Introduction
Nowadays cloud computing has become the backbone of many businesses, offering unparalleled flexibility, scalability and cost-effectiveness. According to O’Reilly’s Cloud Adoption report from 2021, more than 90% of organizations rely on the cloud to run their critical applications and services [1]. High availability and reliability of cloud computing systems has never been more important, as failure would be catastrophic for organizations that rely on these systems. While many failure scenarios can be predicted and prevented through resilient design and clean code, some cannot. These events are called “black swans” (as opposed to “white swans”, which are far more common and predictable events) and refer to rare and unpredictable events that have severe consequences and can have a significant impact on the reliability and availability of a service [2]. In this blog post, we’ll take a look at the importance of high availability and reliability in cloud computing and approaches to ensuring them, as well as explore how black swans can affect these attributes.
Understanding Black Swan Events in Cloud Computing
A system can fail for various reasons. Even though many known failure scenarios can be addressed through design and code, there are outlier events that are much harder to predict but can still occur. These outlier events are called “black swans”. The term black swan has been popularized by Nassim Taleb as a metaphor for unpredictable events resulting in catastrophic failures, much like the 2008 financial crash. In production systems and infrastructure these incidents trigger problems that result in a break of business continuity and can’t be addressed quickly without the proper preparation. Laura Nolan’s taxonomy classifies black swan events into various categories based on their characteristics and origins.[2] Among these categories are:
Hitting Limits: Hitting limits refers to encountering and reaching the maximum capacity or constraints of a particular component or system such as resource, storage or API call limits that remained unknown until then. [2]
Spreading Slowness: Spreading Slowness describes a situation where slowdowns in one component or service of a system have a cascading impact on other components or services in that system to also experience reduced performance. [2]
Thundering Herds: In the context of computer systems Thundering Herds refer to a sudden or unexpected spike of requests that overwhelm a system leading to performance, increased latency or even service disruptions. [2]
