AI and Scaling the Compute becomes more relevant as the strive for larger language models and general purpose AI continues. The future of the trend is unknown as the rate of doubling the compute outpaces Moore’s Law rate of every two year to a 3.4 month doubling.
Introduction
AI models have been rapidly growing in complexity and sophistication, requiring increasingly powerful computing resources to train and operate effectively. This trend has led to a surge of interest in scaling compute for AI, with researchers exploring new hardware architectures and distributed computing strategies to push the limits of what is possible. Figure 1 depicts the scale of compute required to train language models for the last ten years.
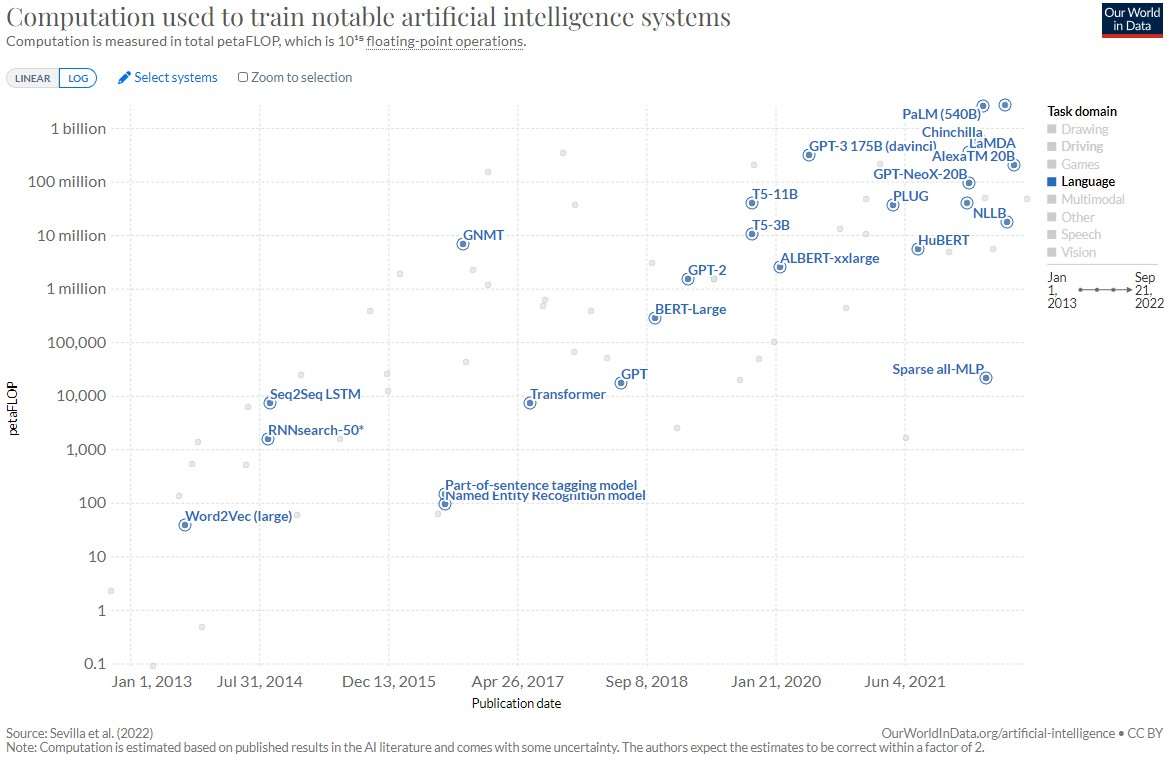
Figure 1: Computation used to train notable artificial intelligence systems [1]
The evolution of AI models has been driven by advances in deep learning, which allows models to learn from vast amounts of data and make predictions or decisions with remarkable accuracy. However, the sheer size and complexity of these models require an unprecedented amount of compute power to train and operate, presenting significant challenges for hardware designers and data center operators. Despite these challenges, progress has been impressive, with new breakthroughs in hardware and software helping to unlock the full potential of AI. Specialized hardware, such as GPUs (Graphics Processing Units) and TPUs (Tensor Processing Units) have emerged as powerful tools for training AI models, while distributed computing architectures are being developed to allow multiple machines to work together seamlessly. As AI models continue to grow in complexity, the need for scalable and efficient compute resources will only continue to grow. Researchers and engineers will need to work together to develop new hardware and software solutions that can keep pace with the rapid evolution of AI, unlocking new possibilities for intelligent automation, predictive analytics and other transformative applications.
