Einleitung
Den meisten sollte das Spielprinzip von “Cookie Clicker” bekannt sein: Ein Klick auf einen Keks erhöht den Spielstand um einen Punkt. Das Spiel ist endlos, hat keine Punktegrenze. Es geht darum, im Leaderboard nach oben zu klettern. Im Rahmen der Vorlesung “System Engineering and Management” (143101a) erweiterten wir das Konzept zu einem Echtzeit-Multiplayer Spiel. Das Spiel nannten wir “Overcookied”.
In Overcookied treten zwei zufällig ausgewählte Spieler in einem 60 Sekunden Match gegeneinander an. Wer am Ende die meisten Klicks hat, gewinnt. Zusätzlich spawnt alle 5-10 Sekunden ein “Golden Cookie”. Der Spieler, der zuerst auf den Golden Cookie klickt, erhält einen kurzen „Double Click”-Bonus, bei dem jeder Klick doppelt gewertet wird.
Das Ziel des Projekts war nicht die Entwicklung eines ausgereiften Spiels, sondern das Kennenlernen und Verstehen von Echtzeit-Gameloops in verteilten Systemen sowie moderne Web- und Cloud-Technologien. Wir wollten Amazon Web Services (AWS) durch praktische Implementierung kennenzulernen, indem das Spiel als verteiltes System betrieben wird, horizontal skalierbar ist und gleichzeitig geringe Latenzen, konsistente Zustände sowie eine zuverlässige Synchronisation zwischen den Clients bietet. Zusätzlich war das Projekt durch einen Budgetrahmen begrenzt. Die Umsetzung erfolgte innerhalb eines AWS-Free-Tier-Accounts mit einem verfügbaren Guthaben von 200 US-Dollar. Aufgrund dieser Einschränkung musste die Infrastruktur jederzeit automatisiert auf- und abgebaut werden können, um Kosten zu kontrollieren und unnötige Ausgaben zu vermeiden. Also musste unsere Infrastruktur zusätzlich als “Infrastructure as Code” aufgebaut werden, um reproduzierbare und kosteneffiziente Deployments zu ermöglichen.
In den folgenden Kapiteln des Blogeintrags werden die einzelnen Umsetzungsschritte, Architekturentscheidungen und Herausforderungen beschrieben.
Lernziele
