Fog computing offers a compromise between cloud and edge computing for real-time, scalable data analysis. Ideal for regional applications and IoT. However, authentication and privacy issues must be addressed.
Most Cloud Developers seem to agree that the best way to gain knowledge and optimize processes is to collect and store data in the cloud and to analyze the collected data after the fact or in almost-real-time. In a world where the number of users and devices is already almost uncountable, the name Big Data becomes more and more a euphemism for the vast landscape we call the internet. On the other hand, we can also execute data analysis tools on the devices locally in a network using edge computing. This allows developers to work on the data of single devices or single users-grade networks.
Apparently, we can either have all the data or only a little data, but either way is difficult to handle efficiently. This is where fog computing comes into play.
What is the Fog?
When it comes to internet services like Internet of Things, web services, Infrastructure-as-a-service, or networking solutions, the limiting factors are latency, networking resources, data storage, and computing power. While most of these problems can be solved through more or faster hardware, there are problems that need analytical and clever solutions. More parallelization, e.g. load balancing multiple servers, and chaining of microservices, e.g. message queues, do not solve the logical problems of conflicting data or processes, e.g. database locking. It is simply physically impossible to manage all requests all the time.
In cloud computing, resources are distributed over the world and information is shared across that ominous, obscure cloud. This makes it possible to handle requests on devices that have availability, in order to handle requests with medium latency and high cumulative computing power. This makes it easy to scale the infrastructure, but makes the analysis of data very time and resource consuming and necessitates to store data permanently from time to time.
Whereas cloud computing handles all requests on a “synchronized” level, where we don’t know and don’t care about the location and type of device that handles a request, edge computing happens at the “edge to the internet”. That means that edge devices or edge networks process data either incoming or outgoing at or close to the user. This approach is often also referred to as “serverless” because no server is needed to handle any requests other than offering the code to create the interface (HTML, CSS etc.) and the code to be executed on edge devices.
With edge computing it is easy to pinpoint the physical and logical “location” and state and type of requests, data and devices. It is possible to handle those requests with extremely low latency, both network and compute, and a low need for computing power and resources. Although the need is low, scalability and access to data is very limited. This means that the calculations and processes done in edge computing are fast, but not always very rich or productive.
How does Fog Computing improve system architecture?
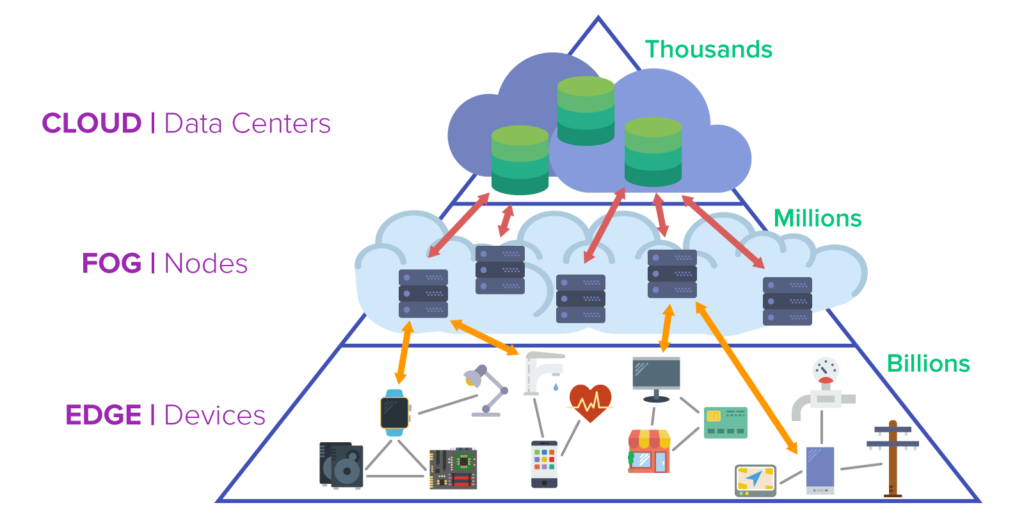
Fog computing places nodes between the edge, where the user with his private devices and networks resides, and the cloud, where nobody can identify any instance for sure, unless one asks the cloud providers themselves. The cloud stores and manages data in a somewhat manageable number of datacenters, and the edge completes processes on billions of devices. The fog on the other hand, consists of servers with numbers in the high thousands or few millions worldwide. This infrastructure allows developers and operators to make a compromise between cloud and edge computing. These servers are physically close to users’ networks.

The compromise has the following characteristics:
- The shorter physical distance also implies a low network latency and low need for computing resources due to limited data amounts.
- Data can be analyzed locally and in real time.
- Nodes can be scaled flexibly in response to growing numbers of users in small networks and regions with a small priority of single nodes.
- Nodes in the fog act as handlers between edge networks and the cloud. Urgent requests are forwarded to the cloud, and requests that can be processed locally are.
