Anmerkung: Dieser Blogpost wurde für das Modul Enterprise IT (113601a) verfasst.
Aus Gründen der besseren Lesbarkeit wird in dieser Arbeit auf eine geschlechtsneutrale Differenzierung verzichtet. Sämtliche Personenbezeichnungen gelten gleichermaßen für alle Geschlechter.
Kurzfassung
Die Branche der fortschreitenden Cloud Digitalisierung und die steigenden Anforderungen an hochverfügbaren, skalierbaren Anwendungen haben Kubernetes zu einer der führenden Container-Orchestratoren gemacht. Eines der zentralen Aspekte dieser Cloud-Umgebungen ist die automatische Skalierung von Clustern, um sich an den ständig ändernden Intensitäten der Ressourcensnachfragen anzupassen indem sichergestellt wird, dass Ressourcen effizient genutzt werden und somit letztendlich auch die Betriebskosten optimiert werden. Diese automatische Skalierungsfunktion lässt sich traditionell mit einem einfachen Parametersatz anpassen, dieser arbeitet aber auf statischen Regeln oder einfachen Heuristiken, die häufig nicht optimal auf dynamische schwankenden Webanfragen reagieren können. Die wachsende technologische Entwicklung im Bereich der Künstliche Intelligenz (KI) eröffnet neue Möglichkeiten zur Optimierung von Auto-Scaling-Strategien, die auf die tatsächliche Variabilität eingehender Anfragen eingeht und zukünftige Anforderungen vorhersagen und seine Skalierungsstrategien adaptiv und in Echtzeit implementieren kann. Dadurch lassen sich grundlegend konkurrierende Mechanismen entwickeln, die sowohl durch ihre Effizienz als auch durch ihre Reaktionsgeschwindigkeit verlorene Anfragen deutlich reduzieren.
Einleitung
Kubernetes ist derzeit eines der beliebtesten Open-Source-Orchestrierungssystemen zu Verwaltung von containisierter Anwendungen, die von Dienstanbietern verwendet werden. Es bietet mitunter in Bezug auf Bereitstellung, Skalierung und Verwaltung den vollständigen Lebenszyklus von Anwedungskomponenten. Einer der wichtigsten Funktionen, um die Bereitstellung containerisierter Anwendungen auf dynamische Benutzerauslastungen zu gewährleisten ist die automatische Skalierung.[1]
Die Auswahl der richtigen Skalierungsstrategie hängt unter anderem von der Art der Anwendung ab, weshalb wir in diesem Abschnitt erstmal die Anwendungsarchitekturen betrachten. Traditionell wurden viele Anwendungen in einer monolithischen Architektur entwickelt. Hierbei sind alle oder die meisten Komponenten und Funktionen in einer einzigen, engverbundenen Codebasis enthalten[2]. Diese werden in der Regel in einem einzigen Kubernetes-Container bereitgestellt, was zwar die initiale Entwicklung erleichtert, jedoch in Bezug auf Skalierbarkeit und Wartung oft die erneute Bereitstellung der gesamten Anwendung erfordert. Microservice-basierte Anwendungen hingegen bestehen aus mehreren eigenständigen Diensten, die miteinander interagieren und daher zunehmend eingesetzt werden, um den Herausforderungen der monolithischen Architektur zu begegnen. Hierbei wird die Anwendung in Services unterteilt, die unabhängig voneinander einsatzfähig und skalierbar sind. Autoskalierungsansetze müssen hier allerdings die Abhängigkeiten zwischen den Diensten berücksichtigen.[3]
Eine bewährte Methode zur Skalierung von Anwendungen ist das Scale Cube Modell, das drei verschiedene Skalierungsansätze definiert.