Unser Ziel war es, praktische Erfahrungen mit Cloud-nativer Softwareentwicklung zu sammeln und die wichtigsten Konzepte verteilter Systeme kennenzulernen und in einem realen Projekt anzuwenden. Den Fokus legten wir dabei auf den Cloud-Anbieter Amazon Web Services, wo wir unsere Anwendung in einem Kubernetes Cluster deployen wollten, sowie die Verwendung von Infrastructure as Code. Außerdem wollten wir lernen, wie ein Echtzeit- Multiplayer Gameloop funktioniert und wie er sich in einem verteilten System realisieren lässt.
Anforderungen
Aus unseren Lernzielen ergaben sich folgende funktionale und nichtfunktionale Anforderungen an das Projekt Overcookied:
| Funktionale Anforderungen | Nicht-funktionale Anforderungen |
| – Login über Google OAuth 2.0Zufälliges Matchmaking zwischen 2 Spielern – Echtzeit-Multiplayer-Gameloop (Begrenzung der Spielzeit auf 1min pro Match) – Live Anzeige der Klicks und Scores (Eigene und des Gegners) – Goldener Cookie mit 5s begrenztem Doppelte-Punkte-Bonus – Leaderboard und Spielhistorie | – Geringe Latenz – Konsistente Spielstände – Hohe Verfügbarkeit (Horizontale Skalierbarkeit) – Kostenkontrolle (Reproduzierbarer Infrastruktur Auf- und Abbau) – Trennung von Frontend, Backend und Infrastruktur – Ansprechendes UI |
Echtzeit Gameloop
Die Anwendung hat drei Schichten: ein Next.js-Frontend, ein Go-Backend mit WebSocket-Support und eine Datenhaltungsschicht. Im Frontend nutzten wir TypeScript sowie Next.js, wo wir bereits Erfahrung hatten. Mithilfe von Tailwind konnte so schnell das UI für das Spiel erstellt werden. Das Frontend besteht aus diesen Pages:
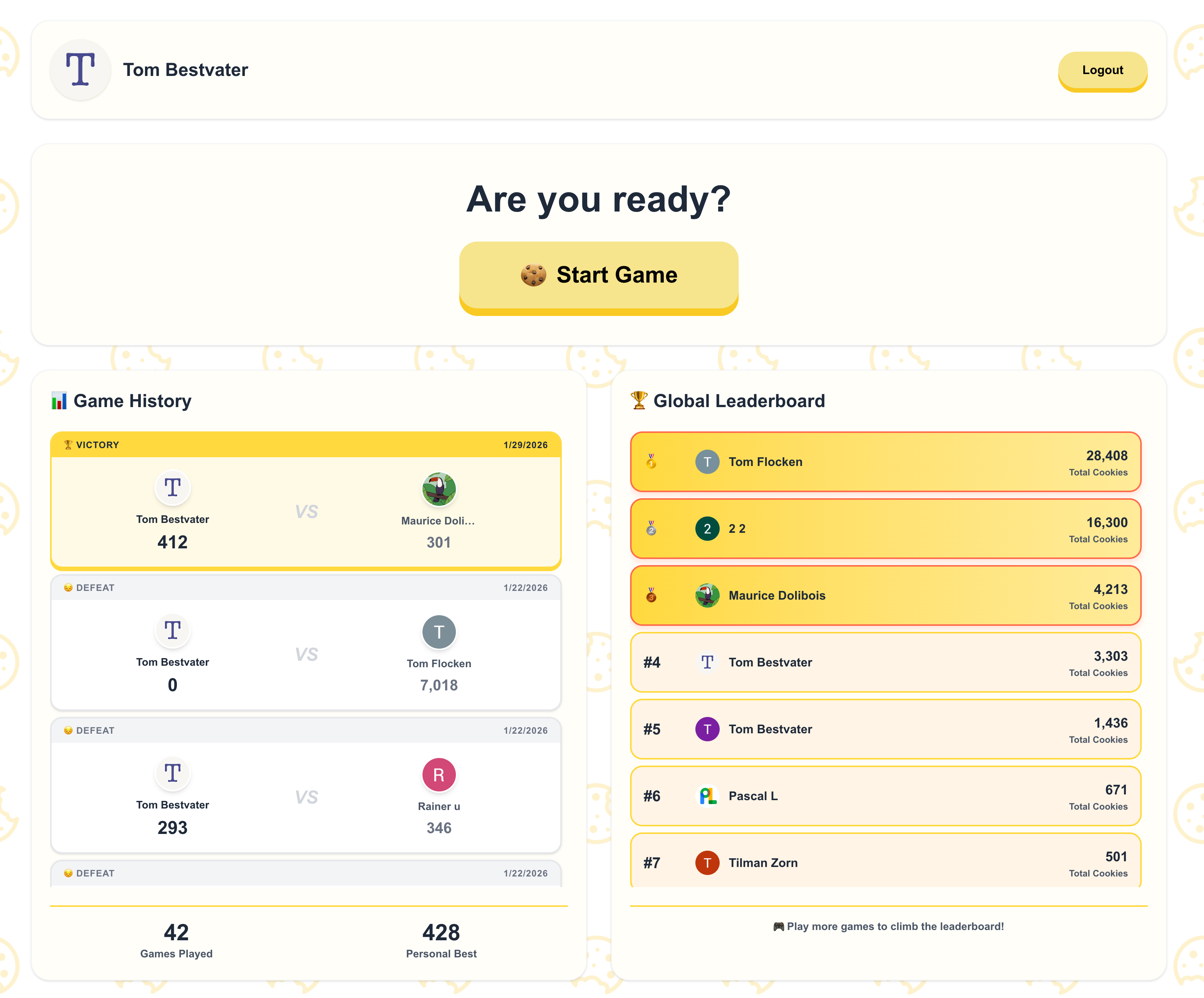
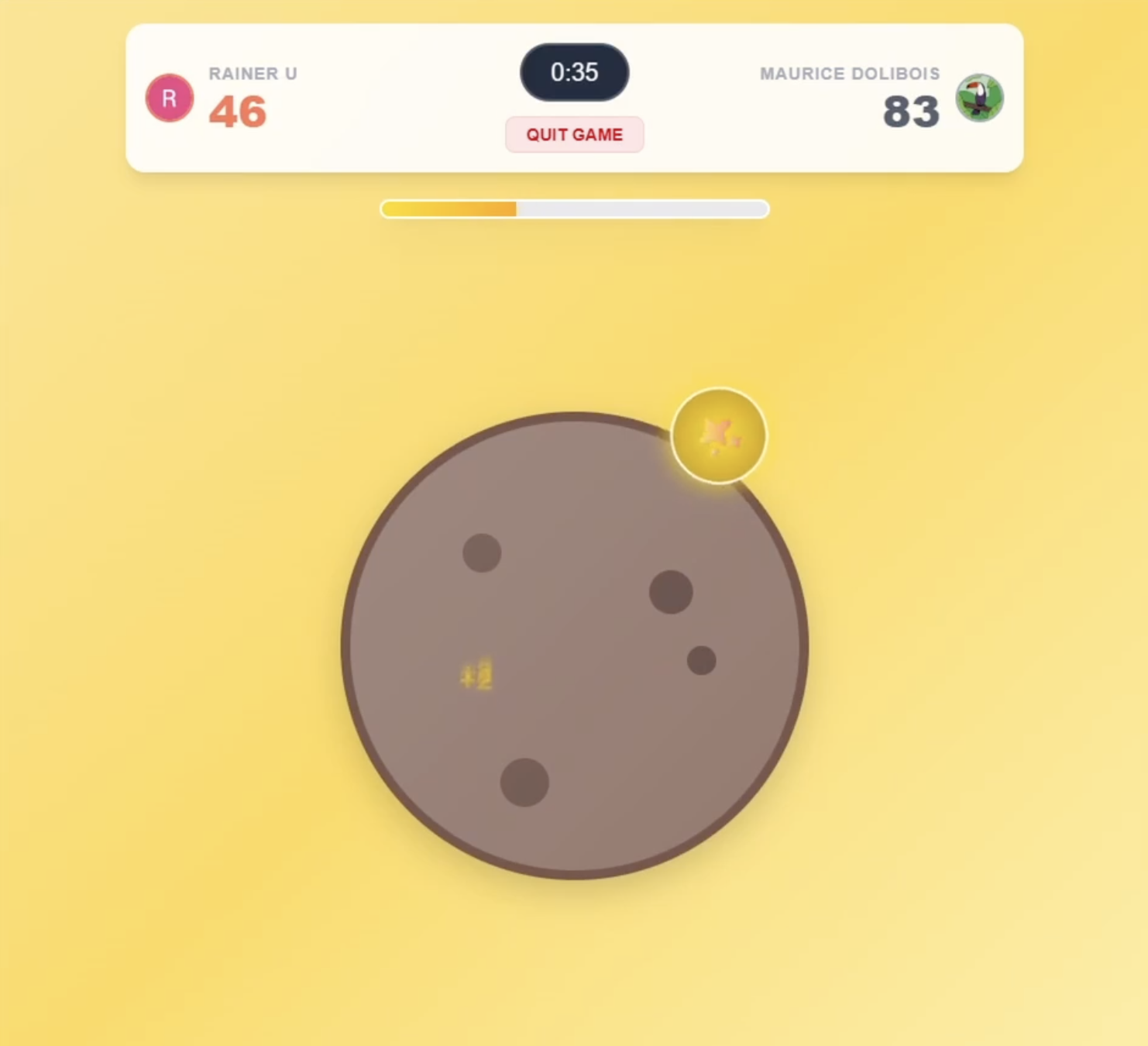
Fig. 1 – Main-Menu-Page (links): Game History und Leaderboard | Fig. 2 – Game-Page (rechts): Cookie + Golden Cookie, sowie ein HUD über den aktuellen Spielstand
Für das Backend wählten wir die Programmiersprache Go, die für uns neu war. Durch AI-assisted Coding und den vielfältigen guten Dokumentationen aufgrund der Popularität von Go, wurde der Einstieg in neue Programmiersprache deutlich erleichtert. Go eignet sich aufgrund seiner Performance und seiner einfachen Concurrency mittels Goroutines und Channels besonders gut für serverseitige Echtzeit-Anwendungen und wurde daher für den Multiplayer-Gameloop eingesetzt.
