tl;dr: Unser Semester-Projekt bestand im Aufbau einer skalierbaren File-Share-Lösung auf AWS auf Basis von NextCloud. Unsere Motivation bestand darin die volle Kontrolle über die eigenen Daten zu erlangen, individuelle Anpassbarkeit zu ermöglichen und eine Kosteneffizienz zu erreichen. Es wurden klare Ziele in den Bereichen Verfügbarkeit, Performanz, Sicherheit und Skalierbarkeit definiert, anhand deren das Projekt ausgerichtet wurde. Dabei kamen AWS-Dienste wie VPC, Route 53, Certificate Manager, ALB, ASG, EC2, RDS und S3 zum Einsatz. Learnings aus diesem Projekt bestanden in den für uns wertvollen Einblicken in Planung, Skalierung und Herausforderungen mit AWS-Services.
Motivation
Wie man einen Cloud-Dienst – ähnlich wie iCloud oder Google Drive – entwickelt und dabei möglicherweise den hohen Gebühren entkommen kann , beschäftigt uns schon seit geraumer Zeit. Im Rahmen der Vorlesung System Engineering & Management hatten wir dieses Semester die Gelegenheit dieser Frage nachzugehen.
Die Entscheidung, einen eigenen Cloud-Dienst aufzusetzen, bietet gleich mehrere interessante Aspekte.
Ein wesentlicher Vorteil liegt in der vollständigen Kontrolle über die eigenen Daten. Da der Standort und die Speicherung der Daten selbst bestimmt werden, entfällt die Abhängigkeit von externen Anbietern – und damit möglicherweise auch der Vendor-Lock-In. Gleichzeitig bringt diese Selbstbestimmung jedoch auch volle Eigenverantwortung für die Datensicherheit mit sich, was ein erhebliches Risiko darstellen kann.
Ein weiterer Vorteil liegt in der individuellen Anpassbarkeit des Dienstes. Anders als bei standardisierten Angeboten etablierter Cloud-Anbieter bietet eine eigens entwickelte Lösung die Möglichkeit, Konfiguration und Anpassungen exakt auf die spezifischen Bedürfnisse des Nutzers abzustimmen – auch wenn dies mit einem höheren initialen Entwicklungsaufwand verbunden ist.
Angesichts der oft hohen monatlichen Kosten kommerzieller Cloud-Dienste stellt sich die Frage, ob eine eigene Lösung langfristig kosteneffizienter betrieben werden kann. Auch wenn sich diese Frage nicht pauschal beantworten lässt, bietet sie zumindest den Anreiz, alternative Ansätze auszuprobieren.
Nicht zuletzt bietet dieses Projekt zudem die ideale Möglichkeit, praxisnah wertvolle Erfahrungen in der Entwicklung mit modernen Cloud-Technologien zu sammeln. Wie Richard Feynman schon sagte: “What I cannot create, I do not understand”, wollen wir durch dieses Projekt lernen, was es bedeutet, einen eignen Cloud-Dienst skalierbar aufzubauen.
Ziele
Um den Rahmen für unser Projekt und die spätere Architektur klar abzustecken, haben wir zunächst präzise Ziele definiert. Ein zentraler Entschluss war, die Anwendungslogik nicht selbst zu entwickeln – da unser Team aus lediglich zwei Personen besteht. Stattdessen haben wir uns bewusst dafür entschieden, eine bestehende Open-Source-Lösung zu integrieren. Aufgrund der umfassenden Dokumentation und einer großen Entwickler-Community fiel die Wahl auf NextCloud. Diese Entscheidung ermöglichte es uns, unseren Fokus auf die kritischen Aspekte der Architektur zu legen, anstatt auf die reine Softwareentwicklung.
Orientierung über den gesamten Projektverlauf hinweg gaben uns daher die nach folgenden Ziele:
1. Verfügbarkeit
Die Architektur soll eine prinzipielle Verfügbarkeit von 99,9% gewährleisten.
Das bedeutet, dass innerhalb eines Monats maximal ca. 43 Minuten ungeplante Downtime toleriert werden dürfen. Diese hohe Verfügbarkeit erfordert mehr als den Einsatz eines einzigen Servers. Stattdessen müssen ausfallsichere Strukturen in die Planung einbezogen werden, um die geforderte Betriebszeit sicherzustellen.
2. Performanz
Ein weiteres Ziel ist die schnelle Reaktionszeit der Anwendung.
Konkret soll die Time-to-First-Byte (TTFB) der Benutzeroberfläche unter 200 ms liegen.
Dieser häufig genannte Richtwert gewährleistet, dass Nutzer nahezu unmittelbar eine Antwort beim Aufruf der Seite erhalten.
3. Sicherheit
Angesichts der sensiblen Daten, die in einer persönlichen Cloud verarbeitet werden, ist Sicherheit eines unserer Hauptziele.
Zum einen soll ausschließlich ein verschlüsselter Zugriff via HTTPS realisiert werden, um Daten vor unerlaubtem Zugriff zu schützen.
Zum anderen soll die Registrierung neuer Accounts so gestaltet werden, dass zwar eine Registrierung möglich ist, der tatsächliche Zugriff jedoch erst nach einer manuellen Bestätigung durch einen Administrator freigegeben wird.
Diese Maßnahme verhindert, dass sich unkontrolliert zahlreiche Nutzer registrieren, und stärkt somit die Systemsicherheit.
4. Skalierbarkeit
Die Skalierbarkeit der Anwendung ist ein weiterer zentraler Aspekt.
Sie muss gewährleisten, dass auch bei steigender Nutzerzahl keine Einbuße in der Performance auftreten.
Das bedeutet, dass in der Regel mehrere Frontend-Server horizontal hinzufügbar sein müssen, während der Speicher zentralisiert wird. Dieses Konzept ermöglicht es, bei steigendem Traffic weitere Instanzen hinzuzufügen, um die Leistungsfähigkeit aufrecht zu erhalten.