Connecting edge devices and the cloud through an independent actor allows for more and better control over the incoming and outgoing data. Information can be separated regionally and the usage of the cloud can be controlled in the fog. Forwarding requests is a concern because both the storage of sensitive information and the limitation of needed computing resources is detrimental to the overall quality of the cloud.
Data security and media rights management can be provided through those nodes on a regional basis. Sensitive information is stored locally on fog level and never forwarded to the cloud. The urgency of a request has to be determined on fog nodes. Under normal circumstances, networking bandwidth and computing resources are spared in the cloud by storing data locally whenever necessary and storing it in the cloud when the localization of data is no concern.
Smart Cities: An example for Fog Computing applications
One example for the use of fog nodes are smart cities, meaning independent traffic systems interacting to reduce traffic jams and incidents. Cars, traffic signals and road barriers are installed with sensors to collect data and send that data to a fog node. It is not necessary for a traffic light in New York to gain information about a car in Los Angeles, but the general gist of traffic optimization is the same. Fog computing allows real-time data analysis that enables traffic signals to rapidly change according to the traffic situation.

To this end, it is more useful to connect every device in the city to a fog node that is only responsible for that city. That way, millions of fog nods are placed to control traffic in a city or wider city area with its own scaled infrastructure. For example, New York City will most likely need more resources per square mile than Austin, Texas.
This separation of fog nodes leads to a separation of private data, like location data, e.g. home addresses, from the cloud service providers, and between each fog node. Only essential data is forwarded to the cloud and used to generate predictions, update traffic models, and generate newer algorithms and usage analysis.
With this method, degrading performance due to high demand only affects one city. High loads can be forwarded to the cloud, where requests are distributed globally to free resources. This way, the averaged load of the cloud can be used to cushion the impact of high local demand.
Obstacles for the implementation of Fog Computing
- Authentication and trust issues: Just like cloud service providers, fog service providers can be different parties with varying trust levels. One provider can pose as a trustworthy entity and manipulate the integrity of the fog for its connected end-users.
- Privacy: Decentralizing data security and media rights management to the fog and outsourcing the responsibility to a third party instead of the cloud or edge devices endangers user’s privacy due to the number of fog nodes.
- Security: Due to the number of devices connected to fog nodes, it is difficult to ensure the security of all gateways and the protection of personal information.
- Node placement: The physical and logical location of fog nodes should be optimized to reach the maximum service quality. The data for the right placement has to be analyzed and chosen carefully.
Conclusion
Fog Computing places nodes logically between edge networks and devices and the cloud.
It provides 4 main advantages:
- Network latency: Lower distance to the end-user and smaller data consumption leads to lower network delay and lower computing time.
- Data analysis: Low data amounts allow for real-time data analysis and the limitation of cloud usage.
- Security: Configuring fog nodes to the data protection needs ensures that cloud service providers only gain access to as much data as needed.
- Cost reduction: The regional placement and subdivision can minimize the hardware and energy cost for the fog service providers.
Sources
- IBM Blog – What is fog computing?
https://www.ibm.com/blogs/cloud-computing/2014/08/25/fog-computing/ - E-SPIN Group – The Examples of Application of Fog Computing
https://www.e-spincorp.com/the-examples-of-application-of-fog-computing/ - TechTarget – What is fog computing?
https://www.techtarget.com/iotagenda/definition/fog-computing-fogging - YourTechDiet – Brief About The Challenges with Fog Computing
https://yourtechdiet.com/blogs/fog-computing-issues/ - GeeksForGeeks – Difference Between Cloud Computing and Fog Computing
https://www.geeksforgeeks.org/difference-between-cloud-computing-and-fog-computing/ - Sam Solutions – Fog Computing vs. Cloud Computing for IoT Projects
https://www.sam-solutions.com/blog/fog-computing-vs-cloud-computing-for-iot-projects/ - AWS Documentation – Regions and Zones
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-regions-availability-zones.html - AWS Documentation – AWS Outposts Family
https://aws.amazon.com/outposts/ - AWS Documentation – AWS Global Infrastructure
https://aws.amazon.com/about-aws/global-infrastructure/ - Heavy.ai – Fog Computing Definition
https://www.heavy.ai/technical-glossary/fog-computing - Akamai – What is edge computing?
https://www.akamai.com/our-thinking/edge-computing - Cloudflare – What is edge computing?
https://www.cloudflare.com/learning/serverless/glossary/what-is-edge-computing/ - Cloudcomputing Insider – Was ist Fog Computing?
https://www.cloudcomputing-insider.de/was-ist-fog-computing-a-736757/ - CloudPing – AWS Latency Monitoring
https://www.cloudping.co/grid/p_50/timeframe/1W - Vercel – Edge Functions
https://vercel.com/features/edge-functions - SpiceWorks – What Is Fog Computing? Components, Examples, and Best Practices
https://www.spiceworks.com/tech/edge-computing/articles/what-is-fog-computing/ - Welotec – Edge Computing, Fog Computing or both?
https://www.welotec.com/edge-computing-fog-computing-or-both/
Leave a Reply
You must be logged in to post a comment.