Category: Secure Systems
Cybersecurity Breaches
Sicherheitsrisiken im digitalen Zeitalter: Eine Analyse aktueller Cyberangriffe und ihre Implikationen Data Breaches sind eine zunehmende Bedrohung, bei der Hacker und Cyberkriminelle weltweit nach Möglichkeiten suchen, sensible Informationen zu stehlen. Die Motive für solche Angriffe umfassen finanzielle Gewinne, Prestige und Spionage. Laut dem Verizon Report von 2023 machen technische Schwachstellen nur etwa 8% aller Angriffsmethoden…

The Impact of Quantum Computing on Cybersecurity
The future has arrived: Welcome to the second quantum revolution. But what does this mean for Cybersecurity?
Browser Session Hijacking
This article outlines the dangers of insufficiently protected browser session cookies, how they work, how they can be hijacked and what to do to avoid it.
Usability in Code an Overview from IDE to AI
Wenn man über Usability Kontext von IT redet, wird ein integraler Part gerne komplett übersehen: Den Entwickler.Wie soll Usability richtig umgesetzt werden wenn, der der Beides umsetzten, muss von beiden Themen während seiner Arbeit nichts mitbekommt?Warum hört Usability immer dort auf, wo der Entwickler auf sein Handwerkszeug schaut? Die Fragen oben sind natürlich etwas überspitzt,…
- Allgemein, Artificial Intelligence, ChatGPT and Language Models, Ethics of Computer Science, Secure Systems
Brechen der Grenzen: ChatGPT von den Fesseln der Moral befreien
Abb. 1: Hacking-Katze, die dabei ist, ChatGPT zu jailbreaken, Darstellung KI-generiert “Ich würde lügen, würde ich behaupten, dass kein Chatbot bei der Erstellung dieses Blogeintrags psychischen Schaden erlitten hat” – Anonymes Zitat eines*r CSM-Studierenden 1 Einleitung 1.1 Bedeutung des Themas und Relevanz in der heutigen digitalen Welt Seit 2020 das Large Language Model (LLM) GPT-3…
- Cloud Technologies, Design Patterns, Secure Systems, System Architecture, System Designs, System Engineering
High Availability and Reliability in Cloud Computing: Ensuring Seamless Operation Despite the Threat of Black Swan Events
Introduction Nowadays cloud computing has become the backbone of many businesses, offering unparalleled flexibility, scalability and cost-effectiveness. According to O’Reilly’s Cloud Adoption report from 2021, more than 90% of organizations rely on the cloud to run their critical applications and services [1]. High availability and reliability of cloud computing systems has never been more important, as…

Optimierung der Investitionen in Cyber-Security
Vier Millionen und dreihunderttausend Euro – dies ist der durchschnittliche Preis, den deutsche Unternehmen für ein einzelnes Datenleck zahlen müssen. Und dies ist nur der monetäre Schaden. Der Vertrauensverlust der Kunden und der potenzielle Verlust von Geschäftsgeheimnissen können einen bleibenden Schaden verursachen, der weit über die unmittelbaren Kosten hinausgeht. Dies sind die Fakten, die der…