Architektur
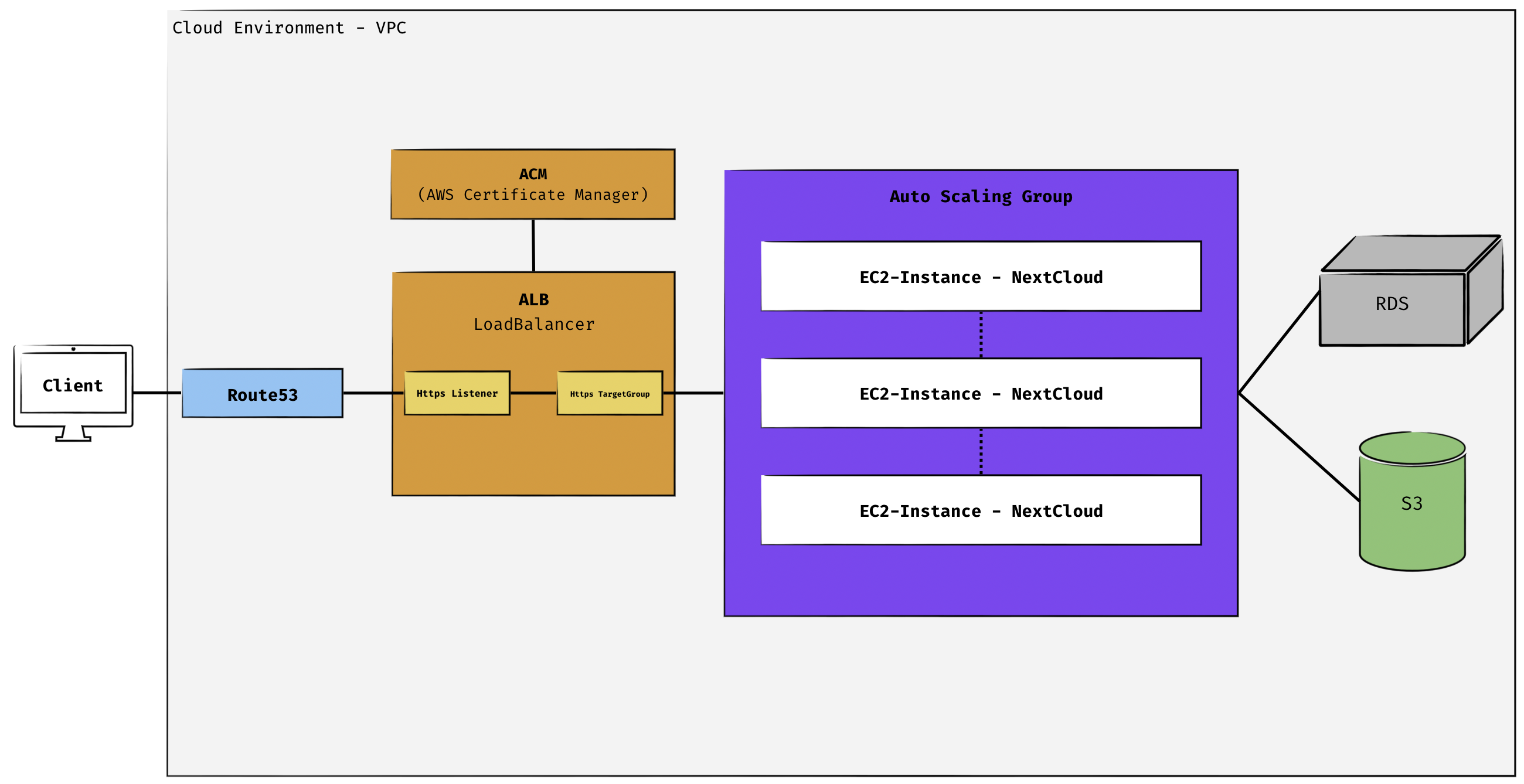
Network & DNS
- Route 53: Wird genutzt, um eine eigene Domain auf die Anwendung zu routen.
- Subnets: Mindestens zwei Subnets (z. B. Public und Private), um Netzwerkzugriff und Sicherheitsanforderungen zu berücksichtigen.
- VPC (Virtual Private Cloud): Isolierter, sicherer Netzwerkbereich in AWS in der die Anwendung betrieben wird.
- Certificate Manager: Stellt TLS-Zertifikat für den Load Balancer bereit, was die Verbindung über https sichert.
Load Balancing
- Application Load Balancer (ALB):
- Nimmt eingehenden Traffic über die Listener entgegen.
- Verteilt den eingehenden Traffic gleichmäßig auf die verfügbaren EC2-Instanzen (TargetGroup).
Compute-Resources
- EC2-Instanzen:
- Instanzen hosten die NextCloud-Applikation.
- Mehrere EC2-Instanz (t2.micro) sind im private Subnet über den ALB erreichbar.
- Kommunizieren mit RDS (Metadaten) und S3 (Dateien).
Storage-Backend
- S3-Buckets:
- Dateien der Nutzer liegen nicht lokal auf der EC2-Instanz, sondern in einem S3-Bucket. Dadurch können mehrere EC2-Instanzen auf dieselben Daten zugreifen.
- Relationale Datenbank (RDS):
- Bietet einen zentralen Speicherort für Metadaten, der von allen EC2-Instanzen gemeinsam genutzt wird.
Security
- Security Groups:
- Eingehender Traffic nur vom ALB mittels HTTPS an die EC2-Instanzen.
- EC2 hat outbound Zugriff auf S3 und RDS.
- IAM-Rollen:
- EC2-Instanzen erhalten IAM-Rollen, um sicher und direkt auf S3 und RDS zugreifen zu können (ohne feste Keys in der Applikation).
- Benutzerregistrierung mit approval-Mechanismus:
- Registrierung benötigt Bestätigung der Konten zur Aktivierung.
Scaleability
- Auto Scaling Group (ASG):
- Bekommt von ALB anhand verschiedener Metriken mitgeteilt ob weitere EC2-Instanzen hinzugefügt werden sollen oder ob sie heruntergefahren werden können.
- Auf Datenebene sorgen der S3 und RDS Speicher dafür, dass Daten zentral ausgelagert sind.
Monitoring & Logging
- CloudWatch Logs & Metrics: Überprüfung der CPU oder RAM Auslastung der EC2-Instanzen sowie Verfügbarer Speicherplatz der S3-Buckets.
- Health Checks: Überwachen Metriken wie Netzwerkauslastung und Instanz-Gesundheit.
Entwurfsentscheidungen
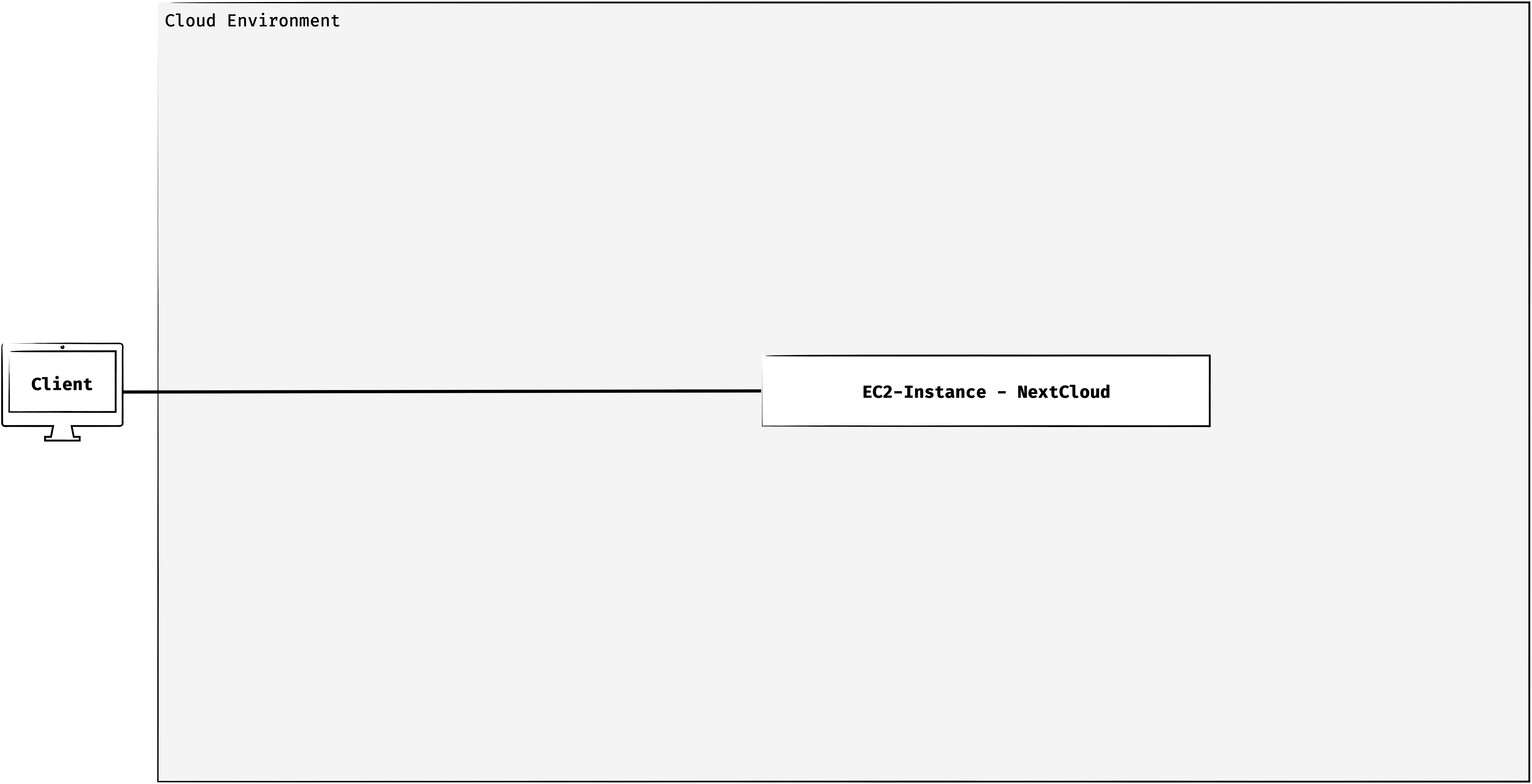
Ausgangspunkte für unsere Überlegungen hinsichtlich der Architektur war zunächst unser erster Proof-of-Concept (siehe Abbildung oberhalb). Hierbei war unser primäres Ziel NextCloud zugreifbar auf einer EC2 Instanz zum laufen zu bringen. Allerdings unterstützt diese Version keines unserer genannten Ziel, weshalb wir von hier aus die Architektur grundlegend aufbauen mussten.
