Dieser Blogbeitrag soll einen Einblick in die Entwicklung unserer Webanwendung mit den unten definierten Funktionen geben sowie unsere Lösungsansätze, Herausforderungen und Probleme aufzeigen.
Cloud Computing Vorlesung
Ziel der Vorlesung “Software Development for Cloud Computing” ist es, aktuelle Cloud Technologien kennen zu lernen und diese im Rahmen von Übungen und kleinen Projekten anzuwenden. Unser Team hat sich im Rahmen dieser als Prüfungsleistung zu erbringenden Projektarbeit dazu entschieden, das bekannte Spiel „Stadt, Land, Fluss“ als Multiplayer-Online Game umzusetzen.
Projekt Idee & Inspiration
Zu Beginn der Vorlesung war sich unsere Projektgruppe noch sehr unsicher, was wir als Projekt mit Cloudkomponenten umsetzen wollten, da wir noch keine bis sehr geringe Vorerfahrung in der Cloud-Entwicklung hatten. Erste Brainstormings hatten ergeben, dass wir gerne eine Webanwendung entwerfen wollten. Jedoch war es gar nicht so leicht Zugriff zu interessanten Daten zu bekommen.
Letztendlich hat sich unsere Gruppe dazu entschieden, sich nicht von Daten abhängig zu machen, sondern etwas Eigenes zu kreieren.
Die Inspiration für unsere finale Idee (Stadt-Land-Fluss) war das Online-Spiel Skribbl IO, ein kostenloses Multiplayer-Zeichen- und Ratespiel. Dabei wird in jeder Runde ein Spieler ausgewählt, der etwas zeichnet, das die anderen erraten sollen. Skribbl ermöglicht es dem Spieler auch, einen eigenen Raum zu erstellen und Freunde einzuladen, die einen Link zu diesem Raum teilen.
Im Rahmen unseres Projektes hat uns die Idee gefallen etwas zu entwickeln, was man danach mit Freunden zusammen nutzen kann. Den Multiplayer Ansatz fanden wir spannend, da wir so etwas noch nie umgesetzt haben. Da wir alle Stadt-Land-Fluss Fans sind, fiel unsere Wahl auf dieses Spiel.
Ziel
Primäres Ziel des Projektes war es für uns, erste Erfahrungen in Cloud-Computing zu sammeln und gleichzeitig unsere Fähigkeiten im Software-Engineering auszubauen.
Konkret war es die Idee ein Stadt-Land-Fluss Spiel mit den folgenden Funktionalitäten zu entwickeln:
- Schritt 1: Raumerstellung
- Spieler kann einen neuen Raum erstellen, oder über eine Raum-Id einem Raum beitreten
- Schritt 2: Spieldaten bestimmen