Dependency Loops: A dependency loop forms when a component relies on another, which in turn relies on the first component, creating a circular relationship resulting in a scenario where if one component fails, the other will fail as well. [2]
Cyberattacks: Large scale cyberattacks and data breaches can also be considered black swan events, as they can cause a complete system failure if hackers manage to bypass security protocols and shut down service components. [2]
Considering that outlier events like black swans are impossible to predict, how can systems and infrastructure be designed and built to be highly available and reliable to resist these events and ensure business continuity?
Understanding High Availability in Cloud Computing Systems
In the context of cloud computing high availability (HA) describes the percentage of time that the infrastructure or system is operational under normal circumstances. Designing high availability cloud infrastructure is one of the key factors to ensure continuous operation and uninterrupted access to applications and services. Minimizing downtime and mitigation of service disruptions because of hardware failures, network outages, software issues or even natural disasters or cyber security attacks are key goals of high availability approaches. These approaches focus on one thing: avoiding single points of failure (SPOF) on every layer of a system or solution. [3]
The availability of a component is expressed as a percentage of uptime per year and can be measured using the following formula:
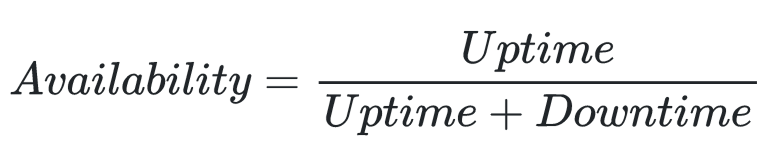
Availability is usually specified as part of a Service Level Agreement (SLA), among other criteria – more on this later. SLAs are contracts between a provider and customers and often allow a certain amount of downtime while promising 99,9% uptime (or “three nines”) for example. Table 1 shows the availability in percent with the allowed downtime for a particular availability percentage. [3]
| Availability in % | Downtime per year | Downtime per month |
| 90% (“one nine”) | 36.53 days | 73.05 hours |
| 99% (“two nines”) | 3.65 days | 7.31 hours |
| 99.9% (“three nines”) | 8.77 hours | 43.83 minutes |
| 99.99% (“four nines”) | 52.60 minutes | 4.38 minutes |
| 99.999% (“five nines”) | 5.26 minutes | 26.30 seconds |
When designing a high availability system or infrastructure there are several components that have to be considered. In the following we’ll take a look at some of these components:
- Redundancy
- Scalability
- Load Balancing
- Automated Failover Mechanisms
Redundancy
