1. Einleitung
“Moorhuhn”, wer erinnert sich nicht? Damals auf Windows XP, in der Mittagspause oder nach der Schule, mit dem Fadenkreuz über den Bildschirm und auf pixelige Hühner geballert. Für uns war Moorhuhn eines dieser Spiele, das man eigentlich nie alleine spielen wollte. Man saß vor dem Rechner, jemand schaute über die Schulter, und am Ende wurde verglichen: “Ich hatte 210 Punkte!” – “Ja klar, du hast aber auch das goldene Huhn erwischt.”
Was Moorhuhn gefehlt hat? Ein echtes Multiplayer-Erlebnis. Nicht nur Highscores vergleichen, sondern gleichzeitig auf dieselben Hühner schießen, sich im Score-Ranking live messen und das ganze direkt im Browser, ohne Installation, ohne Download.
So entstand Morehuehner: Ein Moorhuhn-Remake mit Echtzeit-Multiplayer, gebaut als Cloud-Native-Anwendung mit Kubernetes. Die Idee klingt erstmal simpel. Die Umsetzung? Die hatte es in sich.
Unser Tech-Stack im Überblick:
- Web-Frontend: Next.js mit React und Tailwind CSS
- Lobby-Server: Socket.IO auf der Bun-Runtime
- Game-Server: Socket.IO auf der Bun-Runtime
- Lobby-Discovery-Service: Elysia.js (ebenfalls Bun-nativ)
- Monorepo-Management: Turborepo mit Bun Workspaces
- Orchestrierung: Kubernetes mit Kustomize
Jeder dieser Services ist ein eigenständiger Microservice, containerisiert und unabhängig skalierbar. Die hohe Skalierbarkeit erreichen wir durch Kubernetes, da verschiedene Microservices je nach Last unabhängig voneinander horizontal skaliert werden können. Das macht unser Projekt cloud-native: nicht nur “irgendwie in der Cloud”, sondern architektonisch darauf ausgelegt, die Stärken von Container-Orchestrierung voll auszunutzen.
2. Anforderungen
Bevor wir losgelegt haben, mussten wir uns erstmal einig werden: Was soll das Ding eigentlich können? Was muss es können und was nicht? Wir haben unsere Anforderungen in zwei Kategorien aufgeteilt.
Funktionale Anforderungen
- Multiplayer: Bis zu 4 Spieler schießen gleichzeitig auf Hühner in derselben Spielrunde. Kein Singleplayer-Modus mit Highscore-Vergleich, sondern echtes Echtzeit-Multiplayer.
- Realtime-Gameplay: Latenz gering genug für ein gutes Spielerlebnis. Bei einem Shooter zählt jede Millisekunde, denn wenn man klickt und das Huhn erst eine halbe Sekunde später reagiert, macht das keinen Spaß.
- Lobby-System: Spieler sollen sich in Lobbys zusammenfinden können, bevor eine Runde startet. Beitreten, Ready-Status, automatischer Countdown bei voller Lobby.
- Magazin- und Nachlade-Logik: 8 Schuss pro Magazin, dann manuell nachladen. Das zwingt zu taktischem Spielen, man kann nicht einfach wild draufhalten.
- Verschiedene Seltenheitsstufen: Normale Hühner (10 Punkte), schnelle Hühner (25 Punkte) und seltene Bonus-Hühner (50 Punkte). Schnellere Hühner sind schwerer zu treffen, geben aber mehr Punkte.
Nicht-funktionale Anforderungen
- Cloud-Native: Die gesamte Architektur soll auf Container-Orchestrierung mit Kubernetes ausgelegt sein.
- Horizontal skalierbar: Mehr Spieler? Mehr Pods. So einfach soll es sein, zumindest in der Theorie.
- Lokal ausführbar: Kein AWS-Account, keine Cloud-Kosten zum Entwickeln. Alles läuft mit Minikube auf dem eigenen Rechner.
- Kein Login-System: Website öffnen, Name eingeben, spielen. Keine Registrierung, keine Passwörter. Der Fokus lag auf dem Spiel und der Infrastruktur, nicht auf User-Management.
- Moderner Tech-Stack: TypeScript von vorne bis hinten, Bun als Runtime, Turborepo als Monorepo-Tool. Wir wollten mit aktuellen Technologien arbeiten, nicht mit einem Legacy-Setup.