- Der Spieler, welcher einen Raum erstellt, soll die Kategorien selber bestimmen können, sowie die Zeit, welche man für das Ausfüllen einer Spielrunde hat, ebenfalls sollen Mitspieler- und Rundenanzahl bestimmt werden können
- Schritt 3: Waiting Room
- Nach Erstellen oder Beitreten eines Raumes, kommt der Spieler in einem Warteraum, wo er die festgelegten Parameter der Spielrunden sieht und informiert wird, welche Spieler der Runde schon beigetreten sind
- Schritt 4: Letter Generator
- Der Buchstabe für eine Runde soll zufällig generiert werden, sich aber nicht wiederholen innerhalb eines Spiels
- Schritt 5: Spielrunde
- Auf der Seite der Texteingaben, soll ein Spieler die Runde stoppen können, sobald er alles ausgefüllt hat, dies triggert den Stopp bei allen Mitspielern
- Schritt 6: Kontrollieren der Eingaben
- Alle Spieler sehen nach einer Runde ihre eigenen, aber auch alle anderen Eingaben der Mitspieler sowie die Punkte, die dabei erreicht wurden
- Dabei werden die Punkte nach folgendem Schema berechnet:
- Hat ein Spieler als Einziger in dieser Kategorie eine Eingabe und ist diese auch gültig (beginnt mit dem generierten Buchstaben), dann erhält er für dieses Feld 20 Punkte
- Haben andere in diesem Feld auch Eingaben, erhält der Spieler für eine gültige Eingabe 10 Punkte
- Hat ein anderer Spieler in der gleichen Kategorie die gleiche Angabe, erhält der Spieler 5 Punkte
- Ist die Eingabe leer oder beginnt sie nicht mit dem generierten Buchstaben, werden keine Punkte vergeben
- Schritt 7 : Hall of Fame
- Darstellung der Spieler-Ränge und ihrer Punkte nach Abschließen aller Runden
Das erste Mockup der zu erstellenden Webanwendung entsprach folgendem Design und war unser Leitfaden für die Entwicklungsphase:
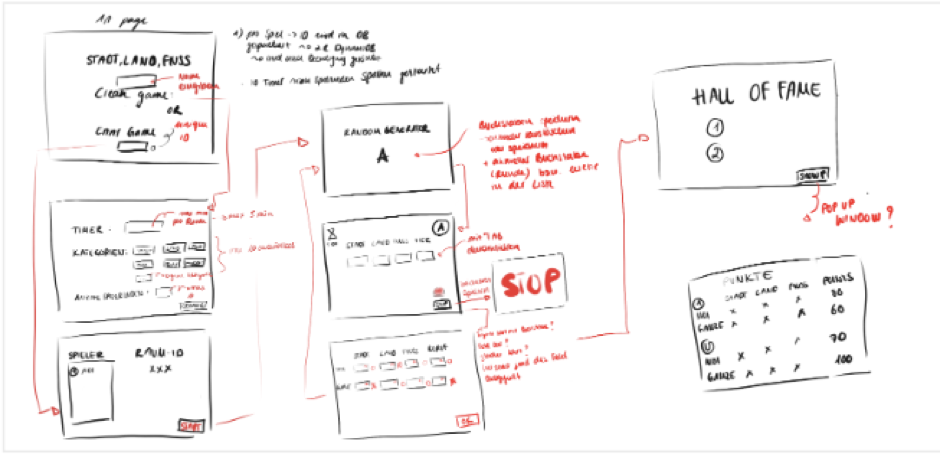
Einblick in das Spiel – Demo
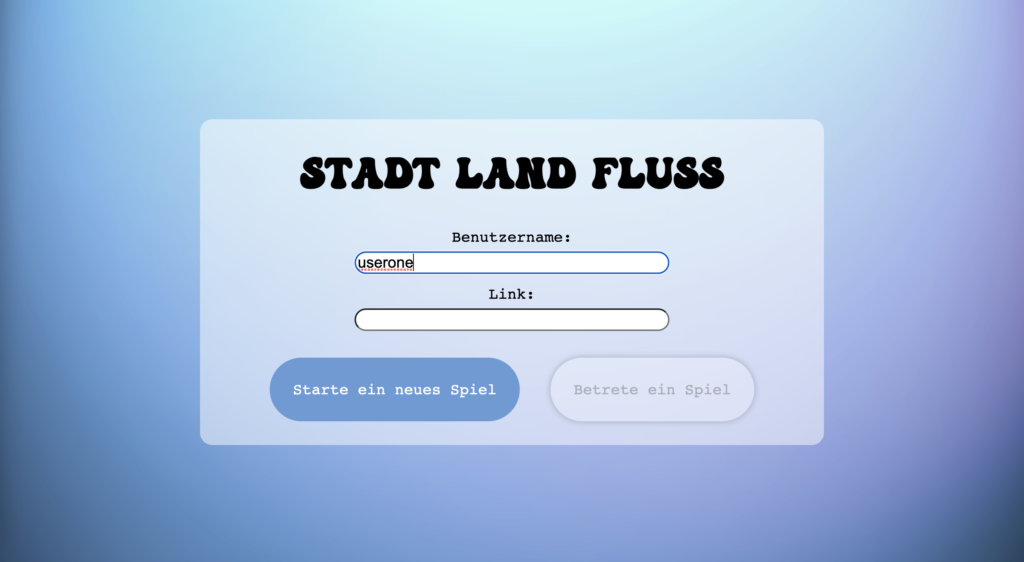
Startseite: Erstelle einen Raum oder betrete ein Spiel 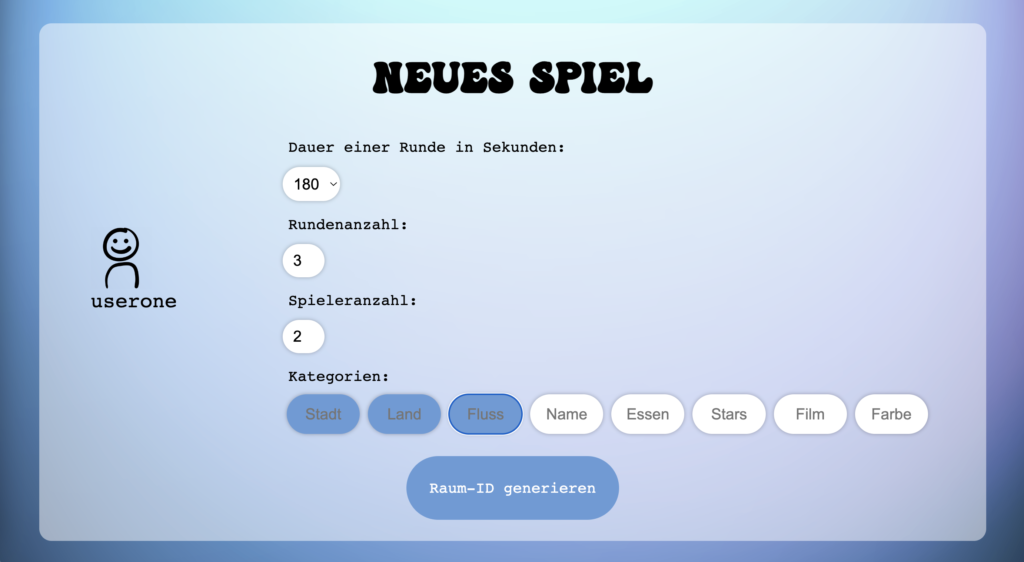
Erstelle ein neues Spiel 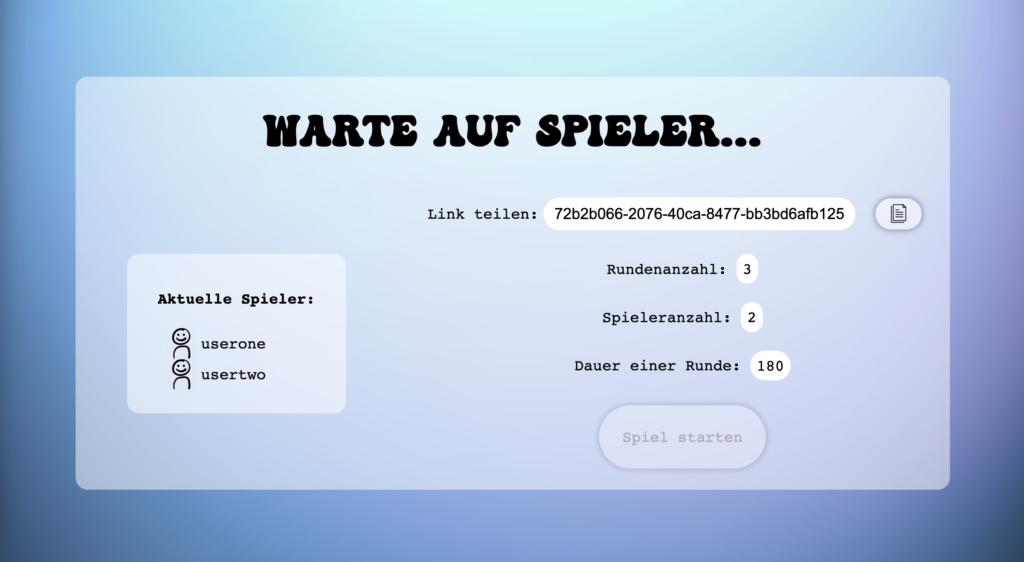
Teile den Link und warte auf weitere Spieler 
Ein Buchstabe wird zufällig generiert 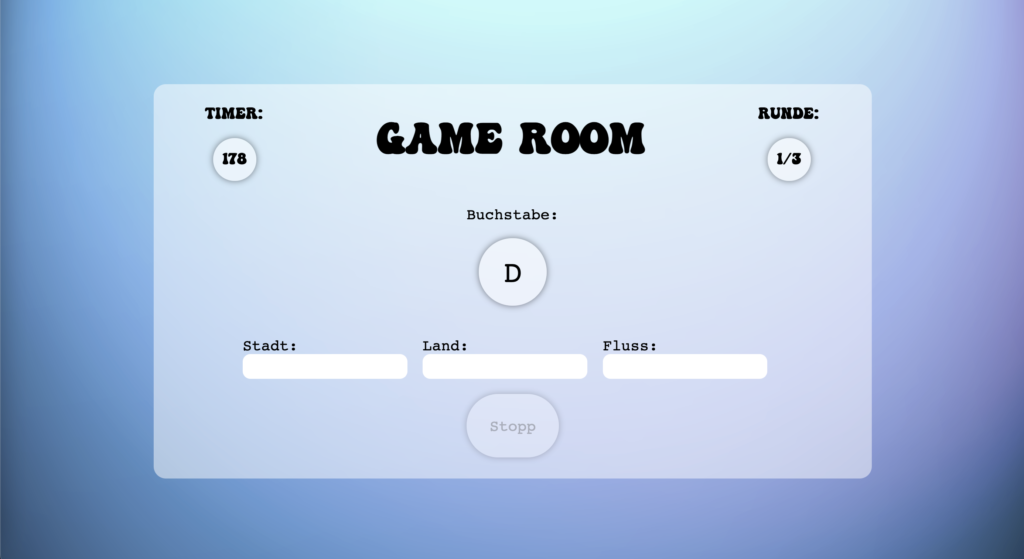
Spielraum, bei dem der User seine Wörter eingibt und auf Stopp drückt, sobald er alle Felder gefüllt hat. Der Timer zählt anschließend von 10 Sekunden auf 0 runter. 
