

article by Annika Strauß (as426) and Maximilian Kaiser (mk374)
1. Introduction
One of the main reasons why machine learning did not take off in the 1990s was that the lack of computational power and the size of data sets, available at that time
Since then, a lot has changed and machine learning methods have found their way into the field of ultra large systems (ULS) like f.e. Google, where they have been used very successfully for quite some time.
Two main areas of application can be distinguished:
- Learn better ML models faster with very large data sets and very high computing power by parallelizing and distributing different components of the ML computation.
- Deep Learning methods are developed, trained and applied to control, understand, improve and optimize specific areas within a ULS, e.g. replace multiple overcomplicated subcomponents with a single, machine learned model that still does the same job
The connection between ULS and Deep Learning is quite obvious here. ULS offers potentially extremely high computational power due to the large amount of distributed software and hardware, enabling faster computation of more complex ML models. In addition, ULS are capable of processing and handling enormous amounts of data. Those are crucial for the quality of a learned model. Thus, ULS provide two very important basic requirements that are important for learning good ML models. One company that has both of these requirements in spades is Google. If you are new to Deep Learning, check out for example Jeff Dean’s Tech Talk to get a brief introduction.
2. Improving Deep Learning with ULS for superior model training
Research has shown that higher DL-scale in terms of the number of training examples, the number of model parameters, or both can dramatically improve the final classification accuracy. This realization increased interest in scaling the training and inference algorithms used for these models and in improving the applicable optimization methods. [1]
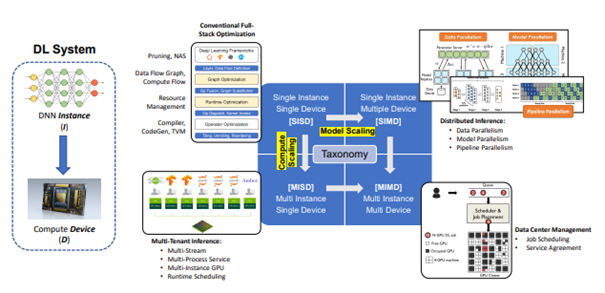
Characterized by the relationships between deep neural network instances (I) and compute devices (D), DL computation paradigms can be classified into three new categories beyond single instance single device (SISD), namely multi-instance single device (MISD), single-instance multi-device (SIMD), and multi-instance multi-device (MIMD), as shown in Figure 1.
Single Instance Single Device (SISD)
SISD focuses on single-model performance. This is the usual traditional approach to optimizing DL Systems. It improves the model’s end-to-end performance (e.g., latency) on the target hardware device. This includes Optimization on every level from compiler-level to algorithm-level. [1]
Multi Instance Single Device (MISD)
Co-locating multiple DNN Instances in one high performance Machine. Optimization will happen mainly through compute scaling, so better hardware. This is more an optimization of cost efficiency, as the best Hardware costs a lot of money, but can potentially handle multiple DNNs at once. The goals of MISD are enhancing serving throughput on the shared hardware and reducing power and infrastructural costs. MISD can be optimized by Workload scheduling, which avoids the inference of jobs from different DNN Instances. [1]
Multi Instance Multi Device (MIMD)
An example for MIMD would be an architecture where service routers are used to route the interference requests of multiple models to multiple devices and manage computation via job scheduling. This mainly lies on Data Center Management for optimal infrastructure. MIMD is still a rather uninvestigated approach, so there is only limited public work available. [1]
Single Instance Multi Device (SIMD)
SIMD optimization includes model parallelization, Data parallelization and pipeline parallelization. As ultra-large model size has shown to have a large impact on the models performance, models that take in billions of parameters as training data have come to be valuable for state-of-the-art industrial models. This scaling volume and complexity of computations bring current hardware to its boundaries. The idea is to distribute models and data to multiple devices. In 2012 Google researchers published a paper on Large Scale Distributed Deep Networks, which featured their new LDL-Framework DistBelief that is based on Model Parallelism and Data Parallelism. [1]
Model parallelism
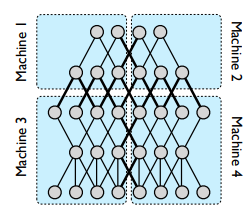
A Data scientist defines the layers of a neural network with feedforward and probably backward connections. For large models, this net may be partitioned across multiple machines like shown in Figure 2. A framework that supports model parallelism automatically parallelized the computations in each machine using CPU and GPU of that machine. Googles DistBelief also manages communication, synchronization, and data transfer between the machines during both training and inference phase.
