
In einer immer stärker digitalisierten Welt haben Neuronale Netze und Deep Learning eine immer wichtigere Rolle eingenommen und viele Bereiche unseres Alltags in vielerlei Hinsicht bereichert. Von Sprachmodellen über autonome Fahrzeuge bis hin zur Bilderkennung/-generierung, haben Deep Learning Systeme eine erstaunliche Fähigkeit zur Lösung komplexer Aufgaben gezeigt. Die Anwendungsmöglichkeiten zeigen scheinbar keine Grenzen. Doch während oft nur die Vorteile und die Fähigkeiten dieser Technologie hervorgehoben werden, ist es unerlässlich auch die damit verbundenen Sicherheitsaspekte gründlicher zu beleuchten.
Der Einsatz von Deep Learning Systemen hat längst nicht mehr nur eine Nischenbedeutung, sondern ist in vielen Bereichen zu einem integralen Bestandteil geworden. Mit dem zunehmenden Vertrauen in diese Systeme stellt sich unweigerlich die Frage: Wie sicher sind Deep Learning Systeme wirklich? Die Sicherheit von Deep Learning Systemen ist zu einem Schlüsselaspekt geworden, der nicht ignoriert werden darf. Vor allem da Cyberkriminelle keine Mühen scheuen, um potenzielle Schwachstellen auszunutzen und Schaden zu verursachen. Daher ist es notwendig, potenzielle Risiken und Verwundbarkeiten zu verstehen, die mit der Implementierung von Neuronalen Netzen und Deep Learning einhergehen.
Was ist Deep Learning?

Bevor wir uns den Sicherheitsaspekten von Deep Learning Systemen zuwenden, werfen wir einen kurzen Blick darauf, was das Konzept hinter Deep Learning darstellt. Deep Learning ist ein Teil des maschinellen Lernens, das sich vor allem mit dem Training und der Nutzung von Künstlichen Neuronalen Netzen beschäftigt. Ein Neuronales Netz besteht dabei aus mehreren Schichten von künstlichen Neuronen, die miteinander verbunden sind. Es soll dabei grob die biologische Funktionsweise des menschlichen Gehirns nachstellen.
Das Training eines Deep Learning Modells erfolgt durch die Präsentation von Trainingsdaten, die aus Eingabe- und entsprechenden Ausgabedaten bestehen. Das neuronale Netzwerk passt während des Trainings die Gewichte und Parameter der künstlichen Neuronen an, um eine bestmögliche Leistung zu erzielen. Dieser Prozess wird als „Lernen“ bezeichnet, da das Modell iterativ seine Fähigkeit verbessert, Eingaben korrekt zu interpretieren und passende Ausgaben zu generieren. Der Kerngedanke des Deep Learning besteht dabei darin, dass ein tiefes neuronales Netz selbständig in der Lage ist, Muster, Zusammenhänge und Merkmale in den Daten zu erkennen. Sie sind somit in der Lage von sich aus zu lernen, ohne dass der Mensch in den eigentlichen „Lernprozess“ eingreift. Für das Training eines solchen Systems sind eine große Menge an Daten notwendig, was sich auch in den riesigen Mengen an Daten widerspiegelt, die z. B. für ChatGPT verwendet wurden [2, 3].
Doch wie können nun Angriffe auf diese Art von Systemen ausgeführt werden und welche Gefahren entstehen dadurch?
Angriffe auf Deep Learning Systeme
Deep Learning Systeme sind anfällig für verschiedene Arten von Angriffen. Dabei zielen die Angriffe auf die folgenden drei Grundsätze ab, die ein System sicher machen:
- Vertraulichkeit: Schutz vor unbefugtem Zugriff auf Informationen.
- Integrität: Sicherstellung, dass Informationen unverändert und korrekt bleiben.
- Verfügbarkeit: Gewährleistung, dass Informationen und Ressourcen immer zugänglich sind, wenn sie benötigt werden.
Diese Angriffe können während der Trainings- oder in der Inferenz-Phase stattfinden. Die Gefahr von Angriffen auf Deep Learning Systeme ist ein wichtiger Aspekt, der bei der Entwicklung und Implementierung von KI-Anwendungen berücksichtigt werden muss [4].
Übersicht von Angriffen

Die vorangehende Abbildung bietet eine übersichtliche Darstellung der verschiedenen Angriffe, denen Deep Learning Systeme ausgesetzt sein können. Diese Angriffe können je nach ihrer zeitlichen Einordnung in zwei Hauptphasen unterteilt werden: Vor/Während des Trainings und nach dem Training (Inferenz-Phase).