Siehe Ergebnisse der anderen nach jeder Runde 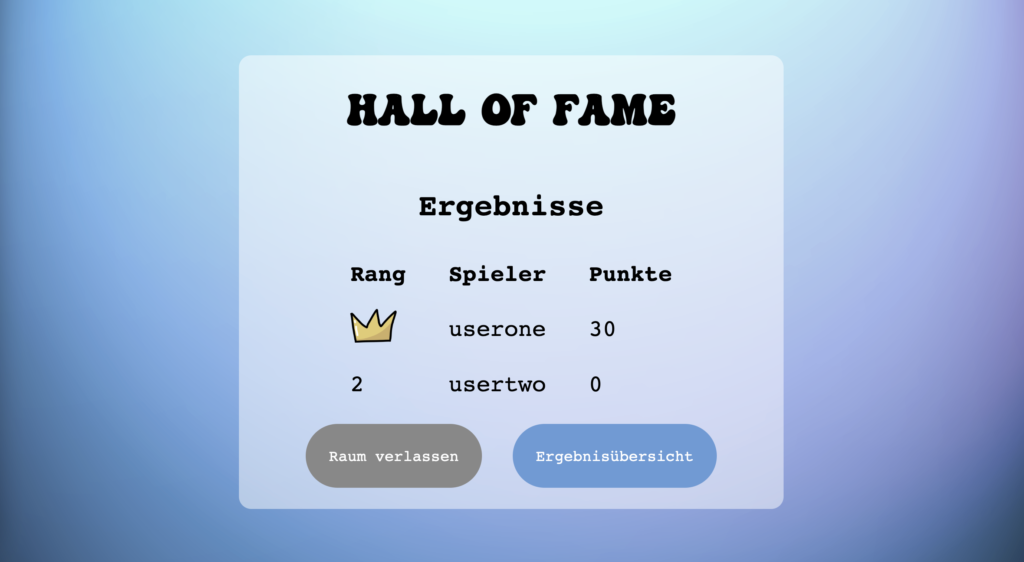
Siehe den Gewinner in der Hall of Fame 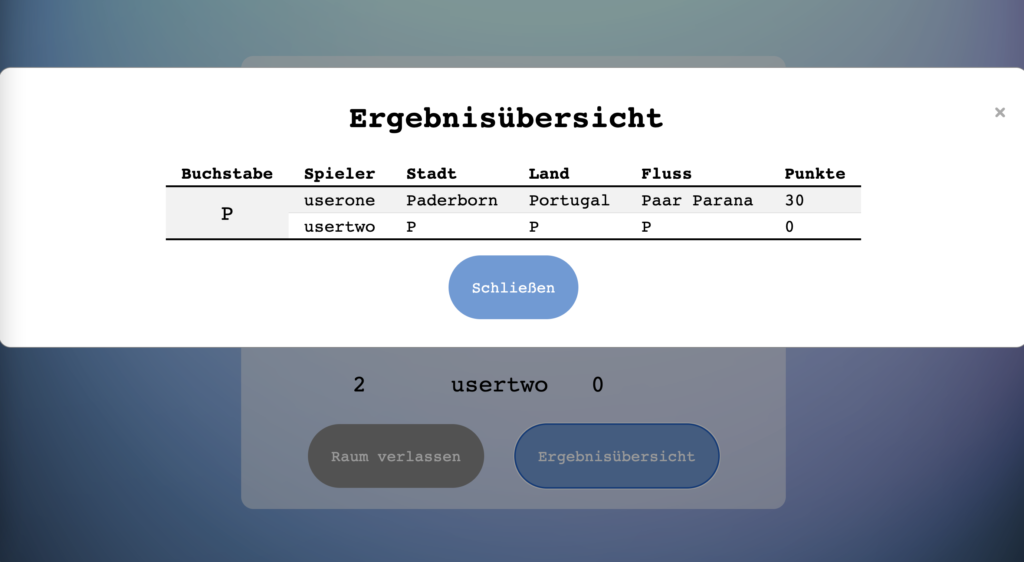
Siehe die Ergebnisübersicht aller Runden
Frameworks – Cloud Services – Infrastructure
Frontend
Aufgrund von vorhandenen Vorerfahrungen wurde die zweite Entscheidung getroffen, das Frontend mit Hilfe des Angular Frameworks umzusetzen. Angular ist ein TypeScript-basiertes Front-End-Webapplikationsframework. Das Backend wurde mit Python als Programmiersprache umgesetzt. Zum einen war hier mehr Vorerfahrung vorhanden bei einigen Teammitgliedern und zum anderen haben wir mehr Beispiele zur Anwendung von Websockets und AWS im Zusammenhang mit Angular gefunden, was uns sehr geholfen hat.
Backend
Wie zu Beginn schon erwähnt, hat uns die parallel zum Projekt laufende Vorlesung gleich zu Beginn den großen Funktionsumfang von AWS aufgezeigt. Besonders interessant fanden wir die Einsatzmöglichkeiten von Lambda Funktionen. Im Zusammenhang damit hat uns die Funktion gefallen ein API Gateway aufzubauen zu können. Da man bei der Programmiersprache völlig frei wählen kann, haben wir uns für Python entschieden. In der Python Programmierung hatten wir als Team zwar wenig Erfahrung, haben aber in dem Projekt eine Chance gesehen, uns in dieses Thema weiter einarbeiten zu können und unsere Fähigkeiten zu verbessern.
