving tone and emotion of voice sample
| Voice sample: Sleepy | VALL-E sample |
The benefits of Voice AI cannot be understated. Especially in systems that heavily rely on (semi)-automated customer service, the application of Voice AI can bring tangible effects for process pipelining and cost reduction. That is especially true in regard to splitting work labor into repetitive tasks that an AI can be trained to do and tasks that requires human interaction. Voice AI does not only benefit the company which utilizes Voice AI for answering user inquiries, but it can also become a vital support for clients and customers who suffer from speech impairment. Even considering the use cases beyond customer support services, Voice AI can decrease the communication friction that occur during interaction between human and AI, therefore improving the user experience regardless of use case.[2]
Voice Waveform Alignment via VITS
VITS stands for Variational Inference with Adversarial Learning for End-to-End Text-to-Speech and I hope you can accept how this acronym came to be. VITS in purest definition is a TTS model that is capable of text-to-audio alignment by utilizing Monotonic Alignment Search (MAS) whereas other TTS models may require external alignment annotations.[7][8] The use of the latter may result in unwanted long utterances and out-of-domain text and may also cause missing or repeating words in the synthesized speech. Typically, a neural TTS model aligns their text and speech either via attention mechanism or by a combined use of a mapping encoder (text input → state) and a decoder (state → mel-spectogram / waveform). Although techniques and methods for these alignment processes were improved by utilizing both content and location sensitive attention, these models still suffer from the aforementioned issues.[9]
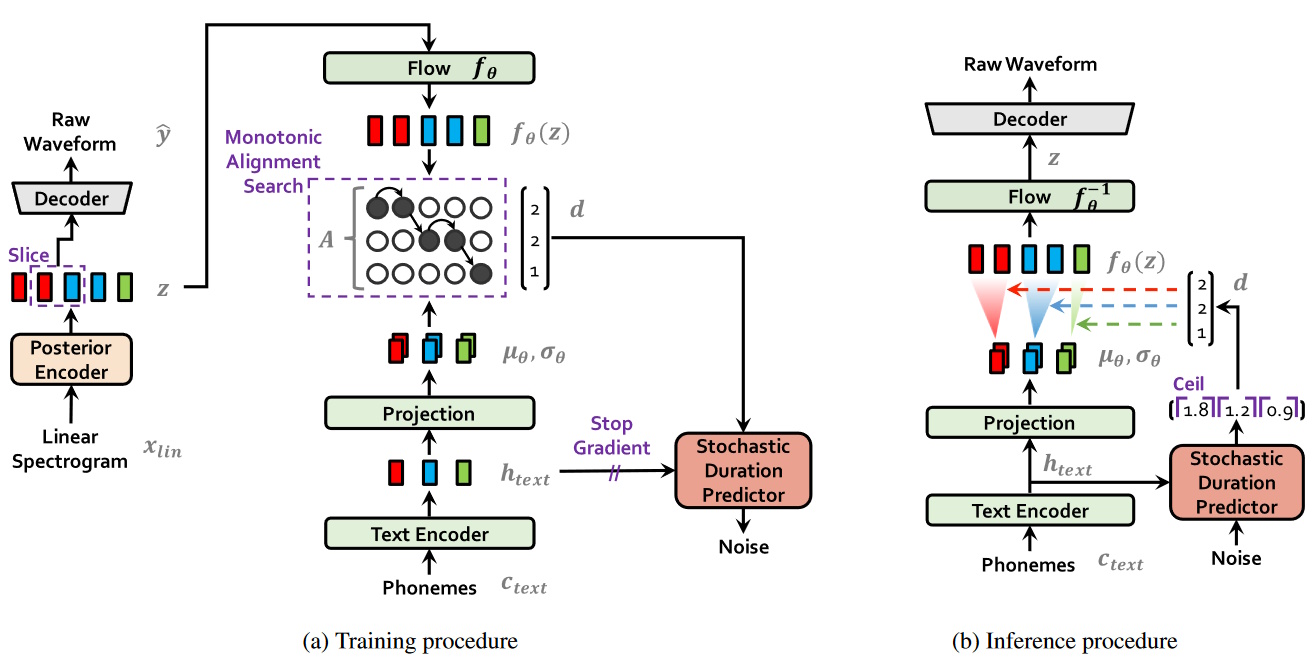
Even though VITS is by far not the only model who tries to tackle the issues, it tries to combat the alignment issue by adversarial learning, Monotonic Alignment Search and the use of a variational autoencoder. Adversarial learning is a machine learning algorithm that is applied onto the waveform domain. To describe is swiftly, the adversarial training utilizes a discriminator that distinguishes between the decoder output and the ground truth waveform in order to calculate the reconstruction loss which in turn can be predicted, trained and aligned via a model architecture built out of a hierarchy of interdependent encoders.[8] Monotonic Alignment Search (MAS) is a method of searching the most probable monotonic alignment between the latent variable and the statistics of the prior distribution of input speech and text. In practical relation with VITS, MAS is capable of estimating the alignment that is necessary to maximize the variational lower bound which in turn is important for natural sounding and stable speech.[10] A variational autoencoder is a likelihood-based deep generative model and it is also termed as VAE. VITS’s usage of the VAE is in combination with MAS in order to remove the burden of being dependent on attention mechanisms and in exchange allow for simpler architecture of continuous normalizing flows that benefits the process of adversarial training.[8]
Applied VITS in Singing Voice Conversion (SVC)
Connoisseurs of Voice AI can create their own song covers by utilizing voice samples and a pre-trained Voice AI model. The subsequent Voice Cloning can align the pitch and inflexion of the source waveform and apply the discretely encoded voice data onto it. The effect is immediate and a use case for the public had been made. Several repositories provide all the necessary means to create something of your own.
