
Ein Artikel von Michelle Albrandt, Leah Fischer und Rebecca Westhäußer.
Durch die Digitalisierung werden immer mehr Daten erzeugt. Dabei erreicht die Datenbasis durch Vernetzung von Mensch zu Mensch, sowie auch von Mensch zu Maschine, eine neue Dimension (Morgen et al., 2023, 6). Prognosen für das Jahr 2025 zeigen, dass in Zukunft ein erhebliches Datenwachstum zu erwarten ist, wobei insgesamt 181 Zettabyte an Daten erzeugt oder repliziert werden sollen (Tenzer, 2022). Aber nicht nur in Zukunft muss mit Herausforderungen gerechnet werden. Dies zeigt ein Vorfall des Erdbeobachtungsprogramms “Sentinel”.Das Earth Observation Center (EOC) verwaltet und archiviert die Daten der Satelliten und hat im Januar 2019 die maximale Speicherkapazität überschritten, wobei erstmals der Wert von 10 Petabyte überschritten wurde, was 10 Millionen Gigabyte entspricht(Earth Observation Center – 10 000 000 Gigabyte Sentinel Am EOC, 2019).
Mit der Zunahme der hohen Datenmengen steigt demnach auch die Nachfrage nach Datenspeicherlösungen mit großer Kapazität. Herkömmliche Speichermedien müssen aufgrund ihrer kurzen Lebensdauer regelmäßig ausgetauscht werden (Welzel et al., 2023, 1). Beispielsweise beträgt die Lebensdauer für Festplatten 10 Jahre und für Magnetbänder 30 Jahre. Zusätzlich haben solche Medien eine begrenzte maximale Informationsdichte von etwa 10³ GB pro mm³, wie beispielsweise bei Festplattenlaufwerken (Konitzer, 2021, 4). Durch Häufigkeit der Schreib- oder Lesezugriffe kann sich die Lebenszeit sogar verkürzen. Lesezugriffe sind zur Überprüfung der Datenintegrität jedoch notwendig (Potthoff et al., 2014, 14).
Ein langfristiges Speichermedium muss aber nicht neu entwickelt werden. Das beste Beispiel für Datenspeicherung, die nahezu ewig anhält, ist eines der allerersten Speichermedien überhaupt, die DNA. DNA kann sehr lange bestehen. So war es möglich, 2015 das Genom eines Wollmammut zu sequenzieren. Dies gelang den Forschern, obwohl der gefundene Knochen 4000 Jahre alt war (Konitzer, 2021, 4). Informationen nicht nur zu extrahieren, sondern auch in der DNA zu speichern, hatten Forscher bereits in den 60er Jahren vor. 50 Jahre später ist es in zwei unterschiedlichen Gruppen gelungen, Daten in Größe von einem Megabyte in der DNA zu speichern. Nach erfolgreichen Errungenschaften, wie ein robustes DNA-Datenspeicherung System durch Fehlerkorrektur und dem Nachweis einer hohen Informationsdichte (2 Bit pro Nukleotid), wurde im Jahr 2018 eine Speicherkapazität von ca. 200 Megabyte erreicht, wodurch das Potenzial dieser Vision immer realistischer wurde (Shamorony & Heckel, 2022, 4).
Datenspeicherung auf der DNA
Um zu verstehen, wie Informationen auf der DNA gespeichert, konserviert und wieder ausgelesen werden können, muss zunächst die Struktur der DNA angesehen werden. Die Desoxyribonukleinsäure, kurz DNA, besteht aus Basen, Desoxyribose (Zucker) und einer Phosphatgruppe und ist Träger der genetischen Information des Menschen. Es gibt vier verschiedene Basen: Adenine, Guanine, Cytosine und Thymine. Eine Base bildet zusammen mit einem Phosphat und einer Desoxyribose ein Nukleotid. Mehrere Nukleotide aneinandergereiht bilden einen DNA-Strang. Die bekannte Doppelsträngige Helixform der DNA wird durch die Verbindung der komplementären Basen Adenin und Thymin sowie Guanin und Cytosin gebildet. Die Abfolge der Basen stellt die codierte Information dar. Dies ermöglicht die Speicherung von Daten auf der DNA, indem diese in den genetischen Code übersetzt werden (De Silva & Ganegoda, 2016, 2-3). Infolgedessen muss DNA geschrieben und wieder ausgelesen werden. Dieser Vorgang wird als Synthese und Sequenzierung bezeichnet (Hughes & Ellington, 2017, 1).
