Month: August 2018
YourTube – A simple video platform in you personal amazon cloud
During the Dev4Cloud Levture i created a simple static webpage that uses Amazons S3 service for Hosting and video storage and amazons cognito for user authentification and role managemant.
Tweets by Donnie - Building a serverless sentiment analysis application with the twitter streaming API, Lambda and Kinesis
tweets-by-donnie dashboard Thinking of Trumps tweets it’s pretty obvious that they are controversial. Trying to gain insights of how controversial his tweets really are, we created tweets-by-donnie. “It’s freezing and snowing in New York — we need global warming!” Donald J. Trump You decide if it’s meant as a joke or not. But wouldn’t it be…
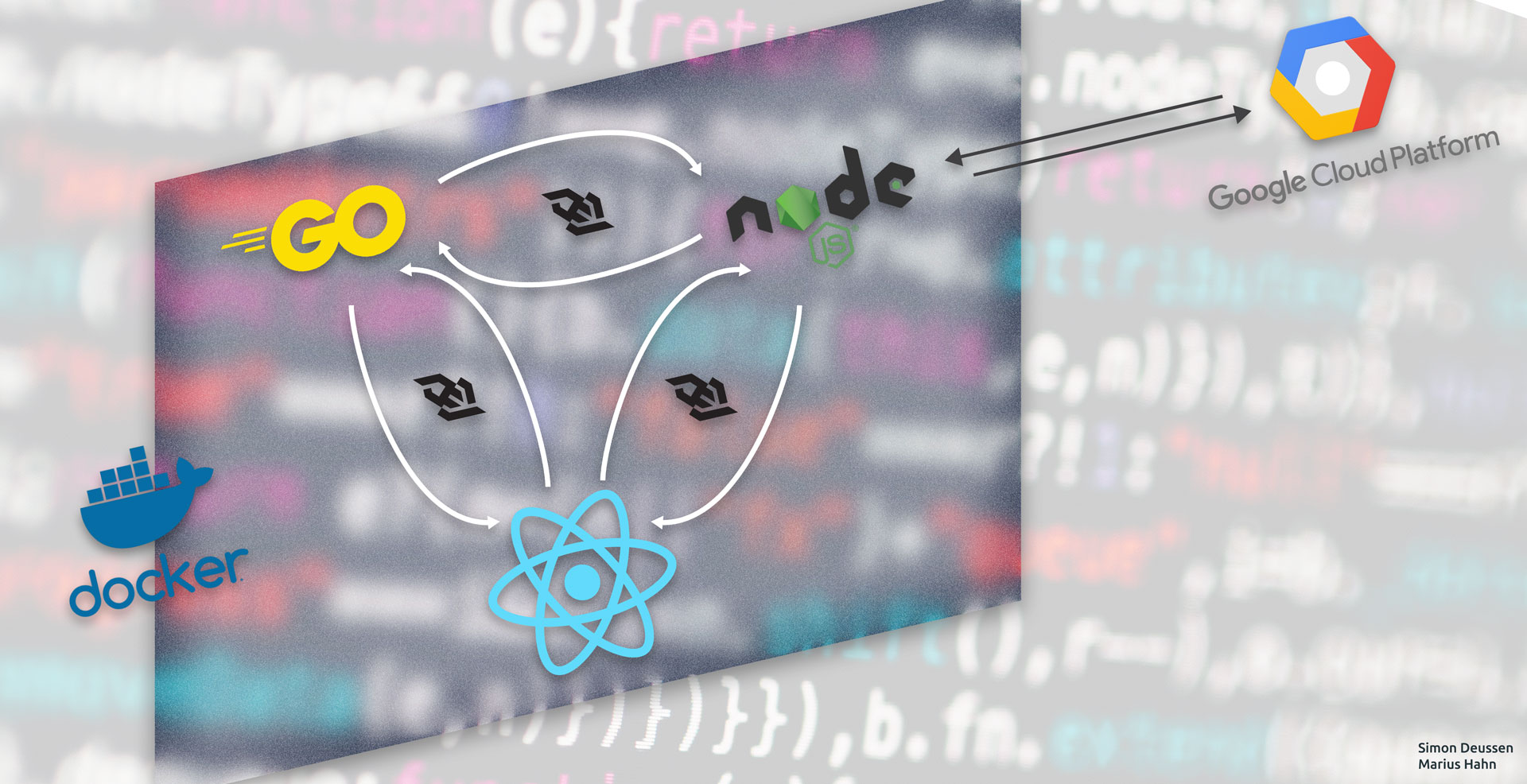
Using the power of google cloud API: A dockerized node app counting words in prasentations.
