Introduction
During the last semester and as part of my Master’s thesis, I worked at an automotive company on the development of a vehicle connectivity platform. Within my team I was assigned the task of monitoring, which turned out to be a lot more interesting but at the same time way more complex than I expected. In this blog post, I would like to present an introduction to system health monitoring and describe the challenges that one faces when monitoring a cloud-based and highly distributed IoT platform. Following that I would like to share the monitoring concept that was the result of my investigation.
Monitoring
When developing an application, monitoring usually is not the first topic to come up to the developers or managers. During my time in university, whenever we had a fixed date to present results as part of a group’s project, me and my colleagues usually shifted our focus towards feature development rather than testing and monitoring. The need for monitoring however, becomes extremely important as soon as you have to operate a software system. Especially when maintaining distributed systems which cannot be debugged as traditional, monolithic programs the need for enhanced monitoring grows. The biggest difficulty with monitoring, is that it has to be designed specifically for the application that is needs to be monitored. There is no one-size-fits-all solution for monitoring. Within the scope of monitoring, there are a lot of different use cases to focus on. When talking about operating a software platform, our focus relies on system health monitoring.
System health monitoring
Monitoring has a different meaning depending on the domain it is being employed in. Efforts when monitoring software systems can put special interest into topics concerning security, application performance, compliance, feature usage and others. In this post I would like to focus on system health monitoring, following the goal of watching software services’ availability and being able to detect unhealthy states that can lead to service outages.
Even when reduced to health monitoring, one implementation of monitoring can differ strongly from another, depending on how different the systems, the processes, the tools and the users and stakeholders of that monitoring information are defined. The basis for monitoring is constantly changing due to the introduction of new technologies and practices. Therefore, a state of full maturity for monitoring tools can hardly ever be reached.
Monitoring Tools
Monitoring tools were created and adapted to fit for the domain of the systems that had to be monitored. Monitoring requirements are substantially different when monitoring clusters of homogeneous hardware running the same operating systems to those when managing the IT-infrastructure of a middle to large-size company with heterogeneous hardware (e.g. databases, routers, application servers, etc.).
If you are building a new software application or have been assigned the task of maintaining one, here are a few example tools that focus on different aspects of monitoring that could be interesting to try out.
- Collectd – Push based host metric collection: Collectd is able to collect data from dynamically started and stopped instances. It works by periodically sending host metrics from preconfigured hosts to a central repository. By being a push-based system, it works also for short-lived processes. [2]
- StatsD – Application level metric collection: StatsD was designed as a simple tool that collects traces and sends them via UDP to a central collector, where they can be forwarded to a collection and visualization tool like Graphite to be used to render graphs that are displayed in dashboards. [3]
- The Elastic-Stack – Log management and analysis: When applications are hosted inside containers running on separate hosts, it is not only difficult to extract a containers low-level metrics, but also to extract and collect application-level metrics and logs. The standard open-source solution for this problem is the Elastic-Stack.
- Riemann – Monitoring based on Complex Event Processing: Riemann differentiates itself from other monitoring tools in that it introduces event stream processing techniques to monitoring. Riemann works by processing events that are pushed by many distinct sources and, thanks to its push-based architecture, provides high scalability.
- New Relic – Monitoring solution as SaaS: New Relic is one of the more recent SaaS solutions that have emerged in the past years. The feature of MaaS (Monitoring-as-a-service) is that the infrastructure and services needed to implement monitoring tools is abstracted away from operations teams. MaaS systems like New Relic can be configured to watch the infrastructure running services and receive monitoring data from the monitored objects either via data pushes directly or by installing agents that run inside hosts. Apart from collecting and processing logs, New Relic provides a browser based interface to access data and create customized dashboards as well as features like auto-detecting anomalies with the use of machine learning.
- Zipkin – Distributed tracing: Zipkin, among other distributed tracing solutions, focuses on tracking requests on a distributed system in order to inspect the system for errors or performance bottlenecks and to enable troubleshooting in architectures where multiple components are being employed.
Zipkin supports the OpenTracing API. OpenTracing is a project aimed to introduce a vendor-neutral tracing specification. Its objective is to standardize the tracing semantics to allow for better distributed tracing capabilities across frameworks and programming languages. Trace collectors can implement the OpenTracing API and can thereby be employed in large scale distributed systems, in which system subcomponents are written by different teams in different languages.