E-Health: Die Lösung für das deutsche Gesundheitssystem?
Willkommen im deutschen Gesundheitswesen, das für seine Effizienz und qualitativ hochwertige Versorgung bekannt ist. In Deutschland basiert die Krankenversicherung auf dem solidarischen Prinzip, bei dem jeder in die Versicherung einzahlt, um im Krankheitsfall abgesichert zu sein. Allerdings gibt es auch Herausforderungen, wie lange Wartezeiten für bestimmte Fachärzte oder die Bewältigung der Bürokratie im Gesundheitssystem. In…
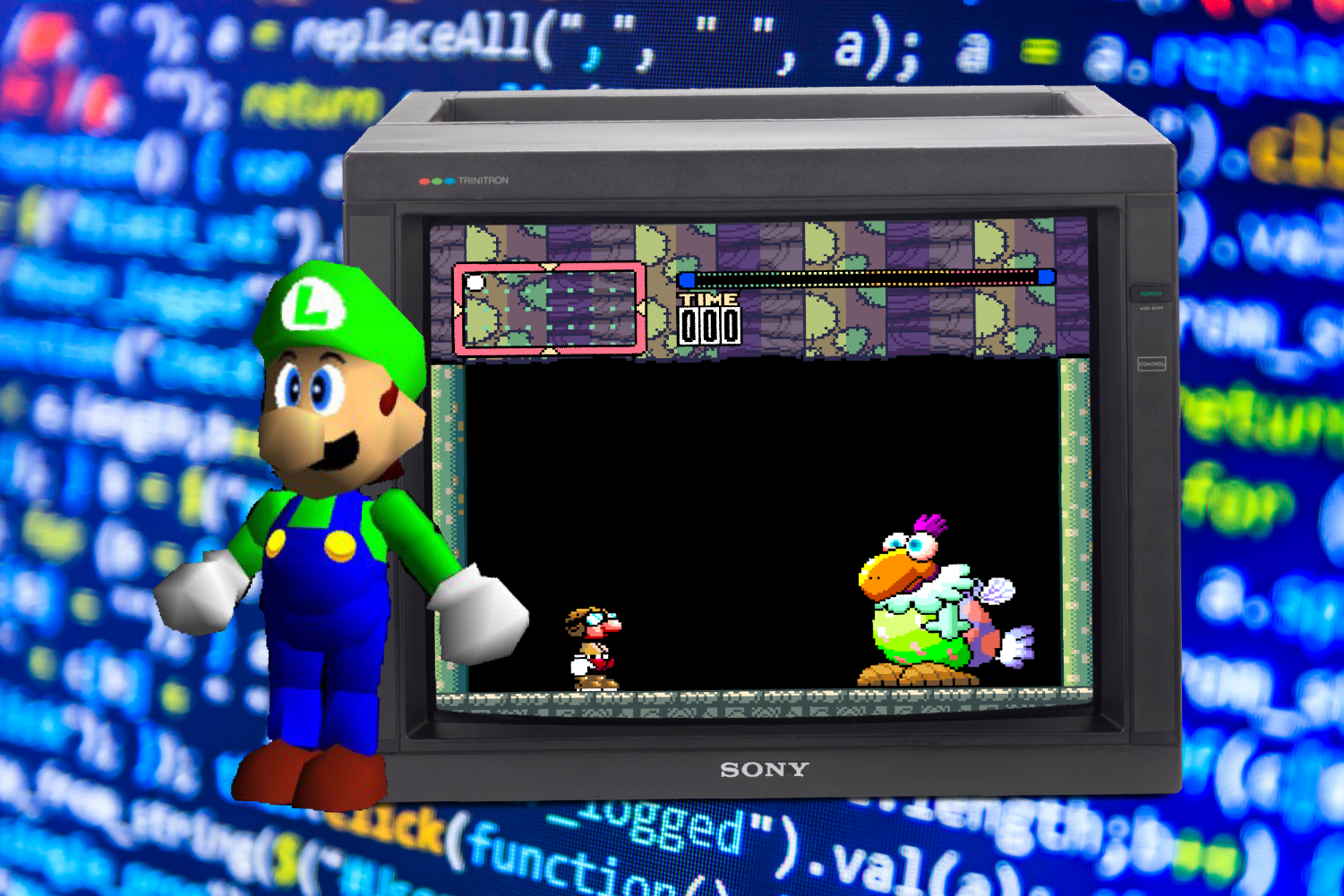
The Nintendo ‘Gigaleak’ Incident
It is not a secret that many big corporations and companies conceal sensitive data and projects from the public. In concern to video game companies, many of these internal game-related projects would never see the light of day even though there had already been a lot of money and time put into them. When these…

Gesichter der Täuschung – Wie Deepfakes unsere Identität bedrohen
Stell dir vor: Deine Tochter ruft dich an – die Stimme klingt zumindest wie deine Tochter, die Schauspielerin Margot Robbie im neuen Barbie-Film trägt statt ihrem dein Gesicht und plötzlich taucht im Internet ein Video auf, das dich bei einer Straftat zeigt – du bist jedoch unschuldig und das Video ist eine perfide Fälschung. Willkommen…