Kodierung
Es gibt bereits viele verschiedene Methoden zur Kodierung der Daten. Im Allgemeinen funktionieren sie jedoch alle nach dem gleichen Schema. Zunächst wird der Binärcode der Dateien in quaternäre Zahlen aufgeteilt. Das bedeutet, dass jeweils vier aufeinanderfolgende Nullen und Einsen des Binärcodes zusammengefasst werden. Jede Base entspricht einer quaternären Zahl, wodurch der binäre Code in den genetischen Code übersetzt werden kann. Dieser Schritt wird als Source Coding bezeichnet. Zur Kodierung von Textdateien können zum Beispiel folgende Methoden verwendet werden: arithmetische Kodierung, Wörterbuch-Kodierung oder Huffman-Kodierung. Von den genannten Beispielen ist die Huffman-Kodierung sehr populär in der Anwendung. Hier werden häufig vorkommende Symbole mit einer kurzen Codierung und selten vorkommende Symbole mit einer längeren Codierung versehen. Dadurch wird die durchschnittliche Länge des Codes für den zu speichernden Text reduziert. Auf diese Weise wird gleichzeitig die zu speichernde Datenmenge komprimiert, was einen weiteren Vorteil darstellt. Darüber hinaus sind alle Sonderzeichen in der Kodierung enthalten (Dong et al., 2020, 1096-1098).
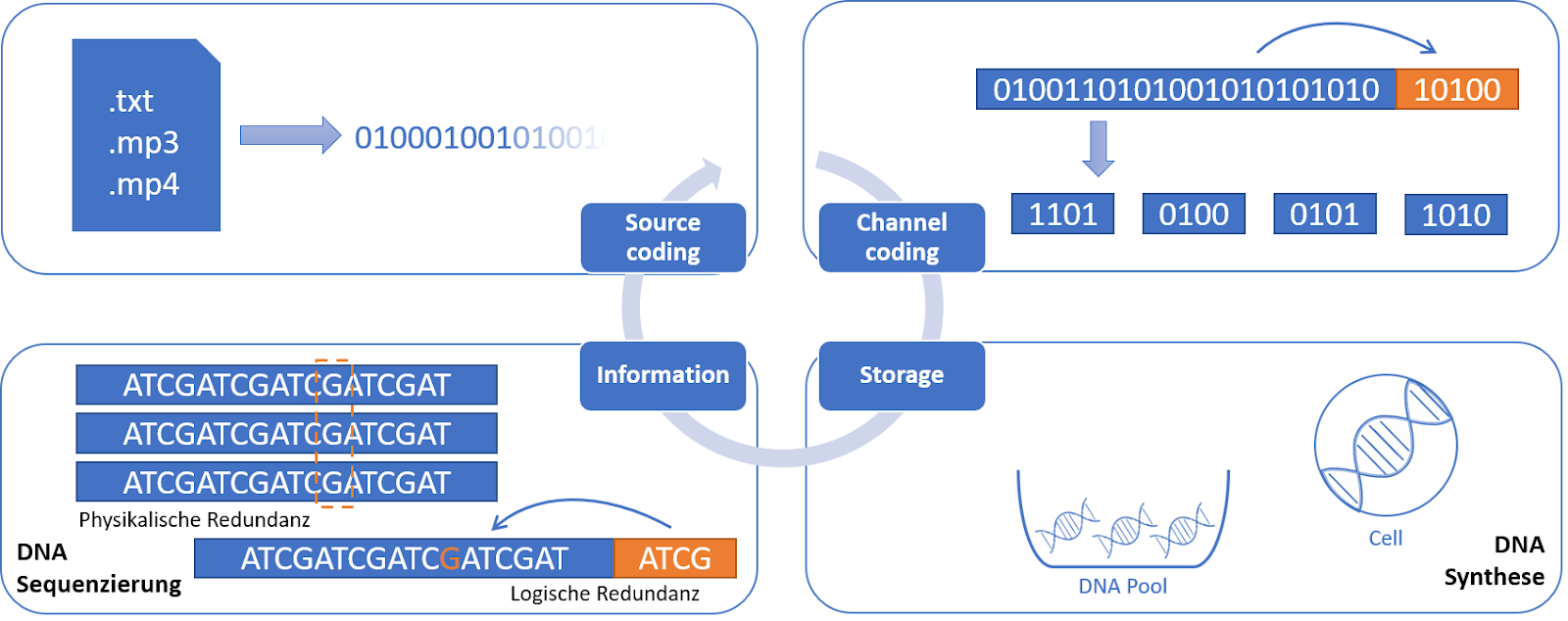
Informationsfluss in der DNA-basierten Informationsspeicherung (In Anlehnung an (Dong et al., 2020, 1096))
Die Kanalcodierung wird verwendet, um die Informationen vor Verzerrungen während der Übertragung zu schützen. Solche Verzerrungen können beispielsweise bei der Synthese oder der Sequenzierung auftreten. Um die Informationen vollständig wiederherstellen zu können, wird Redundanz erzeugt. Die Redundanz kann entweder physisch oder logisch sein. Physikalische Redundanz entsteht durch die Anfertigung von Kopien desselben DNA-Strangs, so dass es mehrere Kopien mit der gleichen Information gibt. Bei der logischen Redundanz hingegen werden sogenannte Prüfzeichen hinzugefügt, um Fehler erkennen und korrigieren zu können. Mit der Basenfolge, in der die Informationen enthalten sind, kann nun eine synthetische DNA erstellt werden, die demzufolge ebenfalls die zuvor kodierte Information enthält (Dong et al., 2020, 1096-1098).
Lagerung/Speicherung