If your project if focused more on infrastructure components, it would be interesting to take a look at collectd. For a smaller web application, I would recommend to build in StatsD and focus on tracking relevant business KPIs from inside the relevant functions within the code. For any software project I would recommend to employ a log management system like the Elastic-Stack or an alternative. Since its an open source solution, there are no licence costs attached and it can notably reduce troubleshooting time when debugging your application, specially if your application relies on a microservice architecture. For start-ups with smaller cloud projects going to production, I would recommend trying out a Monitoring-as-a-service solution to analyze your application usage. Especially for smaller businesses going to the cloud, finding out how your customers are using your application is crucial. Discovering which functions and to what extent resources are being utilized can enable operations teams to optimize the cloud resource allocation while providing the business with important feedback about feature reception.
If you are building a complex distributed architecture involving many different components, it might make sense to evaluate more versatile tools like Riemann and take a look at OpenTracing.
Monitoring Strategy
Unarguably, the employment of the right tools or solutions to monitor a distributed system is crucial for the successful operation of it. However, effective monitoring does not only focus on tooling, but rather incorporates concepts and practices derived from the experience of system operations in regard to monitoring, and to some extent, to incident management. If your task is to monitor a software system, the best way to start is to define a monitoring strategy. When doing so, it should consider the following concepts:
- Symptoms and causes distinction – The distinction of symptoms and causes is especially important when generating notifications for issues and defining thresholds for alerting. In the context of monitoring, symptoms are misbehavior from a user perspective. Symptoms can be slow rendering web pages or corrupt user data. Causes in contrast are the roots of symptoms. Causes for slow rendering web pages can be unhealthy network devices or high CPU load on the application servers.
- Black-box and white-box monitoring – Black-box monitoring is about testing a system functionality and checking if the results are valid. If results are not what was expected, an alert is triggered. White-box monitoring is about getting information about a component’s state and alerting on unhealthy values. While white-box monitoring can help the operations personnel find causes, black-box monitoring is used to detect symptoms.
- Proactive and reactive monitoring – In relation to black-box and white-box monitoring are the concepts of proactive and reactive monitoring. Whereas reactive monitoring is concerned about collecting, analyzing and alerting on data that can reflect an outage of the system, reactive monitoring emphasizes on detecting critical situations within the monitored object that can lead to a service performance degradation or complete unavailability. While the results from black-box monitoring can be useful to detect problems affecting users, white-box monitoring techniques provide more visibility into a system’s internal health state. With careful analysis of trends on internal metrics, a prediction of imminent failures can be made, which can either trigger a system recovery mechanism, an auto-scale of system resources or alert a system operator.
- Alerting – Alerting is a crucial part of monitoring. Alerting however, does not necessarily involve paging a human being. The latter should mostly remain the exception and only be employed when services are already unavailable or failure is imminent without human action. For events that require attention, but do not involve failing systems, alerts can simply be stored as incidents in a ticketing system, to be reviewed by the operations team when no other situation requires their attention. In case of pages, they should be triggered as sparsely as possible, since constantly responding to pages can be frustrating and time consuming for operations employees. When defining thresholds to be notified on, new approaches propose to aggregate metrics and generate alerts on trends, instead of watching simple low-level metrics, e.g. watching for the rate in which available space on a database is filling up, instead of its current free space at a certain point in time. This concept relates to focusing on symptoms rather than causes when alerting.
When implementing the monitoring strategy for your project, it’s best to start with black-box monitoring, covering the areas that affect your users the most (such as being able to log in to your system). When defining alerts, focus should rely on symptoms rather than causes, since causes might or might not lead to symptoms. Also, if your are defining alerts, always focus on the right choice of recipients. Different groups of project employees might be interested on different types of alerts or different granularity. Alert the business about decreasing page views and not about cluster certificates that will expire soon.
Real-life scenario: monitoring a cloud-based vehicle connectivity platform
The connectivity platform I worked on provides infrastructure and core services to develop connectivity services for commercial vehicles. These services enable users to open the vehicles’ doors remotely via smartphone or displaying the position and current state of a vehicle on a map. The platform provided a scalable backend which handled the load of incoming vehicle signals and provided it as JSON data from APIs. It also included frontend components which fetched data from the provided APIs and displayed it in a smartphone in the custom app or in a browser as a web application. The platform was built on top of Microsoft Azure and was based on the IoT reference architecture proposed by Microsoft in the Azure documentation. It was built on a highly distributed microservice architecture that made extensive usage of Azure’s products, both SaaS and PaaS. Its core was made of an Azure Service Fabric cluster running all microservices that implemented the business logic of the connectivity services. The communication between microservices was established either synchronously via HTTP or asynchronously using Azure’s enterprise messaging component Azure Service Bus. In order to implement most use cases the platform’s components also had to communicate with various company-internal systems, as well as third party software services that implemented specific functionality, such as user management.