Den Einstiegspunkt bildet die Client-Seite von der aus Nutzer über ihren Browser auf unsere Anwendung zugreifen können. Um eine bessere Nutzererfahrung zu bieten wollen wir einen Zugriff über eine gleichbleibende Domain ermöglichen. Dabei viel unsere Wahl auf den AWS eigenen Service Route53.
Gerade für einen Cloud Service, bei dem teils sensible Daten hochgeladen werden, ist ein verschlüsselter Datenaustausch unerlässlich. Deshalb wird der gesamte Datenverkehr ausschließlich über HTTPS abgewickelt. Die hierfür nötigen SSL/TLS-Zertifikate werden über den AWS Certificate Manager bereitgestellt, was einen soliden Sicherheitsstandard garantiert. Hierbei könnten auch externe Zertifikatsdienste wie Let’s Encrypt in Betracht gezogen werden, was insbesondere dann sinnvoll sein kann, wenn man eine Unabhängigkeit von einem einzigen Anbieter anstrebt. Im Rahmen dieses Projekts hat für uns jedoch die nahtlose Integration in die AWS-Umgebung überwogen.
Hinsichtlich der Skalierbarkeit haben wir uns bewusst für eine horizontale Skalierung entschieden. Es bietet im Gegensatz zu einer vertikalen Skalierung, bei der wir lediglich eine EC2-Instanz mit starker Speicher und Rechenleistung dauerhaft betreiben hätten müssen, folgende Vorteile:
- Verbesserte Skalierbarkeit, da Instanzen nach Auslastung weg oder dazu geschaltet werden können.
- Daraus resultierende Kostenvorteile, aufgrund der Möglichkeit bei geringer Nutzung, Leistungsschwächere und kostengünstigere Instanzen zu betreiben.
- Ermöglicht eine durchgehende Verfügbarkeit und bessere Wartbarkeit.
- Erhöht die Ausfallsicherheit, da auf weitere Instanzen zurückgegriffen werden kann.
Ein Load-Balancer ist für eine horizontale Skalierung und zur Erreichung unserer definierten Ziele unerlässlich. Er übernimmt die Aufgabe, den eingehenden Traffic über definierte Listener an die EC2-Instanzen zu verteilen. Da es sich bei einem File-Share um keine Latenzkritische Anwendung handelt, wie z.B. Online-Games oder Streaming-Dienste, sondern eher flexibles Routing und Lastenverteilung benötigen, viel die Wahl auf den Application Load Balancer. Durch das Monitoring der „Gesundheit“ der Instanzen leitet er den Traffic automatisch an “gesunde” Instanzen weiter, was die Systemverfügbarkeit deutlich erhöht. Skalieren lässt sich unsere Anwendung jedoch erst im Zusammenspiel des ALB mit einer Auto-Scaling-Group (ASG). Die ASG reagiert auf die Mitteilungen des ALB zum Zustand verschiedener Metriken wie CPU-Auslastung oder Netzwerk-Traffic und passt daraufhin die Anzahl der EC2-Instanzen dynamisch an den tatsächlichen Bedarf an. Dies ermöglicht eine optimale Ressourcennutzung, da Instanzen bei geringer Last automatisch heruntergefahren und bei steigender Nachfrage neue hinzugefügt werden. Dieser Ansatz ermöglicht eine hohe Ausfallsicherheit – wenn es auch Herausforderungen der Datenredundanz mit sich bringt.
Anstatt einzelne EC2-Instanzen zu verwalten, hätte man auch Container einsetzen können, die über Plattformen wie Amazon Elastic Container Service (ECS) oder Amazon Elastic Kubernetes Service (EKS) orchestriert werden. Containerisierte Anwendungen haben den entscheidenden Vorteil, dass sie portabler sind und sich leichter zwischen verschiedenen Cloud-Anbietern bewegen lassen. Allerdings steigert dieser Ansatz ebenfalls die Komplexität, die den Mehrwert insbesondere im Kontext unseres Projekts nicht rechtfertigt. Zur Thematik des Vendor-Lock-In komme ich am Ende ausführlicher zu sprechen. Ein Serverless-Architektur Ansatz wäre für NextCloud ebenfalls weniger geeignet, da dieser vor allem für kurzlebige Funktionen konzipiert ist. Für Anwendungen wie die unsere, die einen kontinuierlichen Betrieb mit persistentem Zustand erfordern, entstehen dabei erhebliche Nachteile – insbesondere durch Cold Starts.
Um Herausforderungen der Datenredundanz zu überwinden, mussten die Instanzen bzw. NextCloud “zustandslos” gestaltet werden und wir benötigten ausgelagerte Speichermöglichkeiten. Die Wahl des passenden Speichers gestaltete sich als schwieriger als zunächst Angenommen. Natürlich gäbe es auch die Möglichkeit einen Storage-Service ausserhalb von AWS zu wählen. Dies hätte allerdings die Umsetzung für uns lediglich erschwert, ohne nennenswerte Vorteile mit sich zu bringen. Wenn man nicht über die nötige Erfahrung mit den von AWS angebotenen Storage-Services verfügt, wirkt das Angebot schnell überwältigend. Hierbei hat uns vor allem der Guide [1] aus der AWS Dokumentation sehr geholfen. Für die Verwaltung der Metadaten wie der Nutzeraccounts ist eine relationale Datenbank wie der Amazon Relational Database Service (RDS) am geeignetsten. Für die Ablage der verschiedenen Dateien der Nutzer (wie Bilder, Videos, Dokumente, etc.) standen verschiedene Speicherlösungen zur Auswahl – wie ObjectStore, FileStorage oder BlockStorage. Amazon S3 als ObjectStore verwaltet Dateien als URL-adressierte Objekte. Die Vorteile liegen in der nahezu unbegrenzten Skalierbarkeit, hohen Verfügbarkeit und den vergleichsweise günstigen Kosten. FileStorage bietet zwar intuitive Dateisystemzugriffe, stößt aber bei hoher Last schnell an Grenzen. BlockStorage ermöglicht präzise Dateiadressierung, erfordert jedoch mehr Verwaltungsaufwand und ist weniger flexibel in der Skalierung. In Anbetracht unserer gesetzten Ziele sowie der geringeren Kosten, haben wir uns daher für S3 als zweiten Storage entschieden. [2]
Den Zugriff zwischen den EC2 Instanzen und unseren Datenbanken haben wir durch IAM-Rollen und Security Groups in privaten Subnetzen kontrolliert (Näheres hierzu im Abschnitt Implementierung). Letztlich stellt die finale Architektur für uns eine ausgewogene Lösung dar, die die Vorteile einer hohen Verfügbarkeit, flexiblen Skalierbarkeit, konsistenter Performance und robusten Sicherheit bietet und zudem den Raum für zukünftige Erweiterungen – wie zusätzliche Containerisierung – ermöglicht.
