Tag: Monitoring
Von Metriken zu Unknown Unknowns: Observability im Uber-Klon
Abstract Verteilte Microservice-Architekturen ermöglichen hohe Skalierbarkeit, erschweren jedoch Betrieb und Fehlersuche, da klassisches Monitoring den Zusammenhang zwischen den vielen Services in Ultra-Large-Scale-Systemen nur unzureichend abbildet. Diese Arbeit konzipiert ein integriertes Monitoring-, Tracing- und Observability-Framework am Beispiel eines Uber-ähnlichen, verteilten Ride-Sharing-Systems. Dabei werden SLO-basiertes Alerting, Distributed-Tracing-Konzepte mit angepasster Sampling-Strategie sowie eine auf OpenTelemetry gestützte, herstellerunabhängige Gesamtarchitektur…
Cloudbasiertes Performance-Monitoring für Rich-Media-Systeme
Problemstellung In einer zunehmend digitalisierten Welt haben sich Rich-Media-Systeme zu einem integralen Bestandteil unseres Alltags entwickelt. Diese Systeme umfassen komplexe Informations- und Kommunikationsumgebungen, die verschiedene Medienformen und interaktive Komponenten vereinen, um eine hohe Informationstiefe und Interaktionsdichte zu erreichen. Beispiele hierfür sind Video-Streaming-Dienste, Augmented Reality (AR) Anwendungen und interaktive Webinhalte. Die Relevanz von Rich-Media-Systemen erstreckt sich…
Why system monitoring is important and how we approached it
Introduction Imagine building a service that aims to generate as much user traffic as possible to be as profitable as possible. The infrastructure of your service usually includes some kind of backend, a server and other frameworks. One day, something is not working as it should and you can’t seem to find out why. You…
Combining zerolog & Loki
Publish zerolog events to Loki in just a few lines of code.
Migrating from Heroku to Hetzner: Achieving Scalability with Docker, Kubernetes and Rancher
Dockerizing an existing application and deploying it in a Kubernetes Cluster via Rancher to achieve better scalability and cost minimization. Load Testing with Artillery, Monitoring with Prometheus & Grafana and GitHub Actions for CI/CD were used in the process.
End-to-end Monitoring of Modern Cloud Applications
During the last semester and as part of my Master’s thesis, I worked at an automotive company on the development of a vehicle connectivity platform. Within my team I was assigned the task of monitoring, which turned out to be a lot more interesting but at the same time way more complex than I expected.…

Observability?! – Where do we go from here?
The last two years in software development and operations have been characterized by the emerging idea of “observability”. The need for a novel concept guiding the efforts to control our systems arose from the accelerating paradigm changes driven by the need to scale and cloud native technologies. In contrast, the monitoring landscape stagnated and failed…
Cloud security tools and recommendations for DevOps in 2018
Introduction Over the last five years, the use of cloud computing services has increased rapidly, in German companies. According to a statistic from Bitkom Research in 2018, the acceptance of cloud-computing services is growing. Cloud-computing brings many advantages for a business. For example, expenses for the internal infrastructure and its administration can be saved. Resource…
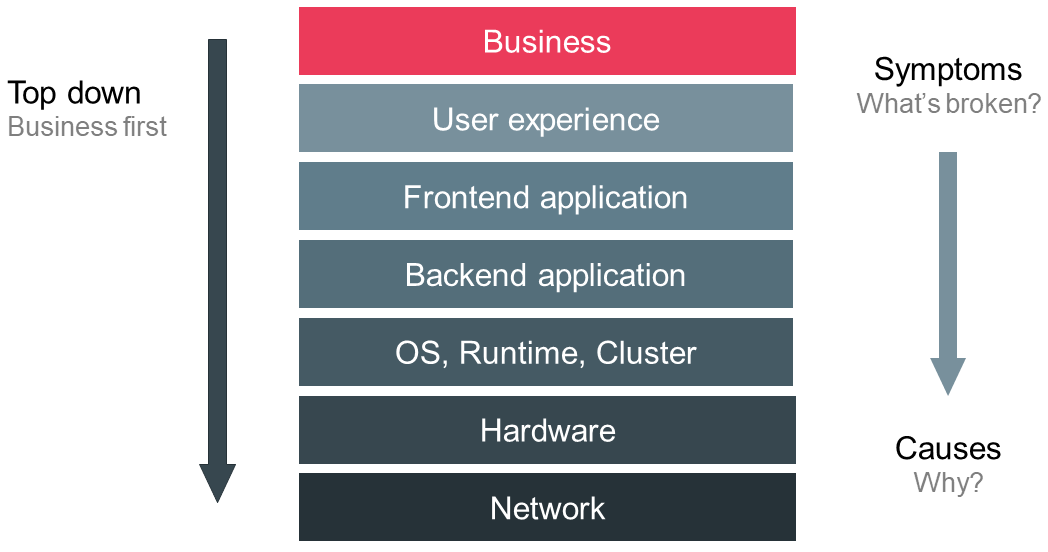
End user monitoring – Establish a basis to understand, operate and improve software systems
End user monitoring is crucial for operating and managing software systems safely and effectively. Beyond operations, monitoring constitutes a basic requirement to improve services based on facts instead of instincts. Thus, monitoring plays an important role in the lifecycle of every application. But implementing an effective monitoring solution is challenging due to the incredible velocity…