
While developing our guessing game “More or Less”, we encountered a common challenge many developers face: determining the structure of our data model.
Challenge 1: List vs. Detailed View
Many websites show an excerpt of their content in a list view. In our “More or Less” game, for example, we see a series of game cards. Each card shows the game’s title, a picture, a short description, and the creator’s name. If we click on a card we get redirected to a single game where we can play the game with the game data.
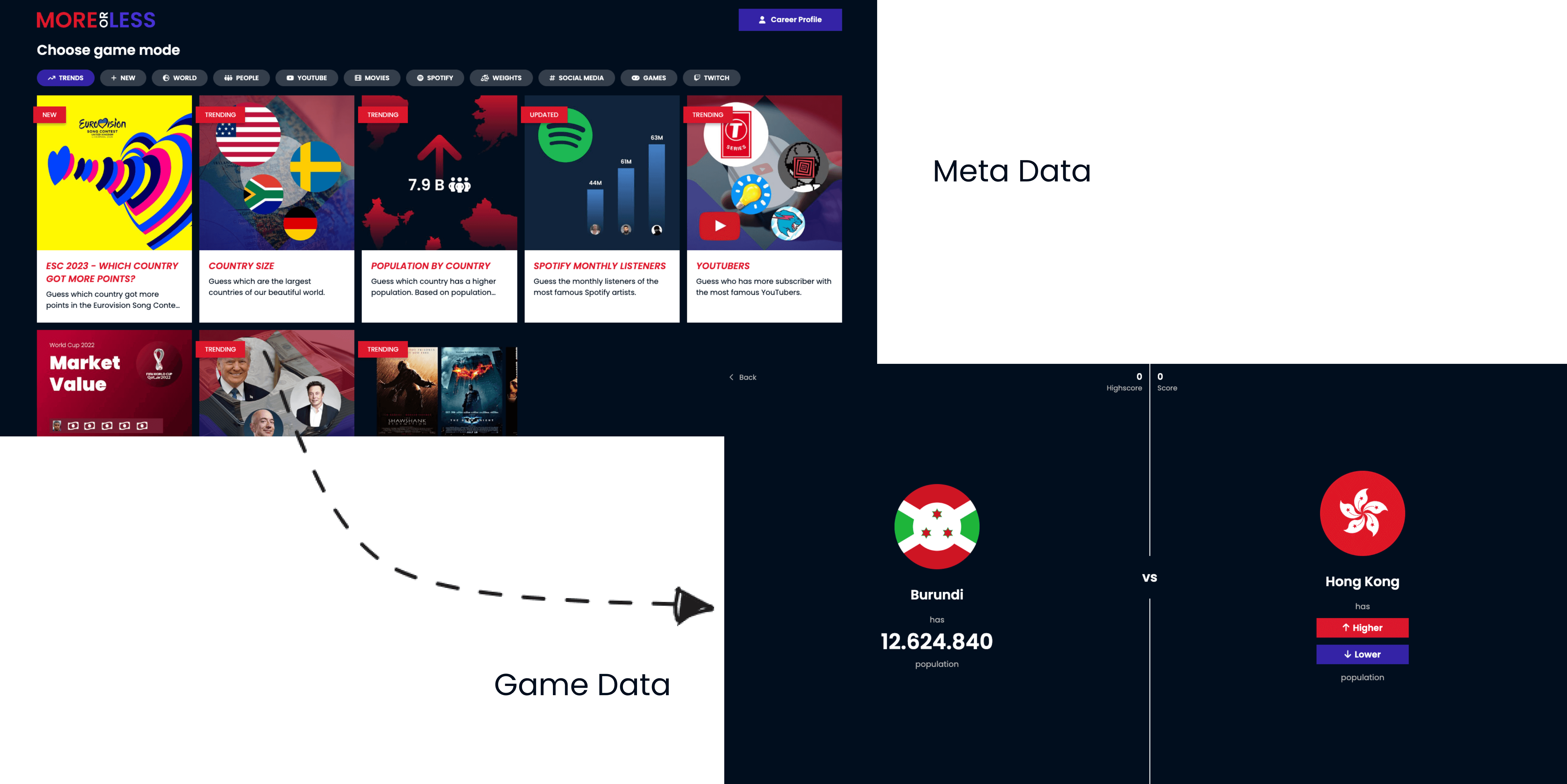
What could a data structure for this purpose look like?
The simple way
One solution for this could be setting up a game object with all metadata and an object with the additional game data.
{
gameId1: {
metaData: {
title: ...,
// Other game meta...
gameData: {
items: ...
strings: ...
// Other game data for single game
}
},
gameId2: {
metaData: {
title: ...,
// Other game meta...
gameData: {
items: ...
strings: ...
// Other game data for single game
}
},
// Other games
}In our overview, we fetch all games and show only the metadata. When we get a single game, we fetch the same and just take the game data.