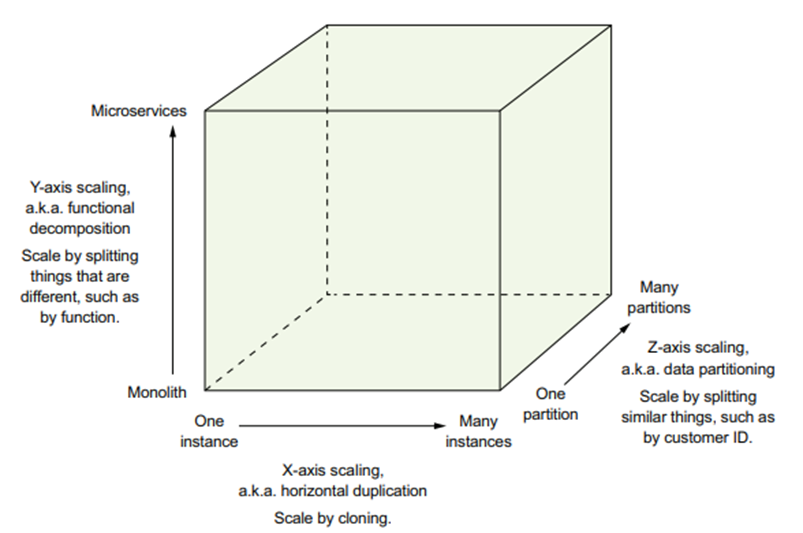
Abbildung 1: Das Scale Cube Modell zur Software-Architektur.
- X-Achsen-Skalierung (Horizontal Duplication): Hierbei werden mehrere identische Instanzen einer Anwendung hinter einem Load Balancer betrieben, um die Kapazität und Verfügbarkeit zu erhöhen.
- Z-Achsen-Skalierung (Data Partitioning): In diesem Modell werden Anfragen basierend auf einer bestimmten Datenattribut (z. B. userId) an dedizierte Instanzen weitergeleitet, wodurch die Effizienz bei großen Datenmengen verbessert wird.
- Y-Achsen-Skalierung (Functional Decomposition): Diese Methode unterteilt eine monolithische Anwendung in verschiedene Microservices, die unabhängig voneinander skaliert werden können. Dadurch wird die Entwicklung und Wartung erleichtert.[4]
Kubernetes bietet eine Vielzahl von Tools zur Implementierung dieser Skalierungsstrategien, darunter:
- Horizontal Pod Autoscaler (HPA): Dieser unterstützt die Hochverfügbarkeit, indem er die Anzahl der Pods also die Anzahl der ausführbaren Einheiten auf Grundlage verschiedener vordefinierten Metriken wie z.B CPU- und Speicherauslastung dynamisch anpasst.
- Vertical Pod Autoscaler (VPA): Diese Methode ändert die Spezifikationen der Ressourcenanforderungen für bestehende Pods und hält die Anzahl der funktionierenden Pods aufrecht. Dies ist besonders vorteilhaft für Workloads mit stark schwankenden Ressourcenbedarf.
- Cluster Autoscaler (CA): Dieser skaliert die Anzahl der Worker-Knoten, die die eigentlichen Container-Workloads ausführen, indem er neue Knoten hinzufügt oder ungenutzte Knoten entfernt.[5]
Durch die Kombination dieser Skalierungsmechanismen ermöglicht Kubernetes eine effiziente und dynamische Ressourcennutzung.
Stand der Forschung und Technologische Lösungen
Nachdem die verschiedenen Mechanismen von Kubernetes nun erläutert wurden, ist es essenziell, die Methoden der automatischen Skalierung im Hinblick auf Timing zu betrachten. Insbesondere lassen sich die genannten Ansätze in reaktive und proaktive Skalierung unterteilen, die jeweils unterschiedliche Herangehensweisen verfolgen.