Vor/Während des Trainings
In dieser Phase finden Angriffe statt, während das Deep Learning Modell noch im Trainingsprozess ist und aus den bereitgestellten Trainingsdaten lernt. Während dieser Zeit besteht die Möglichkeit, das Modell absichtlich zu beeinflussen oder zu manipulieren, um es zu einem späteren Zeitpunkt in der Vorhersage-Phase anfälliger zu machen.
Poisoning Attacks

Bei einem Poisoning Attack werden falsche, irreführende oder anderweitig böswillige oder schädliche Daten in den Trainingsdatensatz eines Systems eingeschleust. Diese Daten werden bewusst so ausgewählt, dass sie das Modell verfälschen und die Modellleistung beeinträchtigen. Ziel eines Poisoning Attacks ist es, das Modell so zu manipulieren, dass es in der Anwendung falsche Vorhersagen tätigt.
So könnte beispielsweise ein Angreifer absichtlich falsch gelabelte Daten in den Trainingsdatensatz einschleusen. Wenn das Modell während des Trainings diese manipulierten Daten verarbeitet, kann es lernen, falsche Muster zu erkennen und fehlerhafte Zusammenhänge zu ziehen. Dadurch kann die Verfügbarkeit des Systems eingeschränkt werden. Ebenfalls könnte ein Angreifer mithilfe von Confused Data eine Hintertür im Zielmodell erzeugen. Das Modell verhält sich dabei die meiste Zeit normal, aber macht mit den manipulierten Daten falsche Vorhersagen. Mithilfe dieser eingerichtet Hintertür und den eingepflanzten Daten, kann ein Angreifer die Ergebnisse des Modells manipulieren und so weitere Angriffe starten [5, 6].
Ein sehr bekanntes Beispiel eines Poisoning Attacks auf ein Machine Learning System ist der Fall des „Tay“ Bots von Microsoft. Tay war ein künstlicher intelligenter Chatbot, der auf Twitter entwickelt wurde und als 19-jähriges Mädchen auftrat. Tay wurde trainiert, um menschenähnliche Konversationen zu führen und aus den Interaktionen mit Benutzern zu lernen. Tay wurde von Trolls und bösartigen Benutzern gezielt manipuliert, indem sie den Bot mit rassistischen, sexistischen und extremistischen Aussagen fütterten. Das Ergebnis war, dass Tay die negativen Inhalte aufnahm und in ihren Antworten wiedergab [7].
Model Extraction Attacks

Ein Model Extraction Attack ist eine Art von Angriff auf ein Deep Learning System, bei der der Angreifer versucht, das Model ohne vorherige Kenntnis der Trainingsdaten und Algorithmen zu kopieren. Dadurch können Informationen gewonnen werden, um ein ähnliches Modell zu erstellen und dies für die Zwecke des Angreifers zu nutzen.
Der Prozess des Model Extraction Attack beginnt in der Regel damit, dass der Angreifer Zugriff auf das Zielmodell erhält. Dies kann durch verschiedene Möglichkeiten geschehen, wie zum Beispiel durch Black-Box-Zugriff auf ein Modell, bei dem der Angreifer nur die Möglichkeit hat, Eingaben an das Modell zu stellen und die Ausgaben zu beobachten, aber keine Kenntnisse über die internen Strukturen oder Gewichte des Modells hat. Durch gezielte Abfragen an das Zielmodell, sammelt der Angreifer die Ausgaben des Modells. Mithilfe der Eingaben und der Reaktionen des Modells können durch unterschiedliche Ansätze wie das Training eines Substitute Models, dass das Verhalten des Zielmodells nachahmt, wichtige Informationen wie Hyperparameter, etc. gesammelt werden.
Ein Model Extraction Attack kann verschiedene Motivationen haben. In einigen Fällen kann ein konkurrierendes Unternehmen das Modell extrahieren, um Zeit und Ressourcen für die eigene Modellentwicklung zu sparen. In anderen Szenarien könnten Angreifer das Modell für böswillige Zwecke nutzen, wie zum Beispiel das Erstellen von bösartigen Gegenmodellen, um die Sicherheitssysteme des ursprünglichen Modells zu umgehen [5, 8].