In order to avoid single points of failure, redundancy can be used on all system or application layers. Duplicating critical components such as servers, storage and network devices ensures that if one component fails, another takes over seamlessly. The availability of a system with redundant solutions can be calculated using the following formula, where As is the availability of a solution (product of the availability of all used components) and n is the level of redundancy [3]:
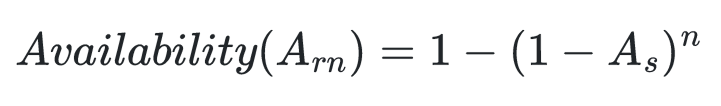
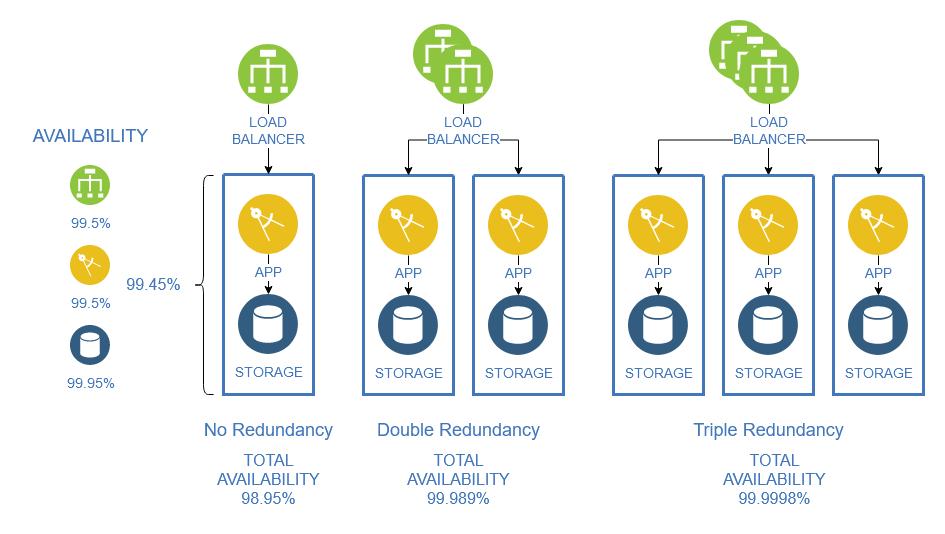
The following example shows how the availability of a solution varies depending on the level of redundancy applied [3]:
Another architectural design approach that goes hand in hand with redundancy is the concept of microservices. Microservices are cloud-native applications which consist of small independent services that can continue working even if individual services fail.
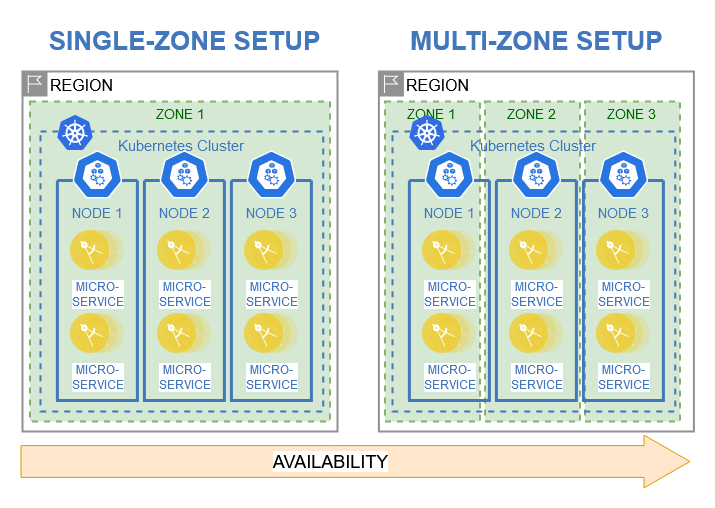
Cloud providers such as IBM Cloud usually offer their cloud services and resources in different geographies all around the world. Each geography offers regions with multiple availability zones, which allows for resources to be distributed across multiple regions and data centers. Cloud architecture patterns for high availability solutions utilize this to create redundant applications across multiple regions. [3] Applying these patterns to a microservice application would result in the following setups:
Single-Zone Setup: Deployment of microservice application with redundant services in a single zone to enable high availability in case of single component failures. [3]
Multi-Zone Setup: Deployment of microservice application with redundant services across multiple zones within a single region to enable high availability in case of single zone failures. [3]
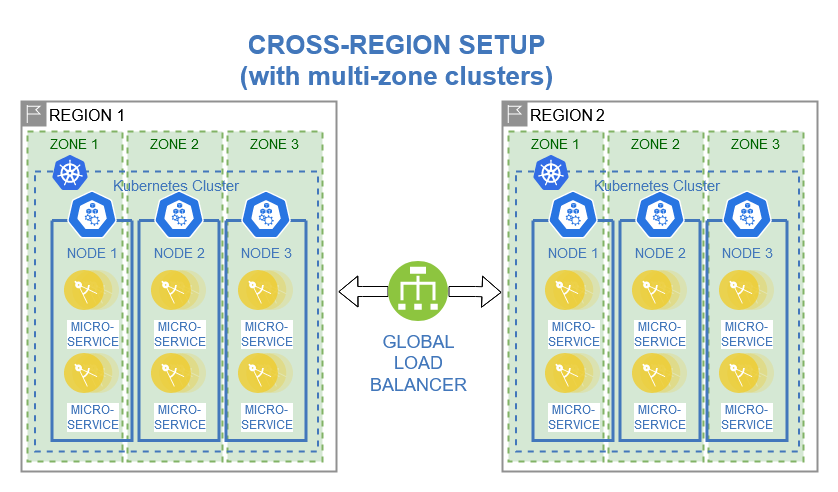
Cross-Region Setup: Deployment of two or more identical microservice application with redundant services in a single across multiple regions to enable high availability in case of single region failures. [3]
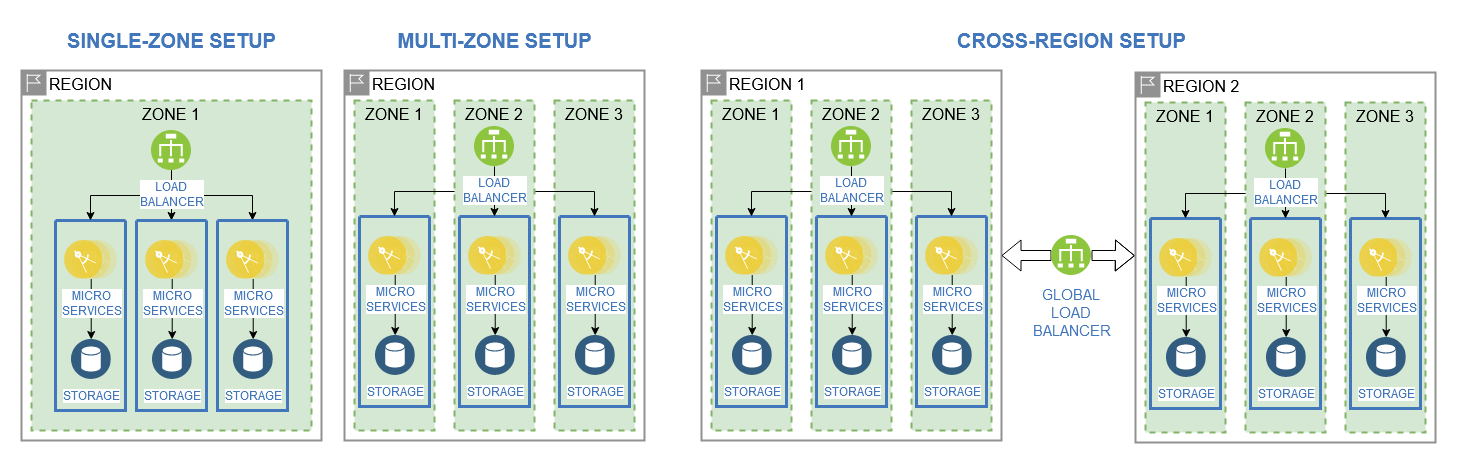
Scalability
Scalability is an important concept to understand when designing and creating highly available systems. It allows a system to scale based on the current workload and ensures that resource limits are not hit, preventing an eventual failure. While microservices already offer a certain level of scalability due to the independence of each service, introducing containerization (i.e. packaging of software code into portable, resource-efficient and lightweight executables [4]) with a container orchestration tool like Kubernetes can add even more scalability.