Die reaktive Skalierung ist der standardmäßig implementierte Ansatz in Kubernetes. Hierbei werden Skalierungsentscheidung, beispielsweise durch den Horizontal Pod Autoscaler, basierend auf bereits gemessenen Lastwerten getroffen. Sobald die Last von CPU- oder Speichernutzung also vordefinierte Schwellenwerte überschreiten, werden Instanzen entweder gestartet oder gestoppt. Nachteile dieses Verfahren bestehen in der Verzögerung, die geschieht, weil die Skalierung erst unmittelbar nach einem Lastszenario erfolgt und es dann einige Zeit dauert bis die zusätzlichen Ressourcen zur Verfügung stehen. Wegen dieser temporären Leistungseinbüße eignet sich die reaktive Skalierung eher für Workloads mit einer langsam ansteigenden Last, bei denen eine kurze Verzögerung weniger auffällt.
Die folgende Abbildung verdeutlicht das Konzept der reaktiven Skalierung:
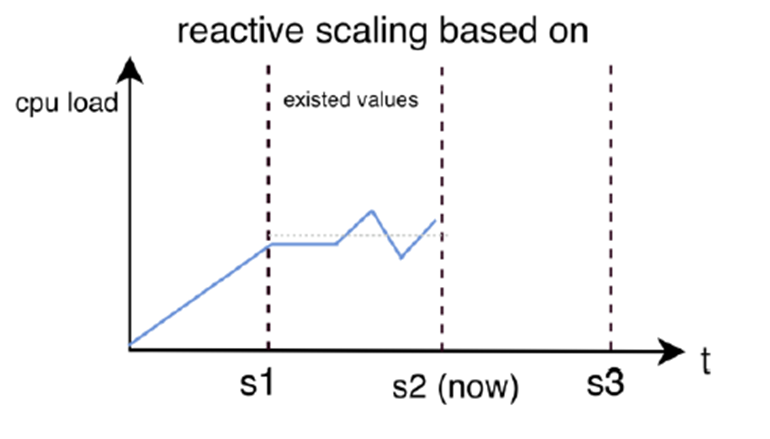
Abbildung 2: Reaktives Skalieren basierend auf CPU-Last über die Zeit.
Hier lässt sich deutlich erkennen, dass die Skalierung erst auf Grundlage bestehender Metriken erfolgt. Trotz ansteigender CPU-Last werden Instanzen erst nach dem Erreichen bestimmter Lastwerte bereitgestellt.
Im Gegensatz zur reaktiven Skalierung basiert die proaktive Skalierung auf einer vorausschauenden Analyse der Lastentwicklung und bildet die Basis für den Einsatz von maschinellem Lernen in diesem Bereich[6]. Hierbei können zukünftige Lastspitzen frühzeitig erkannt und rechtzeitig Ressourcen bereitgestellt werden, um Systemauslastungsmuster zu erkennen. Diese Vermeidung von Verzögerung ist ein klarer Vorteil der proaktiven Skalierung und führt zu einer stabileren Systemleistung. Allerdings setzt diese Methode auf eine hohe Vorhersagegenauigkeit des verwendeten Modells voraus, da Fehlvorhersagen zu einer ineffizienten Ressourcennutzung führen.[7]
Die folgende Abbildung zeigt die Funktionsweise der proaktiven Skalierung:
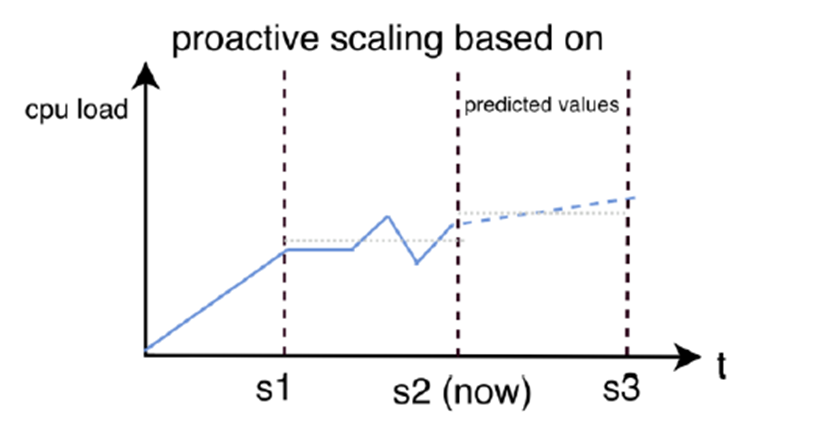
Abbildung 3: Proaktives Skalieren basierend auf vorhergesagter CPU-Last.