Da DNA zum Beispiel durch UV-Strahlung, Wasser oder Enzyme zersetzt wird, muss sie geschützt werden, damit die auf ihr gespeicherten Daten nicht verloren gehen. Während die Halbwertszeit der DNA in Fossilien und unter perfekten Bedingungen mehrere 100 oder gar 1000 Jahre beträgt, verschlechtert sich dieser Wert drastisch, wenn die DNA Feuchtigkeit ausgesetzt wird (DNA DATA STORAGE ALLIANCE, 2021, 27). Synthetisierte DNA kann in vivo oder in vitro gelagert werden (Dong et al., 2020, 1096). Der Begriff “in vivo” kommt aus dem Lateinischen und bedeutet “an einem lebenden Objekt”, während “in vitro” “im Gefäß” bedeutet. Daraus folgt, dass bei der in vivo DNA-Speicherung die DNA in einem lebenden Organismus enthalten ist. Bei der in vitro DNA-Speicherung wird die DNA außerhalb eines Organismus gespeichert (Elder, 1999 & von Reininghaus, 1999).
Als eine der besten Varianten für die Speicherung von DNA gelten Sporen (Cox, 2001, 247). Sporen sind einzellige Fortpflanzungsorgane und -einheiten in Pflanzen und Pilzen (Sporen – Lexikon der Biologie, n.d.). Sie werden als eine sehr gute Möglichkeit angesehen, da sie auch unter sehr lebensfeindlichen Bedingungen überleben können und daher auch nach mehreren Millionen Jahren noch abrufbar wären. Außerdem vermehren sich die Sporen selbst weiter und erzeugen so automatisch Kopien der gespeicherten Daten. Für zusätzlichen Schutz können die Sporen in Bernstein eingeschlossen werden (Cox, 2001, 247).
Zu den möglichen in vitro Methoden für die längerfristige Lagerung von DNA gehören der molekulare und der makroskopische Schutz. Bei der so genannten chemischen Verkapselung wird der molekulare Ansatz verwendet. Dabei werden die einzelnen DNA-Moleküle in ein Matrixmaterial eingebettet, das die Diffusion von Wasser und Sauerstoff zu den einzelnen DNA-Molekülen verhindern soll. In den meisten Fällen bestehen die Matrizen aus anorganischen Materialien wie Glas. Beim makroskopischen Ansatz wird die DNA getrocknet und in Gegenwart eines reaktionsträgen Gases, beispielsweise in einer Metallkapsel, gelagert. Dieses Verfahren wird auch als physikalische Verkapselung bezeichnet. Solange die Unversehrtheit des Behälters gewährleistet werden kann, lassen sich chemische Reaktionen der DNA-Moleküle vermeiden (DNA DATA STORAGE ALLIANCE, 2021, 28).