Kubernetes (kube or k8s for short) is an open-source platform for orchestrating containerized applications. Container orchestration systems handle the management of applications by automating provisioning, scaling and failover. In the case of Kubernetes, services are grouped into containers (or “pods”), which then run on physical or virtual machines. The individual machines, which can also be hosted in the cloud, making Kubernetes an ideal orchestration platform for cloud-based applications, are referred to as “nodes” with one or more worker nodes forming a cluster. Clusters provide vertical and horizontal scalability by scaling pod or node specifications and by scaling the number of pods per node or number of nodes, respectively. [5]
In addition, extending the previously created microservice example to include a Kubernetes cluster has several benefits for availability. In a multi-zone setup, a Kubernetes cluster can be spanned across multiple zones. Each zone represents a data center within a city which is geographically isolated from the other zones. Provisioning a cluster’s nodes across different zones ensures higher availability compared to a single zone setup and guarantees cluster uptime in the event that one of the datacenters experiences a severe outage or major failure.
Load Balancing
Load balancing evenly distributes network traffic across multiple servers or instances to avoid overloading any particular resource. By intelligently managing workloads, load balancers optimize performance, prevent bottlenecks, and enhance fault tolerance. Kubernetes introduces built-in load balancing on pod-level. This allows loads to be evenly distributed between individual pods and is crucial for maintaining stability and scalability in an application. In addition, a global load balancer can be implemented to realize the cross-region setup mentioned earlier and other architecture patterns that provide disaster recovery and failover functionality.
Automated Failover Mechanisms
Automated failover mechanisms detect system failures and automatically switch to redundant components or backup infrastructure. These mechanisms reduce downtime and provide uninterrupted service delivery by minimizing manual intervention. Kubernetes already implements automated failover by immediately restarting a crashed pod, ensuring high availability of application services. Combining Kubernetes with nodes running on virtual machines in the cloud enables additional failover since it accounts for a node failure by distributing the workload on the remaining worker nodes as well as automatically reprovisioning a new node.
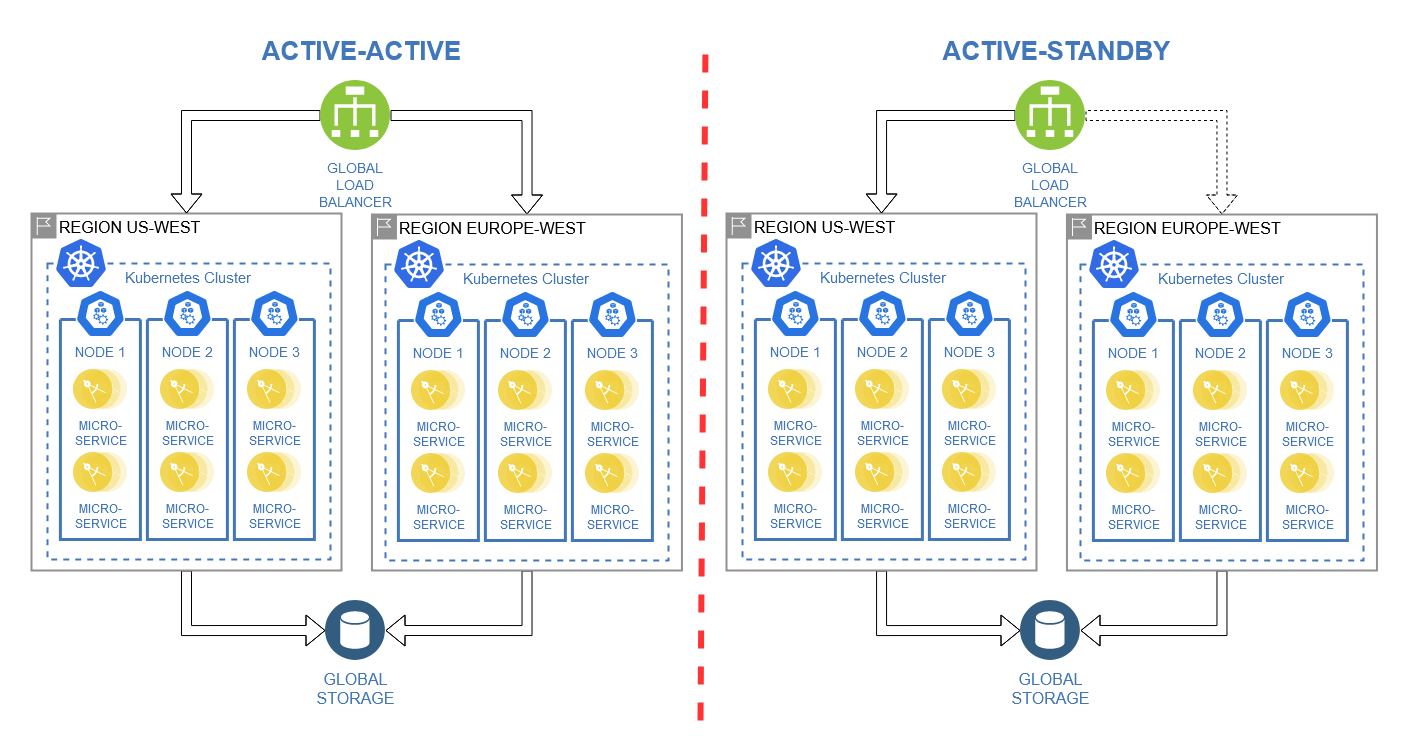
As mentioned previously, using a cross-region setup with a global load balancer enables failover through two distinct patterns:
Active-Active: Deployment of multiple identical instances that run concurrently and are managed by a global load balancer. In the event of a failure, requests are automatically redirected to another instance, resulting in near-zero recovery time, but with reduced computing capacity. [3]
