Note: This blog post was written for the module Enterprise IT (113601a) in the summer semester of 2025
Introduction
Kubernetes has become the leading open-source platform for managing containerized applications. Its ability to automate deployment, scaling, and operations helps teams efficiently manage microservices architectures and dynamic cloud workloads.
A cornerstone of efficient Kubernetes cluster management is auto-scaling, a mechanism that dynamically adjusts resources to meet fluctuating application demands, thereby ensuring optimal performance, maximizing resource utilization, and controlling operational costs. While Kubernetes offers built-in auto-scaling capabilities through tools like the Horizontal Pod Autoscaler (HPA) and the Vertical Pod Autoscaler (VPA), these traditional methods often rely on reactive measures and predefined thresholds. These approaches, while effective for many scenarios, can fall short in handling the dynamic and often unpredictable nature of contemporary workloads.
Artificial Intelligence is now stepping in to revolutionize this landscape, offering a more intelligent and efficient way to manage Kubernetes cluster scaling. AI’s capacity to analyze vast amounts of data, learn from patterns, and make proactive decisions is transforming how Kubernetes clusters adapt to changing demands, leading toward a future of more autonomous and optimized cloud-native operations. This article looks at the limitations of traditional Kubernetes auto-scaling and explains how AI is enabling more autonomous and optimized cloud-native operations.
Foundations of Kubernetes Auto-Scaling Mechanisms
To fully grasp Kubernetes’ auto-scaling capabilities, it’s essential to first understand the foundational components that form its backbone: Containers, Pods, Nodes, and Clusters.
- Containers: These are standardized, executable software packages that bundle an application with all its dependencies, ensuring consistent execution across various environments. Each container is designed to be stateless and immutable, promoting repeatable deployments by decoupling applications from the underlying host infrastructure. [1]
- Pods: The smallest deployable unit in Kubernetes, a Pod represents a single instance of a running process in your cluster. A Pod encapsulates one or more Containers, along with shared storage resources, a unique network IP, and options that govern how its containers run. All containers within a Pod share the same network namespace and can communicate with each other easily. [2]
- Nodes: These are the worker machines (either virtual or physical) in a Kubernetes cluster where Pods are actually run. Each Node is managed by the Kubernetes control plane and contains the necessary services, like kubelet, a container runtime, and kube-proxy, to facilitate container execution and network communication for its Pods. [3]
- Clusters: A Kubernetes Cluster is a complete system that manages containerized applications. It consists of a set of Nodes (which run your Pods) and a control plane. The control plane acts as the brain of the cluster, coordinating all activities such as scheduling Pods, maintaining the desired application states, and managing scaling, all to ensure high availability and fault tolerance of your applications. [4]
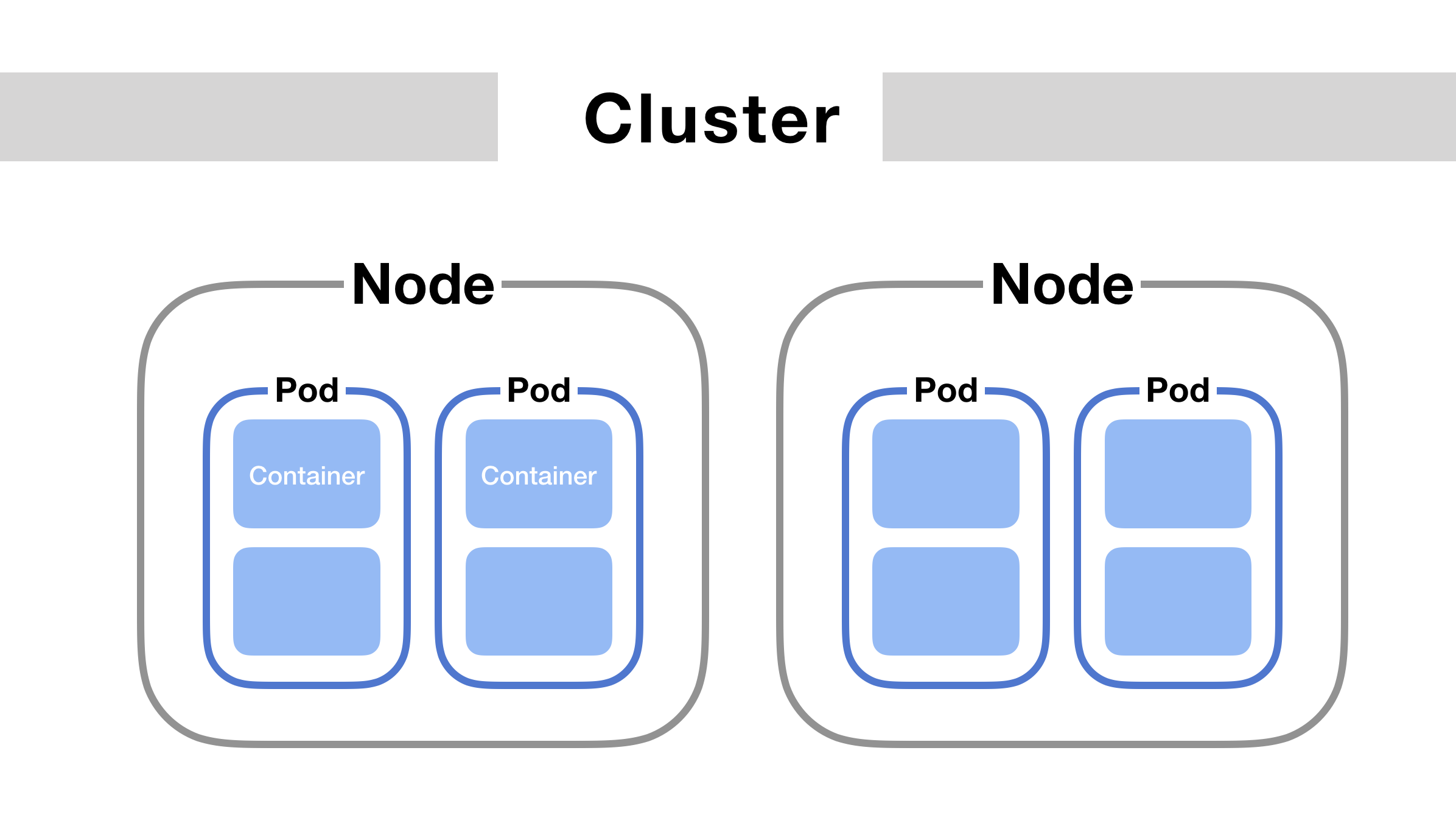
Overview of Kubernetes Auto-Scaling Mechanisms
With these foundational components in mind, we can now explore Kubernetes’ built-in mechanisms for automating the scaling of applications and infrastructure. These mechanisms ensure that applications can dynamically adjust to varying workloads, optimizing resource utilization and maintaining performance.