Monitoring challenges
In order to reach a basic level of monitoring in the platform, at least each component of the platform, which was not being fully managed by Microsoft or a third-party service provider (e.g. a SaaS- component), had to be monitored by the operations team. As stated above, special care was put in the choice of components that demanded the lowest level of administration effort of the aforementioned team. That led to an increased usage of PaaS-components instead of Virtual Machines or other infrastructure alternatives.
Even though the infrastructure of PaaS-components does not need to be managed by the cloud consumer, there are some aspects when using PaaS-components that can generate errors in runtime and must, for this reason, be constantly monitored by the operations team. Some examples are:
A queue in the Service Bus, filling up rapidly because a microservice is not keeping up with the number of incoming messages.
An Azure Data Factory Pipeline that stopped running because a wrong configuration change removed or changed a database’s credentials and the pipeline is not able to fetch new data.
The former scenario can be easily detected, since Azure provides the resource owner with many metrics regarding the high-level usage of each component. In this case, a counter of unread messages is available in the Azure Portal or via Azure Metrics. Since the counter is available in the portal, widgets displaying its data can be pinned to a dashboard and alerts can be created for a given threshold on this metric.
In the data pipeline scenario, an outage can be detected by setting alerts on the activity log, which is the only place where occurring errors within Data Factories are reported. However, an aspect adding risk to the latter scenario is that detecting that a pipeline stopped running is especially difficult when testing the system from the user’s perspective, since it is only reflected by outdated or incorrect data, instead of directly throwing an error.
In this sense, the operations team of the platform should always be notified in the case of a stopped pipeline because user complains might be misleading. Also, the advantage of using PaaS components and having the underlying infrastructure abstracted away from the user comes with the disadvantage that all available logs and metrics, from which monitoring events can be derived, are defined by the component’s provider and cannot be easily expanded, customized or complemented with own information.
The monitoring strategy
When defining the monitoring strategy for the platform from a technological point of view, the first decision was to make extensive use of the SaaS monitoring solutions already provided by Microsoft to monitor applications and infrastructure hosted inside of Azure, before introducing external proprietary solutions or deploying open-source monitoring tools to watch the platform. The tools employed were Azure Monitor, Azure Log Analytics and Azure Application Insights. Implementing white-box monitoring was simpler due to the seamless integration of tool provided by Microsoft to monitor Applications on Azure. Implementing black-box monitoring to be able to tell that the most important functions of the platform were available was way trickier. The next section explains the concept developed as part of my thesis.
End-to-end black-box monitoring
Why monitoring single components is not enough
The problem statement above only describes the challenges of monitoring each component on its own. The services offered by the platform however, are provided only as a result of the correct functioning of a specific set of these subcomponents together. In many cases, the platform’s subcomponents receive messages, process them and then forward them via a synchronous or asynchronous calls to the next subcomponents, forming complex event chains. These event chains can also include third party systems operated within the same organization or third parties, which handle specific technical areas of the connected vehicle logic. From an operations’ perspective, the most valuable information is to know whether a specific, user-facing service is running at the moment or if it is facing technical disruptions. In this case, not only knowing if a service is running in the sense of a passing an integration test is important, but rather having further insights into the system (including its complex event chains) and which part of it is failing to process the requested operation.
This observability can be partially provided by monitoring the platform’s subcomponents on their own, but not entirely. Here is one example:
In case a Service Bus queue filles up, the cause of messages missing in the frontend can be detected by alerting on a threshold on the involved Service Bus queue’s length.
However, here is an example of a case in which finding out the root cause of a service disruption might become less obvious:
A configuration change from a deployment altered the expected payload of a microservice, and incoming asynchronous messages are being ignored by that microservice for being badly formatted.
The error would only be visible by examining the logs generated by the service. If the message drop is not being actively logged by that specific microservice, there is no way for the operations team to find out on which part of the system the messages are being lost. This
observability problem is increased by the fact that PaaS components do not generate logs for every message being processed. That means the last microservice which created logs including the message’s ID is the last point of known correct functioning of the event chain.