For the Dev4Cloud lecture at HdM Stuttgart, we created a simple Go/NodeJS/React App, which helps people to keep track of often used words during presentations. In a presentation setting, most people tend to use too many fill words and to train against this, we want to introduce our presentation counter to you.
Building a Serverless Web Service For Music Fingerprinting
Building serverless architectures is hard. At least it was to me in my first attempt to design a loosely coupled system that should, in the long term, mean a good bye to my all-time aversion towards system maintenance. Music information retrieval is also hard. It is when you attempt to start to grasp the underlying…
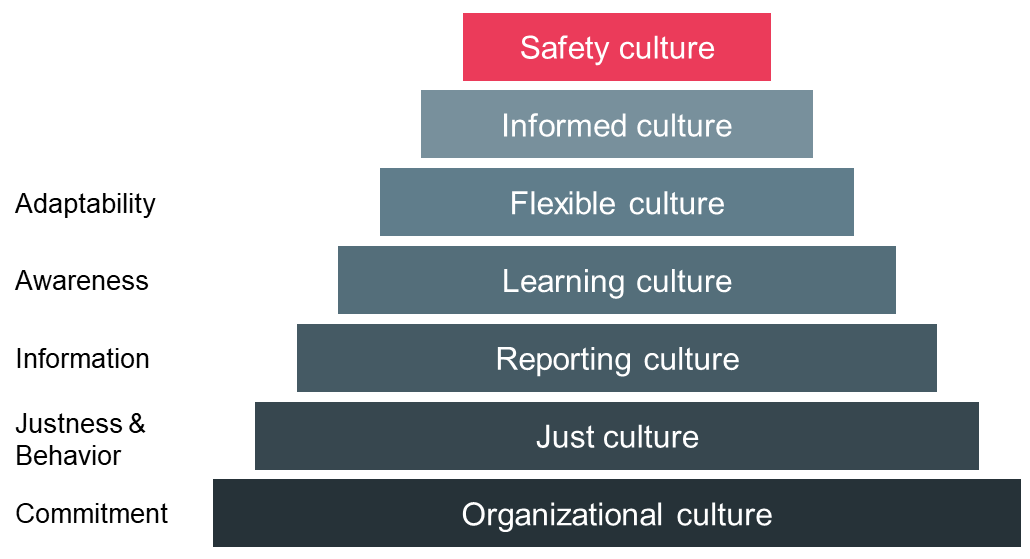
Safety Culture – Improve “the way we do things around here”
The safety culture of an organization is the key indication of its performance related to safety. It incorporates the visible rules, norms and practices as well as the implicit factors such as values, beliefs and assumptions. That is why the safety culture reflects “the way we do things around here” which is the most precise…
Smart Meter
Smart meters are a controversial topic in Germany. Still there are no certified products available although the roll out was planned at the beginning of 2018. Security breaches can affect customer data as well as the safety of the energy net. That’s why there are very strict security guidelines provided by the BSI. Several smart…
Why AI is a Threat for our Digital Security
Artificial intelligence has a great potential to improve many areas of our lives in the future. But what happens when these AI technologies are used maliciously? Sure, a big topic may be autonomous weapons or so called “killer robots”. But beside our physical security – what about our digital one? How the malicious use of…
Cloud security tools and recommendations for DevOps in 2018
Introduction Over the last five years, the use of cloud computing services has increased rapidly, in German companies. According to a statistic from Bitkom Research in 2018, the acceptance of cloud-computing services is growing. Cloud-computing brings many advantages for a business. For example, expenses for the internal infrastructure and its administration can be saved. Resource…
Usability and Security
Usability and Security – Is a tradeoff necessary? Usability is one of the main reasons for a successful software with user interaction. But often it is worsened by high security standards. Furthermore many use cases need authentication, authorisation and system access where high damage is risked when security possibilities get reduced. In this article the…
Security in Smart Cities
Today cities are growing bigger and faster than ever before. This results in various negative aspects for the citizens such as increased traffic, pollution, crime and cost of living, just to name a few. Governments and city administrations and authorities are in need to find solutions in order to alleviate these drawbacks. Over the past…
You must be logged in to post a comment.