- Horizontal Pod Autoscaler (HPA) – scales the number of pod replicas in a workload. [5]
- Vertical Pod Autoscaler (VPA) – adjusts the CPU/memory requests of containers (changing pod resource allocations). [6]
- Cluster Autoscaler (CA) – adds or removes nodes in the cluster itself. [6]
Each of these mechanisms operates through a rule-based control loop that continuously monitors relevant metrics and makes scaling decisions reactively.
Horizontal Pod Autoscaler (HPA): Scaling by Replicas
The Horizontal Pod Autoscaler (HPA) is a core Kubernetes feature that automatically adjusts the number of pod replicas for a given workload to match demand [5].
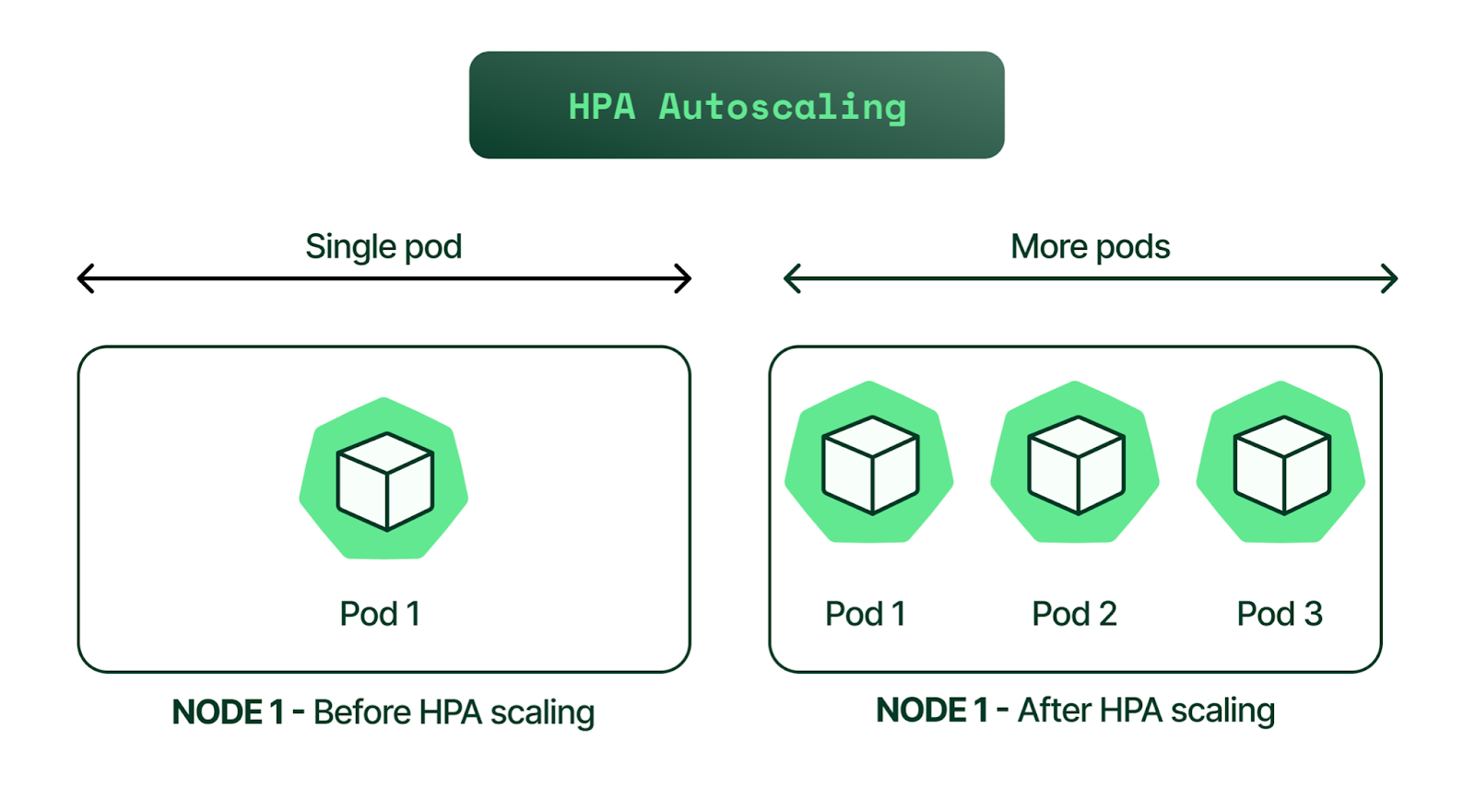
HPA scales based on observed metrics such as average CPU utilization, average memory usage, or custom metrics [5]. The HPA controller operates in a control loop, periodically querying metrics and comparing them to target values to determine the desired number of replicas [5]. The calculation for the desired number of replicas is as follows:

For example, if the current average CPU utilization across all pods is 200m, the target is set at 100m, and there are currently 2 replicas, the HPA computes:
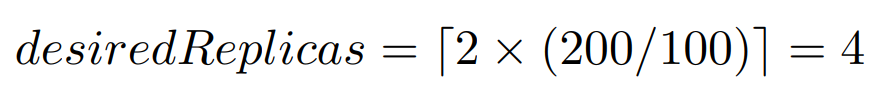
This results in the HPA doubling the number of pods to meet the target. This calculation is performed at regular intervals (defaulting to every 15 seconds). [5]
Vertical Pod Autoscaler (VPA): Scaling by Resources
The Vertical Pod Autoscaler (VPA) takes a different approach to scaling by automatically adjusting resource requests (minimum guaranteed resources) and limits (maximum allowed resources) for containers. Instead of changing the number of replicas like HPA, VPA focuses on optimizing the resource allocation of existing pods to improve workload efficiency. [8]