Implementierung

Dieser Abschnitt beschreibt die schrittweise Umsetzung und dokumentiert dabei unsere Erfahrungen im Laufe des Projekts.
Network & DNS
Um Nutzern einen zentralen Zugang zu unserer Anwendung zu ermöglichen, haben wir in einem ersten Schritt eine eigene Domain registriert. Über den AWS eigenen Service Route53 war dies problemlos möglich. Um den Datenverkehr abzusichern haben wir den AWS Certificate Manager genutzt, um SSL/TLS-Zertifikate für unsere Domain zu beantragen. Voraussetzung dafür war, dass wir einerseits eine “Hostet-Zone” erstellen und andererseits einen “CNAME-Record” erstellen, um zu validieren, dass uns die Domain gehört. Aufgrund der sensiblen Daten die unsere Anwendung verwaltet empfiehlt es sich sie von anderen, potenziell unsicheren Netzwerken zu trennen. Hierfür nutzen wir eine virtuelle private Cloud (VPC) als isoliertes Netzwerk innerhalb von AWS. VPC ermöglicht es uns beispielsweise die EC2-Instanzen, in privaten Subnets zu betrieben, wodurch sie nicht direkt aus dem Internet erreichbar sind. Dadurch können wir das Risiko vor unbefugtem Zugriffe erheblich reduzieren.
Load Balancing & Scaleability
Um nicht nur den eingehenden Traffic effizient zu verteilen, sondern auch bei variierenden Lasten flexibel horizontal skalieren zu können, kamen der Application Load Balancer (ALB) und die Auto Scaling Group (ASG) zum Einsatz.
Bei der Konfiguration des ALB half uns die Dokumentation von AWS erneut sehr bei der initialen Einrichtung weiter. Bei der Netzwerkzuordnung haben wir drei Availability-Zones für unsere Zone ausgewählt um die Fehlertoleranz unserer Anwendung zu erhöhen. Anschließend müssen Listener konfiguriert werden, die den Eingehenden Traffic an den Ports entgegennehmen. Hierfür haben wir einen Listener für Port 433 erstellt, der eingehende HTTPS-Anfragen entgegennimmt. Hierbei ist es essentiell dem Listener das beantragte Zertifikat aus dem ACM zu hinterlegen. Unserer Unerfahrenheit geschuldet schlugen aufgrund dessen, auf für uns unerklärliche weiße, die Health Checks dauerhaft fehl. Erst nachdem wir alle anderen Fehlerquellen, von der Serverkonfiguration bis hin zu etwaigen Health-Check Anpassungen, ausgeschlossen haben, sind wir auf die eigentliche Ursache aufmerksam geworden. Die Target Group wurde so eingerichtet, dass sie den eingehenden Traffic zu unseren EC2 Instanzen weiterleitet. Zusätzlich überprüfen regelmäßige Health-Checks, ob der Server erreichbar ist. Durch die Healh-Checks kann der Load-Balancer erkennen, wann er Traffic von “ungesunden”-Instanzen zu den verbleibenden “gesunden”-Instanzen umleiten muss.
Parallel dazu ergänzt die Auto-Scaling-Group den Load Balancer, indem sie bei Ausfallen einer Instanz, diese abschaltet und automatisch zusätzliche EC2-Instanzen startet. Wir haben zusätzlich noch weitere Skalierungsmetriken wie eine durchschnittliche CPU-Auslastung von 50% hinterlegt.
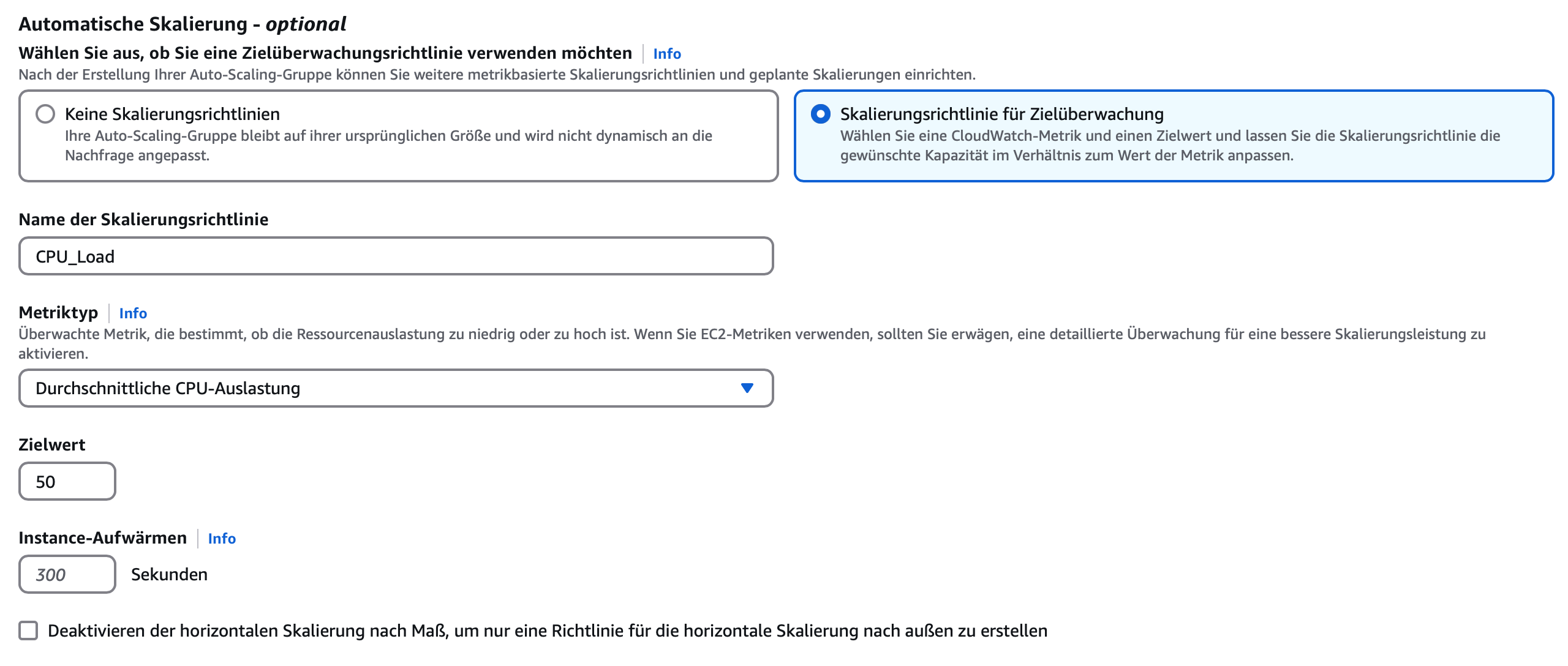
Weitere notwendige Konfigurationen der ASG, neben der Scaling Policy waren zum Einen das private VPC auszuwählen in dem die Instanzen laufen sollen, sowie die ASG mit dem bestehenden ALB zu verbinden. Des Weiteren haben wir für unsern Testzweck eine gewünschte Mindestanzahl gleichzeitig betriebener Instanzen von 1 gewählt und ein Maximum von 2 festgelegt, um bei Konfigurationsfehler keine zu hohen Kosten zu erzeugen. Im produktiven Umfeld würden wir diese Zahl natürlich entsprechend anpassen. Zudem muss die ASG bei der Erstellung mit unserem bestehenden ALB und dessen Zustandsüberprüfungen verknüpft werden.