Active-Standby: Deployment of multiple identical instances with one operating as primary, while all others are standby. The global load balancer directs requests to the primary instance. In the event of a failure, requests are rerouted to a standby instance, resulting in recovery time within minutes but with identical computing capacity. [3]
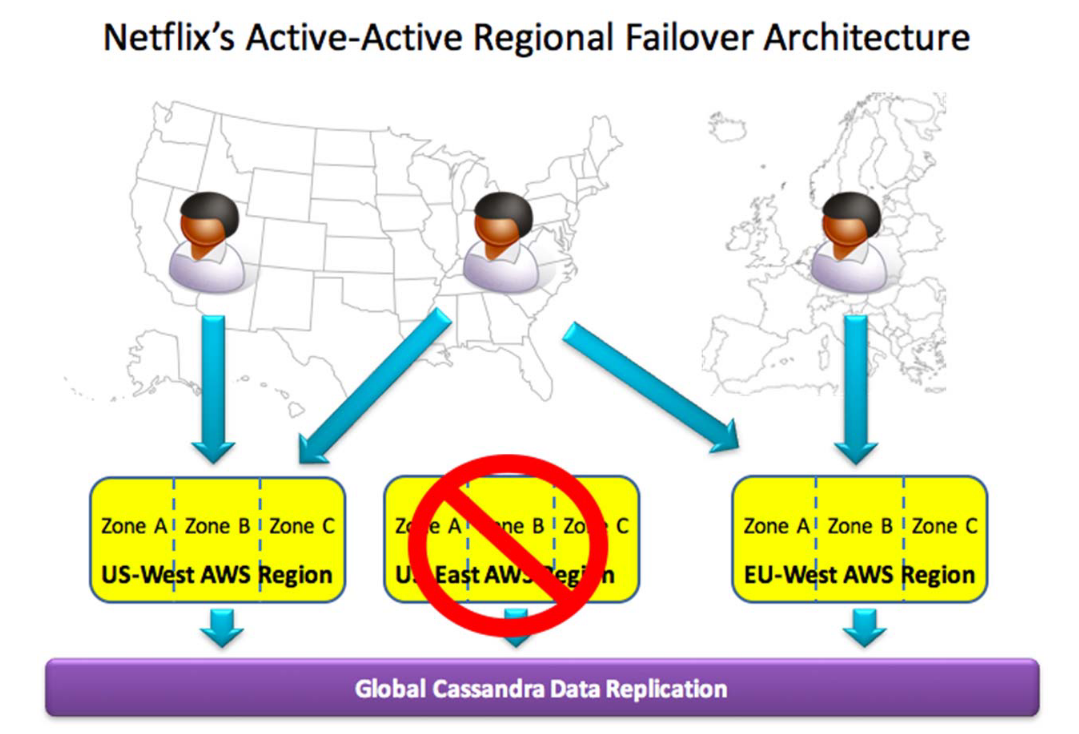
After experiencing an 18-hour outage affecting the majority of their customers due to a regional failure, Netflix moved to an active-active cross-region setup. Customer traffic is distributed across three cloud regions with redundant computing capacity. In the event of a regional outage, the other regions continue to serve customers from that affected region, resulting in virtually no impact on customers. In order to ensure the consistency of customer data across regions, data is synced and replicated in a global data base which also has a positive effect on availability. [6]
Ensuring Reliability in Cloud Computing Systems
Reliability describes the probability that the system or infrastructure will meet certain performance standards and deliver correct output for a given period of time. Reliability and availability are closely related but they are not quite the same. Reliability complements high availability by focusing on the consistent, error-free performance of a system or infrastructure. Much like high availability cloud infrastructure, reliability can’t just be added to an existing system – it must be designed and implemented from the ground up. Ensuring fast service within an acceptable time and minimizing failed responses is crucial for mitigation of service disruptions and a positive user experience. [7]
Reliability is usually expressed as “defects per million” (DPM) and can be calculated using the following formular [7]:
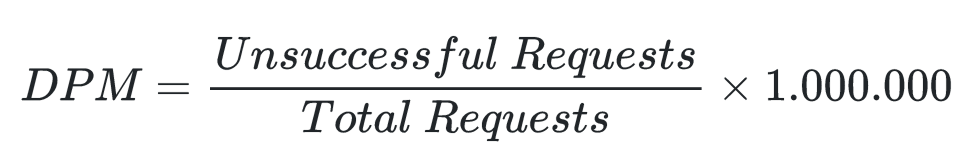
A reliable system or infrastructure can be realized by implementing several components. In the following we’ll take a look at some of these components:
- Service Level Agreements (SLAs)
- Backup and Disaster Recovery
- Chaos Engineering
- Observability through Monitoring
- Deployment Strategies
Service Level Agreements (SLAs)
Service Level Agreements (SLAs) are formal contracts or agreements between service providers and their customers that outline the specific level of service to be provided. In the case of cloud providers SLAs set clear expectations on targets for a service’s uptime, performance and response time. They establish accountability for the provider and define compensation based on the cumulative unavailability or unreliability of a service. SLAs play a crucial role in establishing a mutual understanding between service providers and customers to ensure that the service meets the required standards and performance levels, which has a positive impact on reliability and availability. [3]
Backup and Disaster Recovery