Thats a simple and straightforward solution but has some disadvantages:
- Over-fetching Data: With the simple structure, you fetch all the data (both meta and game data) even when you only need a part of it for the list view. This will increase the traffic and also make the initial page load slower.
- Scalability Concerns: As the number of games grows, the amount of unnecessary data fetched for the list view can become significant, degrading the user experience.
Given these disadvantages, how can we fix those?
For the list view:
- Fetch just the data which actually gets displayed.
- Avoid getting all the data for every game right away. This way, pages load faster, and we have less traffic.
When a user clicks on a game card:
- We want to fetch all the game data for that single game.
So how can we structure our data model to meet these needs efficiently?
Reads over Writes
Websites, like “More or Less”, often involve more reading than writing. Think about it: players frequently search for or play a game, but they don’t often create or delete one. So, we read game modes more than we write them.
With that in mind, our data structure should prioritize reads.
But remember: This doesn’t have to mean that’s the right way for everyone: In your own project, think about, how often a user reads things and how often the user creates, updates or deletes something? Is it more read or write heavy?
A Solution with Firebase
In our project we decided to use Firebase Firestore as our dynamic database. Here is our solution for the problem.
1. Modelling Data Structure in Firestore
Instead of stuffing the games collection with all our data, we’ll just add the essential details, or metadata, for each game. This makes our list view efficient.
games (collection)
|
|-- gameId1 (document)
| |-- title
| |-- userId
| |-- visibility
| |-- createTime
| |-- updateTime
| |-- image
| |-- description
| |-- tags
| |-- badgeFor more game details like game items, a sub-collection named gamedetails can be nested within each game document. Firestore will treat this subcollection like its own collection. If you fetch the game document you will not automatically get the subcollection. This allows us to only get the metadata in the list view and fetch the game data in the single view.
games (collection)
|
|-- gameId1 (document)
| |-- title
| |-- userId
| |-- ...
| |
| |-- gamedata (sub-collection)
| |-- data (document)
| |-- items
| |-- item1
| |-- title
| |-- value
| |-- image
| |-- ...
|-- gameId2 (document)
...2. Fetching List View Data
When we want to display the list of games, we now just fetch the games collection
const gameRef = collection(firestore, "games")
const gamesSnapshot = await getDocs(gameRef)
const games = gamesSnapshot.docs.map((doc) => (doc.data())
return games3. Fetching Detailed Data for a Single Game
When a user selects a specific game, we can then fetch the game data from the sub-collection:
const gameDataRef = doc(firestore, ”games”, slug, “gamedata”, ”data”)
const gameDataSnapshot = await getDoc(gameDataRef)
const gameData = gameDataSnapshot.data()
return gameDataGreat! But when we are trying to implement this in our frontend, we have another problem. The username. How can we display each author username on our card?
Challenge 2: Translating User IDs to Usernames
To avoid storing data multiple times, we often save just the user’s ID in a list item and keep user details in a separate collection (users collection).