Vor- und Nachteile
Die Datenspeicherung in der DNA hat viele Vorteile, die die DNA zur Zukunft der Datenspeicherung machen. Der größte Vorteil ist die parallele Berechnung. Mit der DNA können viele Operationen gleichzeitig ausgeführt werden, was bedeutet, dass die Leistungsrate sehr hoch ist. Hinzu kommt die effiziente Nutzung von Speicher und dem verfügbaren Platz. Beispielsweise passen rund 10 Billionen DNA-Moleküle auf einen Kubikzentimeter, was theoretisch einem Computer mit 10 Terabyte Speicherplatz entspricht (El-Seoud & Ghoniemy, 2017). Ein weiterer positiver Aspekt sind die geringen Energiekosten für die korrekte Lagerung im Vergleich zu herkömmlichen Speichermedien. Sie kann Jahrtausende lang überleben und ist zudem wesentlich umweltfreundlicher, da sie biologisch abbaubar ist und für die Erzeugung keine Schwermetalle oder seltene Elemente verwendet werden (Zhirnov et al., 2016).
Neben den genannten Vorteilen gibt es auch Nachteile, die die Nutzung der DNA mit sich bringt. Zum einen ist die Arbeit mit massiven Datensätzen ein Nachteil, da hierbei die Fehlerwahrscheinlichkeit exponentiell ansteigt. Zudem stellt die Analyse der Ergebnisse Schwierigkeiten dar, da es sich um Milliarden von Molekülen handelt, die miteinander interagieren (Akram et al., 2018). Der Durchsatz beim Lesen und Schreiben von Daten ist ein weiterer Nachteil sowie die Kosten für die Speicherung, welche derzeit zwischen 800$ und 5000$ liegen (Meiser et al., 2022). Ein weiterer wichtiger Aspekt sind die anfallenden Kosten für die Labore und die biologischen Experimente, die durchgeführt werden müssen, um die Speicherung der DNA überhaupt zu ermöglichen. Der größte Vorteil ist zugleich auch ein Nachteil, da die parallelen Berechnungen extrem viel Zeit in Anspruch nehmen (El-Seoud & Ghoniemy, 2017).
Anwendungen
Es gibt zahlreiche Möglichkeiten, wie die DNA in Zukunft für Daten eingesetzt werden kann. Die Forschungen hierfür gehen in verschiedenste Richtungen, aber der relevanteste Aspekt ist die Speicherung von Daten. Erste Studien haben Daten mit einer Größe von 200 Megabyte auf der DNA gespeichert. Weitere Forschungen haben beispielsweise 2000 Bilder als Kunstwerk oder ein Musikalbum auf der DNA kodiert. Anfängliche Berechnungen der Forschungen zeigen, dass alle Informationen, die in einem Jahr global erzeugt werden, auf ca. 4g von DNA gespeichert werden könnten, was den Vorteil der optimalen Nutzung von Speicher und Platz der DNA verdeutlicht (Boyle & Bergamin, 2020 & 2018).
Eine Einsatzmöglichkeit von DNA als Informationsträger ist das Barcoding bzw. das sogenannte Product Tagging. Bisher sind Barcodes auf Produkten oder auch QR-Codes bekannt, allerdings können diese Codes beispielsweise nicht für Tabletten oder Textilien verwendet werden. Hierfür bietet die DNA die Lösung der molekularen Barcodes. Das ist eine feste Menge an DNA, die den Bausteinen von Substanzen hinzugefügt wird. Diese müssen über den ganzen Lebenszyklus des Produktes intakt bleiben und ungiftig sein. Anhand der molekularen Barcodes kann Information zu einem Objekt hinzugefügt werden, ohne dass es für das menschliche Auge sichtbar ist (Meiser et al., 2022).
Die Erweiterung des Barcoding und der Datenspeicherung ist die DNA of Things (DoT), was sich von “Internet of Things” ableitet. DoT ist eine Mischung der beiden Ansätze und kann beispielsweise für das Labeling von medizinischen Produkten genutzt werden oder auch für Materialien, die eine Produktkontrolle benötigen. Für die Kontrolle wird die Tatsache genutzt, dass die Information nicht sichtbar ist (Koch et al., 2020).
