
In the past couple of years research in the field of machine learning (ML) has made huge progress which resulted in applications like automated translation, practical speech recognition for smart assistants, useful robots, self-driving cars and lots of others. But so far we only have reached the point where ML works, but may easily be broken. Therefore, this blog post concentrates on the weaknesses ML faces these days. After an overview and categorization of different flaws, we will dig a little deeper into adversarial attacks, which are the most dangerous ones.
Overview and Categorization
To get an idea of what attack surfaces a ML model provides it makes sense to remind the key concepts of information security: confidentiality, integrity and availability (CIA).
Availability
Regarding availability a ML model faces the same challenges as any other system. For example, it must somehow prevent DoS (Denial of Service)-Attacks. In addition, ML models can become unavailable or at least useless in noisy environments. E.g. your smart assistant can’t understand you if it is too loud around you. A different example could be a security scan that checks irises or faces to grant access somewhere. If the lens of the scanner is polluted the ML model won’t recognize anyone and no one could gain access.
Confidentiality (Privacy and Fairness)
In the context of ML confidentiality is usually referred to as ‘privacy’. It means that the system must not leak any information to unauthorized users. This is especially important for ML models that make decisions based on personal information like making a disease diagnose based on a patient’s medical records. Attackers could try to steal some information either by recovering it from the training data or by observing the model’s prediction and inferring additional information from it by knowing how the model acts. Both has been shown to be possible. Since the attacker tries to find out more about the model and the belonging data these attacks are sometimes also called ‘exploratory attacks’. The more the attacker already knows about a possible victim from other sources the more powerful such an attack can become. With enough additional information it is even possible to gain insight about a person if the training data was anonymized. Luckily there are also countermeasures available. For example, PATE provides differential privacy which means it can guarantee a specified amount of privacy when it is used to train a ML model.
Another issue where ML has shown that it is not robust at all is quite related to privacy: Fairness. For a ML model to be unfair it does not even take an adversary. All it needs is biased train data to make a ML model sexist or racist. This article contains a few examples like a North Indian bride classified as ‘performance art’ and ‘costume’. As countermeasures they recommend annotating train data with meta data describing where the data comes from, who labelled it etc. so everyone can easily check if the data is suitable for a specific use case. It might also be helpful to debug your data e.g. using XAI (EXplainable Artificial Intelligence) especially influential instances to find possible biases. If a bias is found it is possible to (re-) train a model giving more weight to a group that is underrepresented in the data. There are tools supporting this like IBM’s AI Fairness 360.
Integrity
An adversary attacking the integrity of a ML model tries to alter its predictions from the intended ones. Depending on when an attacker tries to manipulate the model there are different attacks possible. With an integrity attack at training time the adversary tries to poison the training data by altering, adding or removing samples or labels in a way that the model trained on it will make false decisions later. This is probably most dangerous for online learning models that are trained more and more on all new data. An example where this clearly went wrong was Microsoft’s chatbot Tay, which was intended to learn to tweet like a 19-year-old girl but quickly became racist and genocidal when some trolls started to train it. A different example could be a ML based IDS (Intrusion Detection System) that slowly gets trained by an attacker to accept his behavior as usual. Countermeasures could comprehend debugging training data, keep that data safe and most important meaningful input validation to online learning models.
Although they can be dangerous integrity attacks at training time are not such a high risk to a ML model, simply because integrity attacks during inference (test- or runtime) are so much easier. Therefore, the rest of this blog post is dedicated to these so called ‘adversarial samples’.
Adversarial Examples
Basics
Adversarial examples are input samples to ML models that are slightly perturbed in a way that causes the model to make wrong decisions. Those perturbations usually are indistinguishable to humans but often make the model fail with a high confidence value. In the image below the original image of the panda on the left is correctly classified by the model. Then a small amount of the noise displayed in the middle is added to the image resulting in the adversarial sample on the right, which is classified as a gibbon by the model.

How bad is it?
Admittedly, misclassifying a panda as a gibbon might not seem very dangerous, but there are plenty of examples where adversaries could cause serious damage. Thinking of self- or assisted-driving cars, misclassifying traffic signs is pretty dangerous. One might also think that an attacker would still have to get into the car’s systems to perturb the pixels of each input image, but this is not the case since adversarial samples got physical. Small stickers on a stop sign are sufficient to make it invisible to a ML model.

Robust Physical-World Attacks on Deep Learning Visual Classification
Small stickers on the road even made Tesla’s autopilot drive into oncoming traffic. It is also possible to fool ML models with printed out and then photographed adversarial samples as described in ‘Adversarial Examples in the Physical World‘. A different kind of sticker admittedly is way more remarkable to humans but has a dangerous effect anyway. For a ML model it turns almost everything it classifies into a toaster!
