Tag: Terraform
Developing a cloud-native web application for case-based file sharing on AWS
Motivation Professional file sharing is a significant challenge in sectors such as healthcare, insurance, and consulting. Practitioners routinely need to exchange sensitive documents with clients, yet existing solutions such as Google Drive and OneDrive can quickly become disorganized when managing multiple cases. Users struggle with scattered links, having to manually control access for each recipient…
Cloudy mit Aussicht auf Wörter: Unser Weg mit CrowdCloud
Willkommen zu unserem Erfahrungsbericht aus der Vorlesung „System Engineering and Management“. In den letzten Monaten haben wir uns an ein Projekt gewagt, das uns sowohl technisch als auch persönlich herausgefordert hat – CrowdCloud. Anstatt uns in trockene Theorien zu verlieren, möchten wir euch in diesem Blog-Beitrag erzählen, wie aus einer spontanen Idee eine interaktive, skalierbare…
 Allgemein, Artificial Intelligence, ChatGPT and Language Models, Cloud Technologies, DevOps, Internet of Things, Scalable Systems, Student Projects
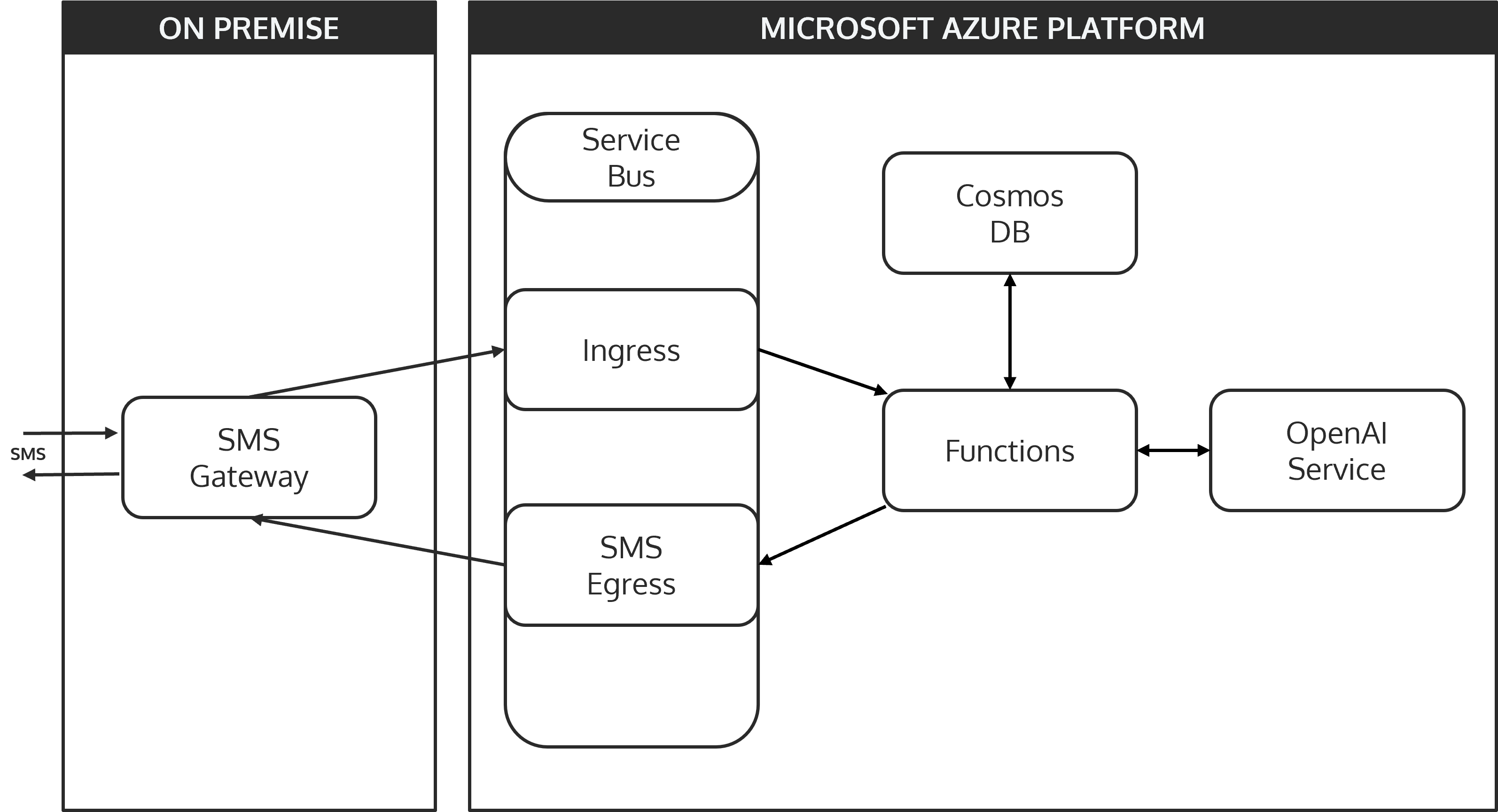
Allgemein, Artificial Intelligence, ChatGPT and Language Models, Cloud Technologies, DevOps, Internet of Things, Scalable Systems, Student ProjectsWelcome to the Future of Government Tech – Meet GuppyAI!