- Serverseitige Validierung: Treffer werden auf dem Server validiert. Der Client schickt die Klick-Koordinaten, der Server prüft ob tatsächlich ein Huhn in Reichweite war. Kein Cheaten durch manipulierte Client-Events.
3. Unsere Cloud Challenge
Ursprünglich hatten wir einen klaren Plan: Deployment auf AWS. Kubernetes-Cluster in der Cloud, eigene Domain, das volle Programm. Wir hatten schon die Architektur im Kopf: EKS, Load Balancer, etc.
Doch dann kam die harte Realität: AWS-Account-Sperre, unklare Kostensituation, und plötzlich standen wir ohne Cloud-Infrastruktur da. Der Worst Case für ein Projekt, das “Cloud-Native” sein soll.
Der Pivot war schnell beschlossen: Lokales Deployment mit Minikube. Statt sich mit dem AWS-Support herumzuschlagen, bauen wir alles so, dass es lokal auf dem eigenen Rechner läuft. Natürlich trotzdem mit denselben Kubernetes-Konzepten, die auch in einer echten Cloud-Umgebung zum Einsatz kommen.
Und das ist der entscheidende Punkt: Minikube ist kein “Spielzeug-Kubernetes”. Es nutzt dieselben APIs, dieselben Ressourcentypen, denselben NGINX-Ingress-Controller. Unsere Deployments, Services, ConfigMaps und RBAC-Regeln sind identisch zu dem, was auf einem echten Cluster laufen würde. Der einzige Unterschied ist die Umgebung: statt us-east-1 heißt es minikube. Die Kubernetes-Konzepte und die Probleme, die wir lösen mussten, bleiben exakt dieselben.
4. Grundlagen
Kubernetes
Kubernetes ist ein Container-Orchestrierungssystem. Es verwaltet, wo und wie Container laufen, skaliert sie bei Bedarf und sorgt dafür, dass sie nach einem Absturz automatisch neu gestartet werden. Für unser Projekt nutzen wir folgende Konzepte:
- Deployments: Definieren, wie viele Instanzen (Pods) eines Services laufen sollen. Unser Lobby-Deployment startet z.B. mit 3 Replicas. Jeder Pod ist eine eigenständige Lobby.
- Services: Stellen eine stabile Netzwerk-Adresse für eine Gruppe von Pods bereit. Wir nutzen sowohl normale ClusterIP-Services (für Ingress-Routing) als auch Headless-Services (
clusterIP: None) für die direkte Pod-Discovery. - Ingress: Der “Eingang” von außen in den Cluster. Unser NGINX-Ingress routet
/zum Web-Frontend,/api/*zum Discovery-Service,/lobby/socket.io/*zum Lobby-Service und/game/socket.io/*zum Game-Service. - ConfigMaps: Zentrale Konfiguration für alle Services, Ports, Game-Settings und die Redis-URL. Alles an einem Ort, statt in jedem Pod einzeln.
- ServiceAccounts + RBAC: Unser Lobby-Discovery-Service braucht Zugriff auf die Kubernetes-API, um Pod-IPs abzufragen. Dafür bekommt er einen eigenen ServiceAccount mit einer Role, die nur
endpointslesen darf (Principle of Least Privilege).
Warum Kustomize? Wir brauchen verschiedene Konfigurationen für verschiedene Umgebungen: lokal (Minikube) mit reduzierten Replicas und imagePullPolicy: Never, und Production mit Autoscaling und höheren Ressourcen-Limits. Kustomize löst das elegant mit Base-Manifests und Overlays, ohne Templates oder Helm-Charts.
Minikube
Minikube startet einen vollwertigen Kubernetes-Cluster in einer lokalen VM oder einem Docker-Container. Für uns ist es das perfekte Tool für lokale Entwicklung:
minikube docker-env: Lässt das lokale Docker-CLI direkt gegen den Docker-Daemon innerhalb von Minikube arbeiten. Heißt: Wir bauen unsere Images einmal und sie sind sofort im Cluster verfügbar, ohne Registry, ohne Push.minikube tunnel: Erstellt einen Netzwerk-Tunnel, damit der Ingress-Controller von außen erreichbar ist. So können wir im Browser aufhttp://morehuehner.localzugreifen.- Ingress-Addon: Minikube bringt einen NGINX-Ingress-Controller als Addon mit. Ein
minikube addons enable ingressund das Routing funktioniert.