Backing up mission-critical data and having disaster recovery plans in place ensures that systems have data integrity and can get back up and running quickly in the event of a major disruption such cyberattacks or even natural disasters. Taking another look at the Netflix example mentioned earlier, implementing a cross-region setup with global data replication not only improves the overall availability of a system, but also increases recoverability from disasters. A system or infrastructure that is able to recover quickly without data loss increases reliability by ensuring that performance and availability SLAs can be met as well as business continuity can be maintained.
Chaos Engineering
Over time, a live production environment can experience ever-changing usage patterns such as traffic spikes (and even thundering herds) or poor network conditions, which will eventually expose bottlenecks, dependency loops and failure scenarios that were not accounted for in design or testing. Chaos engineering is a discipline that is supposed to proactively identify and address these potential bottlenecks and scenarios by experimenting in a live production environment. The ultimate goal is to build confidence in a live production system’s capability to withstand stressful and unpredictable situations (such as black swan events). Netflix originally popularized chaos engineering when they announced their “Simian Army”, a set of “chaos tools” that trigger controlled failures in a production environment to test a its failure detection and disaster recovery mechanisms. The Simian Army consists of several agents, such as the “Chaos Monkey”, which randomly terminates mission-critical live production instances, the “Latency Monkey”, which injects additional latency to a client-server connection or the “Chaos Kong”, which evacuates an entire cloud region. Despite the reluctance of some business owners, the chaos engineering approach has proven its necessity and cost-effectiveness in improving system reliability. [6]
Observability through Monitoring
The observability of a system describes the ability to understand its internal behavior through external monitoring outputs such as metrics, logs and traces. Monitoring is a critical aspect of ensuring the reliability of infrastructure, services, and applications. In the context of reliability, monitoring involves continuously observing and tracking the health, performance, and availability of system components to quickly detect deviations from the expected behavior. The primary goal of monitoring is to proactively identify and isolate potential issues or anomalies in system performance before they escalate into critical failures. [8]
Deployment Strategies
While the previously mentioned components ensure reliability on an infrastructure level, the application level is also a risk for outages due to faulty code deployments or configuration changes. One way to ensure reliability on application level is to implement deployment strategies such as canary releases and blue-green deployments in order to minimize risk of an outage after a change in production code.
