When I was invited to a design thinking workshop of the summer school of Lucerne – University of Applied Sciences and Arts, I made my first experience with the end user interaction part of Industry 4.0. It was an awesome week with a lot of great people and made me interested in the whole Industry 4.0 theme. So when we did projects in the lecture of cloud development I was sure to do a production monitoring project.
Industry 4.0
Before we talk about the Project itself, we should talk about the artificial word Industry 4.0. Industry 4.0 is meant to be part of the fourth industrial revolution and originated from a German strategy project. Where as computer earlier had mostly executional tasks, like painting robots in the automobile sector, the focus now changed to more observing and strategic decision making tasks.
From a computer science point of view we got three major points to cover regarding the factory and product. It is important, that we’re not talking about user analytics in a marketing kind of way.
Production Monitoring is about increasing the efficiency. We are collecting any data from the manufacturing itself and store it in a database. With the information we can
- check if our deviation exceeds a certain threshold
- make a more accurate expected profit calculation independent for every product
- sort them into different quality’s and increase the yield of high quality products through matching parts
End user interaction is about the services we offer with our products. For example if we produce large coffee machines for cafes, we might want to add an app to find our machines, pre-order and online pay the coffee. This will keep our customers happy and is a bonus reason to buy the product.
Usage analytics is the most important part and the reason why Industry 4.0 is sometimes called disruptive (A technology is called disruptive if it is so much better in something that it will repress every other technology in this field). We are trying to understand how the customers are using our product, to develop a better fitting successor. It is a chance and a threat, because if you are realizing that 90% of your customers are using only 2 of 10 features of your product, but the other 8 features cost 80% of your development founds than you know what to do. If you realize that you’re loosing customers because your competitor usage analytics is bearing fruits and you have not started with your own yet, then you will have a hard time, because it will take at least 2 product iterations to get a feeling for what your customers want.
In summary in Industry 4.0 we try to get as much information as we can to be more efficient and create better fitting products.
Production monitoring project:
My project was a proof of concept production monitoring software. I wanted to show how easy it is to create such a program and what are the things to keep in mind. I used multiple Raspberry Pi to simulate production machines, wrote a java back-end, deployed it as a Amazon Web Services (AWS) Lambda function (serverless function) and deployed a Maria DB.
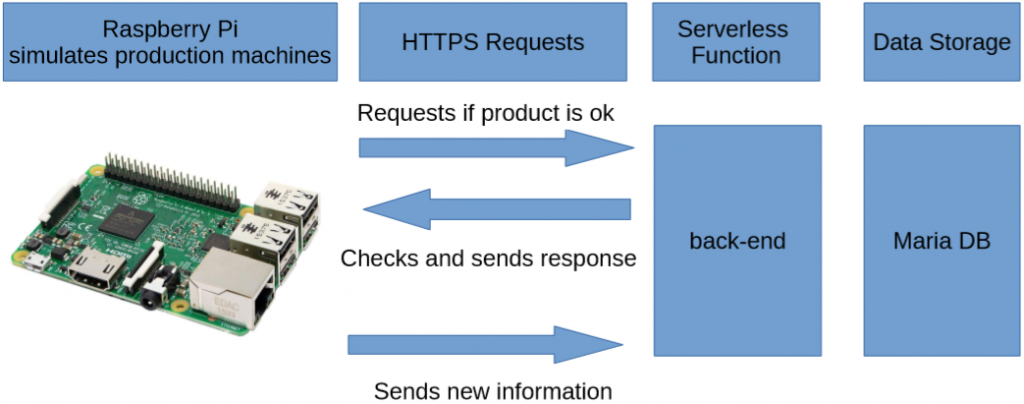
The python scripts running on the Raspberry Pi clients where creating fake deviation data and sending requests to the back-end à la “add a new product”, if it was the first in a production row, “add manufacturing step deviation ” and, if it was not first in a row “is the product still OK for the next step?” The back-end received the requests, got the data from the DB, calculated if the product should be continued to be build or recycled (only a deviation threshold check for simplicity) and sent the response back. This may sound pretty standard and indeed it was not much of a problem. The problems started with AWS.
Lets have a closer look at the AWS architecture. Amazon Web Services offers a lot of micro services that are developed by many teams. A instance of a service is called a resource and resources are referred by there unique arn (Amazon resource name). Every resource that is doing something has to have a role. A role is a summary of privileges that that resource can do. A Bucket is a primitive data storage and a Stack is a collection of resources.
When we want to deploy a Lambda function in java we have to upload the java code to the S3 bucket, create a stack which contains a reference to the uploaded code, starting it as a resource and add a gateway. It is important to keep in mind, that we are using 4 different AWS to host and use our serverless function.
Development walk through, Problems and Solutions :
Amazon Web Services offers micro services, developed by many teams simultaneously. Due the rapid change things were different in the time I played with the AWS for the first time in May and the start of the clean build in July and the provided examples seemed to be outdated and not working.