Unser Setup-Skript dev-k8s.sh automatisiert den gesamten Prozess: Minikube starten, Docker-Env konfigurieren, alle vier Images bauen, Kubernetes-Manifeste anwenden und warten, bis alle Deployments ready sind.
Next.js
Next.js ist unser Frontend-Framework: React-basiert, mit Server-Side-Rendering und dateibasiertem Routing. Für Morehuehner nutzen wir es primär als Client-Side-App: Die Lobby-Auswahl, die Lobby-View und das Game-Canvas sind alles React-Komponenten, die über Socket.IO-Client mit den Backend-Services kommunizieren. Der Turbopack-Dev-Server macht die lokale Entwicklung angenehm schnell.
Socket.IO
Socket.IO ist unsere Wahl für die Echtzeit-Kommunikation. Es abstrahiert WebSocket-Verbindungen, bietet Rooms (für Lobby- und Game-Sessions), automatische Reconnects und, ganz wichtig, den Redis-Adapter für Multi-Pod-Sync. In der lokalen Entwicklung nutzt es den Polling-Fallback, im Kubernetes-Modus erzwingen wir reinen WebSocket-Transport, um Probleme mit Sticky-Sessions zu umgehen.
Elysia.js
Elysia ist ein ultraschnelles HTTP-Framework für die Bun-Runtime. Unser Lobby-Discovery-Service braucht keine WebSocket-Verbindungen, er beantwortet einfache REST-Requests: Lobby-Liste abrufen, Game-Server-Status abfragen, den am wenigsten ausgelasteten Game-Pod für eine neue Runde zuweisen. Elysia ist dafür perfekt: minimaler Overhead, schnelle Cold-Starts, TypeScript-nativ.
Redis
Redis dient bei uns als Pub/Sub-Backbone für die Cross-Pod-Kommunikation der Lobby-Server. Über den @socket.io/redis-adapter können alle Lobby-Pods Events austauschen, ohne sich gegenseitig direkt zu kennen. Lokal, ohne Kubernetes, wird Redis nicht benötigt. Der Adapter wird nur aktiviert, wenn die Umgebungsvariable REDIS_URL gesetzt ist.
5. Deployment-Setup
Kustomize-Struktur
Unser Kubernetes-Setup folgt dem Kustomize-Muster mit drei Schichten:
k8s/
├── base/ # Shared Manifests
│ ├── configmap.yaml
│ ├── deployment-game.yaml
│ ├── deployment-lobby.yaml
│ ├── deployment-lobby-discovery.yaml
│ ├── deployment-redis.yaml
│ ├── deployment-web.yaml
│ ├── ingress.yaml
│ ├── rbac.yaml
│ ├── service-*.yaml
│ └── kustomization.yaml
├── overlays/
│ ├── minikube/ # Lokale Entwicklung
│ │ └── kustomization.yaml
│ └── production/ # Autoscaling, HPAs
│ ├── hpa-game.yaml
│ ├── hpa-lobby.yaml
│ └── kustomization.yaml
Die Base definiert alle Ressourcen mit sinnvollen Defaults. Das Minikube-Overlay reduziert Replicas (2 Lobbys, 1 Game-Pod, 1 Web-Pod) und setzt imagePullPolicy: Never, damit Minikube die lokal gebauten Images nutzt. Das Production-Overlay fügt HorizontalPodAutoscaler hinzu und skaliert die Ressourcen-Limits hoch.
Key Features unseres Deployments
- 1 Lobby-Pod = 1 Lobby: Jeder Lobby-Pod verwaltet genau eine Lobby mit eigenem In-Memory-Zustand. Mehr Lobbys? Einfach
kubectl scale deployment/lobby --replicas=5. - N Games pro Game-Pod: Game-Pods können mehrere Spielrunden gleichzeitig hosten. Die
GameManager-Klasse verwaltet eineMap<string, GameRoom>. Jeder Room ist eine laufende Partie. - Sticky Sessions: NGINX Ingress setzt Affinity-Cookies (
LOBBY_AFFINITY,GAME_AFFINITY), damit Folge-Requests eines Spielers beim selben Pod landen. - Headless Services für Pod-Discovery:
lobby-headlessundgame-headlessServices mitclusterIP: Nonegeben der Endpoints-API die tatsächlichen Pod-IPs zurück, statt eine virtuelle ClusterIP. Der Discovery-Service nutzt das, um jeden Pod einzeln anzusprechen. - Dynamische Game-Allocation: Wenn eine Lobby voll ist, fragt der Lobby-Pod den Discovery-Service nach dem Game-Pod mit der geringsten Auslastung. Der Discovery-Service sortiert alle Game-Pods nach Anzahl aktiver Rooms und gibt den besten Kandidaten zurück.