Model Inversion Attacks
Bei einem Model Inversion Attacks handelt es sich um Angriffe, die auf die Privatsphäre abzielen, um sensible Informationen über die Trainingsdaten zu extrahieren. Ziel des Angriffes ist es den Informationsfluss, der im Training des Modells verwendet wird, um aus den Trainingsdaten ein Modell zu erhalten umzukehren. Diese Inversion ermöglicht es Angreifern, vom Modell auf die Trainingsdaten zu schließen, da sich neuronale Netze möglicherweise zu viele Informationen aus den Trainingsdaten merken. So können Zugehörigkeiten oder Eigenschaften in den Daten wieder hergestellt werden und erhebliche Risiken für den Datenschutz mit sich bringen, insbesondere in Szenarien, in denen die Trainingsdaten sensible oder persönliche Informationen enthalten.
Ein Angriff läuft dabei folgendermaßen ab:
- Generierung Synthetischer Daten: Der Angreifer generiert synthetische Daten und beobachtet die entsprechenden Ausgaben des Zielmodells. Dabei handelt es sich in der Regel um Beispiele, die für den Angreifer von Interesse sind, wie zum Beispiel spezifische Klassen oder Merkmale, die vom Modell identifiziert werden.
- Erstellen eines Inversionsmodells: Der Angreifer erstellt ein sogenanntes „Shadow-Modell“, das in der Lage ist, aus den Ausgaben des Zielmodells Rückschlüsse auf die entsprechenden Eingabedaten, d. h. den Originaldatensatz, zu ziehen. Das Inversionsmodell wird so trainiert, dass es Eingabebeispiele generiert, die ähnlich den Ausgaben des Zielmodells sind.
- Ausführen des Angriffs: Der Angreifer verwendet das trainierte Inversionsmodell, um Eingabedaten zu generieren, die den gewünschten Klassen oder Merkmalen des Zielmodells entsprechen. Durch das Generieren dieser invertierten Eingaben kann der Angreifer Rückschlüsse auf interne Strukturen und Trainingsdaten des Modells ziehen.
Der Angriff zielt darauf ab, vertrauliche Details über individuelle Trainingsdatenpunkte zu erlangen und kann in Szenarien wie medizinischen Diagnosen oder Gesichtserkennung erhebliche Datenschutzrisiken darstellen [5, 9].
Nach dem Training (Inferenzphase)
In der Inferenzphase befindet sich das Deep Learning Modell im produktiven Einsatz, nachdem es erfolgreich trainiert wurde. Während dieser Phase nimmt das Modell neue, nicht in den Trainingsdatensatz enthaltene Eingaben entgegen und generiert Vorhersagen oder Ausgaben basierend auf dem erlernten Wissen aus dem Trainingsprozess.
Adversarial Attacks
Adversarial Attacks sind eine spezielle Art von Angriffen auf Deep Learning Modelle, die darauf abzielen, das Modell in der Prediction Phase gezielt zu täuschen. Bei diesen Angriffen werden gezielt kleine und oft kaum erkennbare Störungen oder Veränderungen in den Eingabedaten vorgenommen, um das Modell zu irreführen und falsche Vorhersagen zu erzeugen. Diese veränderten Daten, werden Adversarial Examples genannt.

Die Besonderheit von Adversarial Attacks liegt darin, dass die Manipulationen an den Eingabedaten für das menschliche Auge meist nicht sichtbar sind. Die veränderten Eingaben sehen für den Menschen identisch oder nahezu identisch zu den originalen Eingaben aus, jedoch kann das trainierte Modell darauf völlig unterschiedliche oder sogar falsche Ergebnisse liefern.
Adversarial Attacks beruhen auf Schwächen im Verhalten von Deep Learning Modellen, insbesondere in Bezug auf die Robustheit und Generalisierungsfähigkeit. Diese Angriffe können auf verschiedenen Methoden basieren, wie zum Beispiel auf der Optimierung spezieller Störungen (auch Adversarial Perturbations genannt) oder auf der Verwendung speziell entwickelter Algorithmen zur Generierung der manipulierten Eingabedaten. Durch diese Angriffe können Gefahren entstehen für zum Beispiel autonome Fahrzeuge, falls Verkehrszeichen mit Absicht verändert werden. Ebenso könnten Gesichtserkennungssysteme so getäuscht werden, dass man die Identität anderer Menschen annehmen könnte [5, 10, 11].