There are two ways of developing AWS Lambda function. First you can use the plugin AWS Toolkit for Eclipse or IntelliJ, or you can install the aws cli and the sam cli. Both require Docker. Docker needs windows hyper-v to work, a feature that is not included in win 10 home by standard but can be downloaded extra. The Problem is, Docker does not check if hyper -v is enabled, it does only check for win 10 pro. So you have to install hyper-v, change the registry entry to win 10 pro, install docker, switch it back to home and hope that no other program is making decision based on that registry entry during that time. The other concern is, Docker needs your clear admin password to work.
The next thing is the free AWS education account. You have an account at awseducate.com not at aws. To login in the AWS console, or to get your credentials to deploy your code you have to login at awseducate and they will redirect you. You can not create or modify roles, you are only allowed to use the AWS standard preset roles and that is quite a mess to begin with.
Next we should have a short look at the directory structure of an AWS lambda project. These structures are created if you either call sam cli init or create a new AWS Lambda project in IntelliJ.
StackDirectory
|-HelloWorldAWSExampleProject
| |-pom.xml
| |-default stuff
|
|-template.yamlAnd a look at the current yaml file:
Resources:
ProductionMonitoringFunction:
Type: AWS::Serverless::Function # More info about Function Resource: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#awsserverlessfunction
Properties:
FunctionName: ProductionMonitoring
Role: arn:aws:iam::631016394235:role/ProductionMonitoringIAM
CodeUri: ProductionMonitoring/target/ProductionMonitoring-1.0-SNAPSHOT-jar-with-dependencies.jar
Handler: de.hdm.mi.MainClass::handleRequest
Runtime: java8
Environment: # More info about Env Vars: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#environment-object
Variables:
dbUrl:
Ref: dbUrl
dbUsername:
Ref: dbUsername
dbPassword:
Ref: dbPassword
Events:
ProductionMonitoringAPI:
Type: Api # More info about API Event Source: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#api
Properties:
Path: /productionmonitoring
Method: get
.
.
.
Parameters:
dbUrl:
Type: String
Description: db url
NoEcho: true
dbUsername:
Type: String
Description: db username
NoEcho: true
dbPassword:
Type: String
Description: db username
NoEcho: trueAs you can see, every resource you want to deploy in this yaml file has to be listed or referred to. If you list it, you have to give it a name (ProductionMonitoringFunction), a type (AWS::Serverless::Function) and properties. Those properties are a function name, a role (privileges), CodeURI (where the root directory of the source code is) and handler (where to find the entry function). You can also add parameters for you environment, mark them as secrete and read them in while deploying or keep them in a private secondary yaml file you refer to. The dilemma is, the lambda example itself is only writing the project folder name as CodeURI input and sam cli is not able to find the handler there unless you add a /.
Serverless Application Model command line interface (sam cli) is a tool adding the support of serverless function debugging to the aws cli. It is able to invoke a function (to create a local instance for debugging reasons), to create a package and to deploy the package to the cloud. When you add add the slash to the CodeURI something interesting happens. First you are able to call the invoke functionality, but then you realize, that it does only translate and execute the code you already translated and executed with IntelliJ. The next questionable thing is, even if you preparing your code with IntelliJ, calling sam cli package and sam deploy to deploy your package in the cloud, it will fail there, because sam cli seems to not add the dependencies to the package, even though it is their only reason for existence. At this point you have to use maven to create a jar file with dependencies, set the CodeURI to the new created file and deploy that.
Now we have your Lamba function deployed and the only thing missing is the gateway to access it. With the standard yaml file configuration we already created a gateway listening on the GET method, we just need to deploy it to a stage. The AWS gateway addresses are created like that:
https://sj8utl768f.execute-api.eu-central-1.amazonaws.com/live/productionmonitoringWe have a gateway specific prefix (here “sj8utl768f”), the execute-api part, the region where it is hosted (here Frankfurt), the stage name (live) and the name of your Lambda function.
A stage is basically a set of rules that are applied to every function in in it. The rules are for example how many simultaneous requests are allowed, the logging threshold for the gateway and so on. The strange problem here was, even the deployed gate way was not reachable, it always failed with error code 403 forbidden, even though there was no access regulation active. Sadly the education account did not allow to set an CloudWatch (the AWS logging service) arn in my account settings and because of that there was no possibility to log and have a closer look on it. When I created a completely new one with the same settings it worked.
Summary and Outlook:
This was the first time I had to use python, my first serverless function project, the first AWS related project and my first practical Industry 4.0 project. There were a lot of things to learn (and still are) and many many problems to solve (I only mentioned the biggest ones) but I’m still happy about the outcome of this project.
In regards of the production monitoring there are a few things to consider:
- Distance matters! If you have to wait a second for each request it will stall your production.
- Don’t use atomic requests, as it will skyrocket your waiting time
- Don’t use auto incrementing fields
- Save every information you can – it’s cheap and you may want it in a few years
- Try to connect product creation information, product usage information and information about defects to get a better feeling for your production
The next thing I want to do is to use an AWS SQL DB instead of the self hosted, use terraform instead of sam cli and check the different possibility’s of a normal AWS account. Also I would like to set up the production monitoring in a kubernetes environment to check the effects of a company’s decision to not host their data in a cloud or save there db credentials there.
Leave a Reply
You must be logged in to post a comment.