- Downward API: Pod-Name und Pod-IP werden über die Kubernetes Downward API als Umgebungsvariablen injiziert. So kennt jeder Pod seine eigene Identität.
Ingress-Routing
Unser Ingress besteht aus vier Regeln, die den gesamten Traffic intelligent verteilen:
# Frontend (catch-all)
- path: / → service: web (Port 3000)
# REST API (Discovery)
- path: /api(/|$)(.*) → service: lobby-discovery (Port 3010)
# Lobby WebSocket
- path: /lobby/socket.io/ → service: lobby (Port 3002)
# Game WebSocket
- path: /game/socket.io/ → service: game (Port 3001)
Alle WebSocket-Pfade bekommen extra Annotations für Proxy-Timeouts (3600s), HTTP/1.1 und Sticky-Sessions. Der rewrite-target sorgt dafür, dass /lobby/socket.io/ als /socket.io/ beim Lobby-Pod ankommt, die Server erwarten den Standard-Socket.IO-Pfad.
6. Problem #1: WebSockets und Horizontal Pod Autoscaling
Das Problem
Horizontal Pod Autoscaling klingt erstmal nach einer sauberen Architektur. Ist es auch, bis man WebSockets ins Spiel bringt.
WebSocket-Verbindungen sind stateful und langlebig. Ein Spieler verbindet sich mit einem Lobby-Pod, und ab diesem Moment hält dieser Pod den Zustand für diesen Spieler im Speicher: Name, Ready-Status, Lobby-ID. Das widerspricht der Grundannahme von Kubernetes: alle Pods sind austauschbar.
Konkret sieht das Problem so aus:
- Spieler A will Lobby
abcbeitreten, die aufPod 1läuft. - Der WebSocket-Connect geht durch den Ingress, der per Round-Robin einen Pod auswählt.
- Spieler A landet auf
Pod 2, dem falschen Pod. Pod 2hat keine Ahnung von Lobbyabc, weil der Zustand nur aufPod 1existiert.
Der Sticky-Cookie LOBBY_AFFINITY greift zu spät, er wird erst nach dem initialen Request gesetzt. Aber zu diesem Zeitpunkt ist der Spieler bereits am falschen Pod gelandet.
Autoscaling verschärft das Ganze zusätzlich: Der HPA kann jederzeit Pods herunterfahren, wodurch bestehende WebSocket-Verbindungen und der gesamte In-Memory-Zustand verloren gehen.
Wie wir es diagnostiziert haben
Debugging war zäh. In der Web-Oberfläche zeigten sich Inkonsistenzen: Manchmal funktionierte ein Join, manchmal nicht. Der Lobby-Status flackerte. Spieler tauchten auf und verschwanden wieder. Das Tückische: Es funktionierte manchmal, nämlich genau dann, wenn der Round-Robin zufällig den richtigen Pod traf. In der lokalen Entwicklung mit nur einem Pod war das Problem unsichtbar.
Wir haben gelernt: Oft führen viele verschiedene Probleme zu einem Fehlerbild, was das Debugging extrem schwer und zäh macht. Erst als wir anfingen, die Pod-Logs aller Lobby-Instanzen gleichzeitig zu beobachten, wurde klar, dass die Requests am falschen Pod ankamen.
Mögliche Lösungsansätze
Wir haben drei Optionen evaluiert:
Option A: Redis Adapter mit Event-Forwarding
Der @socket.io/redis-adapter verbindet alle Lobby-Pods über Redis Pub/Sub. Die Grundidee: 1 Pod = 1 Lobby bleibt erhalten, der Zustand bleibt lokal im Speicher. Aber wenn ein Event am falschen Pod ankommt, leitet dieser es per serverSideEmit über Redis an den richtigen Pod weiter. Broadcasts werden über Redis an alle Sockets im Room zugestellt, egal auf welchem Pod sie physisch verbunden sind.