Requiring compute beyond Moore’s Law
As explained in [2] the training of AI systems can be categorized in two distinct Eras, the First Era and the Modern Era. The First Era of compute usage in training AI systems, starting with the perceptron, lasted from the 1950s to the late 2000s and relied on limited computational resources and simple algorithms. In contrast, the Modern Era began around 2012 with the rise of deep learning and the availability of powerful hardware such as GPUs and TPUs, allowing for the training of increasingly complex models with millions or even billions of parameters. [3] even suggests three Eras with the current one being the “Large Scale Era” starting with AlphaGo around 2016.
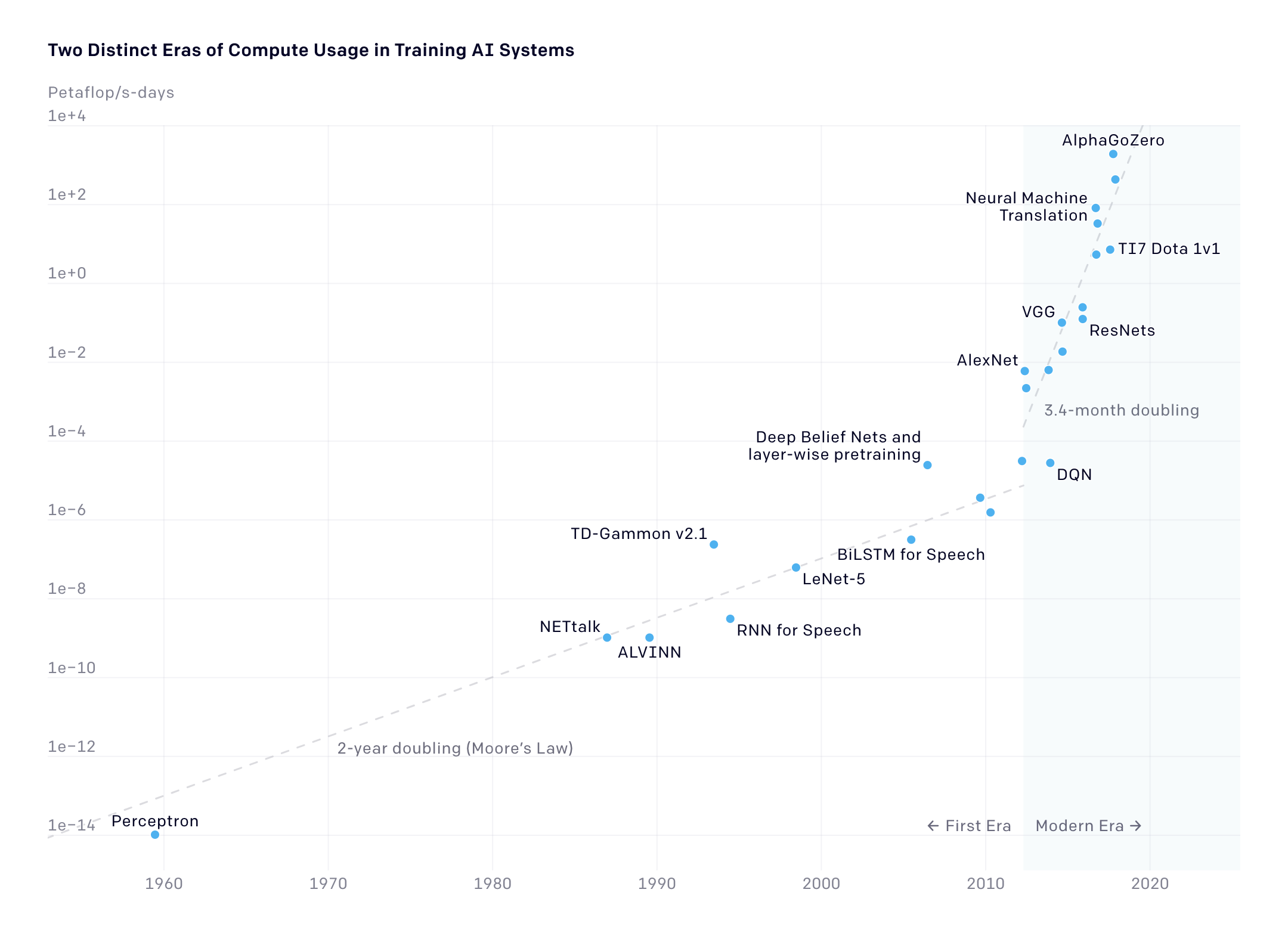
Figure 2: AlexNet to AlphaGo Zero: 300,000x increase in compute [2]
Increase in AI computation
Figure 2 depicts the increase in computational resources needed to train AI systems over time, which is evident by the rise of GPUs and TPUs and the transition from Moore’s Law’s 2-year doubling of compute to a 3.4-month doubling. This increase in compute demand is exemplified by the difference between AlexNet and AlphaGo Zero, where the latter requires 300,000 times more computational resources to train than the former.