Architektur
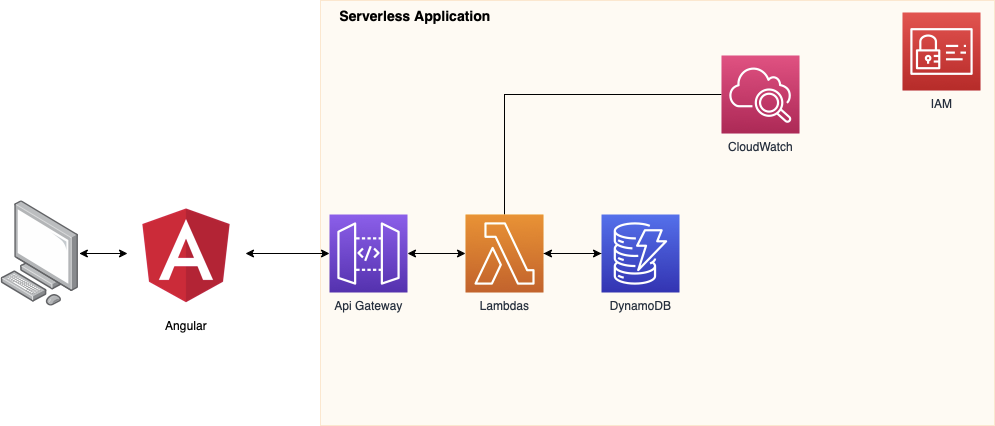
Cloud Komponenten
Vor dem Projektstart hatten wir zu Beginn die Schwierigkeit zu entscheiden, welchen Cloud-Anbieter wir für die Entwicklung nutzen wollen. Voraussetzungen für die Entscheidungen waren, dass es eine ausführliche Dokumentation der Möglichkeiten und Funktionen gibt (aufgrund der mangelnden Vorerfahrung), ebenfalls wollten wir nicht eine Kreditkarte als Zahlungsoption hinterlegen müssen und auch keine bis sehr wenig Kosten verursachen.
Zu Beginn der Vorlesung hieß es noch, dass wir eventuell ein Konto bei der IBM-Cloud oder über AWS von der Hochschule bekommen würden. Allerdings war dies leider doch nicht der Fall, weswegen wir nach erstem Warten selbst eine Entscheidung treffen mussten. Wir haben uns schlussendlich für AWS (Amazon Web Services) entschieden, da es einer der führenden Anbieter im Cloud Computing ist. Hierbei hat uns gefallen, dass es sehr viele Tutorials und gute Dokumentation zu den einzelnen AWS Services gab. Ein Nachteil war, dass man beim Anlegen eines Kontos eine Kreditkarte hinterlegen musste. Vorteil war andererseits, dass man mit einem Gratis-Kontingent (Free Tier) an Funktionsaufrufen, Rollen, und DB Kapazitäten etc. startet, weswegen im Rahmen des Projektes dahingehend keine Kosten entstehen sollten. Im späteren Verlauf haben wir herausgefunden, dass man allerdings für die Funktionalität von AmazonCloudWatch, welches ein Service zur Einsicht der Logs ist, zahlen muss. Die Kosten waren nicht hoch, weswegen es kein Problem darstellte, allerdings sollte man sich eindeutig über die Kosten, welche bei der Entwicklung entstehen können, im Klaren sein, um nicht böse überrascht zu werden.
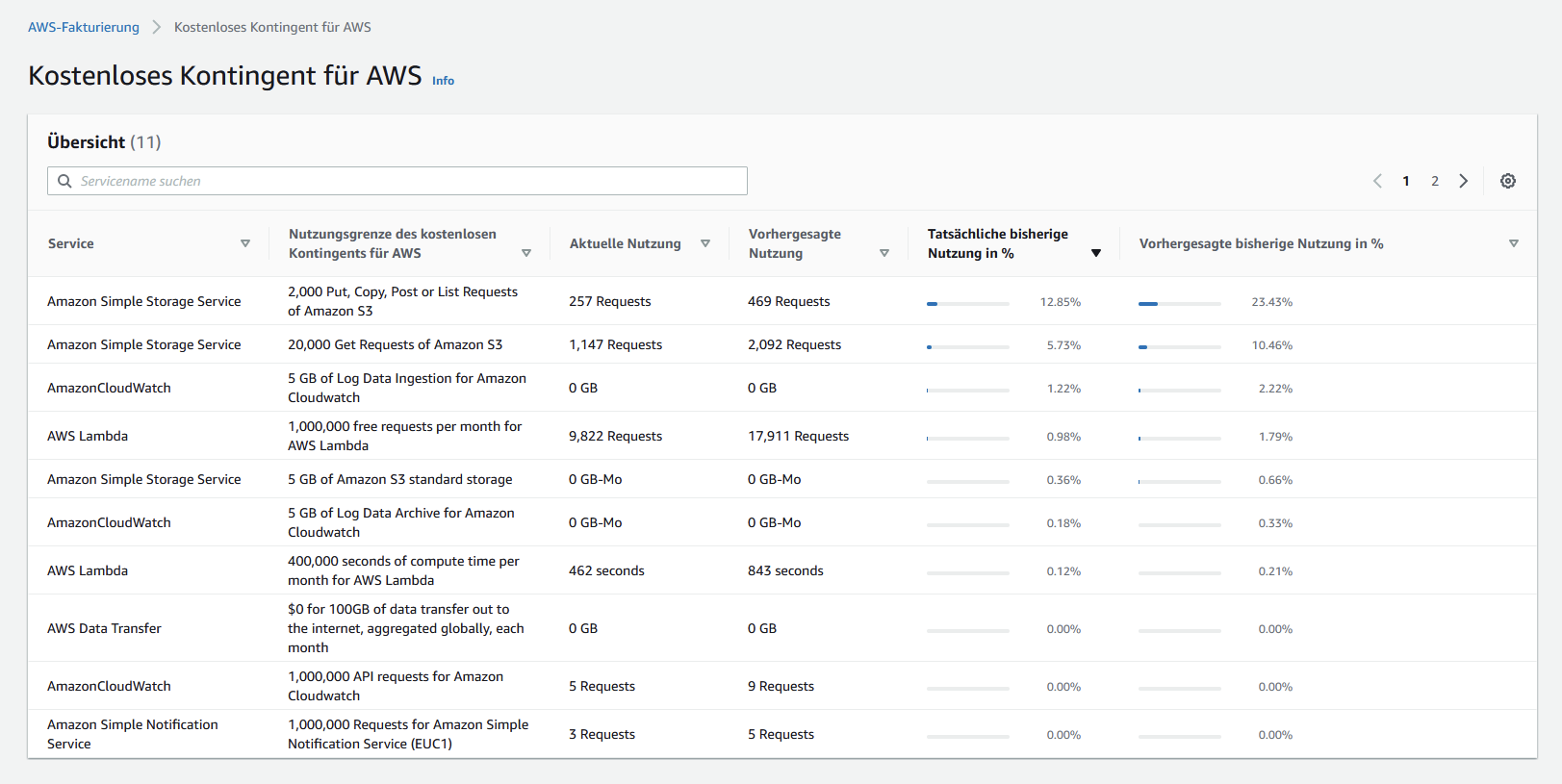
Übersicht Free Tier : https://aws.amazon.com/de/free/?all-free-tier.sort-by=item.additionalFields.SortRank&all-free-tier.sort-order=asc&awsf.Free%20Tier%20Types=tier%23always-free&awsf.Free%20Tier%20Categories=*all
AWS Services
Serverless
Für das Anlegen unseres Projektes und auch der späteren Möglichkeit einer übersichtlichen Vorlage des Codes zur Bewertung, haben wir nach einer Möglichkeit gesucht, alle für AWS benötigten Konfigurationen sowie das Anlegen der verschiedenen Lambda-Funktionen in unserem GitLab Reporsitory hinterlegen zu können und direkt im Code Editor bearbeiten und ändern zu können.