Ein Nachteil: Es muss ein zusätzlicher Service verwendet werden, der weitere Ressourcen allokiert.
Option B: StatefulSets mit Ingress-Mapping
Das Lobby-Deployment wird zu einem StatefulSet mit festen Pod-Namen (lobby-0, lobby-1, …). Pro Pod ein eigener Service und Ingress-Pfad (/lobby-0/socket.io/). Das Frontend verbindet sich direkt zum richtigen Pod-Pfad. Nachteil: Die Ingress-Konfiguration muss bei jeder Skalierung angepasst werden, das skaliert nicht.
Option C: Agones (Game-Server-Orchestrator)
Googles Open-Source-Framework für dedizierte Game-Server auf Kubernetes. Verwaltet automatisch IP-Zuordnung pro Session. Nachteil: Hohe Komplexität, eigenes CRD-Ökosystem, Overkill für ein Lobby-System.
Unsere Lösung: Option A
Wir haben uns für den Redis-Adapter entschieden. So funktioniert der Flow:
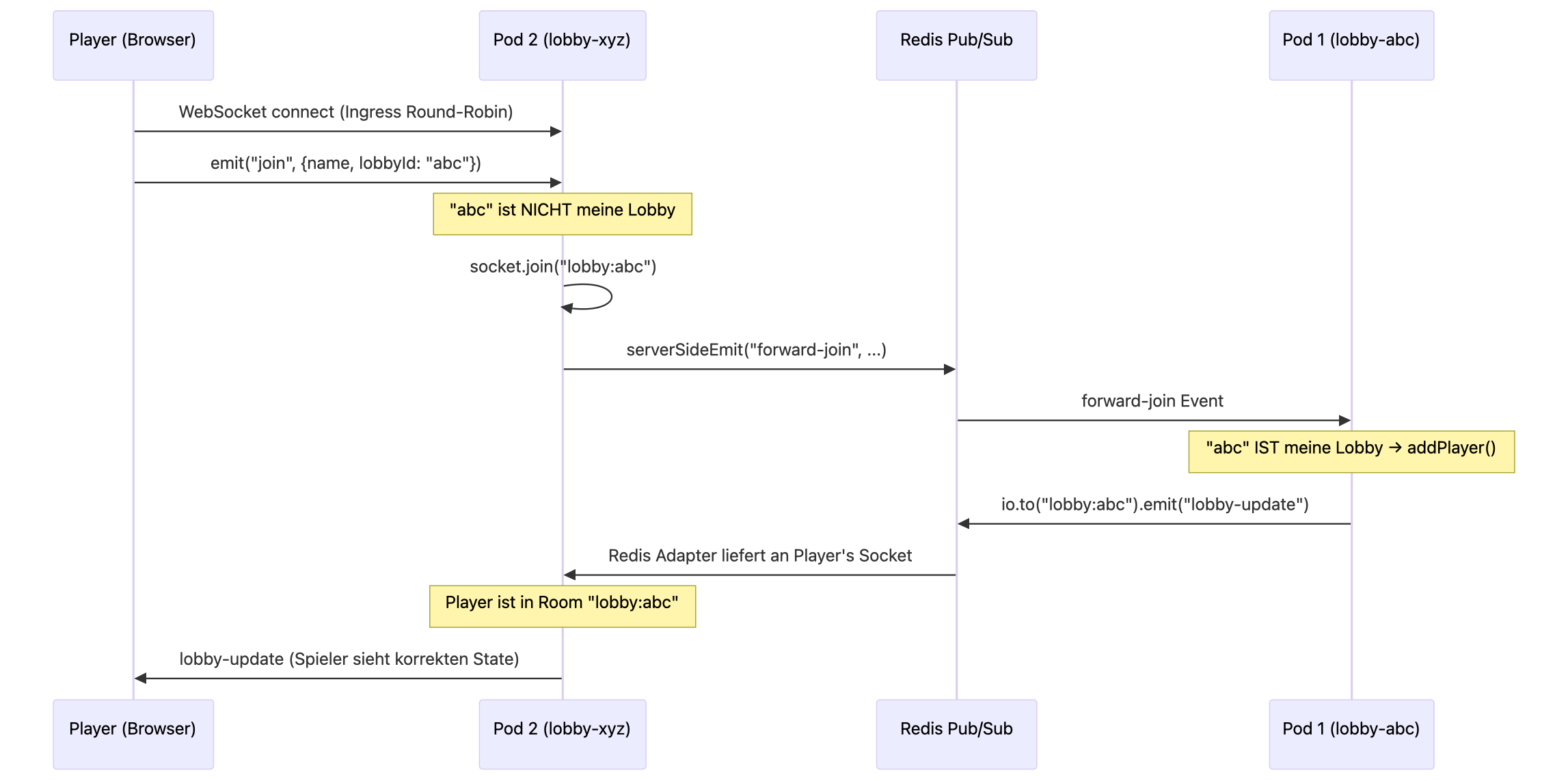
Der entscheidende Mechanismus in der index.ts des Lobby-Servers: Beim join-Event prüft der Pod, ob die angeforderte lobbyId zu seiner lokalen Lobby gehört. Falls ja, wird lokal verarbeitet. Falls nein, tritt der Socket trotzdem dem Socket.IO-Room bei (damit Broadcasts ihn erreichen) und das Event wird per serverSideEmit über Redis an alle anderen Pods weitergeleitet. Der Pod, der die Lobby besitzt, verarbeitet das Event dann lokal.