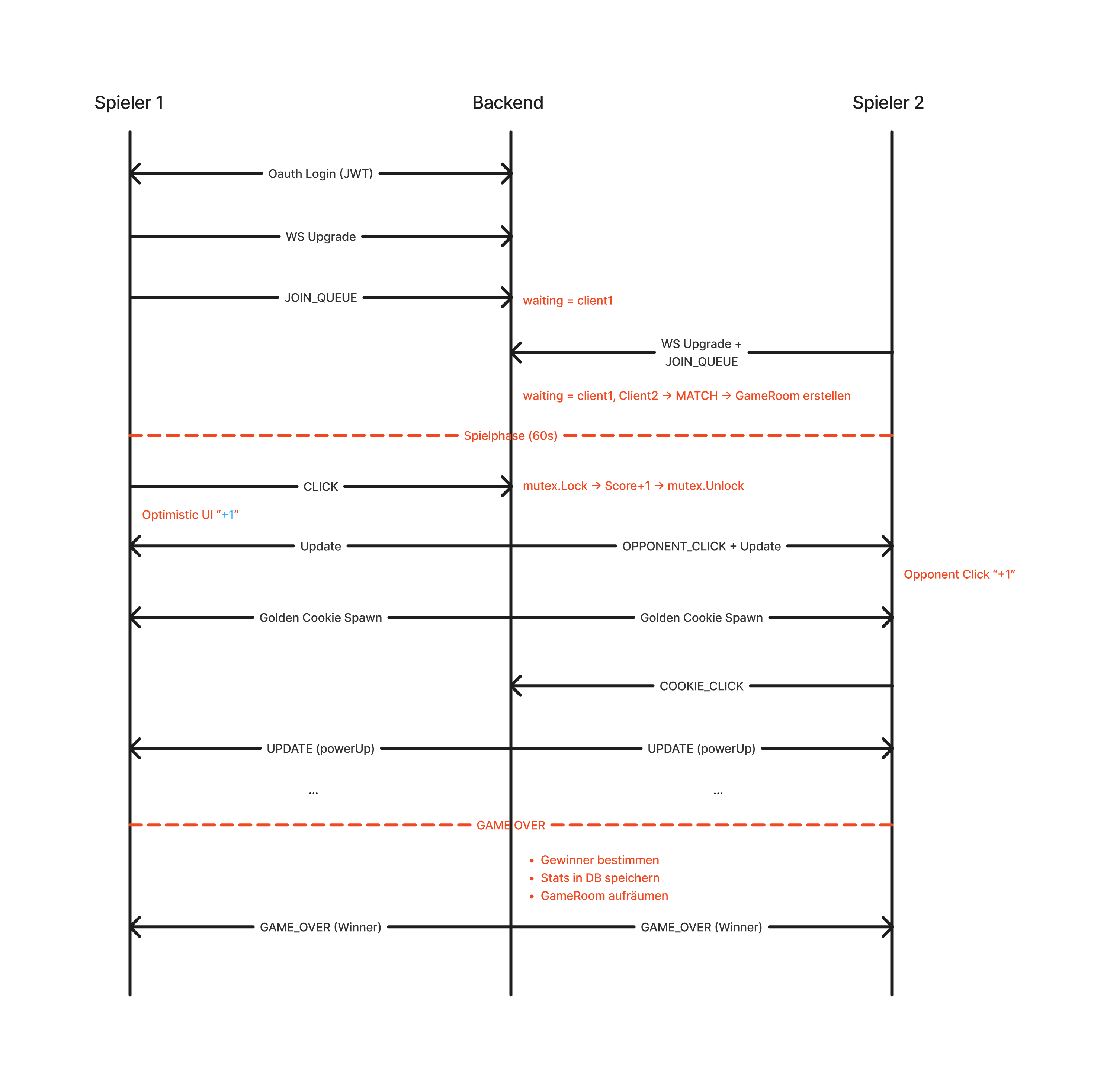
Wenn ein Spieler die Game-Seite betritt, öffnet das Frontend eine WebSocket-Verbindung. Im Frontend ist die echtzeit Spiellogik in einem Custom Hook gekapselt. Er verwaltet die WebSocket-Verbindung, den Spielstatus (IDLE → MATCHMAKING → PLAYING → FINISHED), Scores, Timer und Power-Ups. Das Frontend ruft nur exponierte Methoden auf (sendClick, claimGoldenCookie, quitGame) und reagiert auf State-Änderungen.
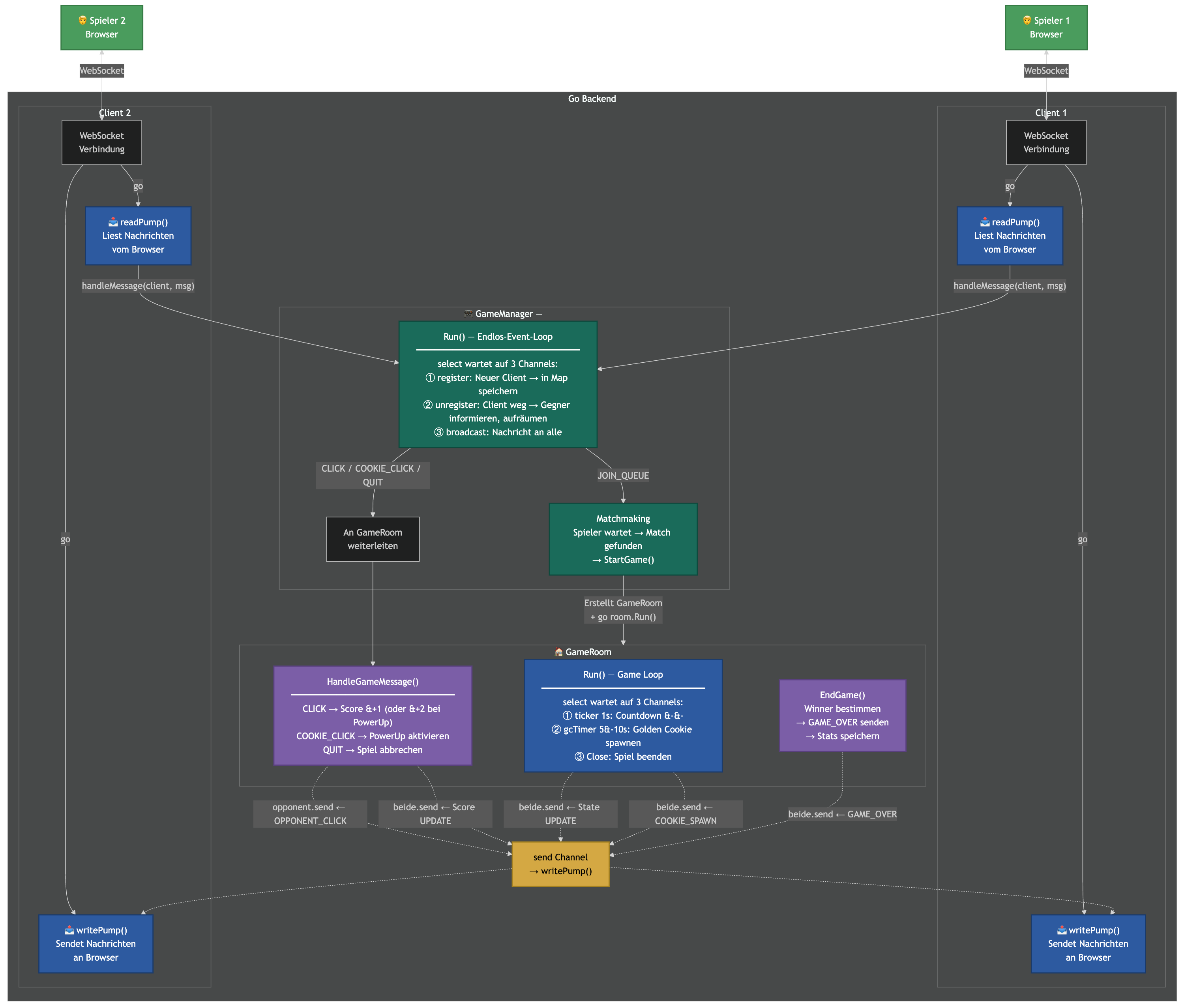
Das Backend registriert die Websocket Verbindung und erstellt einen Client mit den Benutzerdaten. Für jeden Client werden zwei parallele Goroutinen gestartet, sogenannte “Pumps”. Der Name kommt aus der Analogie zu einer Wasserpumpe: Eine Pump-Funktion läuft in einer Endlosschleife und “pumpt” Daten kontinuierlich von einer Quelle zu einem Ziel. Sie blockiert, wartet auf den nächsten Datensatz, leitet ihn weiter, und wartet erneut.