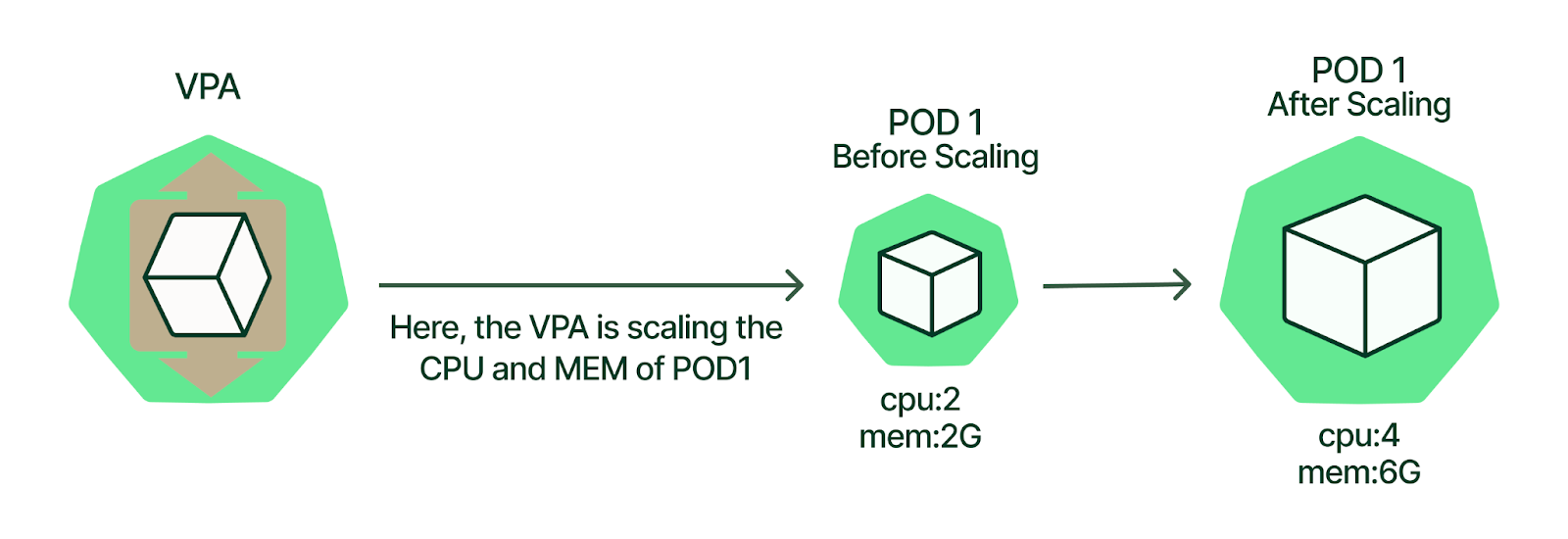
VPA operates through three main components: the Recommender (which analyzes resource usage and generates recommendations), the Admission Controller (which applies resource settings to new pods), and the Updater (which evicts pods to apply new resource configurations when needed). The system can operate in different modes, ranging from recommendation-only to fully automated resource management. VPA manages resource requests and limits for containers by analyzing historical usage data and Out-Of-Memory events to determine optimal resource allocations. [8]
Cluster Autoscaler (CA): Scaling the Infrastructure
The Cluster Autoscaler (CA) operates at the cluster level, automatically adjusting the number of nodes based on pod scheduling requirements. Unlike HPA and VPA, which work at the pod level, CA monitors for pods in a pending state rather than directly measuring resource utilization, checking every 10 seconds by default to detect when pods cannot be scheduled due to insufficient cluster capacity. [9, 10]
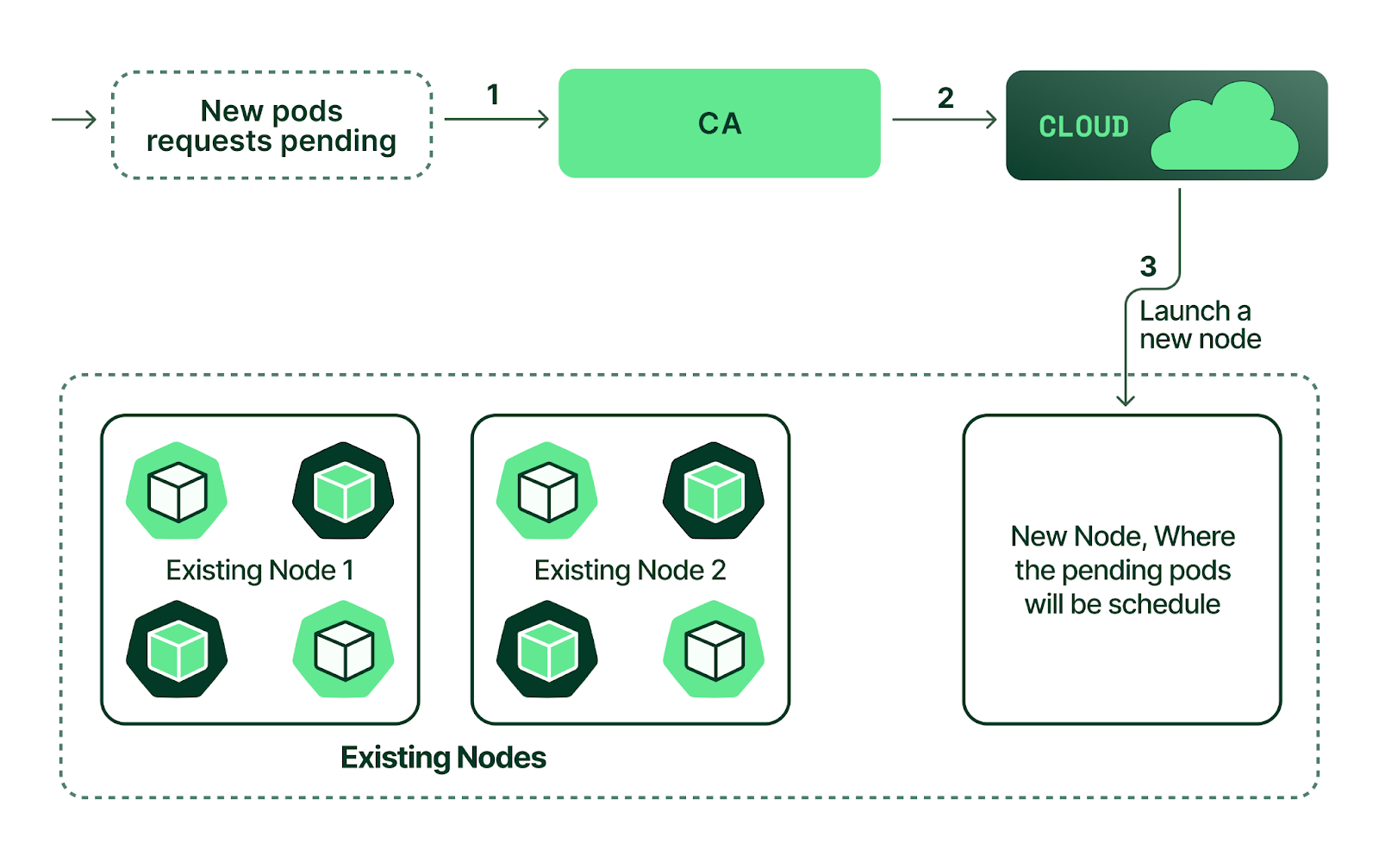
As illustrated in Figure 4, the scaling process follows a systematic workflow: CA detects pending pods that cannot be scheduled (1), communicates with the cloud provider infrastructure to provision additional capacity (2), and triggers the launch of a new node (3). The newly provisioned node is then registered with the Kubernetes control plane, making it available for scheduling the previously pending pods. [9]
Limitations of Traditional Autoscaling: Reactive Design
Traditional autoscaling mechanisms in Kubernetes, like the Horizontal Pod Autoscaler (HPA), Vertical Pod Autoscaler (VPA), and Cluster Autoscaler (CA), operate reactively, initiating scaling actions only after a change in demand is detected [11]. This reactive approach inherently