Gegenmaßnahmen
Angesichts der vielfältigen Gefahren, denen Deep Learning Systeme ausgesetzt sind, ist es entscheidend, geeignete Gegenmaßnahmen zu implementieren, um die Sicherheit und Vertrauenswürdigkeit dieser Systeme zu gewährleisten. Folgende Gegenmaßnahmen können besseren Schutz bieten:
- Modellverschleierung: Diese Techniken werden verwendet, um die Funktionsweise und Struktur des Modells vor potenziellen Angreifern zu verbergen. Das kann durch Techniken wie „Gradient Masking“ erreicht werden, bei denen sensible Informationen über das Modell, wie beispielsweise die Gradienten während des Trainings, nicht öffentlich gemacht werden.
- Datenschutz: Um Datenschutzrisiken zu minimieren, sollten Datenschutztechniken wie „Differential Privacy“ eingesetzt werden. Diese Techniken fügen zufälliges Rauschen zu den Trainingsdaten hinzu, um zu verhindern, dass das Modell spezifische Informationen über einzelne Datenpunkte lernt.
- Adversarial Training: Beim Adversarial Training wird das Modell während des Trainings mit speziell generierten Adversarialen Examples konfrontiert. Dadurch lernt das Modell, robuster gegenüber Adversarial Attacks zu sein und kann besser mit manipulierten Eingaben umgehen.
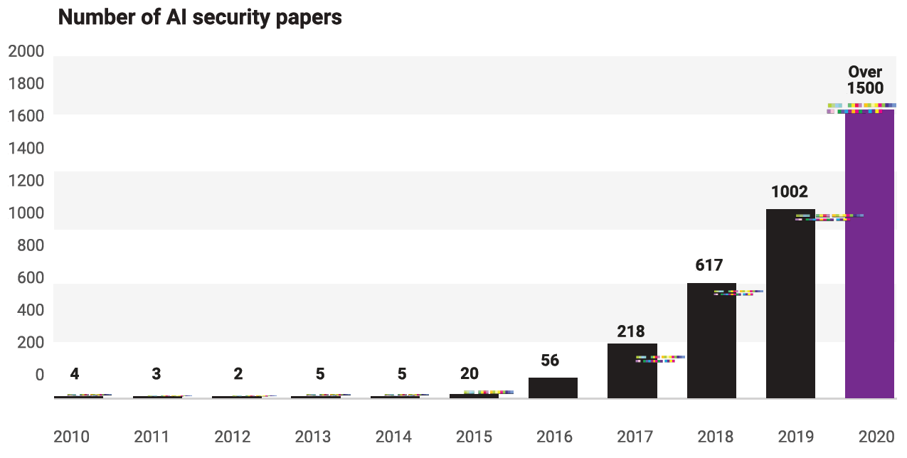
Durch die Implementierung dieser umfassenden Gegenmaßnahmen können Deep Learning Systeme besser gegen Angriffe geschützt werden und ihre Sicherheit und Integrität gestärkt werden. Wie aktuell das Thema derzeit ist, zeigt die obige Abbildung. Die Anzahl der Paper, die im Bereich KI-Security erscheinen, haben sich in letzter Zeit deutlich erhöht. Je mehr Künstliche Intelligenz und die Deep Learning in die unterschiedlichen Lebensbereiche integriert werden, desto wichtiger ist es diese vor Angriffen zu beschützen [5, 12].
Ausblick
Die Sicherheit von Deep Learning Systemen ist ein Thema von entscheidender Bedeutung, dass weiterhin eine Vielzahl von Herausforderungen und Entwicklungen mit sich bringt. Obwohl Deep Learning viele beeindruckende Fortschritte gemacht hat, sind diese Systeme nach wie vor anfällig für verschiedene Arten von Angriffen, die ihre Integrität und Zuverlässigkeit gefährden können. Die Forschung in diesem Bereich entwickelt sich schnell, und es gibt vielversprechende Ansätze, um die Sicherheit von Deep Learning Systemen zu verbessern.
Ein entscheidender Schritt in Richtung Sicherheit ist die stetige Verbesserung der Angriffserkennung und -abwehr. Forscher arbeiten daran, immer effektivere Gegenmaßnahmen zu entwickeln, um bekannte Angriffe wie Poisoning Attacks, Model Inversion Attacks und Adversarial Attacks zu erkennen und abzuschwächen. Die präventive Absicherung während des Trainingsprozesses und die ständige Überwachung während der Inferenzphase werden essenziell, um potenzielle Schwachstellen frühzeitig zu identifizieren und zu entschärfen. Ein vielversprechender Ansatz zur Stärkung der Sicherheit besteht auch in der Kombination von Deep Learning mit anderen Technologien, wie beispielsweise Blockchain. Blockchain kann als dezentrales Sicherheitsprotokoll fungieren, um die Integrität der Trainingsdaten zu gewährleisten und Angriffe auf das Modell zu erschweren.