Es werden zwei Goroutines benötigt, da Websocket Verbindungen gleichzeitig lesen und schreiben. Ein Spieler kann jederzeit klicken (Read), während der Server ihm gleichzeitig Timer-Updates schickt (Write). Ein einzelner Loop müsste zwischen Lesen und Schreiben wechseln und blockiert sich so selbst: Wenn gerade kein Click ansteht, wartet die “Read-Routine” auf unbestimmte Zeit und in dieser Zeit können keine Server-Events gesendet werden. Umgekehrt blockiert ein langsamer Client das Schreiben und staut eingehende Nachrichten auf. Die Trennung in zwei Goroutines löst das Problem:
- “readPump”: blockiert auf dem Read-Channel und leitet empfangene Nachrichten sofort an den GameManager weiter. Bei Fehlern (Disconnect, Timeout) löst sie die Deregistrierung aus.
- “writePump”: blockiert auf dem Send-Channel und schreibt Nachrichten auf die Verbindung. Parallel sendet sie periodisch Ping-Frames. Fehlt die Pong-Antwort innerhalb von 60 Sekunden, gilt der Client als tot und wird getrennt.
Zwischen beiden Goroutinen sitzt ein gepufferter Channel. Er entkoppelt die Geschwindigkeit von Sender und Empfänger. Läuft der Channel voll, weil ein Client nicht mehr empfängt, wird die Verbindung geschlossen. Das verhindert Memory-Leaks durch blockierte Clients.
Alle Client-Verbindungen laufen beim GameManager zusammen. Der GameManager ist die zentrale Komponente im Backend: eine permanente Goroutine, die über drei Channels (register, unregister, broadcast) alle Client-Verbindungen, die Matchmaking-Queue und die Zuordnung von Clients zu aktiven Spielen verwaltet.
Sobald die WebSocket-Verbindung steht, sendet der Hook automatisch eine JOIN_QUEUE-Nachricht. Der GameManager speichert den Spieler in einer Warteliste. Betritt ein zweiter Spieler die Queue, erkennt der GameManager: waiting ist nicht leer. Damit ist ein Match gefunden. Dann wird ein GameRoom erstellt, der den gesamten Spielstand beider Spieler synchron kapselt: Scores, Timer, Power-Ups. Eine Timer-Goroutine wird gestartet, und beide Clients erhalten eine GAME_START-Nachricht mit der Gegner-Info und ihrer Rolle (Spieler 1 oder 2).
Jetzt startet das Spiel. Wenn ein Spieler auf seinen Cookie klickt, wird ein blaues “+1”-Partikel angezeigt, bevor die Server Antwort eintritt. Das Frontend nimmt an, dass der Click erfolgreich ist (Optimistic UI) und korrigiert erst bei der nächsten Server-Antwort. So fühlt sich das Spiel trotz Netzwerklatenz wie Echtzeit an.
Im Backend empfängt die readPump die Nachricht und leitet sie an den GameManager weiter. Dieser delegiert an den GameRoom, der den Score erhöht. Zwar werden die Spieler-Klicks unabhängig voneiner getrackt, jedoch kann es zu einer Race-Condition kommen, wenn beide Spieler gleichzeitig auf den “Golden Cookie” klicken. Bei beiden readPumps von Spieler 1 und 2 kommt die Nachricht an, dass sie auf den goldenen Cookie geklickt haben. Beide würden das Power-Up vergeben, obwohl nur einer es erhalten darf. Das wird durch einen sync.Mutex im GameRoom verhindert. Jede Funktion, die den State liest oder schreibt (Click-Handler, Golden-Cookie-Claim, Timer-Broadcast) sperrt zuerst den Mutex und gibt ihn erst nach Abschluss wieder frei. Nach der Score-Erhöhung sendet das Backend eine OPPONENT_CLICK-Nachricht an den Gegner (rotes “+1”-Partikel auf dessen Seite) und eine UPDATE-Nachricht an beide Spieler mit den aktuellen Scores.
Wenn der Timer null erreicht, stoppt der Gameloop. Der GameRoom bestimmt den Gewinner anhand der Scores oder stellt ein Unentschieden fest. Beide Spieler erhalten eine GAME_OVER-Nachricht mit der Gewinner-ID und werden wieder zum Main Menu geroutet, wo sie erneut ein Spiel starten können. Währenddessen persistiert das Backend die Ergebnisse: Für jeden Spieler wird ein Game-Record in der Datenbank gespeichert (Score, Gegner, Gewinner) und die Gesamtstatistik für das Leaderboard aktualisiert. Der GameRoom wird aufgeräumt und die Client-Room-Zuordnungen entfernt.
Infrastructure as Code
Um das Spiel als ein verteiltes System zu deployen, entschieden wir uns für den AWS Service Elastic Kubernetes Service (EKS). So können Frontend und Backend containerisiert, skalierbar und hochverfügbar betrieben werden. Persistente Daten wie Spielstände und Leaderboards werden in DynamoDB gespeichert, während Redis für Session-Management und die Synchronisation von Echtzeit-Zuständen eingesetzt wird. Die Docker-Images der Anwendung werden in der Amazon Elastic Container Registry (ACR) verwaltet. Ein wesentlicher Faktor war zudem der effiziente Umgang mit Cloud-Kosten. Da das Projekt innerhalb eines AWS-Free-Tier-Accounts umgesetzt wurde, musste die gesamte Infrastruktur automatisiert auf- und abbaubar sein, um die laufenden Kosten zu minimieren. Deshalb entschieden wir uns, für den Aufbau und Betrieb dieser Cloud-Infrastruktur das Infrastructure-as-Code-Tool Terraform einzusetzen. Ziel war es, sämtliche AWS-Ressourcen deklarativ zu definieren und reproduzierbar bereitzustellen.