Nach einiger Recherche sind wir dabei auf das Serverless Framework gestoßen. Vorteile des Serverless Frameworks gegenüber der AWS Grafikoberfläche sind, dass alle man alle Elemente wie Datenbanken, Buckets, API-Routen und Aufrufe sowie Lambda Functions über eine serverless.yaml Datei verwalten kann. Zudem ist es nicht nötig, AWS-Kontoschlüsseln oder anderen Kontoanmeldeinformationen in Skripte oder Umgebungsvariablen zu kopieren oder einzufügen. Über die serverless.yaml können alle Ressourcen und Funktionen übersichtlich und schnell angelegt und bearbeitet werden.
Functions
In der serverless.yaml angelegte Lambda Funktionen entsprechen dem folgenden Schema :
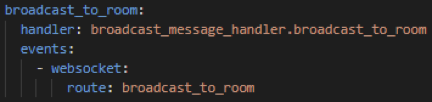
Die in der Datei definierten Funktionen werden jeweils über einen eigenen „handler“ referenziert. Das bedeutet, dass sie über ein „Event“ aufgerufen werden können. Ein Event entspricht dabei beispielsweise einem API-Aufruf.
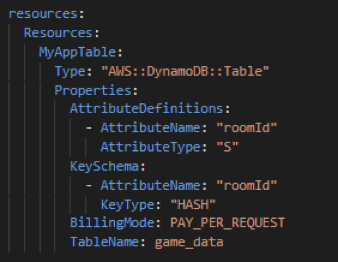
Resources
Neben unseren Funktionen sind in der serverless.yml ebenfalls alle Tabellen sowie Buckets definiert. Dies erleichtert die Einrichtung neuer Ressourcen, welche benötigt werden und gibt eine gute Übersicht.
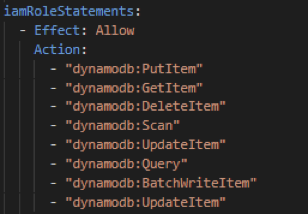
iamRoleStatements
Zudem können IAM-Rollen und Berechtigungen, die auf Lambda-Funktionen angewendet werden, konfiguriert werden.
Allgemeine Konfiguration
Es können ganz einfach allgemeine Settings angegeben werden, wie zum Beispiel:
Übersicht der Möglichkeiten: https://www.serverless.com/framework/docs/providers/aws/guide/serverless.yml/
Dynamo DB
Um unser Spiel umsetzen zu können, waren wir darauf angewiesen, bestimmte Daten in einer Datenbank zu speichern, dies waren beispielsweise Elemente wir eine Raum-ID, die Spielernamen, die gewählten Spielparameter, sowie die benutzen Buschstaben und eingetragene Ergebnisse der Spieler. Da die Einträge in der Datenbank immer variieren und keinem starren Muster folgen, beispielsweise ist es möglich eine unterschiedliche Zahl an Kategorien pro Spielraum zu haben, haben wir nach einer NoSQL Lösung gesucht. Wir wollten eine Datenbank mit nicht-relationalen Ansatz, um nicht von einem festen Tabellenschemata abhängig zu sein. Unsere Wahl fiel dabei auf Amazon DynamoDB, welches eine schnelle NOSQL-Schlüssel-Wert-Datenbank für beliebig große Datenmengen ist.
Es gibt eine Tabelle „game_data“, welche alle relevanten Informationen enthält.
Datenstruktur
Ein Beispiel unserer Datenstruktur ist in der folgenden Abbildung zu erkennen:

Diese JSON-Datei zeigt ein laufendes Spiel mit insgesamt zwei Spielern. Ganz oben ist die Room-Id gespeichert, welche einen einzigartigen Wert aufweist. Diese ist für die Spielrunde besonders wichtig, da so mehrere Räume generiert und gleichzeitig laufen können. Der darunter gespeicherte Array „categories“ beinhaltet alle Kategorien als String-Elemente, die der Spieler, der den Raum erstellt hat, ausgewählt hat. Das Dictionary „game_players“ enthält die Informationen zu allen Spielern. Dazu gehört bspw. der Username, der als Key im Dictionary agiert, die jeweilige Raum-Id, die Punkteanzahl sowie die Eingaben, die der Spieler für eine Runde eingegeben hat. Daneben werden zwei weitere Werte gespeichert, „next_round“ und „status“, welche dazu dienen, zu erkennen, dass die nächste Runde beginnen kann, also alle Spieler bereit sind, oder ob der Spieler noch aktiv ist, also das Spiel nicht bereits verlassen hat.
Des Weiteren werden die Rundenanzahl, die Spiellänge für eine Runde, sowie in einem Array die generierten Buchstaben der Runden gespeichert. Dieser wird pro Runde immer um den nächsten zufällig generierten Buchstaben erweitert.