The number of machines to distribute the model for better performance depends on the complexity of the model and number of parameters. DistBelief runs Models with a very large number of parameters, with up to 144 partitions.
Problem: The typical cause of less-than-ideal speedups is variance in processing times across the different machines, leading to many machines waiting for the single slowest machine to finish a given phase of computation. [2]
Data parallelism
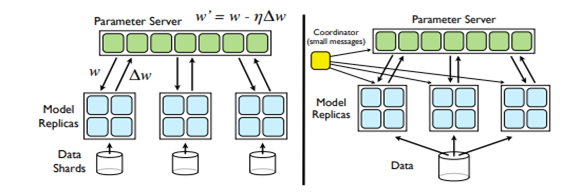
In order to optimize the training of parallelized models, Figure 3 describes two procedures that not only parallelize the computation within a single instance of a model, but distribute the training across the multiple instances and replicas of the model. [2]
Figure 3, Left: Downpour SGD (stochastic gradient Descent):
Online learning method. SGD is inherently sequential and therefore impractical for very large datasets. Downpour SGD is a variant of asynchronous stochastic gradient descent. It uses multiple replicas of a single DistBelief model. Training data is divided into multiple data shards that are each fed into one replica of the model. The Model Replicas share one Parameter Server, that holds the current state of the best model parameters. [2]
Figure 3, Right: Sandblaster L-BFGS (Limited Memory Broyden–Fletcher–Goldfarb–Shanno)
Batch learning. While Inherent batch learning methods work well on smaller models and datasets, Sandblaster optimizes batch learning for large deep networks. It also uses multiple model replica that share one parameter storage. A Coordinator writes out operations that can be computed by each parameter server shard (batch) independently. Data is stored in one place, but distributed to multiple Machines, each responsible for computing the parameters for a subset of data. [2]
3. Improving ULS and its components with the aid of Deep Learning
The use of AI-supporting methods in everyday life is a common thing nowadays and we are familiar with them. We use them every day. Besides speech recognition, user-specific recommendations for music or shopping, automatic photo sorting, route calculation for navigation and text-to-speech/speech-to-text applications, there are just as many other areas of application where we encounter AI-methods every day. In most cases, they are intended to simplify or optimize our everyday lives.
However, this process does not only take place in end-user oriented applications and systems. Also in Ultra Large Scaled Systems Machine Learning algorithms and methods are used to monitor, control, analyze, understand, simplify and/or improve the system. Below, we give a brief overview of the main ways in which such ML models can be used to have a positive impact on our systems.