Warum Terraform?
- Etablierter Standard in Industrie und Lehre
- Klare, deklarative Struktur ohne zusätzliche Programmlogik
- Besonders geeignet für teamfähige, skalierbare Cloud-Setups
Alternative: Pulumi (Infrastruktur as Code in klassischen Programmiersprachen aber höhere Komplexität).
Layered Terraform-Architektur
Die Infrastruktur wurde in zwei voneinander getrennte Terraform-Layer aufgeteilt:
- Base Layer: Definiert langlebige Grundressourcen wie VPC, Subnets und ECR-Repositories. Dieser Layer stellt das stabile Fundament der Infrastruktur dar und bleibt auch bei einem vollständigen Neuaufbau des Kubernetes-Clusters erhalten. Die Kosten hier sind nur minimal.
- EKS Layer: Definiert den kurzlebigen Teil der Infrastruktur, darunter EKS-Cluster, Managed Node Groups, ElastiCache sowie alle zugehörigen IAM-Rollen. Dieser Layer wurde während der Entwicklung mehrfach zerstört und neu erstellt.
Durch diese Trennung konnte der kostenintensive Teil der Infrastruktur gezielt kontrolliert werden, ohne grundlegende Ressourcen oder Container-Images zu verlieren.

Terraform State
Der Terraform-State wird in einem S3-Bucket gespeichert und durch DynamoDB-Locking abgesichert, um parallele Änderungen an der Infrastruktur zu verhindern. In der Praxis kam es jedoch vor, dass State Locks nach abgebrochenen terraform apply-Runs hängen blieben und manuell gelöst werden mussten. Zusätzlich traten Probleme mit verwaisten IAM-Rollen auf, die bei fehlgeschlagenen Deployments bereits in AWS existierten, aber nicht im Terraform-State erfasst waren. Diese Ressourcen mussten entweder importiert oder manuell bereinigt werden, um weitere Deployments durchführen zu können.
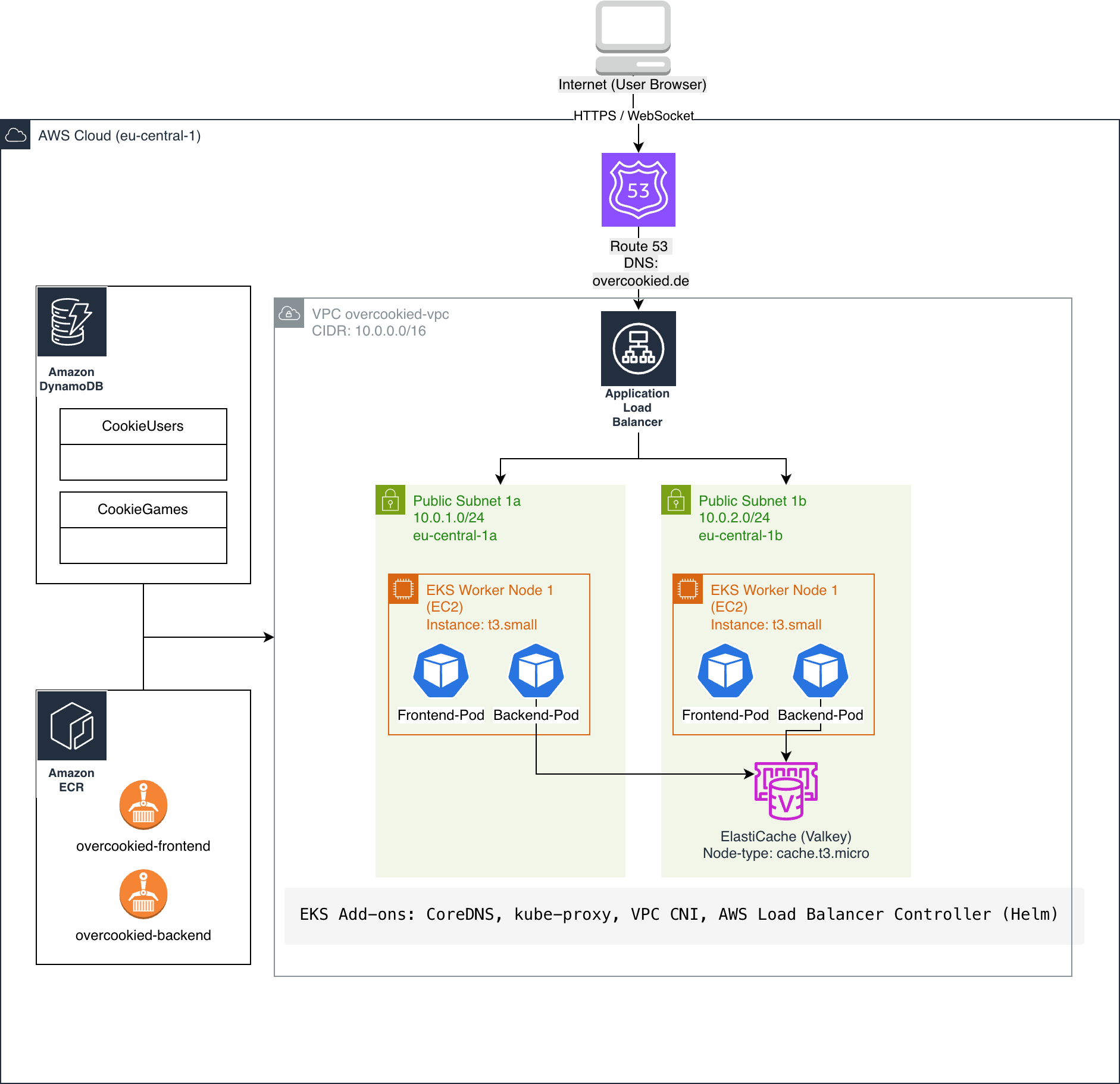
Herausforderungen
Herausforderungen mit der Queue (Distributed Matchmaking)
Solange die Anwendung nur in einer Instanz lief, funktionierte das Spiel. Der gesamte Flow über Login, Matchmaking und der Gameloop mit Cookie-Klicks und Timer war in sich geschlossen, weil alle Spieler auf demselben Prozess landeten. Doch Kubernetes skaliert horizontal. Sobald wir das Backend auf zwei Replicas hochfuhren, wurden Spieler nicht mehr gemachted. Hier kam die Idee auf, dass es an der In-Memory Queue liegen könnte.