Weitere Einsatzmöglichkeiten der DNA sind beispielsweise ein Random Number Generator oder die Kryptografie, wobei versucht wird, eine Nachricht in der DNA zu verschlüsseln. Hier wird momentan an einem Ansatz geforscht, wo menschliche DNA mit der Nachrichten-DNA gemischt wird, um die Nachricht zu verschleiern. Jedoch hat auch dieser Ansatz sehr lange Lesezeiten, was momentan noch ein generelles Problem bei der Nutzung von DNA ist (Meiser et al., 2022).
Aktuelle Entwicklungen und Ausblick
Wissenschaftler, wie auch Unternehmen, sind sehr daran interessiert, diese Technologie zu perfektionieren und an den Markt zu bringen. Seit 2020 gibt es die DNA Data Storage Alliance (DDSA), welche sich dieser Disziplin stellt. Gründer sind Unternehmen wie Illumina, Microsoft, Twist Bioscience und Western Digital. Ziel des Bündnisses ist es, auf Basis von DNA als Speichermedium ein interoperables Speichersystem zu schaffen und dieses auch zu fördern. Dazu gehören Spezifikationen und Standards in Bezug auf Kodierung, physische Schnittstellen, Aufbewahrung und Dateisysteme, die im Rahmen der Forschung entstehen sollen (DNA DATA STORAGE ALLIANCE, 2021, 5).
Im Oktober 2022 veröffentlichte die DDSA konkrete Anwendungsfälle für Fahrerassistenzsysteme (ADAS). Potential sieht die Allianz daher, weil Fahrerassistenzsysteme durch Sensorik Unmengen an Daten produzieren. Hohe Raten sorgen dafür, dass autonome Fahrzeuge bei Spitzenauslastung etwa 15.000 Gigabyte in einem Zeitraum von acht Stunden erzeugen. Bei steigenden Autoverkäufen wird vermutet, dass im Jahr 2025 mindestens 400 Millionen vernetzte Personenkraftwagen unterwegs sein werden. Daraus entsteht ein monatlicher Datenverkehr von zehn Exabyte. In Zukunft wird die Geschwindigkeit der Datenerzeugung ebenso durch steigende Automatisierung und zusätzliche Sensorik beschleunigt. Gründe, die laut DDSA, für die Nutzung von DNA-Speichersystemen sprechen, ist der Bedarf an hochparallel Berechnungen zum Beispiel für eine Suche oder Musterabgleich, trotz langsamer Leselatenz. Andere Archivierungsanforderungen für ADAS wie eine hohe Kapazität, belastbare und unveränderbare Speicherung mit niedrigem Total Cost of Ownership sprechen ebenfalls dafür (DNA DATA STORAGE ALLIANCE, 2022, 6-13).
Es ist sicher, dass die Speicherung von Daten auf der DNA ein großes Potenzial aufweist. Jedoch müssen für den alltäglichen Gebrauch noch einige Hindernisse überwunden werden. Vor allem die Kosten für die DNA Synthese und Sequenzierung sind große Faktoren, welche die aktuelle Nutzung verzögern. Prognosen zufolge sollen die Kosten für die Datenspeicherung in der DNA schon im Jahr 2030 auf 1 Dollar pro Terabyte sinken. Daher wird weiter an Methoden zur Verbesserung dieser Technologien geforscht (DNA DATA STORAGE ALLIANCE, 2021, 32).
Es bleibt abzuwarten, ob das Potenzial ausgeschöpft wird.
Quellen
Akram, F., Haq, I. U., Ali, H., & Laghat, A. T. (2018). Trends to store digital data in DNA: an overview. Molecular biology reports (Vol. 45).
Bergamin, F. (2018, April 20). Entire music album to be stored on DNA. ETH Zürich. Retrieved February 13, 2023, from https://ethz.ch/en/news-and-events/eth-news/news/2018/04/entire-music-album-to-be-stored-on-DNA.html
Boyle, A. (2020, February 24). Artist pays tribute to DNA pioneer Rosalind Franklin with DNA-laced paint and DNA-coded images. GeekWire. Retrieved February 13, 2023, from https://www.geekwire.com/2020/artist-dna-pioneer-rosalind-franklin/
Cox, J. P.L. (2001, July). Long-term data storage in DNA. TRENDS in Biotechnology, 19(7).