This method is called normalization and a good practice in SQL databases.
But we are using a Firstore which is a NoSQL database: So when we show game cards in the list, how can we turn those IDs into the actual usernames?
Adding the username to our games directly: Denormalization!
Denormalization is a database design technique where you intentionally duplicate or store redundant data.
In “More or Less”, we stored the user along with their name in the “games” collection. This means that when we fetch our games, we instantly get the user information along with the game mode:
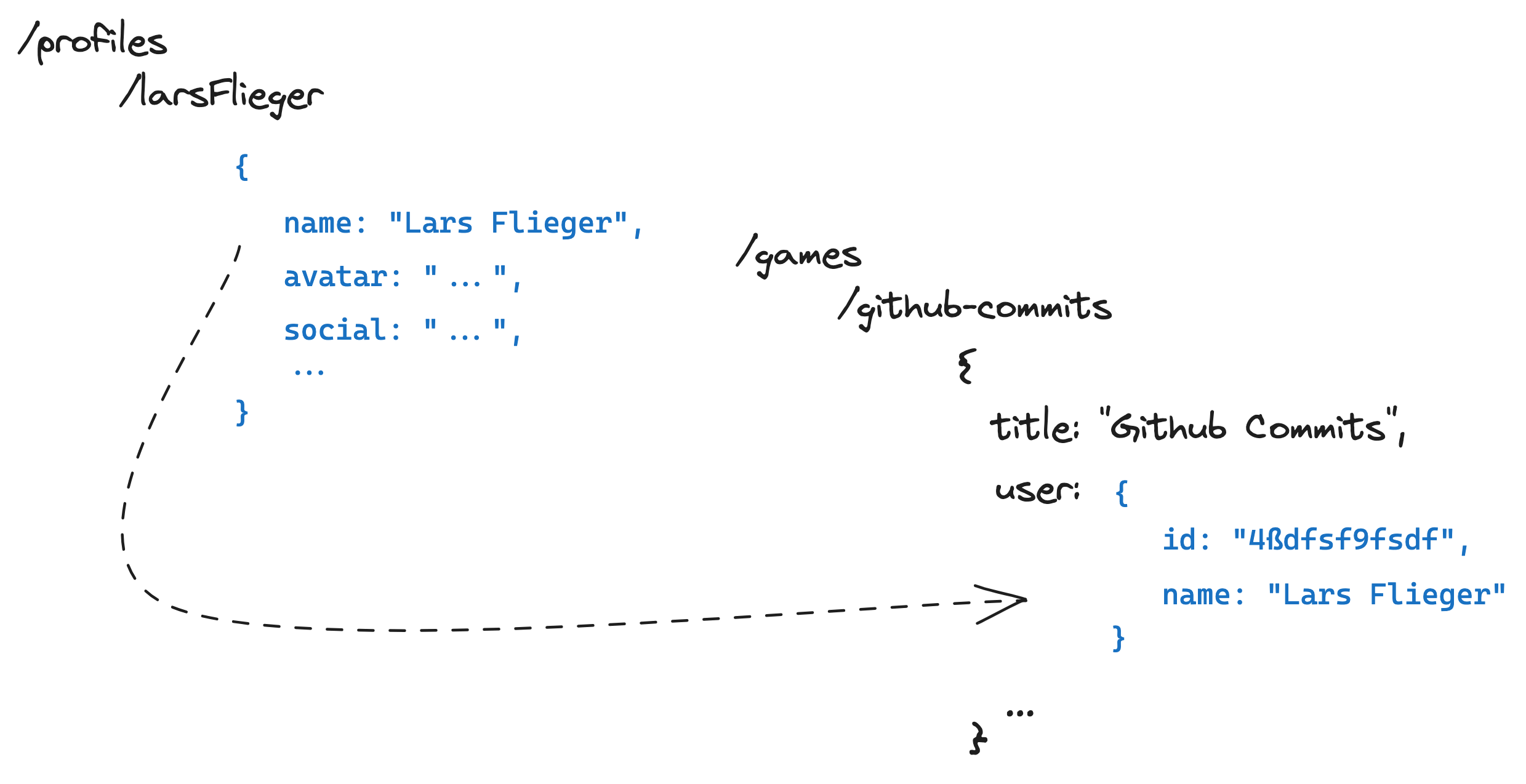
So, our games collection is now updated like this:
games (collection)
|
|-- gameId1 (document)
| |-- title
| |-- user: { id, username } // userId
| |-- visibility
| |-- createTime
| |-- updateTime
| |-- image
| |-- description
| |-- tags
| |-- badgeBut now we are storing the data duplicated?
You’re right. But that’s okay.
Storing data is cheaper than repeatedly fetching large amounts of it. We reduce the need of populating the data and speed up data fetching. So, our focus is on storing data in a way that’s fast and easy to read, even if it means keeping some duplicate information.
Cool but now our writing is getting more complicated?
Firebase changes how we think about our data with its nested collections and documents. It’s really good for reading data. Writing data might take a bit more effort compared to something like an SQL database. Here is an example of how it would look like to update a game mode:
const batch = writeBatch(firestore)
// Set game meta
batch.set(doc(firestore, ”games”, game.slug), {
title: game.title,...
})
// Set game data
batch.set(doc(firestore, “games”, game.slug, ”gamedetails”, ”data”), {
items: game.items,...
})
await batch.commit()We have to do two operations to update our game now. But that’s fine, since we read data way more often than we write it.
Can you not just use something like SELECT?
Wouldn’t it be much easier to just have something like SELECT and pick the field which we require.
Yes and No.
Using the Client SDKs, you can’t fetch just a subset of fields for a Document. When you access a Document, you’ll receive all its fields, the same goes for when you’re fetching a collection.
However, if you want to obtain only specific fields for a Document, you can do so using the Firestore REST API. With this API, you can apply a Projection when retrieving a collection. Specify the desired fields in the payload for the API call, and they will be returned to you.
In our project we are using the Client SDK, since it provides a lot of great features and makes the communication a lot easier than using REST. Adding another method, REST calls, for list views makes the frontend code more complicated and adds logic to a fetch which makes it slower in the end. That’s the reason why we decided to use our approach of splitting the data.
Conclusion
Throughout our journey with “More or Less”, we learned how important the data model is. At first, Firebase’s limitations felt challenging, but as we delved deeper, we discovered its simplicity brought many advantages.
Now put your skills to the test: Dive into our game and guess which repository has more commits.
Our highscore was 23, are you able to beat that? 😉
Happy Guessing!
Leave a Reply
You must be logged in to post a comment.