Understanding your data – AI analytics
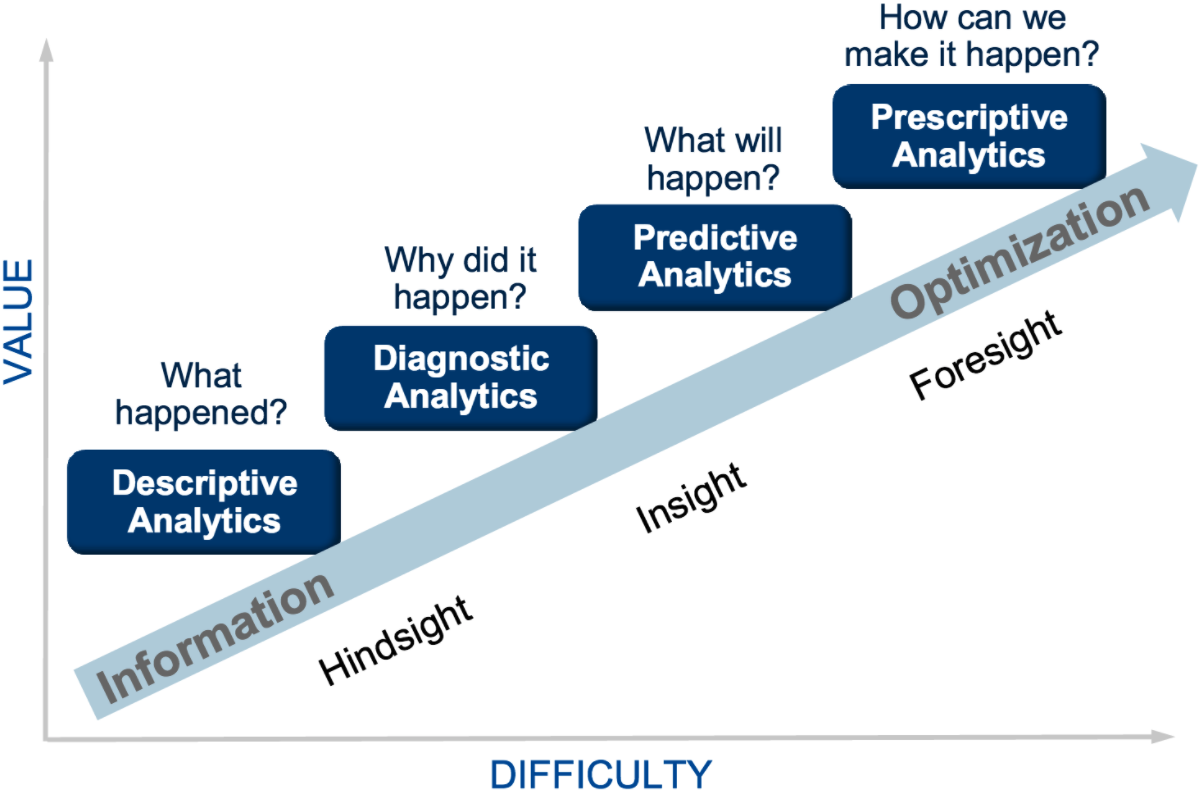
Understanding data has never been more important. It can potentially tell us a lot about our user behavior, enable predictions, or help with system optimization. It’s important though, that we draw the right conclusions and interpret our data correctly. This is traditionally a job done by a data analyst by hand. However, this task becomes very difficult in ultra large scaled systems, where enormous amounts of data come together. The following Gartner Analytic Ascendancy model shows the transition from information to optimization in different stages of informational value and effort. The more value you want, the harder it gets. [3]
A promising approach to tackle this issue is AI analytics. Here, machine learning techniques are used to gain new insights, recognize patterns or find relationships in the data. A machine learning algorithm continuously monitors the system and analyzes large amounts of user data. In this way, the time-consuming work of a data analyst can be automated. However, the goal is not to replace the data analyst, but to speed up the time-consuming analysis process and provide better data and insights. In short, AI analytics provides scalable, fast, and accurate analytics that the data analyst takes as baseline data for his evaluation and conclusions. [3]
Architectural optimization
A rather unintuitive use case for ML methods in very large systems is architectural improvements. As a system grows in size, its complexity usually grows as well, and the monitoring effort increases dramatically to keep a rudimentary overview of all processes. It is understandable that the intensive and quite complex interconnection of various distributed subcomponents leads to a certain degree of inefficiency. This is where AI comes into play. It can be used to replace entire branches of subsystems with a single machine-learned component that is generalizable and less complex to implement and monitor. One can learn such an ML model by using the system’s normal input data as training data and defining the normal output as the target output. In this way, a model is learned that produces the same output for the same input data. [2b]
One area where AI is currently being used for architecture purposes is the design and conceptualization of 6G, an AI-powered wireless network and successor to the current 5G. Here, the network itself is expected to gain some network intelligence through AI and Deep Learning, enabling it to respond autonomously to dynamic changes in the network. The 6G design is expected to take an AI-native approach. In practice, the network shall be able to learn and adapt smartly to the given network dynamics. The network should be self-evolving and split into subnetworks as needed. [4]
Prediction of traffic peaks, technical failures or user behavior
Probably the most obvious use case is one that we also encounter in everyday life: Prediction. We can use AI to predict critical factors for our system, such as unexpected traffic peaks or faults that cannot be detected and/or predicted due to the irregularity of their occurrence or the complexity of the system. A machine learning method can be used here to learn a monitoring component. It’s learned with old monitoring data and is then fed with the new data in the productive environment. This model learns to recognize warning signs to predict impending anomalies early. The better this model is learned, the more accurately we can predict the nature of the incident and, for example, provide new replicas to absorb additional traffic, optimize load balancing or take vulnerable machines offline.