Dasselbe Forwarding-Pattern implementieren wir für ready, leave und disconnect Events.
Ein weiteres Detail, das uns Stunden gekostet hat: WebSocket-Only im K8s-Modus. Socket.IO nutzt standardmäßig ein Upgrade-Verfahren. Erst HTTP-Polling, dann WebSocket-Upgrade. In Kubernetes ist das ein Problem, weil die initialen Polling-Requests nicht garantiert beim selben Pod landen, selbst mit Sticky-Sessions. Die Lösung: Im K8s-Modus erzwingen wir transports: ['websocket'] auf der Client-Seite, um den Polling-Fallback komplett zu umgehen. Lokal bleibt Polling als Fallback aktiv.
Und das Beste: Lokal funktioniert alles ohne Redis. Der Adapter wird nur aktiviert, wenn REDIS_URL gesetzt ist. In der lokalen Entwicklung gibt es kein Cross-Pod-Problem und kein Redis nötig.
Was wir gelernt haben
Entwickelt man wirklich “Cloud Native” ohne Abstraktionsebenen wie AWS Lambda Functions oder verwaltete Message-Queues, muss man solch komplexe Probleme selbst angehen. Nicht alle Technologien verstehen sich von Haus aus mit den Architekturprinzipien von Cloud-Native-Umgebungen. Außerdem: WebSocket-Verbindungen und ihre Details, plötzlich bewegt man sich auf Netzwerkebene und muss verstehen, wie HTTP-Upgrades, Cookies und Load-Balancer zusammenspielen.
7. Problem #2: Pod-Hopping (Von der Lobby zum Game-Server)
Das Problem
Die Lobby läuft, alle Spieler sind ready, der Countdown zählt herunter … und dann? Alle Spieler müssen von ihrem Lobby-Pod zu einem Game-Pod wechseln. Aber welchem? Und wie stellt man sicher, dass alle im selben Game-Room landen?
Die Herausforderungen:
- Game-Server-Auswahl: Welcher Game-Pod hat noch Kapazität? Game-Pods können mehrere Rooms gleichzeitig hosten. Wir wollen den am wenigsten ausgelasteten Pod wählen.
- Verbindungsdaten-Weitergabe: Die Spieler müssen wissen, wohin sie sich verbinden sollen. Host, Port und eine gemeinsame Game-ID.
- Sauberer Übergang: Die WebSocket-Verbindung zur Lobby muss getrennt und eine neue zum Game-Server aufgebaut werden, ohne dass der User etwas davon merkt.
Wie wir es diagnostiziert haben
Anfangs hatten wir einen statischen Fallback: Alle Lobbys schickten ihre Spieler zum selben Game-Server (GAME_SERVICE_HOST). Funktionierte lokal mit einem Pod. In Kubernetes mit mehreren Game-Pods? Chaos. Manche Spieler landeten auf Pod A, andere auf Pod B. Verschiedene Pods, verschiedene Room-Maps, verschiedene Spielrunden.