Im Single-Pod funktionierte das Matchmaking so, dass ein Spieler eine JOIN_QUEUE-Nachricht sendete, die vom Backend in einer Variable gespeichert wurde. Betrat ein zweiter Spieler die Queue, war das Match gefunden. Das Problem trat auf, sobald das Backend in Kubernetes in zwei Pods gestartet wurde. Der Load Balancer verteilt eingehende WebSocket-Verbindungen per Round-Robin. Spieler A landete auf Pod A, Spieler B auf Pod B. Beide schickten eine JOIN_QUEUE-Nachricht, aber jeder Pod hatte seine eigene Queue. Pod A wartete auf einen zweiten Spieler, Pod B ebenfalls. Nach Durchsuchen der Logs, bestätigte sich der Verdacht: “Host pod missing players: hasP1=true, hasP2=false”. Die Hypothese war damit bestätigt: Das Matchmaking braucht einen gemeinsamen, Pod-übergreifenden State-Store.
Um das Umzusetzen, evaluierten wir mehrere Ideen:
- Sticky Sessions am Load Balancer: Das wäre die einfachste Variante, indem alle Spieler auf denselben Pod geroutet werden. Das hätte das Problem umgangen, aber nicht gelöst. Bei Skalierung auf mehrere Pods wäre das Matchmaking trotzdem nicht erfolgreich gewesen. Zudem sind in Kubernetes Pods temporär, da sie jederzeit “sterben” und neu starten können und damit der State innerhalb des Containers verloren gehen könnte.
- Matchmaking über die Datenbank (DynamoDB): DynamoDB war bereits im Projekt für Spielerprofile und Leaderboards integriert. Man hätte eine Queue-Tabelle anlegen und per Polling abfragen können. DynamoDB ist für Lese-/Schreiblatenzen im einstelligen Millisekundenbereich optimiert, was schnell genug wäre. Jedoch fehlen bei DynamoDB die passenden Primitive für eine Matchmaking-Queue. DynamoDB bietet keinen Pub/Sub, keinen nativen Lock und keine Sorted-Set-Semantik.
- Selbst gehostetes Redis auf einem Kubernetes Pod: Redis ist eine In-Memory-Datenbank, d.h. alle Daten werden im RAM gespeichert, nicht auf der Festplatte. Dadurch ist Redis extrem schnell mit Latenz im Sub-Millisekunden Bereich. Außerdem bietet Redis die Datenstrukturen sorted Sets, Pub/Sub und atomische Operationen, die für die Matchmaking-Queue benötigt werden. Man könnte einen eigenen Redis-Container im Cluster deployen. Damit hätte man die volle Kontrolle, aber es müsste die Persistenz konfiguriert, Monitoring einrichtet, Failover manuell gebaut und Updates selbst eingespielt werden. Für ein Uni-Projekt mit begrenztem Betriebsbudget war das ein zu großer Overhead.
- AWS ElastiCache als Managed Service: ElastiCache übernimmt die gesamte Infrastruktur: Provisioning, Patching, Monitoring, Backups. Seit 2024 unterstützt ElastiCache neben Redis auch Valkey, den Open-Source-Fork von Redis, der nach der Lizenzänderung von Redis Labs entstand. Valkey ist zu 100% API-kompatibel mit Redis, jeder Redis-Befehl funktioniert identisch. Und AWS rückt Valkey als Standard-Engine in ElastiCache in den Vordergrund und bietet es günstiger an als Redis.
Die Entscheidung fiel auf Option 4. Der Managed Service eliminiert operativen Aufwand, Valkey liefert alle Redis-Primitiven, und die Terraform-Integration erlaubt Infrastructure as Code.
Für die Umsetzung der Queue standen zwei Redis-Datenstrukturen zu Auswahl:
| Feature | List (LPUSH/RPOP) | Sorted Set (ZADD) |
| FIFO-Reihenfolge | Nativ | Via Score = Timestamp |
| Duplikat-Schutz | Nein | Ja |
| Flexibles Entfernen von Einträgen | Nur von den Enden | ZREM auf jedes Element |
| Suchen nach User | O(n) | via ZSCORE/ZRANGE |
Die entscheidenden Punkte waren das flexible Entfernen und der Duplikat-Schutz. Wenn ein Spieler disconnected, soll er aus der Queue entfernt werden, egal an welcher Position. Eine Liste erlaubt nur LPOP (links) oder RPOP (rechts), ein Element aus der Mitte zu entfernen erfordert LREM mit O(n)-Kosten und ohne Garantie auf Eindeutigkeit. Ein Sorted Set entfernt mit: ZREM jedes Element in O(log n), und doppeltes Einfügen desselben Spielers überschreibt den Score und erzeugt keinen doppelten Eintrag. Jeder Spieler wird mit einem Unix-Timestamp als Score in die Queue eingefügt. Dadurch entsteht eine FIFO-Reihenfolge. Der Matchmaking-Loop prüft alle 500ms, ob genügend Spieler in der Queue stehen. ZRANGE 0 1 liest die zwei ältesten Einträge, ZREM entfernt sie. Dann kann das Match erstellt werden.
Mit der gemeinsamen Queue war das Problem jedoch nicht behoben. Wenn Pod A zwei Spieler matcht und den Game Room erstellt, muss Pod B, auf dem einer der Spieler per WebSocket verbunden ist, davon erfahren. Dafür kamen zwei Ansätze in Frage:
- Polling: Jeder Pod fragt regelmäßig Redis, ob ein neues Match für seine lokalen Spieler existiert. Simpel, aber verschwenderisch, da 99% der Abfragen nichts liefern und die Latenz immer im halben Polling-Intervall liegt.
- Pub/Sub: Das ist Redis’ eingebautes Publish/Subscribe-System. Ein Pod published nach dem Fire-and-Forget Prinzip eine Nachricht auf einem Channel, alle subscribten Pods empfangen sie. Der Nachteil ist hier jedoch, dass verpasste Nachrichten (wenn ein Pod kurz offline ist) verloren gehen. Deshalb wird der Game State zusätzlich als Key in Redis gespeichert.
Wir verwenden zwei Channels:
| Channel | Zweck |
| `overcookied:match:notify` | Match gefunden → alle Pods prüfen, ob ein lokaler Spieler betroffen ist |
| `overcookied:game:events` | Laufende Game-Events: Clicks, Timer-Ticks, Golden Cookie Spawns, Game Over |
Beim Start subscribed jeder Pod auf beide Channels. Wenn ein Match gefunden wird, published der matchende Pod eine MatchNotification. Alle Pods empfangen die Notification und überprüfen, ob einer der Spieler lokal verbunden ist. Falls ja, sendet er eine GAME_START-Nachricht an dessen WebSocket. Im Gegensatz zum Single-Pod-Modell muss so kein Pod mehr beide Spieler kennen. Jeder Pod kümmert sich nur um seine lokalen WebSocket-Clients und reagiert auf Redis-Events.