In fact, there are already companies built around this idea of AI-powered decision-making. For example, peak.ai with their slogan: “AI-driven decision-making at your fingertips, for the first time.”
Another area where we can use predictions to improve our system is in social media and marketing. If we want to react quickly to the specific behavior of a user, we need an intelligent system that processes the new input immediately and does not have to wait for the analysis of a “far away” system. This would cost precious seconds. Here, the model of the user is adapted with the help of so-called online learning.
Here, the user model is adapted with the help of so-called online learning. Adapting the evaluation model of the user behavior with each new observation (= new data set) yields and not over all data sets ever observed yields faster adaptation of our system. [5]
Load balancing
Whilst load balancing was mentioned before, it is discussed in the following section from a different perspective. AI can be used not only to predict when we need an additional load balancer, but also to decide how and where we should redirect the incoming traffic. Since the interconnection of devices (just think of Iot) has increased enormously in recent years, it is understandable that smart load balancing can have a major impact on the performance of the system. A good load balancer has to ensure that response times of the individual components can be kept as small as possible and the servers do not collapse by load.
Kim and Kim [6], for example, proposed an efficient load balancing in the field of IoT, which is achieved by reinforcement learning. In reinforcement learning, the agent autonomously learns a strategy to maximize rewards received (e.g. positive feedback after a decision). Especially in IoT, where an enormous amount of event data is sent across the network, efficient load balancing is crucial, but difficult to achieve. Their proposal is to measure large amounts of user data and network traffic, to then apply them to a deep belief network. This should then be used to achieve a more efficient load balancing. They called it network load learning.
4. Conclusion and Outlook
The link between ULS and AI may seem counterintuitive at first, but it is much more present today, than one might think. It is evident that the benefits of ULS are already being used extensively to learn more efficient and accurate ML models. We don’t assume that this trend will come to a halt in the near future. On the contrary, it is to be expected that the quality of ML models will improve significantly in the near future and the spread of application areas is only a matter of time. Pioneers like Google are pushing research intensively. It is to be expected that ML models will increasingly move to the edge, enabling small, low-power devices to provide impressive functionality. In addition, it can be assumed that ML models will be increasingly used for planning, optimization and control of future (and existing) systems.
5. Sources
[1] https://arxiv.org/pdf/2111.14247.pdf
[2] https://storage.googleapis.com/pub-tools-public-publication-data/pdf/40565.pdf (2012)
[2b] http://highscalability.com/blog/2016/3/16/jeff-dean-on-large-scale-deep-learning-at-google.html
[3] https://www.anodot.com/learning-center/ai-analytics/
[4] https://ieeexplore.ieee.org/abstract/document/8808168/
[5] http://highscalability.com/blog/2012/7/30/prismatic-architecture-using-machine-learning-on-social-netw.html
[6] https://link.springer.com/article/10.1007/s10586-016-0667-5
Leave a Reply
You must be logged in to post a comment.