Hier wird deutlich, dass nicht erst bei steigender Last eine Skalierung erfolgt, sondern aufgrund von Vorhersagen.
Künstliche Intelligenz und besonders maschinelles Lernen spielt also eine zunehmend wichtige Rolle, um die Genauigkeit von Skalierungsvorhersagen zu verbessern und bietet damit eine vielversprechende Möglichkeit im Gegensatz zu regelbasierten Systemen die Effizienz durch Analyse von Lastmustern zu optimieren. Maschinelles Lernen lässt sich in überwachtes, unüberwachtes und verstärkendes (Reinforcement) Lernen unterteilen, wobei unüberwachtes Lernen zum Beispiel für die Vorhersage von Lastspitzen durch regressive Modelle besonders relevant für Kubernetes-Auto-Scaling ist. Ebenso relevant ist das Reinforced Learning, in dem es kontinuierlich aus den Systemreaktionen lernt.[8] Diese Techniken helfen dabei eine dynamische, adaptive Skalierung zu erreichen die auch komplexe Muster erkennen und sich somit an die unterschiedlichsten Workloads anpassen können.
Heutige Kubernetes-Implementierungen setzen vermehrt auf eine reaktive Skalierung, obwohl diese Vorgehensweise Verzögerungen hervorbringt, da Ressourcen wie bereits erwähnt erst nach dem Erreichen definierter Lastwerte bereitgestellt werden. Um dieser beeinträchtigenden Wirkung auf die Servicequalität (QoS) entgegenzuwirken, fokussiert sich die aktuelle Forschung zunehmend auf die proaktive Skalierung. Im Folgenden werden diese Fortschritte und die damit entstandenen KI-gestützten Skalierungsmethoden detailliert betrachtet und deren Effektivität im Kubernetes-Umfeld bewertet.
Zeitreihenbasierte Vorhersagemodelle
Sie sind einer der am häufigsten untersuchten Methoden und dienen zur Verbesserung des Auto-Scaling-Prozesses. Basierend auf der Annahme, dass Workloads vorhersagbar und mustergesteuert sind, erwies es sich als besserer Ansatz im Gegensatz zum traditionellen Ansatz. Einige der etablierten Modelle sind:
- Auto Regressive Integrated Moving Average (ARIMA): Dieses am häufigsten verwendete Zeitreihenmodel analysiert Muster und ermöglicht die Vorhersage von zukünftigen Workload-Schwankungen und zeigt sich besonders leistungsfähig in stationären Zeitreihen[9]. Eine aktuelle Forschung schlägt außerdem eine optimierte Skalierung durch das EMD-ARIMA-Modell vor, welches eine Kombination des Empirical Mode Decomposition (EMD) und ARIMA darstellt und verbessertes proaktives Autoscaling verspricht, in dem es zur Analyse nicht stationärer Zeitreihen hilft und störende Workload-Schwankungen glättet.[10]
- Exponential Smoothing (ES) und Double Exponential Smoothing (DES): Diese Methoden sind ebenfalls weit verbreitet und gewichten vergangene Daten exponentiell abnehmend, sodass neuere Werte einen stärkeren Einfluss auf zukünftige Prognosen haben. Während das ES vor allem für stationäre Zeitreihen verwendet wird, wurde das DES entwickelt, um auch Trends in Daten zu berücksichtigen und damit eine höhere Vorhersagegenauigkeit als einfache exponentielle Glättungen zu bieten.[11]
Neuronale Netze und Deep Learning Verfahren
Sie haben sich als leistungsfähige Alternative insbesondere bei nicht-linearen und hochdynamischen Workloads gezeigt. In der Forschung werden auch hier mehrere Architekturen evaluiert:
- Long Short-Term Memory (LSTM)-Netzwerke: Diese rekurrenten neuronale Netze wurden speziell für die Modellierung von langfristigen Zeitreihen entwickelt und stellen sich damit als besonders geeignet für Kubernetes heraus, da sowohl kurzfristige als auch langfristige Workload-Abhängigkeiten erlernt werden können. Durch die Erweiterung des Bi-LSTM, werden Daten nicht nur vorwärts, sondern auch rückwärts verarbeitet, wodurch weitere Kontextinformationen erlernt werden, und eine noch höhere Prognosegenauigkeit erreicht wird.