Datenbank-Interaktionen
Während eines Spiels müssen immer wieder Spielerdaten abgefragt, verändert, hinzugefügt oder gelöscht werden. Dazu gehören bspw. das Anlegen eines neuen Spiels, das Hinzufügen neuer Spieler zu der jeweiligen Raum-Id, das Aktualisieren der erreichten Punkte etc. Diese Interaktionen haben wir in den Lambda-Funktionen, die später noch einmal genauer erklärt werden, implementiert und sie werden aufgerufen, sobald diese benötigt werden. Da diese in Python implementiert wurden, haben wir die AWS SDK für Python, Boto3 verwendet, die eine Integration von Python-Anwendungen und Bibliotheken in AWS-Services, darunter DynamoDB, ermöglicht.
Quelle: https://aws.amazon.com/de/sdk-for-python/
Abfragen von Daten
Auch wenn Boto3 als AWS-SDK für Python nützliche Methoden bezüglich DynamoDB bereitstellt, war es nicht immer einfach, diese zu verwenden. Da unsere Datenstruktur durch die Verschachtelungen recht kompliziert war, war es aufwendig, die benötigten Informationen abzufragen.

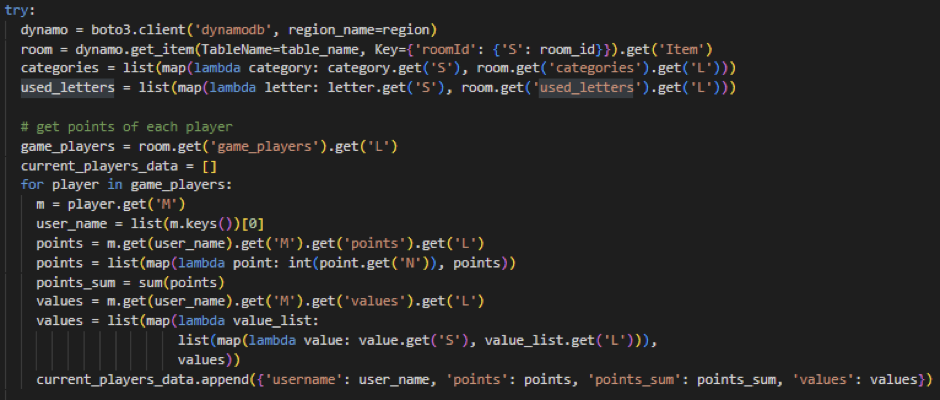
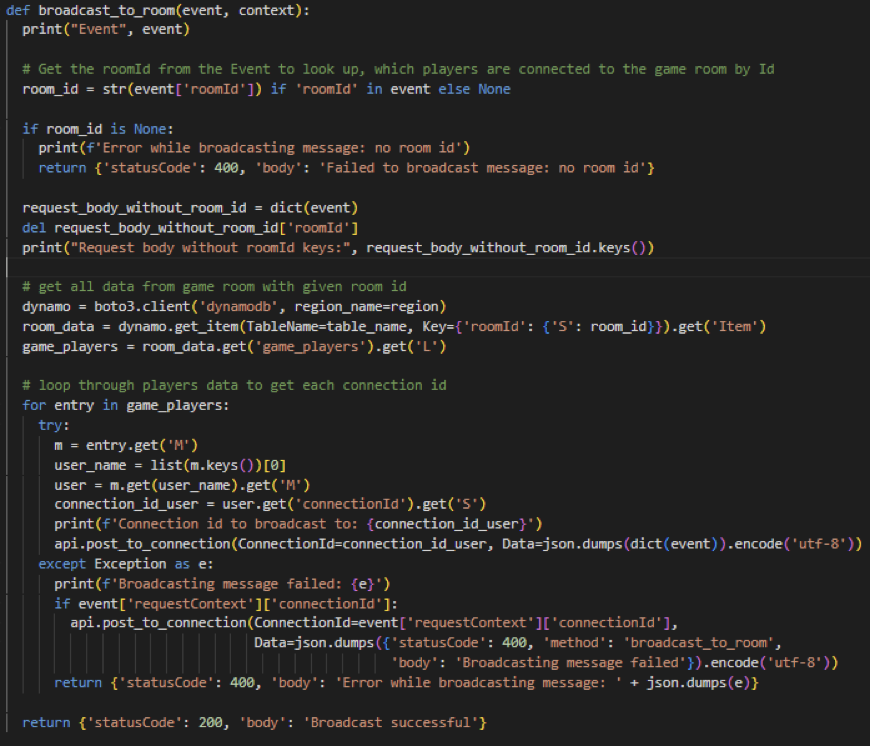
Die obige Abbildung zeigt einen Ausschnitt aus einer Lambda-Funktion und stellt die Abfrage von Spieldaten dar. Zunächst wird die Verbindung zu der gewünschten Datenbank (game_data) hergestellt, indem Endpoint-Url sowie die Region angegeben werden muss. Mit dieser Datenbank-Instanz kann nun mit Methoden wie „.get()“ auf die gewünschte Information in der Datenbank zugegriffen werden. Das Verwenden dieser Funktionen war demnach einfach, jedoch wurden die Daten in der DynamoDB sehr oft in Dictionaries gespeichert, welches an vielen Stellen gar nicht nötig war, was in der Abbildung durch das sich wiederholende „.get(‚L‘)“, „.get(‚M‘)“ etc. zu erkennen ist.
In Wirklichkeit waren die Daten nämlich so aufgebaut:
Man erkennt, dass die Daten durch DynamoDB zusätzlich in Dictionaries und Arrays geschachtelt werden und es war schwierig zu erkennen, um was es sich nun handelt. Das Abfragen wurde dadurch viel komplizierter gestaltet, als es eigentlich ist und war auch sehr fehleranfällig.

Anlegen von Daten

Das Anlegen neuer Daten in die Datenbank erfolgt mithilfe der Methode „put_item“, welcher ein JSON-Objekt mitgegeben werden muss. Die Abbildung zeigt das Anlegen eines neuen Raumes.
Löschen von Daten

Das Löschen von Daten erfolgt ähnlich wie das Updaten von Daten, da der jeweiligen Methode „delete_item“ mehrere Parameter mitgegeben werden können, die den Befehl spezifizieren. In unserem Projekt haben wir komplizierte Aufrufe jedoch nicht gebraucht, weshalb das Löschen im Vergleich zum Updaten von Daten einfach war.