De Silva, P. Y., & Ganegoda, G. U. (2016). New Trends of Digital Data Storage in DNA. BioMed research international. https://doi.org/10.1155/2016/8072463
DNA-Aeon provides flexible arithmetic coding for constraint adherence and error correction in DNA storage. (2023, February 06). Nature Communications, (2023) 14:628. https://doi.org/10.1038/s41467-023-36297-3
DNA DATA STORAGE ALLIANCE. (2021). Preserving our digital legancy: An introduction to DNA data storage.
DNA DATA STORAGE ALLIANCE. (2022, October). Archival Storage Usage Analysis, Requirements, and Use Cases: Part 1 – Advanced Driver Assistance Systems.
Dong, Y., Sun, F., Ping, Z., Ouyang, Q., & Qian, L. (2020). DNA storage: research landscape and future prospects. National Science Review, 7(6). https://doi.org/10.1093/nsr/nwaa007
Earth Observation Center – 10 000 000 Gigabyte Sentinel am EOC. (2019, February 12). DLR. Retrieved February 10, 2023, from https://www.dlr.de/eoc/desktopdefault.aspx/tabid-13247/23165_read-54030/
Elder, K. (1999). in vitro – Lexikon der Biologie. Spektrum der Wissenschaft. Retrieved February 11, 2023, from https://www.spektrum.de/lexikon/biologie/in-vitro/34443
El-Seoud, S., & Ghoniemy, S. (2017). DNA Computing: Challenges and Application. International Journal of Interactive Mobile Technologies (iJIM). 10.3991/ijim.v11i2.6564
Hughes, R. A., & Ellington, A. D. (2017). Synthetic DNA Synthesis and Assembly: Putting the Synthetic in Synthetic Biology. Cold Spring Harbor perspectives in biology, 9(1). http://dx.doi.org/10.1101/cshperspect.a023812
Koch, J., Gantenbein, S., Masania, K., Stark, W. J., Erlich, Y., & Grass, R. N. (2020). A DNA-of-things storage architecture to create materials with embedded memory. Nature biotechnology.
Konitzer, F. (2021, Janary). Daten speichern mit DNA. zfv 1/2021. 10.12902/zfv-0338-2020
Meiser, L., Nguyen, B., Chen, Y., Nivala, J., Strauss, K., Ceze, L., & Grass, R. (2022). Synthetic DNA applications in information technology. https://doi.org/10.1038/s41467-021-27846-9
Nguyen, M., Morgen, J., Kleinaltenkamp, M., & Gabriel, L. (Eds.). (2023). Marketing und Innovation in disruptiven Zeiten. Springer Fachmedien Wiesbaden GmbH.
Potthoff, J., Wezel, J. V., Razum, M., & Walk, M. (2014, January). Anforderungen eines nachhaltigen, disziplinübergreifenden Forschungsdaten-Repositoriums.
Shamorony, I., & Heckel, R. (2022). Information-Theoretic Foundations of DNA Data Storage. In Foundations and Trends in Communications and Information Theory: Vol. 19 (19th ed.). 10.1561/0100000117
Sporen – Lexikon der Biologie. (n.d.). Spektrum der Wissenschaft. Retrieved February 11, 2023, from https://www.spektrum.de/lexikon/biologie/sporen/62944
Tenzer, F. (2022, 05 09). Prognose zum weltweit generierten Datenvolumen 2025. statista. https://de.statista.com/statistik/daten/studie/267974/umfrage/prognose-zum-weltweit-generierten-datenvolumen/
von Reininghaus, A. (1999). in vivo – Lexikon der Biologie. Spektrum der Wissenschaft. Retrieved February 11, 2023, from https://www.spektrum.de/lexikon/biologie/in-vivo/34453
Zhirnov, V., Zadegan, R. M., Sandhu, G. S., Church, G. M., & Hughes, W. L. (2016). Nucleic acid memory.
Leave a Reply
You must be logged in to post a comment.