Tag: internet of things
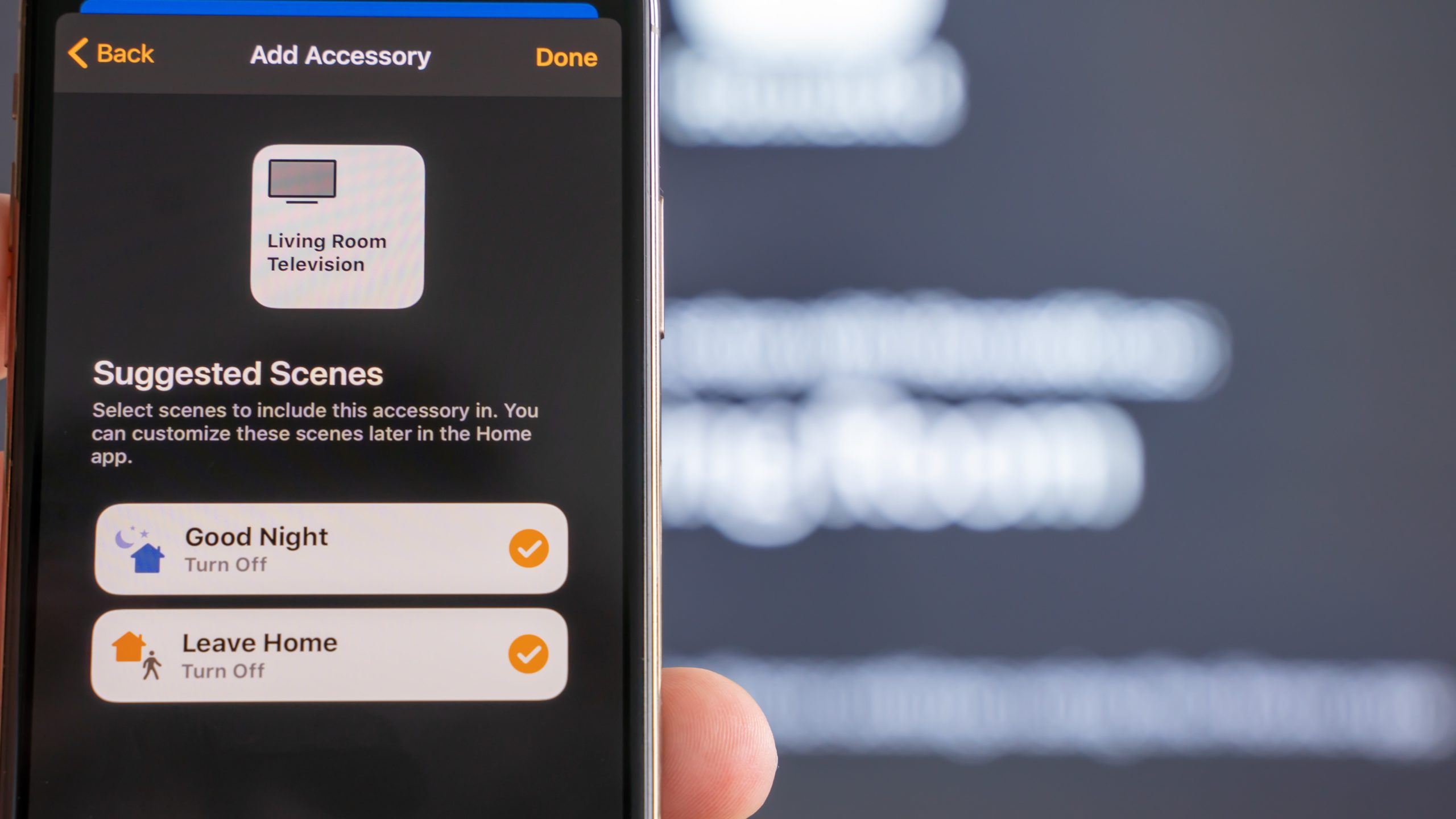
Why It’s So Easy to Hack Your Smart Home
Every day, new smart home accessories go online for the first time to join the Internet of Things. Many of them enjoy the unwarranted trust of their owners.
IoT security – The current situation, “best practices” and how these should be applied
Smart thermostats, lamps, sockets, and many other devices are no longer part of any futuristic movies. These items can be found in most households, at least in parts, whether in Europe, America, or Asia. A trend that affects the entire globe and is currently gaining ground, especially in industrialized countries. It seems to be obvious…
End-to-end Monitoring of Modern Cloud Applications
During the last semester and as part of my Master’s thesis, I worked at an automotive company on the development of a vehicle connectivity platform. Within my team I was assigned the task of monitoring, which turned out to be a lot more interesting but at the same time way more complex than I expected.…
The Elixir Programming Language
An introduction to the language, its main concepts and its potential. The number of security incidents has been on the rise for years, and the growth of the Internet of Things is unlikely to improve the situation. Successful attacks on all kinds of interconnected smart devices, from car locks over home security systems to highly…
You must be logged in to post a comment.