This case might not seem probable, but most of the disruptions happening in a production environment come from unintentional changes to the configuration made by an update. Also, as the architecture becomes more and more complex and further components are added to support the main services of the chain, the task of troubleshooting the platform grows in complexity. An end-to-end black-box monitoring system, which monitors the core services of the platform, would substantially reduce effort when searching for misbehaving components since it would alert the operations team as soon as one of the core services is not available. The alert would as well include information about the exact subcomponent responsible for the outage.
What we need is Event Chain Monitoring
The core of the proposed solution is based on event correlation. In this case, an own definition of events and their aggregation was used. The core ideas are inspired by the Complex Event Processing paradigm but its full complexity would go beyond the scope of this blog post. The use of events creates an abstraction level between incoming signals and relevant information for monitoring. Sources of events can be either HTTP requests triggering a component or logs being added to the log repository of the platform or any kind of process that can be converted to an event. To map data to an event, it has to contain information that can be derived to at least the following event metadata:
- Event source
- Event timestamp
- Tracking ID
- Event type
The event source is used to map the event to the component which originally generated the event. The timestamp contains the time in UTC at which the event was generated or processed. The tracking ID is used to correlate events that belong to the same action. Using a tracking ID, all events originated by the same operation can be grouped together. The event name states the type of event that was triggered, such as data from vehicle received at gateway or message processed by microservice A.
When triggered, all events have to be routed to central repository for analysis and aggregation. From this central repository, single events can be analyzed for patterns that indicate system failures.
Defining the model for a fully functioning event chain is then simple. It is calculated with a query as the aggregation of any number of events and a syntax stating the order and time frames in which the events need to reach the central repository. The exact count of events and their order depends on the level of granularity to which the event chain is going to be monitored.
A visualization of the proposed solution is presented in the following diagram using a sample event chain:
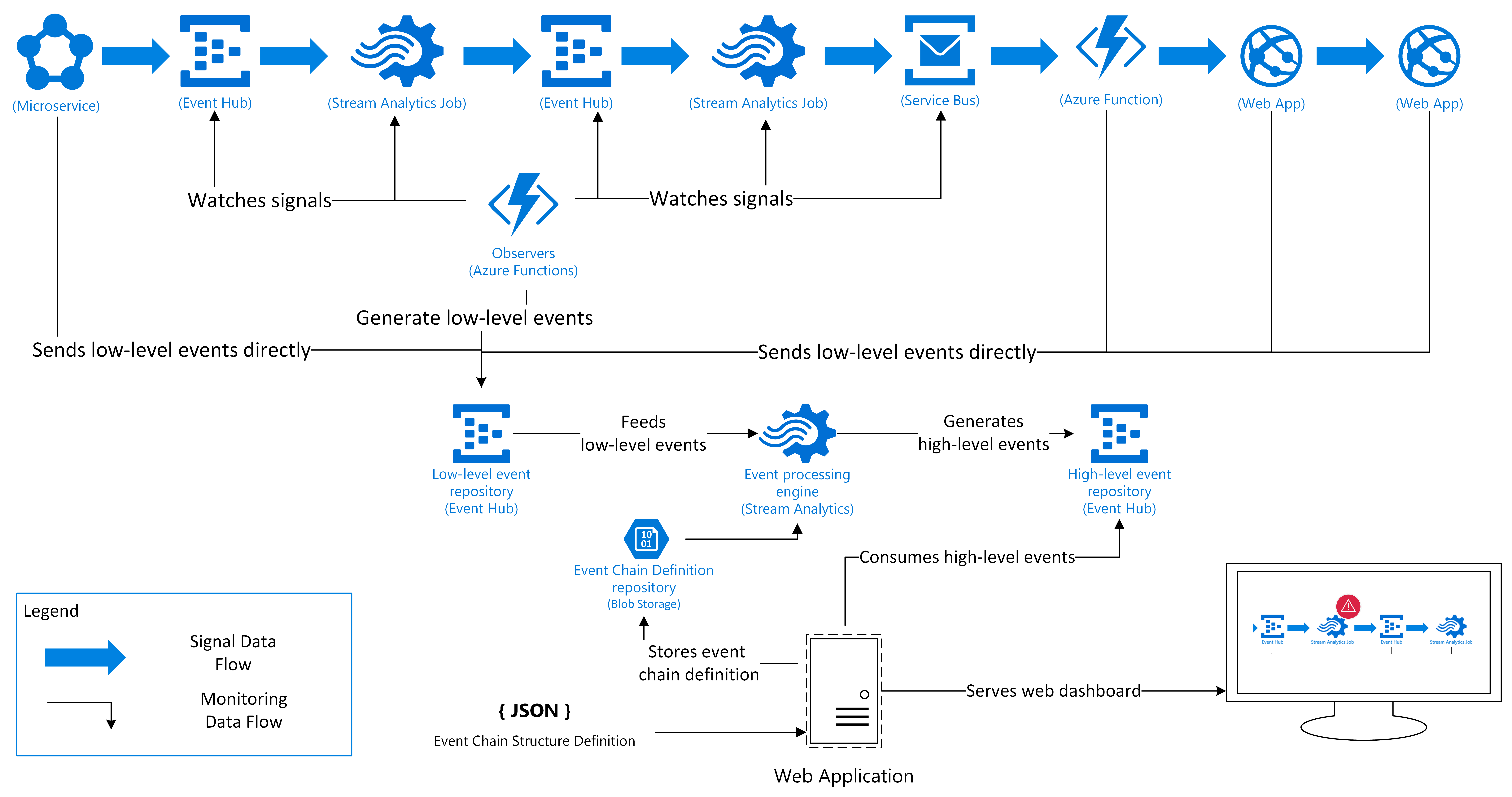

After the event chain is modelled in the monitoring web application, the flow of events can be tracked. First, signals have to be generated. Since generating real signals would involve driving around in a real car connected to the backend, a vehicle has to be simulated, thus the first event would come from a vehicle simulator. After vehicle data events start being pushed to the platform, the different components of the system will start processing the incoming data and interacting with other subcomponents. For each subcomponent, the telemetry capabilities have to be defined. If it supports generating an event for every data signal and sending it to the central event repository or if the event hast to be generated out of the logs or other information sources that are filled by this subcomponent. Depending on the type of components and the level of administration needed, there is more or less information available. If crucial information is missing from a component, a helper or observer unit (here the “observer” Azure Functions) has to be added to the chain, to provide the missing information.