involves a delay between the moment a demand spike occurs and when the autoscalers actually respond and adjust resources [12]. This delay can result in periods of over-utilization (too many resources) or under-utilization (insufficient resources) before the system can adapt [12, 11]. Under-utilization leads to application slowdowns or failures due to a lack of resources and over-utilization to wasted resources and increased costs [12].
The Horizontal Pod Autoscaler (HPA) evaluates metrics like CPU or memory usage at fixed intervals, typically every 15 seconds [5], introducing latency between demand changes and scaling. The Vertical Pod Autoscaler (VPA) applies resource adjustments by restarting pods [13], which temporarily disrupts availability. Similarly, the Cluster Autoscaler (CA) requires time to provision and integrate new nodes, delaying capacity expansion.
From Reactive to Proactive: The Case for AI-Driven Autoscaling
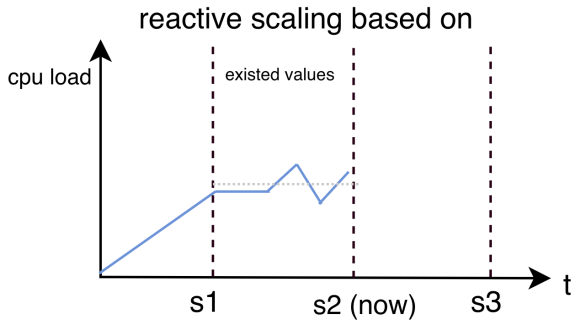
To address the shortcomings of traditional scaling mechanisms, modern infrastructures increasingly turn to proactive autoscaling. Unlike reactive scaling, which acts only after a load increase has been observed, proactive AI-based strategies predict upcoming demand and prepare resources in advance [11].
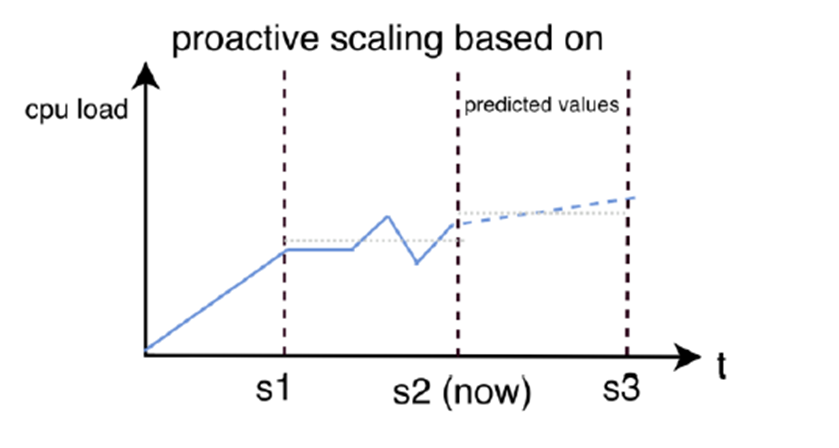
Figure 6 illustrates the concept of proactive scaling: instead of waiting for CPU usage to increase, the system uses predicted values beyond the current time point (s2) to adjust resources ahead of time. This eliminates the drawbacks of reactive scaling by enabling timely resource adjustments, thereby preventing latency issues and performance degradation before they occur. To achieve such proactive capabilities, various AI models are employed, which we will outline in the subsequent section.