Damit die Auto Scaling Group (ASG) auch EC2 Instanzen starten kann, die über die NextCloud Konfiguration verfügen, wie wir sie benötigen, mussten wir eine Vorlage von einer bestehenden EC2-Instanz erstellen. Zunächst haben wir uns für den Ansatz eines “Launch Templates” entschieden. Hierbei lassen sich alle notwendigen Parameter für neue Instanzen – etwa Instance Type, Security Groups, Key-Pair, User-Data-Skripte usw. – in einem Template festlegen. Es zeigte sich , dass Launch Templates sich bei Bedarf auch später noch anpassen lassen, ohne einen komplett neues Template erzeugen zu müssen. Allerdings haben wir auch festgestellt, dass die Nutzung eines Launch Templates allein nicht immer eine vollständige Replikation des Zustands unserer Instanz gewährleistet. Daher sind wir dazu über gegangen einen Amazon Machine Image (AMI) von unserer initial konfigurierten Instanz zu erstellen. Ein AMI bietet den entscheidenden Vorteil, dass es den exakten Zustand der Instanz – inklusive aller installierter Anwendungen und individuellen Einstellungen – kapselt. Dadurch besitzen alle neuen Instanzen, die aus diesem AMI gestartet werden, exakt die gleiche Konfiguration wie unsere ursprüngliche NextCloud-Instanz. Zwar ist die Erstellung eines AMI etwas weniger flexibel als die Nutzung eines reinen Launch Templates, da Anpassungen nachträglich schwieriger vorzunehmen sind, aber eine vollständige Replikation unserer Instanz war für uns zwingend erforderlich.
Compute-Resources
1. Erstellung der EC2-Instanz
Aufgrund unseres horizontalen Skalierungsansatzes ist es ausreichend eine t2.micro – Instanz als Server zu wählen. Da NextCloud als Anwendung vergleichsweise weniger ressourcenintensiv ist und bei steigender Last durch die ASG weitere Instanzen dazu geschaltet werden können, können bei wenig Traffic auf unsere Anwendung so kosten minimiert werden. Die Sicherheitsgruppe wurde so konfiguriert, dass sie nur die nötigen Ports (SSH, HTTPS) freigibt. Zudem haben wir die Instanz in unsere VPC integriert und in einem privaten Subnet platziert, um die Sicherheit zu erhöhen. Dadurch wird der direkte Zugriff aus dem Internet verhindert, während der Load Balancer – der in einem öffentlichen Subnet betrieben wird – den externen Traffic entgegennimmt und über interne, private Verbindungen an die Instanz weiterleitet.
2. Konfiguration des Servers
Nach dem erfolgreichen Start der Instanz erfolgte der Zugang per SSH. Aufgrund der Tatsache, dass wir die Daten in Datenbanken ausserhalb der EC2 Instanz auslagern, konnten wir nicht auf den standardisierten und gut dokumentierten Installationsprozess von NextCloud zurückgreifen. Stattdessen mussten wir uns etliche Forumsbeiträge durchforsten und letztendlich eine individuelle Lösung erstellen. Hierbei war es notwendig den Webserver Apache sowie PHP manuell zu installieren. Als Client benötigten wir MariaDB um die spätere Datenbankanbindung an RDS zu realisieren.
3. Installation von NextCloud
Anschließend wurde NextCloud heruntergeladen und entpackt. Das ownership wurden auf www-data:www-data angepasst, damit Apache auf die Dateien zugreifen kann. An dieser Stelle bereiteten wir auch die grundlegenden Konfigurationsdateien vor, führten aber den Web-Installer noch nicht aus. Schon hier stießen wir auf die erste Hürde, denn NextCloud ist standardmäßig auf einen Single-Server-Betrieb ausgelegt. Für den späteren Einsatz in einer horizontal skalierbaren Umgebung mussten wir sicherstellen, dass die Instanz zustandslos arbeitet und alle persistente Daten ausgelagert werden. Näheres hierzu haben wir im Abschnitt Storage dokumentiert.
4. Konfiguration des Apache Virtual Host
Parallel richteten wir einen Apache Virtual Host ein, der unseren Domain-Namen verarbeitet. Dazu bearbeiteten wir die Konfigurationsdatei in /etc/apache2/sites-available/NextCloud.conf in dem wir den ServerName eintrugen. Nachdem die Konfiguration aktiviert und Apache neu gestartet wurde, überprüften wir, ob die Seite korrekt ausgeliefert wird.
5. Einrichtung des SSL-Zertifikats
Da ein verschlüsselter Zugriff für unsere Anwendung essenziell ist, installierten wir Certbot und führten anschließend sudo certbot --apache -d *unseredomain*. Der Befehl ruft Certbot auf und nutzt das Apache-Plugin, um ein SSL/TLS-Zertifikat für unsere Domain von Let’s Encrypt zu beantragen. Dabei wird automatisch geprüft, ob die Domain korrekt konfiguriert ist, und anschließend die Apache-Konfiguration so angepasst, dass der Webserver HTTPS-Verbindungen unterstützt. Allerdings stießen wir hier zunächst auf Validierungsprobleme, weshalb wir die DNS-Konfiguration in Route53 nochmals überprüfen mussten.
6. DNS-Konfiguration
In AWS Route 53 richteten wir schließlich einen A-Record unsere Domain ein, der auf unserer Instanz zeigt. Nach einer kurzen Wartezeit war die Domain erreichbar und zeigte auf unsere konfigurierte EC2-Instanz.
7. Finalisierung der NextCloud-Installation
Zum Abschluss mussten wir noch einen NextCloud Administrationsaccount hinzufügen und unsere Domain als “vertrauenswürdige Domain” hinterlegen. Anschließend konnte NextCloud über unsere Domain abgerufen werden und eine Anmeldung als Admin war möglich. Über die Einstellungen in der NextCloud Admin Oberfläche konnten wir, unter Installation eines AddIns, die Freigabe neuer Nutzer, die sich über die Startseite registrieren, verwalten. Allerdings sind die Daten zu diesem Zeitpunkt noch immer auf der EC2 Instanz.

Storage
Um den Herausforderungen der Datenredundanz bei horizontal skalierter Infrastruktur zu begegnen, haben wir uns dazu entschlossen, die Metadaten sowie Dateien der Nutzer ausserhalb der EC2-Instanzen auszulagern. Hierbei viel die Wahl auf einerseits Amazon S3 sowie Amazon RDS.
1. Einrichtung eines S3-Buckets
Der erste Schritt bestand darin, einen neuen Bucket zu erstellen – in unserem Fall in der Region eu-central-1. Um im Falle versehentlicher Löschvorgänge oder Änderungen auf frühere Versionen zurückgreifen können, haben wir Versionierung aktiviert. Darüber hinaus haben wir den Bucket in unsere private VPC integriert, um eine gesicherte Verbindung zu gewährleisten.
2. Erstellung einer RDS-Instanz
Parallel haben wir in der AWS RDS-Konsole eine Datenbank-Instanz aufgesetzt. Hier haben wir uns für MariaDB entschieden. Wir wählten db.t4g.micro als Instanzklasse, um einen guten Kompromiss zwischen Performance und Kosten zu erzielen. Die Sicherheitsgruppe der RDS-Instanz wurde so konfiguriert, dass sie den Zugriff auf Port 3306 ausschließlich aus der Sicherheitsgruppe der EC2-Instanzen erlaubt.