Update von Daten
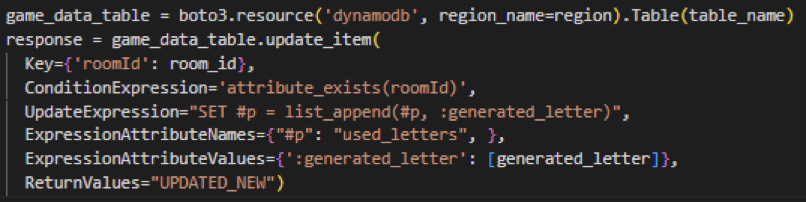
Das Updaten von Daten erfolgt mithilfe der Methode „update_item“, dessen übergebene Parameter komplexer sind als die anderen und auch abhängig davon sind, welche Typen (Array, Dictionaries, ein einfacher Wert) aktualisiert werden sollen. Um zu bestimmen, welches Objekt in der Datenbank bearbeitet werden soll, kann ein sogenannter „Key“, welcher in der obigen Abbildung die Raum-Id ist, mitgegeben werden. Zusätzlich können die übergebenen Parameter überprüft (ConditionExpression) und schließlich bestimmt werden, wie das Objekt aktualisiert werden soll. In diesem Beispiel wird dem Array, der die generierten Buchstaben eines Spiels speichert, um einen Wert erweitert, weshalb als Wert für den Parameter „UpdateExpression“ ein „list_append“ verwendet wird.
S3
AWS S3 (Simple Storage Service) ist ein Service für das Speichern von Objekten. In unserem Projekt haben wir S3 benutzt, um unsere Anwendung zu hosten. Hierfür haben wir einen S3-Bucket erstellt und dort unter „Static website hosting“ die Einstiegs- und Fehlerseite unserer Anwendung angegeben. Damit Benutzer über die dabei erzeugte URL auf unsere Seite zugreifen können, haben wir diese anschließend noch öffentlich zugreifbar gemacht und eine Policy hinzugefügt, um im öffentlichen Modus den Inhalt des Buckets lesen zu können.
Über die AWS CLI können danach immer die aktuellen Files der gebauten Anwendung in S3 hochgeladen werden, wenn die Anwendung deployt werden soll (siehe auch CI/CD Kapitel):
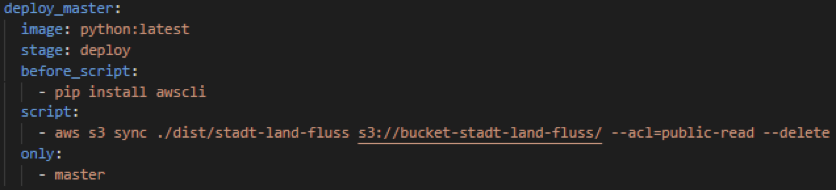
Lambda
„AWS Lambda ist ein Serverless-, ereignisgesteuerter Computing-Service, mit dem Sie Code für praktisch jede Art von Anwendung oder Backend-Service ausführen können, ohne Server bereitzustellen oder zu verwalten. Sie können Lambda in über 200 AWS-Services und Software-as-a-Service (SaaS)-Anwendungen auslösen und Sie zahlen nur für das, was Sie nutzen.“
https://aws.amazon.com/de/lambda/?c=ser&sec=srv
Amazon API- Gateway
Für die definierten Lambda Funktionen hat man bei AWS die Möglichkeit eine eigene Web-API mit einem http-Endpunkt zu erstellen. Dafür kann man das Amazon API Gateway verwenden. Die Funktion des API-Gateway ist es Tools für die Erstellung und Dokumentation von Web-APIs, die HTTP-Anforderungen an Lambda-Funktionen weiterleiten, zu erstellen.
Websocket API Routen
| Api Route | Beschreibung |
| broadcast_to_room | Sendet eine Nachricht an alle Spieler in einem Raum anhand der Raum-Id und den in der Dynamo DB gespeicherten Connection-Ids der Spieler. |
| check_round | setzt den Status der nächsten Runde des jeweiligen Benutzers und sendet die Nachricht für die nächste Runde an die Spieler im Raum, wenn alle Benutzer die nächste Runde angeklickt haben. |
| create_room | Erstellt einen neuen Raum in der Datenbank mit den angegebenen Werten oder Standardwerten, wenn keine Werte angegeben werden. |
| enter_room | Fügt einen Benutzer zu einem Raum hinzu, indem sein Username sowie die entsprechende Connection-Id in der Dynamo DB unter dem Schlüssel der angegeben Raum-Id gespeichert werden. |
| get_current_players | Prüft, ob der Spieler den Raum betreten darf und sendet alle Spielernamen des Raumes an den neuen Spieler. |
| get_results_for_room | Sendet Raumdaten und Spielerdaten an alle Spieler des Raums mit der angegebenen Raum-Id. |
| load_user_inputs | lädt alle Benutzereingaben aus der Datenbank und sendet alle Werte (z.B. [[“Stuttgart”, “Rhein”, “Deutschland”]]) an die Spieler des Raums mit der angegebenen Raum-Id. |
| navigate_players_to_next_room | Navigiert alle Spieler in einem Raum zum Spielraum und wird aufgerufen, wenn der Hauptakteur die Taste “Spiel starten” drückt. |
| play_round | Fragt Timer, Kategorien und Rundeneinstellungen für den Spielraum über die Room-Id aus der Datenbank ab. |
| remove_player_from_room | Setzt den Spielerstatus auf inaktiv in der Dynamo DB und löscht die Raumdaten aus der Datenbank, wenn alle Spieler dieses Raums inaktiv sind. |
| save_round | Speichert Benutzereingaben aus Kategoriefeldern in der Datenbank. |
| start_round | Beginnt die nächste Runde, indem er einen neuen Buchstaben erzeugt und prüft, ob dieser Buchstabe bereits ausgewählt wurde und speichert den erzeugten Buchstaben in der Datenbank. |
| stop_round | Stoppt eine Spielrunde, wenn jemand die Stopptaste gedrückt hat. |
Amazon CloudWatch
Amazon CloudWatch entspricht einem Überwachungs- und Beobachtungsservice für Entwickler. Wir wollten über CloudWatch die Verwendung unserer API protokollieren. Dabei gibt es die Möglichkeit der Ausführungsprotokollierung. Hierbei verwaltet das API-Gateway die CloudWatch-Protokolle. Es können verschiedene Protokollgruppen erstellt werden, welche dann die verschiedenen Aufrufe, Abfragen und Antworten an den Protokollstrom melden. Zu den protokollierten Daten gehören beispielsweise Fehler.