AI Models for Predictive Auto-Scaling
As established, the transition from reactive to proactive auto-scaling in Kubernetes fundamentally relies on the ability to accurately forecast future resource demands. This predictive capability is achieved through the application of various Machine Learning models, which can analyze historical workload data to identify patterns and anticipate future needs.
In this section, we explore key AI model architectures commonly employed for predictive auto-scaling in Kubernetes environments, beginning with foundational time series approaches and progressing to more complex deep learning techniques.
Time Series Models
Time series models like ARIMA (AutoRegressive Integrated Moving Average) can be used to predict future workload, as they are widely used for time series forecasting [14]. These models focus on decomposing time series data into key components [15]:
- Trends: Capturing long-term increases or decreases in resource utilization.
- Seasonalities: Modeling regular, predictable cycles such as daily, weekly, or monthly patterns.
- Cyclical Patterns: Accounting for irregular, non-fixed cycles that may occur due to workload changes or business cycles.
Their relative simplicity and interpretability [15] have made them popular for many years in time series forecasting [14].
However, these models are primarily linear, which can limit their ability to capture complex, non-linear relationships [15] or sudden workload changes often seen in dynamic Kubernetes environments [16].
Neural Networks and Deep Learning
For more complex and non-linear patterns that traditional time series models might miss [15], Neural Networks (NN) and especially Deep Learning (DL) models come into play. These advanced algorithms can process vast amounts of data and learn intricate relationships, making them highly suitable for predictive auto-scaling.
Here are the primary AI model architectures commonly used for this purpose:
- Long Short-Term Memory (LSTM): This special recurrent neural network (RNN) [17] is perfectly suited for time-series forecasting. They can learn long-term dependencies [15] from historical Kubernetes workload data, making them ideal for predicting future resource needs.
- Multilayer Perceptrons (MLP): These fundamental feedforward networks are effective when predictions rely heavily on current or cross-sectional features (e.g., immediate CPU utilization, time of day, current active connections). They can model complex relationships between various input metrics gathered from your Kubernetes cluster.
- Convolutional Neural Networks (CNNs) (specifically 1D-CNNs): While known for image processing and feature extraction, 1D-CNNs can efficiently identify local patterns within time series data. However, their forecasting accuracy tends to be relatively low compared to other models such as LSTM and Arima, as shown in a study, where CNNs performed worse in bitcoin price prediction compared to LSTM and traditional econometric methods [18].
- Ensemble Methods: Since no single forecasting model performs best in all situations, combining models like LSTM, MLP, and CNN can improve prediction accuracy. Each model captures different aspects of the data, and their combination increases the chances of identifying relevant patterns [15]. This makes ensemble approaches more robust, especially in complex and dynamic environments such as Kubernetes workloads.
The choice of the best architecture for your Kubernetes environment depends heavily on the specific workload patterns and available data. LSTMs are often preferred for deep temporal dependencies, MLPs excel with rich feature sets, and CNNs are great for pattern detection. However, ensemble methods generally offer improved overall performance and reliability for proactive scaling decisions.
Benefits of AI-Based Scaling for Kubernetes Environments
Having explored the diverse AI models applicable to predictive auto-scaling, we now turn our attention to the substantial advantages they deliver. The integration of AI into Kubernetes auto-scaling brings a multitude of benefits, leading to more efficient, reliable, and cost-effective cloud-native operations, which we’ll explain in the following sections.
Cost Optimization
Traditional scaling methods often lead to either over-provisioning or under-provisioning [11]. Both scenarios are costly for businesses, resulting in wasted resources or lost revenue due to service degradation [11]. In today’s fast-paced digital environment, even brief downtime or slow responses are increasingly intolerable, potentially leading to substantial financial losses [11].
AI-driven auto-scaling can significantly reduce cloud infrastructure costs by accurately predicting resource needs. This approach can help prevent both over-provisioning during low demand and under-provisioning during peak loads. Techniques like intelligent rightsizing of containers, based on actual usage, can contribute to substantial savings [19].
Beyond basic rightsizing, AI technologies can also optimize the use of discounted computing options offered by major cloud providers like AWS, Azure, and Google Cloud. For instance, AI models can predict when spot instances (unused capacity) are likely to be available and when they might be interrupted. This foresight can help organizations plan their resource allocation to minimize service disruption, potentially allowing them to confidently use these highly cost-effective instances. Similarly, for reserved instances (long-term commitments), AI can analyze historical usage patterns. Based on this data, it can recommend the optimal number and type of reserved instances to purchase, aiming to ensure businesses commit to the right amount of resources and maximize savings by avoiding over-provisioning [19].
Many companies offering AI-based autoscaling for Kubernetes highlight these potential cost benefits. For example, StormForge promotes savings of up to 65% with its machine learning-driven rightsizing [20], and Sedai.io reports 30-50% cost reductions through AI-powered optimization [21]. Furthermore, research and case studies also suggest that AI-based autoscaling can lead to significant cost reductions [22, 23, 24]. These considerable promises underscore AI-based autoscaling’s immense potential for substantial cloud cost optimization.
Improved Performance
AI-powered predictive scaling can significantly boost the performance of cloud environments by proactively adjusting resources based on forecasted workload demands. This is especially advantageous in Kubernetes, where scaling operations, like spinning up new pods or provisioning additional nodes, can introduce noticeable delays during sudden traffic spikes. Factors like metric collection intervals, scaling thresholds, and new infrastructure startup times contribute to these lags [12]. Consequently, workloads might temporarily experience performance degradation or underutilization before the system fully adapts [12].