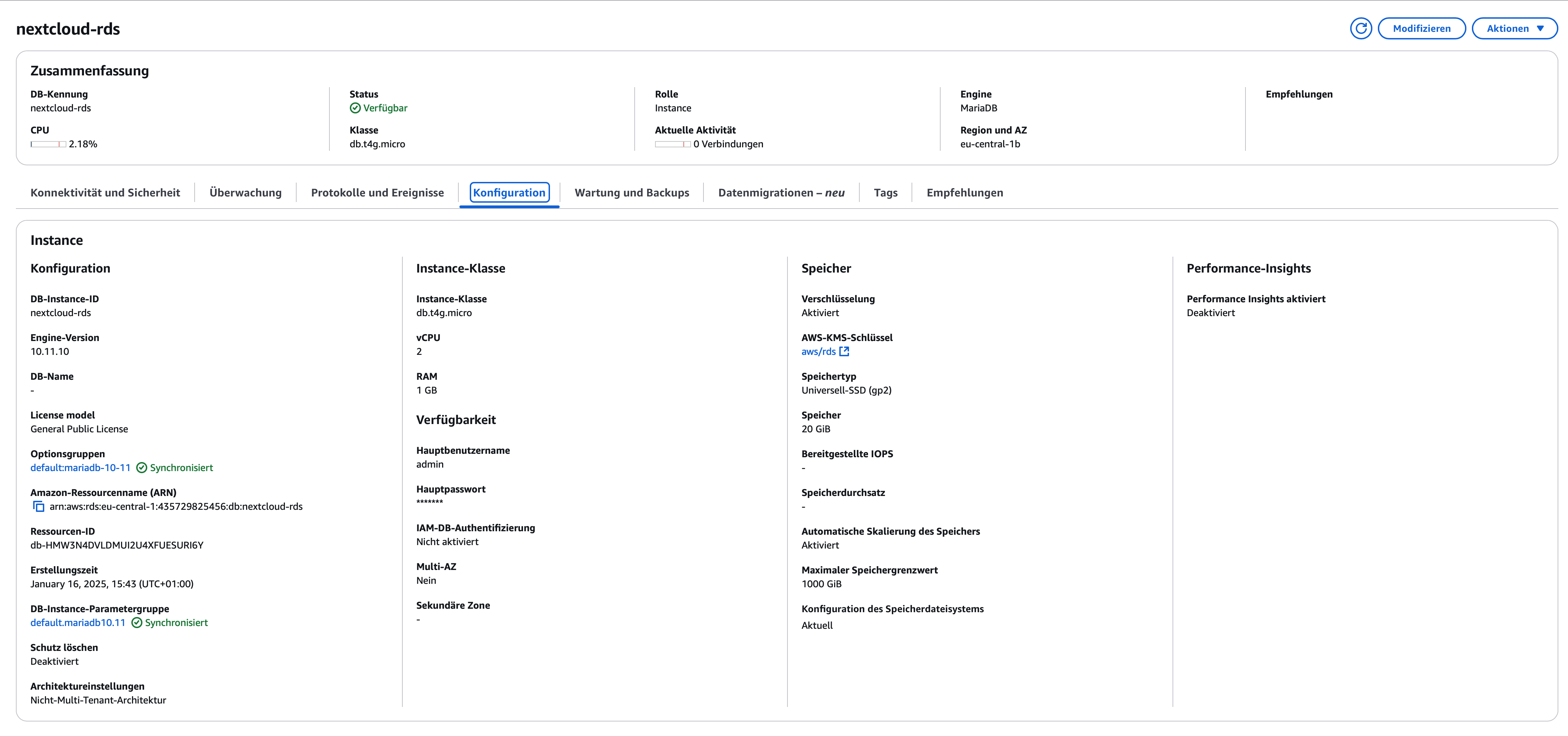
3. Zuweisung von IAM Rollen
Ein weiterer entscheidender Schritt in unserer Storage-Implementierung war die Erstellung und Zuweisung der erforderlichen IAM-Rollen, die den Zugriff unserer EC2-Instanzen auf den S3-Bucket und RDS steuern. Zunächst haben wir in der AWS IAM-Konsole eine neue Rolle definiert und spezifische Policies wie die Berechtigungen s3:GetObject, s3:PutObject, s3:DeleteObject sowie die Verbindung zu unserer RDS-Datenbank über rds:Connect zugewiesen.
Anschließend haben wir diese IAM-Rolle unseren EC2-Instanzen zugewiesen – entweder direkt über die Instance-Konfiguration oder mittels eines Launch Templates, das als Vorlage für die Auto Scaling Group dient. Auf diese Weise wird NextCloud beim Start automatisch über die IAM-Rolle authentifiziert, ohne dass AWS-Schlüssel manuell in der config.php hinterlegt werden müssen. Dieser Ansatz minimiert das Risiko von Schlüsselkompromittierungen und ermöglicht eine zentrale, flexible Verwaltung der Zugriffsrechte.
3. Konfiguration der NextCloud-Instanz
Um die Kommunikation zwischen NextCloud mit dem S3 zu ermöglichen, installierten wir notwendige PHP-Bibliotheken, wie php-curl. In der NextCloud-Konfigurationsdatei config.phpergänzten wir dann ein objectstore-Array, in dem wir Region, Bucket-Namen und weitere Parameter unseres S3 eintrugen. Der Zugriff auf S3 wurde über eine IAM-Rolle konfiguriert – die gegenüber einer direkten Eingabe der AWS-Schlüsseln zusätzliche Sicherheit bietet. Die Implementierung dieses Schrittes war besonders herausfordernd für uns, da NextCloud nicht für die Auslagerung des Speichers angedacht ist. Viele Anpassungen waren notwendig, bis sowohl die Dateien als auch die Nutzerdaten konsistent zwischen mehreren Instanzen genutzt werden konnten.
'objectstore' => [
'class' => 'OC\\\\Files\\\\ObjectStore\\\\S3',
'arguments' => [
'bucket' => '*Bucket-Name*',
'autocreate' => false,
'region' => 'eu-central-1',
'hostname' => 's3.eu-central-1.amazonaws.com',
'use_ssl' => true,
'use_path_style' => false,
],
],Um zuletzt noch RDS in NextCloud einzubinden, konnten wir im Installationsprozess von NextCloud bei den Datenbank Einstellungen, die RDS Daten hinterlegen: dbhost=<RDS-endpoint> dbname=NextCloud_db . Somit nutze NextCloud automatisch unsere RDS als Ablageort für alle Nutzerdaten. Um unser Ziel einer durchgängigen Verfügbarkeit zu erreichen, haben wir zusätzlich die RDS als Multi-AZ deployed. Dabei werden automatisch synchrone Replikate der Datenbank in unseren drei Verfügbarkeitszonen erstellt. Sollte die primäre Instanz ausfallen, übernimmt das System automatisch eines der Replikate, ohne dass manuelles Eingreifen erforderlich ist.
Monitoring & Logging
Um den Zustand unserer NextCloud-Anwendung kontinuierlich zu überwachen und bei Bedarf reagieren zu können, haben wir AWS CloudWatch sowie Health Checks integriert.
CloudWatch Logs & Metrics
CloudWatch haben wir so konfiguriert, dass es die für uns entscheidenden Systemmetriken CPU und RAM-Auslastung unserer EC2-Instanzen sowie den verfügbaren Speicherplatz in unseren S3-Buckets überwacht. Die Konfiguration erfolgte direkt über die AWS Management Console, wobei wir die Alarme mit einem S3-Bucket verknüpft haben, um alle Ereignisse zu dokumentieren.