Da alle Pods gleichzeitig alle 500ms den Matchmaking-Loop durchführen, kann es zu einer Race-Condition führen: Zwei Pods lesen gleichzeitig dieselben Spieler und erstellen zwei unabhängige Räume für dieselben beiden Spieler. Um das zu verhindern, wurde ein Distributed Lock eingesetzt, was mit Redis’ SetNX mit einer TTL von 2s umgesetzt wurde. SetNX schreibt den Key nur, wenn er noch nicht existiert. Der erste Pod, der den Lock erlangt, darf matchen. Alle anderen überspringen und versuchen es beim nächsten Tick. Die TTL von 2s ist ein Sicherheitsmechanismus. Falls der “lockende” Pod abstürzt, bevor er den Lock freigibt, läuft der Key automatisch ab. Damit werden Deadlocks verhindert.
Der Game State (Scores, Timer, Golden Cookies, Power-Ups) liegt jetzt nicht mehr im Arbeitsspeicher eines einzelnen Pods, sondern als JSON-String in Redis, mit einer TTL von 10 Minuten. Jede Game State Änderung liest den State aus Redis, modifiziert ihn und schreibt ihn atomar zurück. Die TTL stellt sicher, dass Game States nach Spielende automatisch aufgeräumt werden, auch wenn der Pod abstürzt. Für die atomaren Score-Updates wird Redis’ Optimistic-Locking-Mechanismus WATCH/MULTI/EXEC verwendet: WATCH beobachtet den Key. MULTI eröffnet eine Transaktion und EXEC führt alle in MULTI gesammelten Befehle atomar aus, aber nur wenn der beobachtete Key seit WATCH unverändert geblieben ist. Ändert ein anderer Pod den State zwischen WATCH und EXEC, schlägt die Transaktion fehl. Der Go-Redis-Client wiederholt sie anschließend automatisch. So gehen keine Klicks verloren, selbst wenn zwei Spieler auf verschiedenen Pods im selben Moment klicken.
Dasselbe Prinzip wird beim Golden-Cookie-Claim angewendet: Beide Spieler klicken gleichzeitig, aber innerhalb der Transaktion wird überprüft, ob der Cookie noch aktiv ist. Nur der erste Claim geht durch, der zweite wird verworfen.
Herausforderungen bei Deployment & Authentication
Hilfsskripte für Deployment
Zur Vereinfachung des Infrastruktur- und Deployment-Prozesses wurden mehrere Hilfsskripte erstellt. Diese kapseln wiederkehrende Aufgaben, stellen die korrekte Reihenfolge sicher:
Build-&-Push-Skript: Baut die Docker-Images für Frontend und Backend und pushed diese automatisiert in die Amazon Elastic Container Registry. Dadurch stehen versionierte Images für das Kubernetes-Deployment zur Verfügung.
Application-Deployment-Skript: Deployed die Anwendung vollständig in das Kubernetes-Cluster. Das Skript erstellt Namespace, Secrets, Deployments, Services und Ingress-Ressourcen und wartet auf abhängige Komponenten wie den Application Load Balancer.
Destroy-Skript: Fährt den EKS-Layer kontrolliert herunter. Kubernetes-Ressourcen werden zuerst entfernt, bevor Terraform den Cluster zerstört, sodass Cloud-Ressourcen sauber aufgelöst und Kosten vermieden werden.
Weitere Skripte unterstützen den Bootstrap der Terraform-State-Infrastruktur sowie die Aktualisierung von DNS- und OAuth-Konfigurationen nach einem Cluster-Neuaufbau.
Externe Authentifizierung dynamischer Infrastruktur
Für die Authentifizierung wurde Google OAuth 2.0 eingesetzt, um eine sichere Benutzeranmeldung zu ermöglichen und gleichzeitig auf die Implementierung eines eigenen Login-Systems verzichten zu können. Die App wurde in der Google Cloud Console registriert, feste Redirect-Routen definiert und das Backend so aufgebaut, dass nach erfolgreicher Authentifizierung ein JWT ausgestellt wird, welches im Frontend gespeichert und für weitere API-Zugriffe verwendet wird. Im lokalen Entwicklungsumfeld lief dieser Ablauf problemlos. Frontend und Backend wurden jeweils als einzelne Instanz betrieben, Redirect-URLs waren statisch und der gesamte OAuth-Flow wurde innerhalb eines Prozesses abgewickelt.
Problem: Mit dem Übergang in den produktionsnahen Betrieb änderte sich diese Ausgangslage. Die Infrastruktur wurde vollständig über Terraform verwaltet und der EKS-Cluster regelmäßig neu aufgebaut. Dabei wurde bei jedem Cluster-Neustart automatisch ein neuer Application Load Balancer (ALB) erstellt, dessen öffentliche URL sich änderte. Zusätzlich lief das Backend nun mit mehreren Pods, sodass Requests nicht mehr garantiert von derselben Instanz verarbeitet wurden. Zusätzlich waren JWTs nicht pod übergreifend validierbar, da jeder Pod ein eigenes Secret verwendete.
Lösung:
- Einführung einer eigenen Domain (overcookied.de), die unabhängig von der dynamischen ALB-Adresse bleibt und als stabiler Endpunkt für OAuth-Redirects dient.
- Verwaltung der Domain über Route 53 und HTTPS-Terminierung über ACM, sodass die öffentliche URL dauerhaft konstant bleibt.
- Umstellung des OAuth-State-Handlings auf HTTP-Cookies, um den Authentifizierungsprozess stateless und pod unabhängig zu gestalten.
- JWT-Secrets als Kubernetes Secret, dass alle Backend-Pods Tokens konsistent signieren und validieren können.