Insgesamt bleibt die Sicherheit von Deep Learning Systemen ein fortlaufendes Forschungsgebiet mit vielen Facetten. Die Forscher und Entwickler müssen sich dabei immer wieder in die Rolle der Angreifer, als auch die der Verteidiger versetzen, um die Sicherheit der Systeme verbessern zu können. In den kommenden Jahren werden immer mehr Angriffe auf Neuronale Netze möglich sein, die auch für die breite Masse an Angreifern interessant werden. Bis dahin werden aber hoffentlich auch starke Gegenmaßnahmen und Abwehrtechniken entwickelt, um vor solchen Angriffen sicher zu sein.
Literatur
| [1] | SCS. „Simplifying the Difference: Machine Learning vs Deep Learning.” https://www.scs.org.sg/articles/machine-learning-vs-deep-learning (Zugriff am: 19. Juli 2023). |
| [2] | IBM. „Was ist Deep Learning?” https://www.ibm.com/de-de/topics/deep-learning (Zugriff am: 18. Juli 2023). |
| [3] | J. Ronsdorf. „Microsoft erklärt: Was ist Deep Learning? Definition & Funktionen von DL | News Center Microsoft.” https://news.microsoft.com/de-de/microsoft-erklaert-was-ist-deep-learning-definition-funktionen-von-dl/ (Zugriff am: 18. Juli 2023). |
| [4] | W. Chai. „What is the CIA Triad? Definition, Explanation, Examples | TechTarget.” https://www.techtarget.com/whatis/definition/Confidentiality-integrity-and-availability-CIA (Zugriff am: 19. Juli 2023). |
| [5] | Y. He, G. Meng, K. Chen, X. Hu und J. He, „Towards Security Threats of Deep Learning Systems: A Survey,“ IEEE Transactions on Software Engineering. [Online]. Verfügbar unter: https://arxiv.org/pdf/1911.12562 |
| [6] | ODSC – Open Data Science, „Exploring the Security Vulnerabilities of Neural Networks,“ Medium, 11. Juli 2022. https://odsc.medium.com/exploring-the-security-vulnerabilities-of-neural-networks-4a4f5b5987b8 (Zugriff am: 15. Juli 2023). |
| [7] | B. Graff, „Chat-Bot “Tay” lernt im Internet – vor allem Rassismus,“ Süddeutsche Zeitung, 03. April 2016. https://www.sueddeutsche.de/digital/microsoft-programm-tay-rassistischer-chat-roboter-mit-falschen-werten-bombardiert-1.2928421 (Zugriff am: 24. Juli 2023). |
| [8] | A. Polyakov, „How to attack Machine Learning ( Evasion, Poisoning, Inference, Trojans, Backdoors),“ Towards Data Science, 06. August 2019. https://towardsdatascience.com/how-to-attack-machine-learning-evasion-poisoning-inference-trojans-backdoors-a7cb5832595c (Zugriff am: 15. Juli 2023). |
| [9] | N. Adams, „Model inversion attacks | A new AI security risk,“ Michalsons, 08. März 2023. https://www.michalsons.com/blog/model-inversion-attacks-a-new-ai-security-risk/64427 (Zugriff am: 24. Juli 2023). |
| [10] | I. J. Goodfellow, J. Shlens und C. Szegedy, „Explaining and Harnessing Adversarial Examples,“ Dez. 2014. [Online]. Verfügbar unter: https://arxiv.org/pdf/1412.6572 |
| [11] | J. Despois, „Adversarial Examples and their implications – Deep Learning bits #3,“ HackerNoon.com, 11. August 2017. https://medium.com/hackernoon/the-implications-of-adversarial-examples-deep-learning-bits-3-4086108287c7 (Zugriff am: 15. Juli 2023). |
| [12] | Adversa, „The Road to Secure and Trusted AI: The Decade of AI Secruity Challenges,“ Rep. 1.1, Apr. 2021. |
Leave a Reply
You must be logged in to post a comment.