Read about our journey of developing GuppyAI, a friendly, SMS-powered AI chatbot designed to upgrade your skills without the hassle.
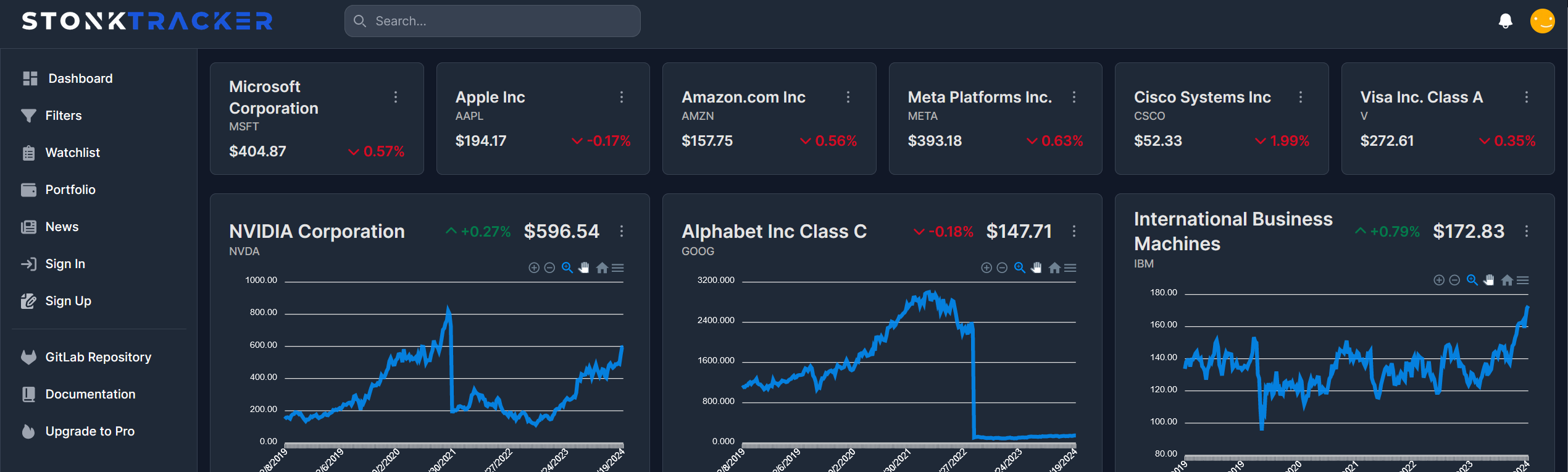
Die Meere der Systemtechnik navigieren: Eine Reise durch die Bereitstellung einer Aktien-Webanwendung in der Cloud
Auf zu neuen Ufern: Einleitung Die Cloud-Computing-Technologie hat die Art und Weise, wie Unternehmen Anwendungen entwickeln, bereitstellen und skalieren, revolutioniert. In diesem Beitrag, der im Rahmen der Vorlesung “143101a System Engineering und Management” entstanden ist, werden wir uns darauf konzentrieren, wie eine bereits bestehende Webanwendung zur Visualisierung und Filterung von Aktienkennzahlen auf der IBM Cloud-Infrastruktur…
Terraform x Go: Challenges when interacting with Terraform through Go
Introduction In a recent project, some of my fellow students and I developed a basic hosting provider that allows a user to spin up Docker containers on a remote server, which is realized by using Terraform locally on the server. During this project, we developed a Go-based backend service that provided a REST API to…
“Studidash” | A serverless web application
by Oliver Klein (ok061), Daniel Koch (dk119), Luis Bühler (lb159), Micha Huhn (mh334) Abstract You are probably familiar with the HdM SB-Funktionen. After nearly four semesters we were tired of the boring design and decided to give it a more modern look with a bit more functionality then it currently has. So we created “Studidash”…
Cloud basierter Password Manager
von Benjamin Schweizer (bs103) und Max Eichinger (me110) Abstract Können Passwort Manager Anbieter meine Passwörter lesen? Wir wollten auf Nummer sichergehen und haben unseren Eigenen entwickelt. Dieser Artikel zeigt auf welche Schritte wir hierfür unternehmen mussten.Dabei haben wir unser Frontend mittels Flutter und unser Backend in AWS umgesetzt. Außerdem gehen wir auf IaC mittels Terraform…
How do you get a web application into the cloud?
by Dominik Ratzel (dr079) and Alischa Fritzsche (af094) For the lecture “Software Development for Cloud Computing”, we set ourselves the goal of exploring new things and gaining experience. We focused on one topic: “How do you get a web application into the cloud?”. In doing so, we took a closer look at Continuous Integration /…