Die Lösung
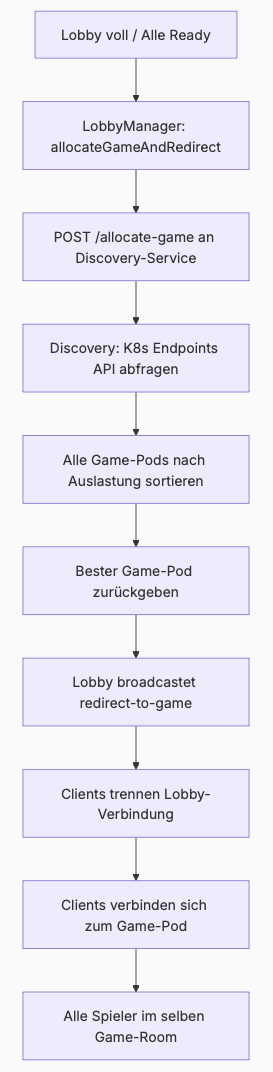
Der Flow sieht so aus: Wenn alle Spieler ready sind (oder die Lobby voll ist), startet der LobbyManager den Countdown. Nach Ablauf ruft er allocateGameAndRedirect() auf:
Game-Allocation über den Discovery-Service: Der Lobby-Pod sendet einen POST-Request an
/allocate-gamedes Lobby-Discovery-Services. Dieser fragt über die Kubernetes Endpoints-API alle Game-Pods ab, ruft deren/health-Endpoint auf (der die Anzahl aktiver Rooms zurückgibt) und sortiert nach Auslastung. Der Pod mit den wenigsten aktiven Rooms wird zurückgegeben.Broadcast der Verbindungsdaten: Der Lobby-Pod generiert eine Game-ID und broadcastet ein
redirect-to-game-Event an alle Spieler im Room. Das Event enthältgameId,host,portund ein Token.Client-seitiger Redirect: Im Frontend empfängt die
LobbyView-Komponente dasredirect-to-game-Event. Sie setzt einisRedirecting-Flag (damit der Disconnect-Handler nicht den State löscht), speichert die Game-Server-Daten, wechselt die View auf dasGameCanvasund trennt die Lobby-Verbindung. DasGameCanvasbaut dann eine neue Socket.IO-Verbindung zum Game-Server auf und joined mit derselben Player-ID und Game-ID.
Das Zusammenspiel der Services macht den Lobby-Discovery-Service zum zentralen Koordinator: Er kennt alle Pods (über Headless-Services und die Endpoints-API), er kennt deren Auslastung (über die Health-Endpoints) und er trifft die Entscheidung, welcher Pod herausgesucht wird.
Für die Kubernetes-API-Zugriffe hat der Discovery-Service einen eigenen ServiceAccount mit einer RBAC-Role, die ausschließlich endpoints in der morehuehner-Namespace lesen darf, nicht mehr.
Was wir gelernt haben
Service-Discovery ist in Kubernetes kein Selbstläufer. Man muss sich aktiv entscheiden, wie Pods sich gegenseitig finden. Headless Services, Endpoints-API, RBAC, das sind alles Puzzleteile, die man zusammensetzen muss. Wenn das System jedoch einmal steht, ist die Implementierung elegant: Neue Game-Pods tauchen automatisch in der Discovery auf, ohne dass irgendwo eine Konfiguration angepasst werden muss.
8. Lessons Learned und Fazit
Was wir über Kubernetes und Minikube gelernt haben
Minikube 1st, Cloud 2nd. Lokales Prototyping mit Minikube hat unsere Feedback-Loops massiv verkürzt. Statt auf Cloud-Deploys zu warten, konnten wir in Sekunden rebuilden, redeployen und testen. Unser dev-k8s.sh-Skript baut alle vier Images und rollt das Deployment in unter zwei Minuten aus. Für ein Uni-Projekt, bei dem man abends nochmal schnell was ausprobieren will, ist das Gold wert.
WebSockets + Kubernetes = tricky. WebSocket-Verbindungen sind langlebig und stateful, während Kubernetes für stateless HTTP-Traffic konzipiert ist. Diese Grundproblematik hat uns mehr Stunden gekostet als jedes andere Problem im Projekt. Sticky Sessions allein reichen nicht aus. Man benötigt ein Forwarding-Konzept und muss den Transport-Layer verstehen.