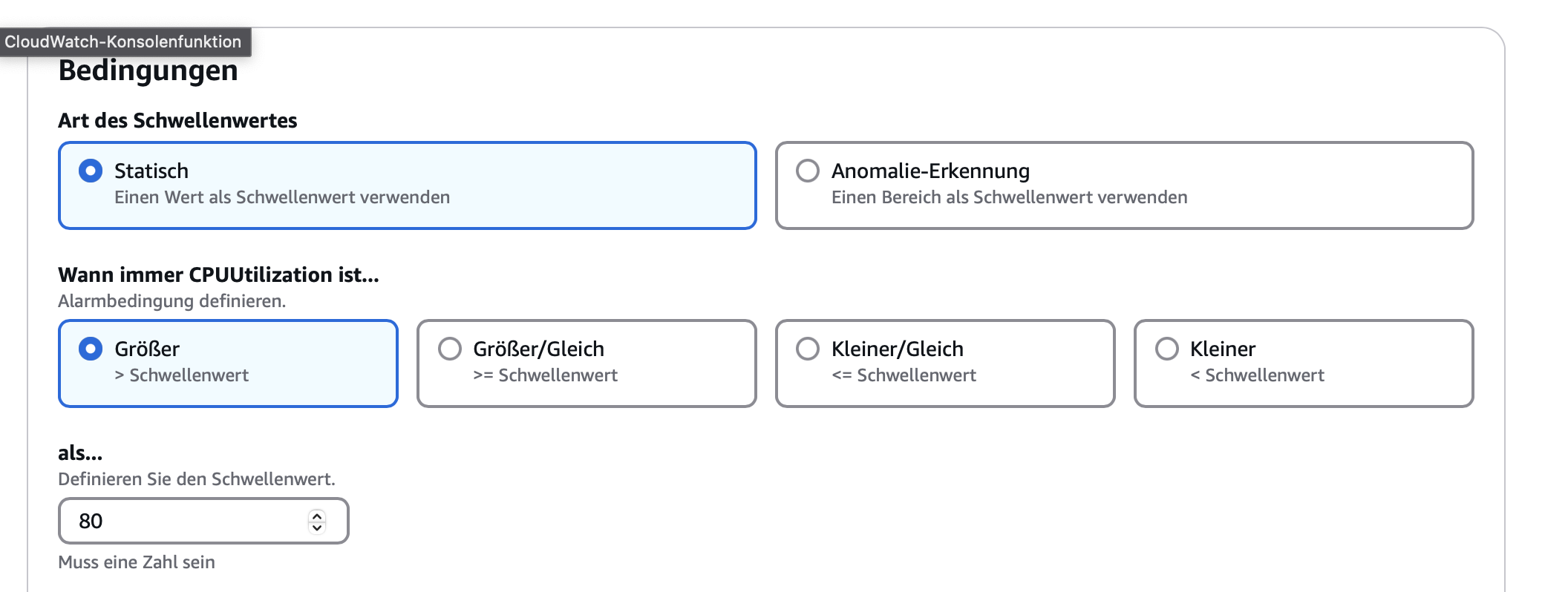
Die für uns relevanten Metriken sind dabei:
- EC2 CPU-Auslastung > 80% für 10 Minuten
- S3-Bucket Memory-Auslastung > 80%
- RDS Free-Storage < 1GB
Health Checks
Parallel dazu setzten wir Health Checks ein, um die Netzwerkauslastung und die allgemeine Instanz-Gesundheit zu überwachen. Diese Health Checks spielen eine zentrale Rolle, da sie den Application Load Balancer (ALB) dazu befähigen, den Traffic nur an „gesunde“ Instanzen weiterzuleiten. Anfänglich hatten wir jedoch erhebliche Schwierigkeiten: Die Health Checks schlugen konstant fehl, was dazu führte, dass die ASG die als unhealthy gekennzeichnete Instanz ständig abschaltete und eine neue startete. Nach intensiver Fehlersuche entdeckten wir, dass das Problem in der DNS-Konfiguration lag. Erst als wir ein zusätzliches A-Record für unsere Subdomain und eine extra statische html Seite hinzufügten, funktionierten die Health-Checks wie erwartet.
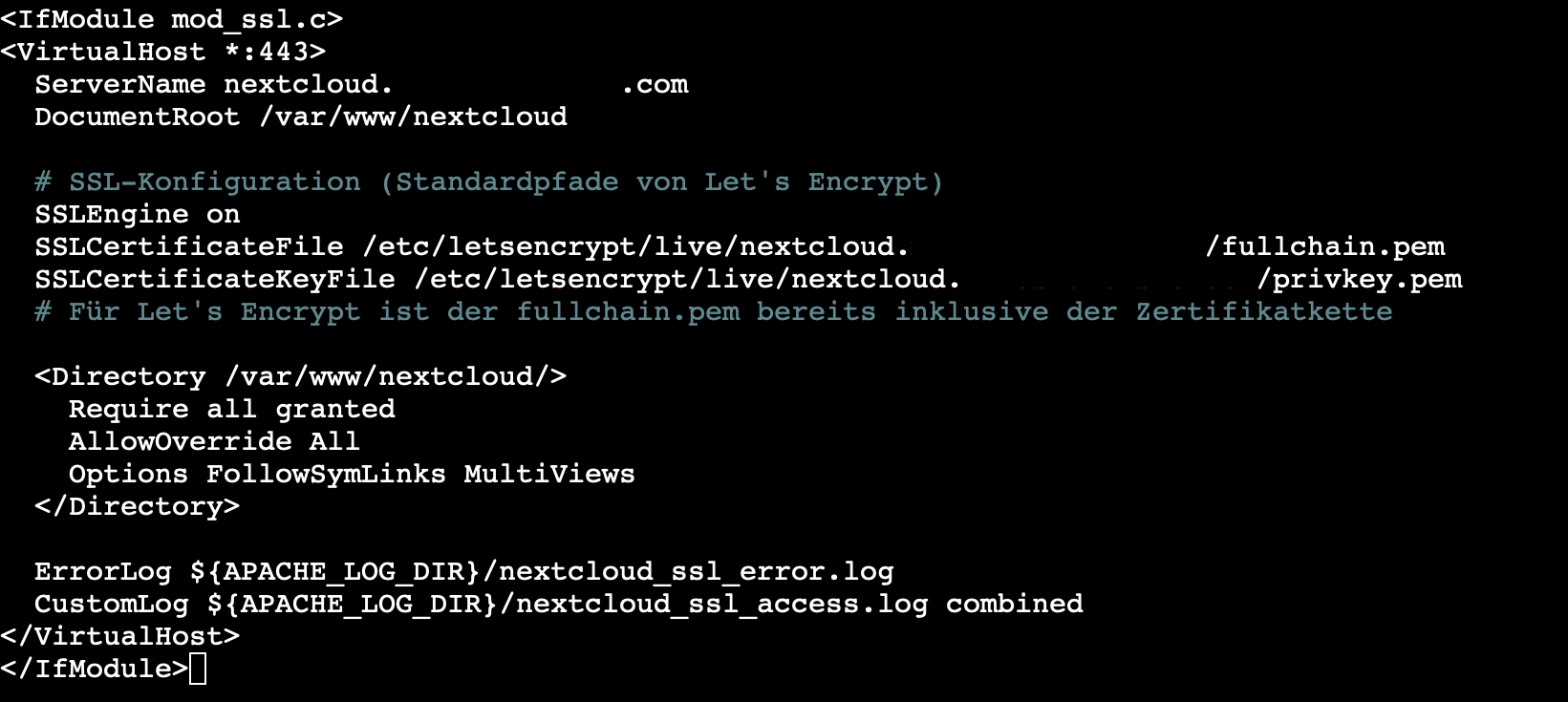
Evaluation
Anbieter Vergleich
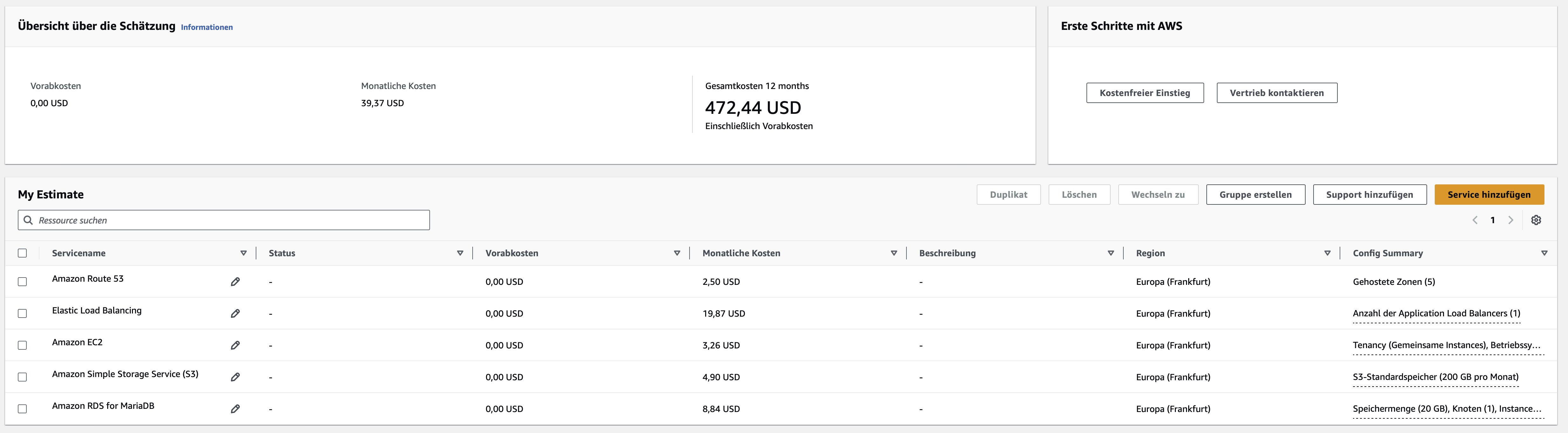
Die Grafik zeigt die monatlichen und jährlichen Kosten unserer Anwendung. Für eine einzelne Person wäre diese Lösung sowohl zu teuer als auch zu over-engineered – hier hätte eine einzelne EC2-Instanz ausgereicht. Bei mehreren Nutzern sinken jedoch die Kosten pro Person deutlich: bei fünf Nutzern auf 12$/Monat und bei 100 Nutzern sogar auf 6,30$/Monat. Wie die nachfolgende Tabelle zeigt, ist es nicht ohne weiteres möglich eine kostengünstigere Alternative zu den etablierten Cloud Anbietern wie iCloud oder Google Drive anzubieten. Die NextCloud Hosting Plattform tab.digital konnten wir preislich jedoch unterbieten.
| Provider | Storage | Costs / mth. |
|---|---|---|
| Apple iCloud | 200GB | $3.49 |
| Google Drive | 200GB | $4.00 |
| tab.digital | 265GB | $11.64 |
| Unsere Anwendung [5 Nutzer] | 200GB | $12.00 |
| Unsere Anwendung [100 Nutzer] | 200GB | $6.30 |
Eine weitere Motivation zu Beginn bestand darin, dem Vendor-Lock-in zu entkommen, dem man durch Cloud-Dienste von Apple, Google oder Microsoft ausgesetzt ist. Leider mussten wir feststellen, dass wir durch unsere Umsetzung mit AWS das Problem lediglich verschoben hatten. Zwar sind die Kosten im AWS-Kosmos überschaubar und die Integration der Services ist hoch, jedoch steigt die Komplexität deutlich, sobald man externe Anbieter integrieren möchte. Eine Möglichkeit, dies zumindest teilweise zu minimieren, wäre die Nutzung von Infrastructure-as-Code-Tools wie Terraform. Damit könnten Teile der Infrastruktur portabel zwischen verschiedenen Cloud-Anbietern gewechselt werden. Da sich jedoch sowohl die Abstraktion als auch der initiale Aufwand zur Erstellung erhöht, lag dieser Ansatz außerhalb unseres Zielbereichs für dieses Semester.