With the rise of large language models like GPT, more recently known due to the publicly available ChatGPT, the question arose on how the trend on computing such models will continue. As seen in Figure 3 the amount of parameters to be learned are increasing rapidly and thus the amount of data and compute required for the models.

Figure 3: Amount of Parameters for Large Language Models [4]
The new Moore’s Law
Moore’s law is the observation that the number of transistors in a dense integrated circuit doubles about every two year [5]. As Moore’s Law has a physical constraint on how many transistors can be placed on an integrated circuits, which will cease to apply, a new trend in compute seems to emerge in the field of AI. As stated in [4] the increase of the size of the language model and in regard of the 3.4-month doubling time stated in [2] we seem to establish a new “Moore’s Law for AI” for compute, which can only be achieved with massive parallelization techniques.
Scaling AI computation
An earlier blogpost [6] already handled the explanation on how deep learning models can be parallelized with the different computation paradigms single instance single device (SISD), multi-instance single device (MISD), single-instance multi-device (SIMD) and multi-instance multi-device (MIMD). Furthermore, the concepts of Model and Data parallelization are explained in that post in more detail.
GPT-3 Example
If we take GPT-3 for example it was scaled up in several ways to enable it to handle its massive size and complexity. Here are some of the key techniques that were used [7]:
- Distributed training: GPT-3 was trained using a distributed training approach that involved multiple GPUs and TPUs working together in parallel. The training data was partitioned across the multiple devices and the model parameters were updated using a process called gradient descent, where each device calculated a portion of the gradient and then combined them to update the parameters.
- Model parallelism: Because GPT-3 has so many parameters (up to 175 billion), it was not possible to store the entire model on a single device. Instead, the model was split across multiple devices using a technique called model parallelism, where each device stores a portion of the model parameters and computes a portion of the model’s output.
- Pipeline parallelism: To further scale up training, GPT-3 also used a technique called pipeline parallelism, where the model is divided into multiple stages and each stage is run on a separate set of devices in parallel. This enables the model to handle much larger batch sizes and process more data in less time.
- Mixed precision training: GPT-3 used mixed precision training, which involves using both 16-bit and 32-bit floating-point numbers to represent the model parameters and compute gradients. This can significantly speed up training and reduce the memory requirements of the model.
- Adaptive optimization: Finally, GPT-3 used an adaptive optimization algorithm called AdamW that adjusts the learning rate and weight decay of the model dynamically during training. This helps to avoid overfitting and achieve better performance on the validation set.
In summary, the training of GPT-3 was scaled up using a combination of distributed training, model parallelism, pipeline parallelism, mixed precision training and adaptive optimization. These techniques allowed the model to handle its massive size and complexity.
Distributed training, but how?
In order to train a large AI model, scaling across multiple GPUs, TPUs, and machines is necessary. However, achieving this becomes more complex when using a compute cluster, as distributing tasks and aggregating results requires careful consideration of several points. Specifically, when training a large model at scale using a cluster of machines, the following
factors must be taken into account [8][9]:
- Communication overhead: Distributed training involves exchanging gradients and model updates between different machines, which can introduce significant communication overhead. Optimizing communication and reducing the frequency of communication can help reduce the overhead and speed up training.
- Load balancing: Distributing the workload across multiple machines requires careful load balancing to ensure that each machine has a similar workload. Imbalanced workloads can lead to underutilization of some machines and slower training overall.