Example 1:
Speaker Prompt:
Source Waveform:
Result:
Example 2:
Speaker Prompt:
Source Waveform:
Result:
Example 3:
Speaker Prompt:
Source Waveform:
Result:
Benefits and friction points
Everyone who had the pleasure of playing the latest Harry Potter video game must have come across the character creator and felt the voice options either lackluster or comedic, or both. The voice production department must have decided to record the lines for both genders once and then offer ways to pitch that voice for a shallowly illusion of variety. The result was far from ideal but it did save money and coordination time with external voice acting agencies. However, the robotic and unnaturally pitched sound quality caused harm to the game’s ability to immerse the player. If the application of Voice AI was more pronounced and the workflow stable and tested, then this would have resulted in a far more favorable impression and converted to a higher revenue due to budget savings on voice acting expenditure. Although it would still be required to record the base voice lines, Voice AI could be utilized afterwards to shape the voice to the player’s preferences. The domain of voice alterations could be treated the same way how a player would change their hairstyle or body shape.
Back in the day with car navigation assistance, the voices were often robotic and generic. Many modern video games also have options to change the voice of the game announcer. So-called announcer-packs and Voice DLCs (downloadable content) were sold to give an existing game more variety and a more personalized user experience. The emergence of Voice AI may very well revolutionize the way how games and media in general handle and treat voice resources. It does, however, not only have benefits to show for. Just like with deepfakes, the claim of identity theft and impersonation is no trifling matter, especially when Voice AI is capable of reproducing voice and emotional nature. How could someone protect the commodity that is their voice, given that a mere three second sample is sufficient in order to establish the Voice AI model?[11]
Lastly, the voice acting industry can expect to take a hit once the use and the workflow with using Voice AI has been stabilized. Especially small studio productions can barely compete with an ocean of synthesized options.[12] On the other hand, independent people can submit their own voice as something others have to pay for. Needless to say, this market would be yet another thing that emerged from Voice AI and is something that could spiral out of control.
Conclusion
Voice AI has proven to become the next big thing in revolutionizing user experience and bridging the communicative aspect of human-computer interaction. As with every technology, the intricacies of how the AI’s capability to learn and to adapt can lead to much better and usable performance in the coming months and years and it is only a matter of time before the industry fully shifts towards its undeniable benefits. The only thing that we need to look out for is to create proper guidelines and regulations and think on how to deal with the emerging push-and-pull effects that are inevitably introduced alongside Voice AI.
In the end, Voice AI can only function as a benefactor of creative vision and a supporter of those who lack a voice, when it is used without ill intentions. Right now the flood gates are opened and everyone is encouraged to jump on the hype and play around with the new ways that Voice AI can spice up their everyday lives.
References
[1] IBM. Conversational AI. published on 02.01.23. https://www.ibm.com/topics/conversational-ai (last accessed: 27.02.23)
[2] LilChirp. Voice AI: What is it and How Does it Work? published on 22.11.22. https://lilchirp.io/blog/voice-ai/ (last accessed: 27.02.23)
[3] Oliver Skinner. Text to Speech Technology: How Voice Computing is Building a More Accessible World. published on 09.06.20. https://www.voices.com/blog/text-to-speech-technology/ (last accessed: 27.02.23)
[4] Ethan Baker. AI Evolution: The Future of Text-to-Speech Synthesis. published on 16.02.23. https://www.veritonevoice.com/blog/future-of-text-to-speech-synthesis/ (last accessed: 27.02.23)
[5] George Seif. You can now speak using someone else’s voice with Deep Learning. published on 02.07.19. https://towardsdatascience.com/you-can-now-speak-using-someone-elses-voice-with-deep-learning-8be24368fa2b (last accessed: 27.02.23)
[6] Chengyi Wang, Sanyuan Chen, Yu Wu. Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers. published on 05.01.2023. https://arxiv.org/abs/2301.02111 (last accessed: 27.02.23)
[7] Coqui TTS Team. VITS Documentation. published on 14.08.21. https://tts.readthedocs.io/en/latest/models/vits.html (last accessed: 01.03.23)
[8] Jaehyeon Kim, Jungil Kong, Juhee Son. Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech. published on 11.06.2021. https://arxiv.org/abs/2106.06103 (last accessed: 01.03.23)
[9] Rohan Badlani, Adrian Ła ́ncucki, Kevin J. Shih, Rafael Valle, Wei Ping, Bryan Catanzaro. One TTS Alignment To Rule Them All. published on 23.08.21. https://arxiv.org/abs/2108.10447 (last accessed: 01.03.23)
[10] Jaehyeon Kim, Sungwon Kim, Jungil Kong, Sungroh Yoon. Glow-TTS: A Generative Flow for Text-to-Speech via Monotonic Alignment Search. published on 22.05.20. https://arxiv.org/abs/2005.11129 (last accessed: 01.03.23)
[11] Justin Carter. Voice Actors Are Having Their Voices Stolen by AI. published on 12.02.23. https://gizmodo.com/voice-actors-ai-voices-controversy-1850105561 (last accessed: 03.03.23)
[12] Joseph Cox. ‘Disrespectful to the Craft:’ Actors Say They’re Being Asked to Sign Away Their Voice to AI. published on 07.02.23. https://www.vice.com/en/article/5d37za/voice-actors-sign-away-rights-to-artificial-intelligence (last accessed: 03.03.23)
Image and figure sources
Banner image: https://www.intelligentliving.co/ai-can-preserve-persons-voice-few-hours-recordings/
Figure 1: https://valle-demo.github.io/
Figure 2: https://arxiv.org/abs/2106.06103
Leave a Reply
You must be logged in to post a comment.