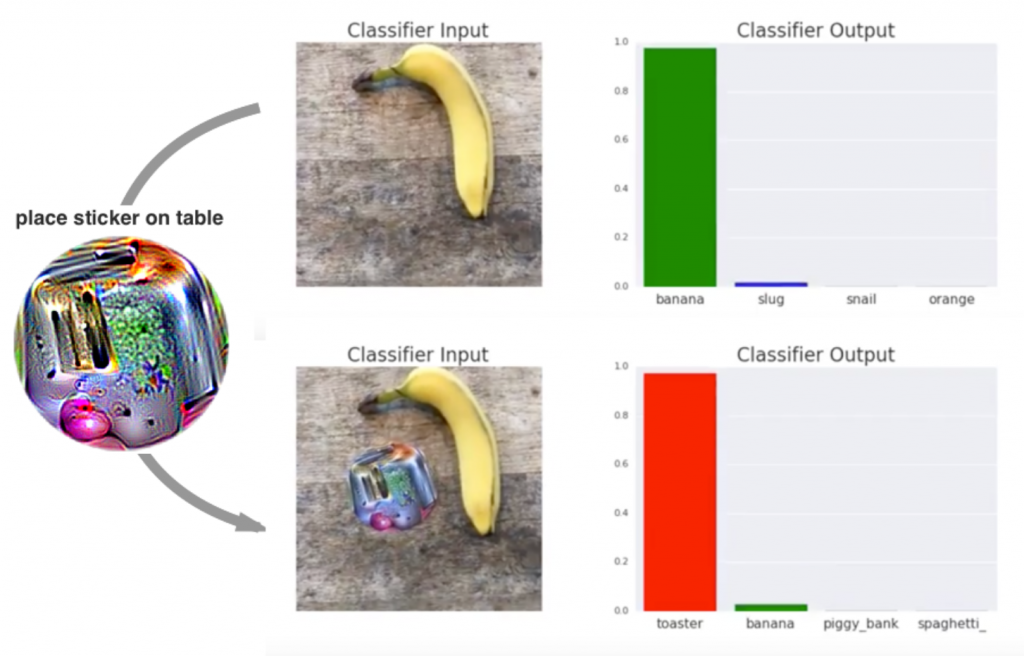
Even though all these ML models only classify 2D images it is possible to fool them using 3D objects. The 3D-printed toy turtle displayed below is classified as a riffle independent of the angle the ML model takes a look at it. The other way around a riffle classified as a toy would be seriously dangerous at any security scans based on ML.

Synthesizing Robust Adversarial Examples
We’ve already seen quite a lot of dangerous possibilities and use cases for adversarial samples, although so far we have only looked at a single domain: object classification. Thinking about other domains like text classification adversarial samples that try to evade spam detection are a common use case. All you need to know is where to insert some typos to fool the ML based spam filter. Also, audio adversarial samples are getting more common. They can fool any ‘smart’ assistant by adding some noise to actual speech or hiding speech commands in music in ways that humans can’t tell the original song from the perturbed one. You can listen to examples here and there.
Categorization of attacks
Adversarial attacks can be grouped into different categories based on some criteria. There are white box attacks that assume the attacker has full insight to the model and all its learned parameters. Usually this is not the case and the internals of a ML model are kept secret which makes the attack a black box attack.
Besides this categorization by the attacker’s knowledge adversarial attacks can also be categorized based on the attacker’s goal into targeted and non-targeted attacks, where targeted attacks try to misclassify an original sample into a specific class, while non-targeted attacks just aim to classify the adversarial sample into any other class than the original sample actually belongs to.
Both kinds of categorization are more detailed or named differently in some sources e.g. grey box attacks or source target attacks are considered as well, but this would go into too much detail for now.
Why isn’t there an effective defense, yet?
There are multiple reasons why adversarial samples are hard to defend against and therefore stay very dangerous. The first one to mention is that there are plenty of ways to craft those samples. Not every way of creating the samples enables an attacker to any kind of attack. Every way of crafting adversarial samples can be applied to white box scenarios. Currently the CleverHanslibrary for testing models against adversarial samples contains 19 different attacks and there are more described somewhere and just not (yet) added to the library. Black box models are a bit more but anyway there are possibilities to attack them. Usually the transferability of adversarial samples gets exploited. This means that an attacker can train its own substitute model with the results from a few queries sent to the black box model or a similar train dataset, then craft adversarial samples using this substitute model and finally apply those samples to the original model. In
‘Practical Black-Box Attacks against Machine Learning‘ it has been shown that the black box is quite likely to be fooled by adversarial samples crafted with a substitute model of the same domain. Another possibility is fingerprinting the black box model to find possible weaknesses like it is done in ‘Practical Attacks against Transfer Learning‘.
Another reason for the lack of a defense mechanism capable to prevent all the possible adversarial attacks is that a theoretical model of the adversarial example crafting process is very difficult to construct. Most adversarial sample crafting processes solve complex optimization problems which are non-linear and non-convex for most ML models. Usually they try to minimize the probability that a source sample belongs to its actual label (for non-targeted attacks) or maximize the probablity that a source sample belongs to a specific target class. At the same time a constraint is used to keep the adversarial sample similar to the source sample. For example, the Euclidean distance between both can be kept under a specified threshold. In the case of images this would lead to an adversarial image where every pixel can be modified but only by a small amount. A different example is keeping the number of modified pixels under a threshold. This even enabled the One-Pixel-Attack, where only a single pixel is modified to misclassify an image. The lack of proper theoretical tools to describe the solution to these complex optimization problems makes it very difficult to make any theoretical argument that a particular defense will rule out a set of adversarial examples.