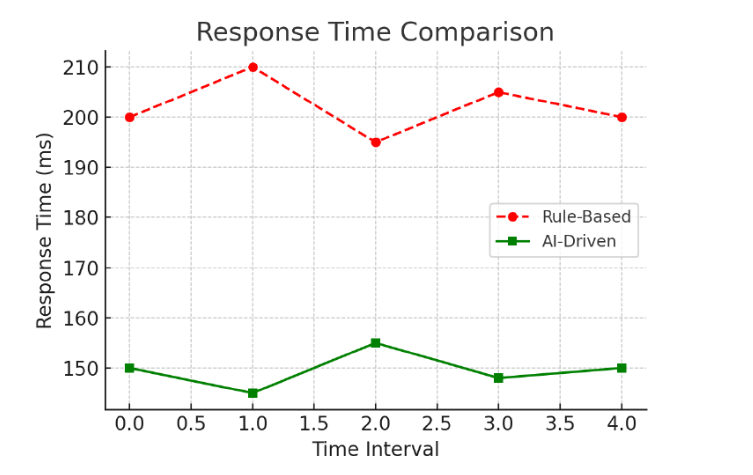
Predictive scaling directly addresses this by provisioning resources ahead of time, ensuring adequate capacity is available precisely when required. This leads to more consistent responsiveness [11]. Experimental results have shown that AI-driven autoscaling can enhance application response times by up to 25% compared to traditional rule-based methods [24].
Enhanced Resource Utilization
AI-based autoscaling offers considerable advantages in optimizing resource utilization by making more intelligent and context-aware scaling decisions. Traditional approaches like the Horizontal Pod Autoscaler (HPA) rely primarily on standard metrics such as CPU and memory usage by default [5]. While these metrics provide a basic indication of system load, they often fail to capture the complexity of real-world workloads. As a result, scaling actions may occur too late or be misaligned with actual resource needs, leading to overprovisioning or underutilization, especially in scenarios where custom metrics are not configured or utilized.
Although HPA can be extended to use custom metrics [5], doing so typically requires considerable manual effort to define, collect, and integrate relevant metrics into the scaling logic. This process can be time-consuming and brittle, especially in dynamic or complex environments. In contrast, AI-driven autoscaling can automatically learn patterns from a broad set of input signals—including CPU, memory, network traffic, disk I/O, latency, request throughput, and even application-specific parameters, without requiring extensive manual configuration.
For example, an AI-based approach might autonomously identify that scaling should occur based on queue length, response times, or the number of active user sessions, factors that may be critical for performance but are ignored by default in traditional setups. By continuously adapting to evolving workloads and learning from historical data, AI-driven systems can provide more timely and accurate scaling decisions with less manual intervention.
This intelligent, adaptive capacity directly translates into tangible improvements in efficiency. Experimental results have shown that AI-driven autoscaling can reduce resource wastage by up to 30% compared to traditional rule-based techniques [24].
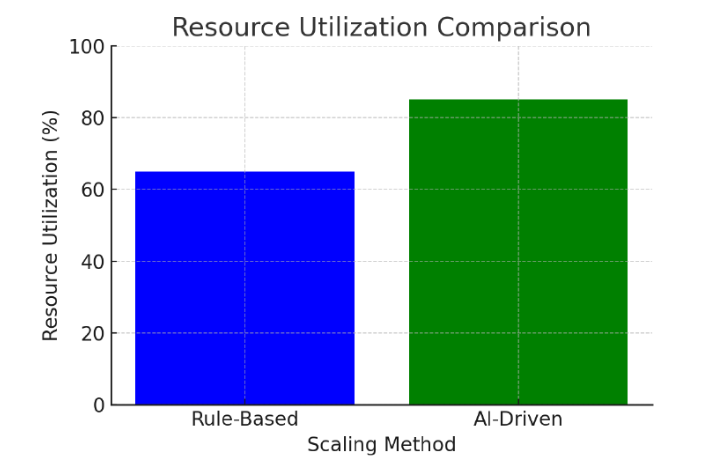
While the benefits of AI-driven autoscaling are substantial, its implementation is not without its own set of challenges and important considerations.
Challenges and Considerations for AI-Driven Auto-Scaling
While AI-driven auto-scaling offers significant advantages, its adoption also presents certain challenges and considerations that organizations need to address.
Implementation and Integration Complexities
Integrating AI-based auto-scaling into existing cloud infrastructure presents challenges, particularly in environments with legacy systems. This process necessitates not only deep technical expertise but also a comprehensive understanding of both the current infrastructure and the proposed AI capabilities.
The implementation of predictive scaling usually involves substantial changes to existing resource management procedures. This could be technically challenging and expensive. Furthermore, implementing AI-based auto-scaling and associated monitoring solutions takes manpower and time for IT departments, reflecting large upfront investments and the need for specialized skill. These inherent complexities are especially burdensome to small and medium-sized enterprises. [11]
Data Requirements and Quality
AI-driven predictive scaling heavily relies on accurate and comprehensive historical and real-time data. Poor data quality, such as noise, inconsistencies, or gaps, can undermine prediction accuracy and lead to inefficient resource allocation. Therefore, ensuring data reliability and addressing any shortcomings in data collection are essential for effective scaling. While cloud environments generate vast amounts of data, preparing this information for AI use remains challenging as it requires careful cleaning, labeling, and filtering to ensure relevance. Moreover, limited access to diverse real-world datasets can make it difficult to train and evaluate AI-based algorithms robustly, impacting their overall performance. [11]
Stability and Predictability
As AI models become part of cloud systems, continuous monitoring and regular updates are essential to maintain their accuracy and effectiveness under changing conditions. This helps ensure stable and predictable scaling behavior, which is critical for reliable system performance. [11]
Computational Overhead
Running AI and machine learning models for auto-scaling can introduce significant computational overhead. This added load may offset some of the expected efficiency gains [11]. Therefore, the overhead must be carefully considered as part of the overall cost-benefit analysis when adopting AI-powered auto-scaling solutions.