Ops-Aufwand > Implementation. Das Schreiben des eigentlichen Game-Codes, also Chicken-Spawning, Hit-Detection und Score-Berechnung, war vergleichsweise einfach. Die GameManager-Klasse hat klare Zuständigkeiten und war in wenigen Wochen fertig. Das Containerisieren, Deployen und zum Laufen Bringen der Services in Kubernetes hat ein Vielfaches an Zeit verschlungen. Dockerfile-Optimierung, Ingress-Debugging, RBAC-Konfiguration, Redis-Setup. Das alles summiert sich.
Cloud vs. Lokal: Trade-offs
Als AWS wegfiel, hat uns Minikube gerettet. Aber es hat Grenzen: Es gibt kein echtes DNS, kein TLS mit Let’s Encrypt und keine echte Netzwerk-Latenz zwischen Nodes. Unser System ist auf echte Cloud-Bedingungen vorbereitet und das Production-Overlay mit HPAs und erhöhten Ressourcen-Limits existiert bereits. Den letzten Beweis, dass es unter Last auf einem echten Cluster funktioniert, können wir jedoch noch nicht liefern.
Würden wir es wieder so machen?
Ja, mit Einschränkungen. Die Microservice-Architektur hat sich bewährt. Da Lobby und Game völlig unterschiedliche Skalierungsmuster haben (1 Pod = 1 Lobby vs. N Rooms pro Game-Pod) und sauber getrennt sind, wurde das Debugging trotz aller Komplexität vereinfacht. Turborepo mit geteilten TypeScript-Typen war ein Segen. Dass dieselben Interfaces auf Client und Server vorhanden sind, eliminiert eine ganze Kategorie von Bugs.
Was wir anders machen würden: Wir würden früher mit Redis und Multi-Pod-Setups testen, statt erst am Ende die Kubernetes-Probleme zu entdecken. Und vielleicht hätten Agones von Anfang an evaluiert werden sollen, nicht für die Lobby, aber für die Game-Server.
Tipps für andere
- Startet mit Minikube. Nicht mit der Cloud. Baut euer Setup lokal, versteht die Kubernetes-Konzepte, und deployt erst in die Cloud, wenn ihr ein funktionierendes lokales Setup habt.
- Plant für Multi-Pod von Tag 1. Wenn euer Service Zustand im Speicher hält und ihr plant, ihn horizontal zu skalieren, denkt sofort über Cross-Pod-Kommunikation nach. Nicht erst, wenn die erste Demo vor der Tür steht.
- Headless Services sind eure Freunde. Für jede Art von Service-Discovery innerhalb des Clusters:
clusterIP: Noneund die Endpoints-API geben euch direkten Zugriff auf einzelne Pod-IPs. - Testet mit mehreren Pods. Mit einem Pod funktioniert alles. Die echten Probleme tauchen erst auf, wenn Load-Balancing ins Spiel kommt.
9. Ausblick
Mögliche Erweiterungen
- User-Management: Login, Accounts, persistente Highscores. Aktuell sind die Daten weg, wenn der Pod stirbt.
- Powerups: Mehr Gameplay-Tiefe. Doppelte Punkte, Slow-Motion, Rapid Fire. Der
GameManagermit seinem Tick-basierten Game-Loop wäre dafür gut vorbereitet. - Metrics Dashboard: Prometheus + Grafana für Serverlast, aktive Rooms, Spieleranzahl pro Pod. Die Health-Endpoints existieren bereits. Man müsste sie nur in ein Prometheus-Format bringen.
Wie könnte man es auf echtes Cloud-Deployment vorbereiten?
Der Sprung von Minikube in eine echte Cloud-Umgebung ist kleiner als man denkt:
- Domain und DNS einrichten: Eine echte Domain registrieren, DNS-Records auf den Cluster zeigen. Der Ingress unterstützt bereits Host-basiertes Routing.
- Kubernetes-Cluster aufsetzen: Entweder über einen KaaS-Anbieter (Managed Kubernetes wie GKE, EKS oder DigitalOcean Kubernetes) oder für die Mutigen: ein selbst verwalteter Cluster mit Talos Linux auf eigener Hardware.
- Deployment: Unser Production-Overlay anwenden, eine Container-Registry einrichten (statt der lokalen Minikube-Images), TLS-Zertifikate über cert-manager und los geht’s.
Die Architektur steht. Die Kubernetes-Manifeste sind bereit. Was fehlt, ist der letzte Schritt.
Leave a Reply
You must be logged in to post a comment.