- Multilayer Perceptrons (MLP) und Convolutional Neural Networks: MLP`s sind feedforward neuronale Netze, die in mehreren Schichten aus Neuronen organisiert sind. Sie zeigten sich besonders geeignet, um nicht-lineare Zusammenhänge in Skalierungsprognosen zu modellieren und Vorhersagen zur CPU, dem Speicher- und der Bandbreitennutzung in Kubernetes-Clustern zu treffen. Obwohl CNNs traditionell für Bildverarbeitung eingesetzt werden, haben sie sich durch ihre Faltungsoperationen erwiesen auch Muster in Workload-Daten zu extrahieren und hochfrequente Ressourcen-Schwankungen zu erkennen. In Kubernetes-Auto-Scaling-Anwendungen wurden 1D-CNNs erfolgreich zur Vorhersage von Workload-Änderungen eingesetzt.[12]
- Ensemble-Methoden: Sie sind eine vielversprechende Strategie, die darin besteht, mehrere heterogene ML-Modelle wie zum Beispiel LSTM, ARIMA und Random Forest zu kombinieren und damit die Gesamtleistung zu verbessern.[13]
Reinforcement Learning (RL)
Gewinnt zunehmend an Bedeutung in der Forschung, da es eine adaptive und selbst lernende Steuerung von Ressourcen ermöglicht.
- Deep Q-Networks (DQN): Diese Architektur kombiniert neuronale Netzwerke mit Q-Learning und hat sich in Experimenten als effizient erwiesen, um komplexe Skalierungsentscheidungen zu treffen.Um die Skalierungsleistung weiter zu optimieren, wurden fortgeschrittene Varianten von DQN entwickelt:
- Double DQN (DDQN): Reduziert die Überbewertung von Aktionen, indem zwei separate Q-Netzwerke verwendet werden – eines zur Aktionsauswahl und eines zur Bewertung der Belohnungen.
- Dueling DQN: Trennt den Entscheidungsprozess in zwei Netzwerke: eines für die Bewertung des aktuellen Zustands und eines für die Bestimmung der besten Skalierungsaktion. Dies verbesserten die Effizienz und Stabilität der Entscheidungsfindung
Konzeption einer KI-basierten Auto-Scaling-Lösung
Für eine Umsetzung in Kubernetes ist eine Architektur erforderlich, die verschiedene Komponenten integriert, Lastdaten erfasst, analysiert und darauf basierend dynamische Scaling-Entscheidungen trifft. Dabei ist es erforderlich, dass Kubernetes-eigene Skalierungsmechanismen eng mit externen KI-gestützten Modellen arbeiten, um somit Ressourcen effektiv und adaptiv bereitzustellen. Ein typisches Implementierungskonzept besteht aus den folgenden Kernkomponenten:
- Datenquellen und Metrik-Sammlung: Eine zuverlässige Datenerfassung bildet die Basis für eine intelligente Skalierung. Kubernetes bietet hierfür integrierte Dienste wie den Metrics Server[14], welcher Echtzeit-CPU- und -Speicherwerte bereitstellt. Diese werden jedoch für eine tiefere Analyse von externen Monitoring-Systemen wie Prometheus[15] genutzt und persistent gespeichert.