- Fault tolerance: When using clusters of machines, it is important to consider fault tolerance, as failures in one or more machines can interrupt training. Strategies for fault tolerance include checkpointing, replication of model parameters, and the use of redundant compute nodes.
- Network topology: The topology of the network connecting the machines can affect the performance of distributed training. For example, using a network with high bandwidth and low latency can reduce communication overhead and speed up training.
- Scalability: The ability to scale up the number of machines used for training is important to accommodate largermodels anddatasets. Ensuringthatthetrainingprocess is scalablerequires careful consideration of the communication patterns and load balancing across a large number of machines.
The trend continues
Taking a look at an even larger language model, the Megatron-Turing NLG [10], we can see that the trend continues. Such large models therefore are required to train on large-scale infrastructure with special software and hardware design optimized for system throughput for large datasets. In [10] the tradeoffs for some techniques are mentioned. Only the combination of several techniques and the use of a supercomputer powered by 560 DGX 100 servers using each eight NVIDIA A100 80GB Tensor Core GPUs allowed NVIDIA to use scale up to thousand of GPUs and train the model in an acceptable time.
Conclusion and outlook
The trend for more compute is expected to continue as AI applications become more complex and require larger datasets and more sophisticated algorithms. To keep up with this demand, we can expect continued improvements in specialized hardware and software optimization techniques, such as neural architecture search, pruning and quantization. Scaling aspects of both software and hardware are critical to meet the increasing demand for computing power and to make AI more efficient and accessible to a wider range of applications.
In contrast to chasing even larger models another approach would be to focus more on specific tasks than general purpose models. As language models continue to grow in size, researchers are beginning to see diminishing returns in terms of their performance improvements. While larger language models have shown impressive capabilities in natural language processing tasks, the computational and financial resources required to train and run them have also increased exponentially. Therefore, [4] proposes a more practical approach which might be more cost and environment friendly than the next big general purpose AI.
As for now we can continue to observe large tech companies joining together for the next big AI model, using supercomputers, cloud infrastructure and every compute they have to build even more impressive AI and thus develop even more sophisticated software and hardware architectures to facilitate the massive amounts of data and computation required to train such models.
Sources
[1] OurWorld in Data. “Computation usedtotrain notable artificial intelligence systems”. In: (2023). URL: https://ourworldindata.org/grapher/artificial-intelligence-training-computation.
[2] OpenAI. “AI and Compute”. In: (2018). URL: https://openai.com/research/ai-and-compute.
[3] Jaime Sevilla et al. Compute Trends Across Three Eras of Machine Learning. 2022. arXiv: 2202.05924 [cs.LG].
[4] Julien Simon. “Large Language Models”. In: (2021). URL: https://huggingface.co/blog/large-language-models.
[5] Wikipedia. Moore’s Law. 2023. URL: https://en.wikipedia.org/wiki/Moore%5C%27s_law.
[6] Annika Strauß and Maximilian Kaiser. “An overview of Large Scale Deep Learning”. In: (2021). URL: https://blog.mi.hdm-stuttgart.de/index.php/2022/03/31/an-overview-oflarge-scale-deep-learning/.
[7] Tom B. Brown et al. “Language Models are Few-Shot Learners”. In: CoRR abs/2005.14165 (2020).
arXiv: 2005.14165. URL: https://arxiv.org/abs/2005.14165.
[8] Martín Abadi et al. TensorFlow: A System for Large-Scale Machine Learning. 2016. URL: https://www.usenix.org/system/files/conference/osdi16/osdi16-abadi.pdf.
[9] Henggang Cui, Gregory R. Ganger, and Phillip B. Gibbons. Scalable deep learning on distributed GPUs with a GPU-specialized parameter server. 2015. URL: https://www.pdl.cmu.edu/PDLFTP/BigLearning/CMU-PDL-15-107.pdf.
[10] Paresh Kharya and Ali Alvi. “Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World’s Largest and Most Powerful Generative Language Model”. In: (2021). URL: https://developer.nvidia.com/blog/using-deepspeed-and-megatron-to-trainmegatron-turing-nlg-530b-the-worlds-largest-and-most-powerful-generativelanguage-model/.
Leave a Reply
You must be logged in to post a comment.