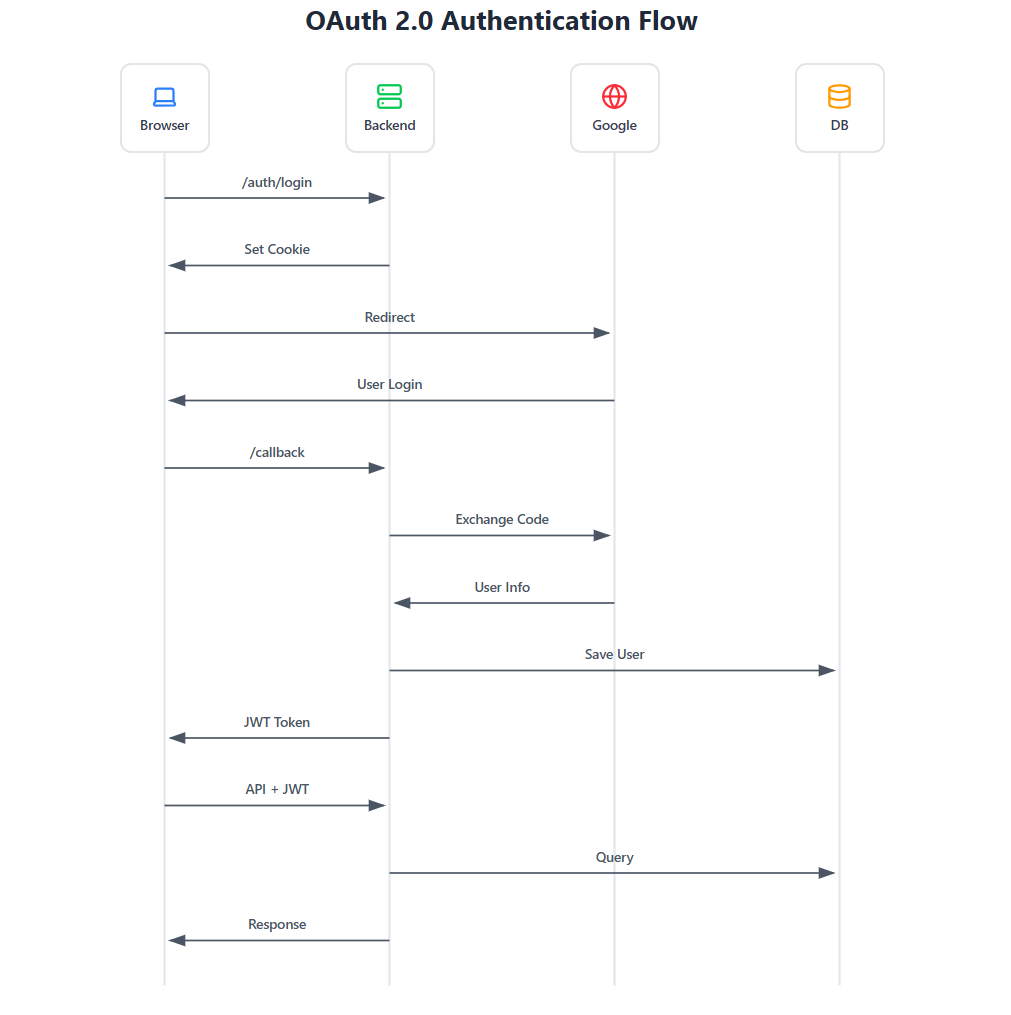
Auf diese Weise ließ sich Google OAuth zuverlässig in eine dynamische, verteilte Cloud-Infrastruktur integrieren und das ursprüngliche Ziel eines automatisierten, reproduzierbaren Betriebs ohne manuelle Nacharbeit bei jedem Cluster-Neustart beibehalten.
Rückblickend wäre eine selbst implementierte Benutzeranmeldung mit verschlüsselter Speicherung der Nutzerdaten vermutlich schneller umzusetzen gewesen. Ebenso hätte man den Application Load Balancer als langlebige Komponente behandeln und bei Cluster-Neustarts beibehalten können, um stabile öffentliche URL zu haben. Die Entscheidung für die Custom Domain ermöglichte jedoch wertvolle praktische Erfahrungen mit weiteren AWS-Services.
Lessons Learned
Next.js NEXT_PUBLIC_* .env Variablen sind Build-Zeit-Konstanten: Die Variablen werden beim Build fest in den JavaScript-Bundle kompiliert und können nicht mehr durch Umgebungsvariablen, bspw. währendes des Kubernetes-Deployments, gesetzt werden. Unser Frontend sprach in “Production” immer noch localhost:8080 an, weil erst im Kubernetes-Deployment eine Umgebungsvariable NEXT_PUBLIC_API_URL=https://api.overcookied.de gesetzt wurde. Alle “Production” Variablen müssen vor dem Build gesetzt werden.
Go-Maps und Concurrency: Fatal Crash ohne Warnung: Go-Maps sind nicht thread-safe. Concurrent Read + Write crasht den Prozess sofort und unwiderruflich, ohne Recover-Möglichkeit. Jede Map, die von mehreren Goroutines berührt wird, braucht einen sync.Mutex.
Nur weil es lokal läuft, heißt das noch lange nicht, dass es in einem Kubernetes Cluster läuft: Mit einem einzigen Pod funktioniert alles wie bei einem lokalen Build. Sobald wir auf 2+ Replicas skalierten, funktionierte das Matchmaking nicht mehr. Wir hätten Von Anfang an “distributed-first” denken und uns häufiger fragen sollen: “Was passiert, wenn ein zweiter Pod läuft?”. Außerdem hätten wir frühzeitig mit Minikube und mehreren Replicas testen müssen, was uns sehr viel Arbeit gespart hätte. So mussten wir einen großteil unserer Backend Architektur ändern und von grundauf neu programmieren.
Terraform ist Komplex, aber der Aufwand rentiert sich: Terraform hat eine steile Lernkurve, aber einmal aufgesetzt ist die gesamte Infrastruktur reproduzierbar, versioniert und per Befehl zerstörbar. Zudem ist es so einfacher, den Anbieter zu wechseln (bspw. von AWS zu Azure).
WebSockets in Kubernetes = Stateful vs Stateless: WebSockets sind langlebige, stateful Verbindungen, wohingegen Kubernetes für Stateless HTTP optimiert ist. Pod-Neustarts killen Verbindungen, Load Balancing wird ungleichmäßig, und zwei Spieler im selben Game können auf verschiedenen Pods landen.
Komplexität von AWS: AWS bietet für jedes Problem einen Managed Service, aber die Komplexität ist enorm. IAM allein mit Policies, Roles, Trust Relationships, IRSA und OIDC Providern fühlt sich wie eine eigene Ausbildung an. Dazu kommen noch die endlose Anzahl an veschiedenen Services von AWS. Wir haben uns ein Semester mit AWS beschäftigt und haben das Gefühl, immernoch and der Oberfläche zu kratzen. Jedoch hat sich AWS zum Lernen von Cloud-Engineering gelohnt.
Security by Design: Jede Architekturentscheidung hat Security-Implikationen, die sich später nur schwer korrigieren lassen. Wir hätten ein Security-Review als festen Schritt vor jedem Deployment einplanen und generell früher und mehr Testen müssen. Außerdem gehören Secrets nie in Code oder ConfigMaps, sondern immer in Kubernetes Secrets oder AWS Secrets Manager.
Leave a Reply
You must be logged in to post a comment.