Despite these challenges, a structured approach is essential for successfully implementing AI-driven autoscaling; a conceptual framework for this process is outlined next.
Conceptual Framework for AI-Driven Auto-Scaling in Kubernetes
Implementing AI-driven autoscaling in Kubernetes requires an architecture that collects data, analyzes it with machine learning models, and translates predictions into scaling actions. In the following, it will be outlined how AI-driven autoscaling in Kubernetes could be implemented.
Step 1: Data Collection and Preprocessing
To enable intelligent autoscaling, relevant metrics must be collected from the Kubernetes environment. These could include CPU and memory usage, request and error rates, latency, and application-specific indicators. Tools like Prometheus can be used to collect and store time-series data from the Kubernetes cluster [25]. The collected data should be preprocessed, cleaned, normalized, and transformed to create consistent and useful input for model training.
Step 2: Model Training and Target Definition
The AI model can be trained to predict different kinds of targets, depending on the chosen scaling strategy:
- Workload Forecasting: The model predicts workload indicators such as CPU demand or request volume. These predictions can then inform scaling decisions by existing autoscaling mechanisms in Kubernetes.
- Direct Scaling Output: Alternatively, the model can be trained to output a desired scaling state directly, for example, the number of pods or nodes required under future conditions.
For model selection, various approaches can be utilized depending on the use case. The different models that could be used were already outlined before.
Step 3: Model Deployment
Once trained, the AI models need to be deployed for real-time inference. This can be achieved in several ways:
- In-Cluster Deployment: Deploy models as containerized services within the Kubernetes cluster using tools like TensorFlow Serving [26].
- External Deployment: Host models on external platforms (cloud ML services, dedicated inference servers) that communicate with the cluster via APIs.
The deployment choice depends on latency requirements, resource constraints, and security considerations.
Step 4: Scaling Execution and Kubernetes Integration
Depending on the model output, different execution paths are required to apply scaling decisions within the Kubernetes environment. If the AI model forecasts workload metrics—such as future CPU usage or incoming request rates—these predictions can be fed into existing Kubernetes autoscalers by making them available through a custom metrics API. For example, a tool like KEDA (Kubernetes Event-Driven Autoscaler) can be used to expose these predicted values as custom metrics, which Kubernetes’ Horizontal Pod Autoscaler (HPA) can then consume to make real-time scaling decisions [27]. Alternatively, if the model directly outputs target scaling values such as the desired number of pod replicas, a custom service or controller can be implemented that reads these predictions and applies them to the Kubernetes API by updating the replica count of deployments.
Step 5: Continuous Inference and Feedback Loop
Once integrated, predictive autoscaling operates as a continuous loop. The model consumes up-to-date metrics, generates forecasts (e.g., CPU demand or target replicas), and triggers scaling actions.
The impact of each scaling action feeds back into the metrics pipeline, allowing the model to adapt to workload changes over time. As patterns evolve, periodic retraining with recent data ensures prediction quality remains high, enabling a self-correcting and adaptive autoscaling system.
Conclusion and Outlook
AI is fundamentally transforming Kubernetes auto-scaling, shifting it from a reactive, threshold-based approach to a proactive, predictive, and adaptive approach. This shift brings significant benefits, including cost optimization through efficient resource utilization, improvements in application performance, and availability. The importance of AI-based scaling in Kubernetes is rapidly growing, with many companies actively developing and deploying solutions that leverage these advanced capabilities. For instance, commercial solutions like StormForge [28], Wave Autoscale [29], and Dysnix PredictKube [30] are already utilizing machine learning to offer intelligent resource optimization. While adopting AI for Kubernetes auto-scaling presents challenges related to increased complexity, significant data requirements for training, and the need for specialized expertise, the potential rewards are immense and lay the groundwork for truly autonomous Kubernetes operations.
References
[1] Containers. Kubernetes. url: https://kubernetes.io/docs/concepts/containers/ (visited on 05/25/2025).
[2] Pods. Kubernetes. url: https://kubernetes.io/docs/concepts/workloads/pods/ (visited on 05/25/2025).
[3] Nodes. Kubernetes. url: https://kubernetes.io/docs/concepts/architecture/nodes/ (visited on 05/25/2025).
[4] Cluster Architecture. Kubernetes. url: https://kubernetes.io/docs/concepts/architecture/ (visited on 05/25/2025).
[5] Horizontal Pod Autoscaling. Kubernetes. url: https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/ (visited on 05/25/2025).
[6] Autoscaler/README.Md at Master · Kubernetes/Autoscaler. url: https://github.com/kubernetes/autoscaler/blob/master/README.md (visited on 05/25/2025).
[7] Chapter 2: Horizontal Autoscaling – Kubernetes Guides – Apptio. Apr. 16, url: https://www.apptio.com/topics/kubernetes/autoscaling/horizontal/ (visited on 07/22/2025).
[8] Chapter 1: Vertical Autoscaling – Kubernetes Guides – Apptio. Apr. 16, url: https://www.apptio.com/topics/kubernetes/autoscaling/vertical/ (visited on 07/22/2025).
[9] Chapter 3: Cluster Autoscaling – Kubernetes Guides – Apptio. Apr. 16, url: https://www.apptio.com/topics/kubernetes/autoscaling/cluster/ (visited on 07/22/2025).
[10] Autoscaler/Cluster-Autoscaler/README.Md at Master · Kubernetes/Autoscaler. GitHub. url: https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/README.md (visited on 07/22/2025).
[11] Pranav Murthy. “AI-Powered Predictive Scaling in Cloud Computing: Enhancing Efficiency through Real-Time Workload Forecasting”. In: Iconic Research And Engineering Journals 5.4 (Nov. 2021). issn: 2456-8880.