Canary Releases: A “canary” release describes the release of a new version of software code on an identical environment to a small portion of customers. identical “canary” environment is set up to run the new version of the code. Engineers collect performance data and analytics to identify problems without affecting the entire customer base. [8] The previously mentioned orchestration tool Kubernetes offers built-in support for deployment patterns and can manage a canary deployment for an application. [9]
Blue-Green Deployments: Two parallel production environments are set up – one with the old version of the software code (blue) and the other with the new release (green). Traffic is gradually routed from blue to green, and any issues with the new release prompt a quick return to the blue environment, which remains functional at all times. Once confidence in the new version is gained, the blue environment is shut down, taking advantage of flexible cloud deployments to only temporarily double production capacity. [8]
Conclusion
In conclusion, black swan events have a significant and unpredictable impact on the reliability and high availability of systems and infrastructure. These rare and unforeseen incidents challenge traditional risk assessment and contingency planning, resulting in unexpected failures, disruptions, and extended downtime. Despite the challenges they present, black swan events also provide valuable opportunities for learning and adaptation.
While it is impossible to completely eliminate the possibility of black swan events, organizations can enhance their preparedness and response capabilities by implementing different availability and reliability patterns and components. Systems and infrastructure should be designed and built from the ground up with availability and reliability in mind. Implementing patterns such as active-active or active-standby and multi-zone or cross-region setups, as well as components such as redundancy, load balancing, automated failover and scalability can greatly improve the availability of a system or infrastructure. Monitoring, SLAs, backup and disaster recovery plans, deployment strategies, and chaos engineering make a system and infrastructure more reliable. It is also important to learn from past incidents and make improvements to the system accordingly, which can lead to greater reliability and high availability, enabling organizations to navigate through potential outages and disasters without significant business disruption.
In the face of uncertainty, organizations must remain cautious, stay informed about emerging risks, and proactively improve the resilience of their systems. Embracing a culture of adaptability and resilience is crucial in responding effectively when confronted with black swan events. Businesses can minimize the impact of black swan events and ensure the continued delivery of reliable and available services in an ever-changing and unpredictable world.
References
| [1] | M. Loukides, “The Cloud in 2021: Adoption Continues,” O’Reilly, 2021. |
| [2] | L. Nolan, “What breaks our systems: A taxonomy of black swans,” Brooklyn, NY, 2019. |
| [3] | C. Hernandez, E. Patrocinio, L. Vadivelu and M. Rodier, “Architecting highly available cloud solutions,” [Online]. Available: https://www.ibm.com/garage/method/practices/run/cloud-platform-for-ha. [Accessed 26 July 2023]. |
| [4] | I. C. Education, “What is containerization?,” [Online]. Available: https://www.ibm.com/topics/containerization#toc-microservi-mCC8udea. [Accessed 28 July 2023]. |
| [5] | I. C. Education, “Kubernetes,” [Online]. Available: https://www.ibm.com/topics/kubernetes. [Accessed 28 July 2023]. |
| [6] | Y. Izrailevsky and C. Bell, “Cloud Reliability,” IEEE Cloud Computing, pp. 39-44, 2018. |
| [7] | E. Bauer and R. Adams, Reliability and Availability of Cloud Computing, Wiley-IEEE Press, 2012. |
| [8] | I. Averdunk, “Build for Reliability,” [Online]. Available: https://www.ibm.com/garage/method/practices/manage/build-for-reliability. [Accessed 26 July 2023]. |
| [9] | K. Documentation, “Kubernetes Documentation,” Kubernetes, 2023. [Online]. Available: https://kubernetes.io/docs/concepts/overview/. [Accessed 29 July 2023]. |
Leave a Reply
You must be logged in to post a comment.