- Vorverarbeitung und Datenanalyse: Nach dem Erfassen der Metriken müssen diese für das maschinelle Lernen aufbereitet werden. Hierzu werden die Daten in zentralen Datenbanken gespeichert und anschließend Methoden der Datenbereinigung, Normalisierung und des Feature-Engineerings angewandt, um eine hohe Vorhersagegenauigkeit zu gewährleisten. Für Kubernetes erfolgt dies häufig mit Hilfe von Apache Kafka oder Flink[16][17], die eine Datenverarbeitung in Echtzeit ermöglichen.
- Maschinelles Lernmodell: Die Lastprognose ist der Kern dieser Implementierung und kann durch verschiedene Algorithmen entweder in einem dedizierten Kubernetes-Pod oder als externer Machine-Learning-Service (z. B. über TensorFlow Serving oder MLflow)[18][19] betrieben werden. Die verschiedenen Algorithmen wurden im vorherigen Abschnitt behandelt.
- Entscheidungs- und Steuerungsebene: Das trainierte Modell gibt Vorhersagen zur Systemlast aus, die nun in konkrete Skalierungsentscheidungen umgewandelt werden müssen. Hierfür kann ein Custom Controller oder ein Operator[20] in Kubernetes implementiert werden, der dann entsprechende Kubernetes-API-Aufrufe basierend auf den Vorhersagen ausführt, um die Skalierung einzuleiten. Ein möglicher Ansatz wäre die Integration eines Horizontal Pod Autoscalers mit einem externen Custom Metrics Provider, welcher die KI-basierten Prognosen als Entscheidungsgrundlage nutzt.
- Deployment und Integration: Die gesamte Architektur wird in Kubernetes als Microservice-basierte Lösung implementiert. Dabei kann eine typische Pipeline folgendermaßen aufgebaut sein:
- Prometheus oder InfluxDB sammelt Metriken.
- Apache Kafka oder Flink verarbeitet Echtzeit-Daten.
- Ein Machine-Learning-Service führt Modell-Inferenzen aus.
- Ein Custom Controller oder Operator steuert die Skalierung über die Kubernetes-API.
Fazit und Ausblick
Auto-Scaling von Kubernetes-Clustern ist ein sehr zentraler Bestandteil moderner Cloud-Umgebungen, um Ressourcen zu Webanfragen effizient zu managen und die Betriebskosten zu optimieren. Während traditionelle Skalierungsmechanismen wie der HPA oder der CA auf statischen Regeln basieren, zeigt die Forschung immer mehr Fortschritte in KI-gestützten Methoden und bietet damit neue, flexiblere und genauere Strategien zur Bewältigung der Cluster-Skalierung.
Durch den Einsatz von Machine und Reinforcement Learning kann eine proaktive Skalierung realisiert werden, die Lastveränderungen präzise vorhersagt und adaptiv anpasst. Insbesondere Verfahren wie LSTM, ARIMA und Exponential Smoothing haben sich als vielversprechende Alternativen erwiesen.
Zusammenfassend lässt sich feststellen, dass KI-basierte Auto-Scaling-Lösungen das Potenzial haben, solche Systeme intelligenter und ressourcenschonender zu verwalten und auch zukünftig verstärkt in Forschungen vorkommen sollten, damit sie eine breite Akzeptanz in der Praxis finden.
Literaturverzeichnis
[1] Hohn, A., & Gupta, A. (Jahr). Getting Started with Kubernetes. Packt 2017
[2] Velepucha, Victor & Flores, Pamela. (2023). A Survey on Microservices Architecture: Principles, Patterns and Migration Challenges. IEEE Access. PP. 1-1. 10.1109/ACCESS.2023.3305687.
[3] Burns, B., Beda, J., Hightower, K., & Evenson, L. Kubernetes: Eine kompakte Einführung. Dpunkt.verlag 2023
[4] Chris Richardson. microservices patterns. manning publications, 2018.