After events are matched, their results can produce other, higher-level events. These high-level events can be consumed by a monitoring dashboard, or a ticketing system. If consumed by a custom dashboard, monitoring information can then be presented by visually showing a graph of the subcomponents of the system. Depending on the patterns matched by predefined queries, different parts of the event chain, that get recognized as failing, can be highlighted in the dashboard.
In addition to displaying a graph of the event chain, the operations team can subscribe to changes to the use-cases health state. If a disruption of a core service is registered, a text message can be sent to the person on-call. Less crucial incidents can be tracked in a ticketing system for further investigation by the operations team. A further advantage of having the event chains displayed visually to the operations team is that even without deep knowledge of the platform, the operations team is able to reason about symptoms visible by users of the platform and track back many incidents that might have the same origin. That is, the operations team would get direct visibility into the state of the subcomponents of the platform and, in the case of an outage, the team gets direct information about the outage’s repercussion on the operability of the system.
Conclusion
The implementation of modern software architecture patterns like microservices combined with the use cloud services beyond IaaS facilitates a faster development of software services. Despite the reduced effort to manage infrastructure when deploying applications to the cloud, being able to monitor the resulting highly distributed systems is becoming an increasingly complex task. On top of that, customers of modern online applications expect short response times and high availability, which raises the need for accurate monitoring systems. In this post I provided a short introduction to monitoring and an overview of current monitoring tools you can test in your projects. However, I also described how a well-thought monitoring strategy is more important than tools in order to increase your system’s availability. In the second half of this post I provided a real-life example scenario and depicted the challenges related to monitoring a distributed IoT-platform. I then presented the concept that was developed in order to reach a better state of observability into the platform.
References
Some of the ideas summarised in this blog post were originally presented in the following articles or books. They are also excellent reads in case the topic of monitoring got your interest.
- B. Beyer, C. Jones, J. Petoff, and N. R. Murphy, Site Reliability Engineering: How Google Runs Production Systems. “ O’Reilly Media, Inc.,” 2016.
- M. Julian, “Practical Monitoring: Effective Strategies for the Real World,” 2017.
- J. Turnbull, The art of monitoring. James Turnbull, 2014.
- I. Malpass, “Measure Anything, Measure Everything,” 2011. link.
- J. S. Ward and A. Barker, “Observing the clouds: a survey and taxonomy of cloud
monitoring,” J. Cloud Comput., vol. 3, no. 1, p. 24, 2014. - B. H. Sigelman et al., “Dapper, a Large-Scale Distributed Systems Tracing Infrastructure,” 2010.
Leave a Reply
You must be logged in to post a comment.