[12] Raymond Ajax, Ayuns Luz, and Crystal Herry. “Autoscaling in Kubernetes: Horizontal Pod Autoscaling and Cluster Autoscaling”.
[13] Vertical Pod Autoscaling — Google Kubernetes Engine (GKE) — Google Cloud. url: https://cloud.google.com/kubernetes-engine/docs/concepts/verticalpodautoscaler (visited on 05/25/2025).
[14] Sima Siami Namini, Neda Tavakoli, and Akbar Siami Namin. “A Comparison of ARIMA and LSTM in Forecasting Time Series”. doi: 10.1109/ICMLA.2018.00227.
[15] Vaia Kontopoulou et al. “A Review of ARIMA vs. Machine Learning Approaches for Time Series Forecasting in Data Driven Networks”. In: Future Internet 15 (July 2023). doi: 10.3390/fi15080255.
[16] Charan Shankar Kummarapurugu. “AI-Driven Predictive Scaling for Multi-Cloud Resource Management: Using Adaptive Forecasting, Cost-Optimization, and Auto-Tuning Algorithms”. In: International Journal of Science and Research (IJSR) 13 (Oct. 2024). doi: 10.21275/SR241015062841.
[17] Sepp Hochreiter and Jürgen Schmidhuber. “Long Short-Term Memory”. In: Neural Computation 9 (Nov. 1997).
[18] Dinh-Thuan Nguyen and Huu-Vinh Le. “Predicting the Price of Bitcoin Using Hybrid ARIMA and Machine Learning”. In: Nov. 2019, isbn: 978-3-030-35652-1. doi: 10.1007/978-3-030-35653-8_49.
[19] Lawrence Emma. “AI-POWERED CLOUD RESOURCE MANAGEMENT: MACHINE LEARNING FOR DYNAMIC AUTOSCALING AND COST OPTIMIZATION”.
[20] Kubernetes Cost Optimization. stormforge.io. url: https://stormforge.io/solution-brief/kubernetes-cost-optimization/ (visited on 05/31/2025).
[21] Autonomous Cloud Cost Optimization for Modern Apps — Reduce Costs by 30-50%. url: https://www.sedai.io/use-cases/cloud-cost-optimization (visited on 05/31/2025).
[22] Charan Shankar Kummarapurugu. “AI-Driven Predictive Scaling for Multi-Cloud Resource Management: Using Adaptive Forecasting, Cost-Optimization, and Auto-Tuning Algorithms”. In: International Journal of Science and Research (IJSR) 13.10 (Oct. 2024). issn: 23197064. doi: 10.21275/SR241015062841. (Visited on 05/31/2025).
[23] Ravi Pulle, Gaurav Anand, and Satish Kumar. “Monitoring Performance Computing Environments And Autoscaling Using AI”. In: International Research Journal of Modernization in Engineering Technology and Science 5.5 (2023).
[24] Shraddha Gajjar. AI-Driven Auto-Scaling in Cloud Environments. Feb. 2025. doi: 10.13140/RG.2.2.12666.61125.
[25] Overview — Prometheus. url: https://prometheus.io/docs/introduction/overview/ (visited on 06/01/2025).
[26] TensorFlow Serving with Docker — TFX. url: https://www.tensorflow.org/tfx/serving/docker (visited on 06/01/2025).
[27] KEDA — KEDA Concepts. KEDA. url: https://keda.sh/docs/2.17/concepts/ (visited on 07/22/2025).
[28] Introducing Intelligent Bi-dimensional Autoscaling. stormforge.io. url: https://stormforge.io/blog/introducing-intelligent-bi-dimensional-autoscaling/ (visited on 07/22/2025).
[29] Stclab Inc. Introduction – Wave Autoscale. Feb. 12, 2025. url: https://waveautoscale.com/docs/introduction (visited on 07/22/2025).
[30] KEDA — Introducing PredictKube – an AI-based Predictive Autoscaler for KEDA Made by Dysnix. KEDA. url: https://keda.sh/blog/2022-02-09-predictkube-scaler/ (visited on 07/22/2025).
List of Figures
Figure 1: Source: Kubernetes Networking Guide for Beginners – Kubernetes Book. https://matthewpalmer.net/kubernetes-app-developer/articles/kubernetes-networking-guide-beginners.html (accessed 2025-07-23).
Figure 2: Source: Chapter 2: Horizontal Autoscaling – Kubernetes Guides – Apptio. Apr. 16, url: https://www.apptio.com/topics/kubernetes/autoscaling/horizontal/ (visited on 07/22/2025).
Figure 3: Source: Chapter 1: Vertical Autoscaling – Kubernetes Guides – Apptio. Apr. 16, url: https://www.apptio.com/topics/kubernetes/autoscaling/vertical/ (visited on 07/22/2025).
Figure 4: Source: Chapter 3: Cluster Autoscaling – Kubernetes Guides – Apptio. Apr. 16, url: https://www.apptio.com/topics/kubernetes/autoscaling/cluster/ (visited on 07/22/2025).
Figure 5: Source: Гутман, Д & Сирота, O.. (2023). Проактивне автоматичне масштабування вверх для Kuberneters. Адаптивні системи автоматичного управління. 1. 32-38. 10.20535/1560-8956.42.2023.278925.
Figure 6: Source: Гутман, Д & Сирота, O.. (2023). Проактивне автоматичне масштабування вверх для Kuberneters. Адаптивні системи автоматичного управління. 1. 32-38. 10.20535/1560-8956.42.2023.278925.
Figure 7: Source: Shraddha Gajjar. AI-Driven Auto-Scaling in Cloud Environments. Feb. 2025. doi: 10.13140/RG.2.2.12666.61125
Figure 8: Source: Shraddha Gajjar. AI-Driven Auto-Scaling in Cloud Environments. Feb. 2025. doi: 10.13140/RG.2.2.12666.61125.
Leave a Reply
You must be logged in to post a comment.