[5] Nguyen, T.-T.; Yeom, Y.-J.; Kim, T.; Park, D.-H.; Kim, S. Horizontal Pod Autoscaling in Kubernetes for Elastic Container Orchestration. Sensors 2020, 20, 4621. https://doi.org/10.3390/s20164621
[6] Ajila, S. A., & Bankole, A. A. (2013). Cloud client prediction models using machine learning techniques. Proceedings of the 2013 IEEE 37th Annual Computer Software and Applications Conference (COMPSAC), 2013
[7] Aslanpour, M. S. & Dashti, S. E. (2017). Proactive Auto-Scaling Algorithm (PASA) for Cloud Application. International Journal of Grid and High Performance Computing (IJGHPC), 9(3),
[8] Alam, Azmir. (2023). What is Machine Learning?. 10.5281/zenodo.8231580.
[9] Al-Qazzaz, Redha & Yousif, Suhad. (2022). High performance time series models using auto autoregressive integrated moving average. Indonesian Journal of Electrical Engineering and Computer Science. 27. 422. 10.11591/ijeecs.v27.i1.pp422-430.
[10] Zhao, Anqi & Huang, Qiang & Huang, Yiting & Zou, Lin & Chen, Zhengxi & Song, Jianghang. (2019). Research on Resource Prediction Model Based on Kubernetes Container Auto-scaling Technology. IOP Conference Series: Materials Science and Engineering. 569. 052092. 10.1088/1757-899X/569/5/052092.
[11] Aimran, Ahmad. (2014). A comparison between single exponential smoothing (SES), double exponential smoothing (DES), holt’s (brown) and adaptive response rate exponential smoothing (ARRES) techniques in forecasting Malaysia population. Global Journal of Mathematical Analysis. 2. 276-280. 10.14419/gjma.v2i4.3253.
[12] Dang-Quang, Nhat-Minh & Yoo, Myungsik. (2021). Deep Learning-Based Autoscaling Using Bidirectional Long Short-Term Memory for Kubernetes. Applied Sciences (Switzerland). 11. 10.3390/app11093835.
[13] Pereira da Silva, Thiago & Batista, Thaís & Delicato, Flavia & Pires, Paulo. (2023). An Online Ensemble Method for Auto-scaling NFV-based Applications in the Edge. 10.21203/rs.3.rs-3490431/v1.
[14] Kubernetes. (n.d.). Metrics Server. Retrieved February 15, 2025, from https://kubernetes.io/docs/tasks/debug/debug-cluster/resource-metrics-pipeline/.
[15] Prometheus. (n.d.). Prometheus – Monitoring System & Time Series Database. Retrieved February 15, 2025, from https://prometheus.io/.
[16] Ververica. (2023). Apache Flink and Prometheus: Monitoring Streaming Applications. Retrieved February 14, 2025, from https://www.ververica.com/blog/apache-flink-and-prometheus-monitoring-streaming-applications.
[17] Apache Software Foundation. (n.d.). Apache Kafka – A Distributed Streaming Platform. Retrieved February 15, 2025, from https://kafka.apache.org/.
[18] Databricks. (n.d.). MLflow: An Open-Source Platform for the Machine Learning Lifecycle. Retrieved February 14, 2025, from https://mlflow.org/.
[19] Google. (n.d.). TensorFlow Serving – Flexible, high-performance ML model serving. Retrieved February 15, 2025, from https://www.tensorflow.org/tfx/guide/serving.
[20] Kubernetes. (n.d.). Custom Controllers and Operators. Retrieved February 15, 2025, from https://kubernetes.io/docs/concepts/extend-kubernetes/operator/.
Abbildungsverzeichnis
Abbildung 1: Гутман, Д & Сирота, O.. (2023). Проактивне автоматичне масштабування вверх для Kuberneters. Адаптивні системи автоматичного управління. 1. 32-38. 10.20535/1560-8956.42.2023.278925.
Abbildung 2: Гутман, Д & Сирота, O.. (2023). Проактивне автоматичне масштабування вверх для Kuberneters. Адаптивні системи автоматичного управління. 1. 32-38. 10.20535/1560-8956.42.2023.278925.
Abbildung 3: Richardson, C. (2018). Microservices patterns. Manning Publications.
Leave a Reply
You must be logged in to post a comment.