Ziel abgleich
Im Abgleich mit unseren zu Beginn definierten Ziele, hat sich gezeigt, dass wir mit dem Stand unserer Anwendung alle unsere definierten Ziele erreichen konnten, auch wenn selbstverständlich noch weiterer Raum für Verbesserungen und alternative Ansätze besteht.
Verfügbarkeit
✅ Die Architektur sollte prinzipiell eine Verfügbarkeit von 99,9% unterstützen.
Performanz
✅ Die Time-to-First-Byte (TTFB) für die Benutzeroberfläche soll unter 200 ms liegen.
Sicherheit
✅ Nur verschlüsselter Zugriff (HTTPS) auf die Anwendung.
✅ Nutzer können sich registrieren, werden jedoch erst nach einer manuellen Bestätigung durch einen Administrator für den Zugriff freigegeben.
Skalierbarkeit
✅ Die Anwendung soll konzipiert sein, dass sie keine Performanceeinbußen bei steigenden Nutzerzahlen hat.
Lessons Learned
Unser Projekt hat uns wertvolle Erkenntnisse vermittelt, die weit über die technische Umsetzung hinausgehen. Besonders deutlich wurde, dass eine gründliche Planung und klare Zieldefinition von entscheidender Bedeutung sind. Zu Beginn hatten wir noch wenig Vorstellung davon, wohin das Projekt letztlich führen sollte – was vor allem an unserer Unerfahrenheit im Umgang mit Cloud-Diensten geschuldet war. Das regelmäßige Feedback während des Semesters half uns jedoch dabei schrittweise unserer Lösung näher zu kommen.
Vor diesem Projekt hatten wir beide noch nicht wirklich mit AWS gearbeitet, und es war für uns daher äußerst wertvoll, einen Einblick in einen kleinen Teil der verfügbaren Dienste zu erhalten. Diese Erfahrung hat uns eine solide Grundlage und ein besseres Verständnis vermittelt, auf dem wir in zukünftigen Projekten aufbauen können.
Ein weiteres großes Learning war das Thema Skalierung. Der Aufbau einer skalierbaren Anwendung brachte viele Herausforderungen mit sich – von der Umstrukturierung der Datenbank bis hin zur Integration von skalierbaren Services wie Auto Scaling Groups und Load Balancern. Dabei haben wir schmerzhaft erfahren, welche Konsequenzen es hat, wenn man Skalierung nicht von Anfang an ausreichend berücksichtigt wird.
Auch wenn sich die Konfiguration von NextCloud als komplizierter als zunächst vermutet herausgestellt hat, sind wir dennoch zufrieden mit unserer Entscheidung auf eine Open-Source Lösung gesetzt zu haben, da wir dadurch die meiste Kapazität in die Infrastruktur legen konnten und weniger auf die reine Software-Entwicklung.
Somit stellte für uns dieses Projekt den idealen Anwendungsfall dar, um praxisnah viele für uns relevante Konzepte des System Engineerings kennenzulernen und ein solides Fundament für zukünftige Projekte in diesem Bereich zu bilden.
Leave a Reply
You must be logged in to post a comment.