What can we do anyway?
The authors of ‘Wild Patterns: Ten Years After the Rise ofAdversarial Machine Learning‘ applied three golden rules of cyber security to ML: know your adversary, be proactive and protect yourself.
To know your adversary, you have to model possible threats for your application. Therefore, you should think of the attacker’s goals, his knowledge and capabilities. Looking at self-driving cars as an example, one possible goal could be to compromise the integrity of the model and make it misclassify traffic signs. A different goal could be to make the car pull over and stop and therefor attack the availability of the ML model. The knowledge refers to the different categories explained before: usually you keep your model’s internals secret and make it a black box. Anyway if you used a public dataset for training like cityscapes for the self-driving car example, an attacker could at least guess that. The attacker’s capabilities could be limited to modifying physical objects like traffic signs or he could manage to bypass other security mechanisms and then manipulate the input between the car’s sensors and its ML model.
Being proactive (instead of reactive) means that you actively test your system and check it for weak points instead of waiting for an attacker to show them to you. You can use libraries like CleverHans to run different attacks against your model and see how well they perform. Unfortunately testing gives you only a lower bound telling you ‘your model fails at least for these samples’. Verification methods that give an upper bound to definitely tell how robust a ML model is against adversarial samples aren’t available, yet. (see this blog post for more information about verification and testing of ML). Even current certification tools like IBM’s CNN-Cert can only provide lower bounds. Anyway testing is much better than doing nothing and can be very helpful to find weaknesses. Another thing you can do is trying to better understand a model’s decision making by applying XAI. Even if the model has a high accuracy meaning it makes lots of correct decisions, it is not gonna be very robust if it makes its decisions for the wrong reasons.
To protect yourself you can apply appropriate defense mechanisms. There are quite a few to choose from, just not the one that fixes everything, as mentioned before. But if you already ‘know your adversary’ and your weaknesses this is going to help you finding the most suitable defenses. There are a couple of defenses implemented in the CleverHans library you can try out and check what improves your model’s robustness the most and doesn’t decrease its accuracy too much. Digging deeper on those defense methods is not part of this blog post, but if you’re interested there are nine of them explained at the end of the paper ‘Adversarial Attacks and Defences: A Survey‘. Currently the most effective ones seem to be adversarial training and defensive distillation which are also explained in this blog post. There is also a list of open-sourced white box defenses available online. After applying defenses you can go on checking out available countermeasures an attacker could apply and test them on your model if you found any.
Another thing you can and should do to protect yourself is stay up to date. There is a lot of research on this topic and new defenses or more robust model architectures are published frequently. Let’s glance at three of them I recently found:
Since current ML models often fail on adversarial samples with a very high confidence (99.3% ‘gibbon’ for the panda in the first example) Deep k-Nearest Neighbors (DkNN) is a new approach to tell how certain a ML model made its prediction. The so called ‘credibility’ score calculated by DkNN doesn’t get fooled by adversarial samples as much as the confidences currently calculated using the Softmax activation function. This makes it possible to determine adversarial samples using a threshold for the credibility. In some cases DkNN can even correct the decision of the network. Unfortunately DkNN requires train data at runtime and is slower than other algorithms what makes it not suitable for every use case.
Facebook proposed to add filtering layers to Neural Networks, that seem to be able to filter out the noise added by adversarial samples. Using those denoising layers they achieved 55.7% accuracy under white-box attacks on ImageNet, whereas previous state of the art was 27.9% accuracy.
Adding filters to a network is also proposed in the paper ‘Making Convolutional Networks Shift-Invariant Again‘. There the use of good old low-pass filters is recommended and described how to integrate them into a neural network without compromising the performance too much. Though it was not the original intention they found that this made their network more robust to adversarial samples.
Conclusion
Concluding we can say that ML faces some serios security issues. The massive use of ML in diverse domains brings various threats for society with it. Especially adversarial samples are very dangerous and hard to defend against. As often security is an arms race in the case of ML and so far attackers are at an advantage. Anyway the great efforts in research give hope. And at least for in one case adversarial samples were even beneficial for cyber security: they kinda brought us CAPTCHAs!
Further Readings
Although I already included lots of links in the post itself, I also want to recommend some readings that helped me getting into this topic.
- The CleverHans-blog contains some great articles in addition to the belonging repository.
- I appreciated the already mentioned survey paper ‘Adversarial Attacks and Defenses: A Survey‘
- There is a great book about a slightly different but correlated topic called ‘Interpretable Machine Learning’ that also contains a chapter about adversarial examples, that I found very useful (both, the chapter and the whole book).
Leave a Reply
You must be logged in to post a comment.