Protokollgruppen
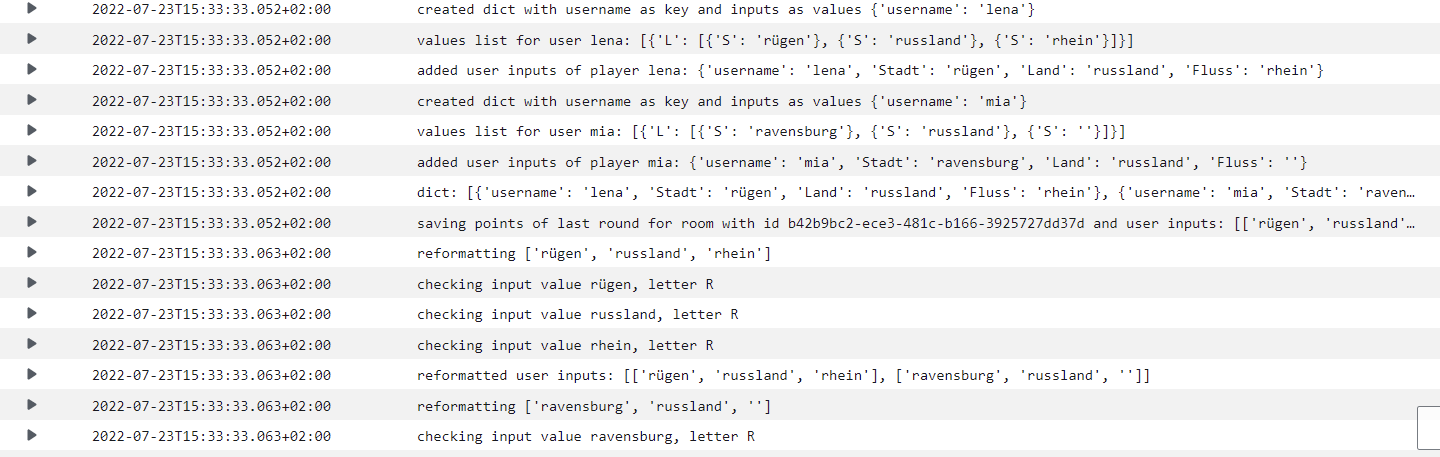
Logs der Methode load_user_inputs
Testing
Beim Testing haben wir uns hauptsächlich auf das Testen der Lambda-Funktionen mit Unittests fokussiert. Dafür haben wir die Bibliothek Moto benutzt, mit der man AWS Services mocken kann. Dadurch konnten wir in den Tests unsere Datenbank mocken und beispielsweise auch testen, ob beim Aufruf der Lambdas Datenbankeinträge richtig angelegt oder Daten richtig aktualisiert werden. Allgemein muss für das Mocken der Datenbank nur die Annotation @mock_dynamodb2 über der Testklasse eingefügt werden und anschließend kann in der setUp-Methode die Datenbank definiert werden, die für die Tests benutzt werden soll. Dadurch können auch Testdaten in die Datenbank eingefügt werden, um bestimmte Testfälle zu testen.
Neben Moto haben wir die Bibliothek unittest.mock benutzt, mit der zum Beispiel das Senden einer Nachricht über die Websocket-Verbindung gemockt werden kann, oder auch der Aufruf einer Lambda-Funktion. Zudem kann man mit Methoden wie assert_called() oder assert_called_with(…) überprüfen, ob und mit welchen Argumenten die gemockte Methode aufgerufen wurde. Allgemein war dies bei unserem Projekt sehr hilfreich, da wir in fast jeder Lambda-Funktion Nachrichten über die Websocket-Verbindung schicken und somit auch testen konnten, ob die richtigen Nachrichten geschickt werden.
Für manuelle Tests oder zum kurzen Testen von bestimmten Eingabewerten war auch die Seite https://www.piesocket.com/websocket-tester sehr hilfreich, da man dort die verschiedenen Lambda-Funktionen über eine Websocket-Verbindung aufrufen kann.
CI/CD Pipeline
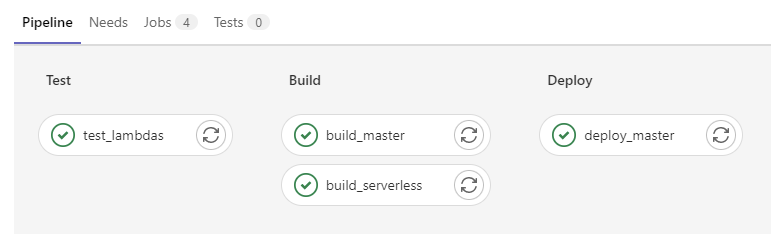
Um unsere Tests automatisiert ablaufen zu lassen und auch andere Schritte wie das Deployen der Lambda-Funktionen nicht immer manuell ausführen zu müssen, haben wir in GitLab eine CI/CD Pipeline erstellt. Da wir alle vor diesem Projekt noch nie eine CI/CD Pipeline angelegt hatten, konnten wir somit durch das Projekt auch Erfahrungen in diesem Bereich sammeln. Allgemein ist unsere Pipeline unterteilt in verschiedene Stages: In der Testing-Stage werden die Unittests für unsere Lambda-Funktionen ausgeführt. In der Build-Stage werden die aktuellen Versionen der Lambda-Funktionen über das serverless-Framework deployt und anschließend wird unsere Angular-Anwendung gebaut. Am Ende wird unsere Anwendung in der Deploy-Stage deployt, sodass sie danach über eine öffentliche Url verfügbar ist. Je nachdem, auf welchen Branch ein Entwickler in unserem Repository pusht, werden unterschiedliche Jobs ausgeführt. So werden zum Beispiel die Unittests auf jedem Branch ausgeführt, das Deployen der Lambda-Funktionen jedoch nur beim Pushen auf den develop- oder master-Branch und das Deployen der Anwendung nur beim Pushen auf den master-Branch.
Insgesamt gibt es in GitLab unter Settings -> CI/CD die Möglichkeit, Variablen anzulegen, die in der CI/CD Pipeline benutzt werden. Wir haben daher in IAM (Identity and Access Management) bei AWS einen Benutzer für die Pipeline angelegt, der nur die Rechte hat, die in der Pipeline benötigt werden. Die Keys dieses Benutzers haben wir anschließend als Variablen in GitLab angelegt, sodass zum Beispiel das Deployen der Lambda-Funktionen in der Pipeline mit diesem Benutzer durchgeführt werden kann.
Schwierigkeiten
Während unserer Arbeit am Projekt sind uns einige Schwierigkeiten begegnet, die im Folgenden näher beschrieben werden.
Datenstruktur
Wie bereits beschrieben hatte sich das Abfragen von Daten in der DynamoDB als sehr aufwendig und komplex dargestellt, auch wenn der Methodenaufruf an sich leicht zu verstehen und einfach ist. Durch die weiteren Verschachtelungen, die AWS zusätzlich zu unserer bereits komplexen Datenstruktur hinzugefügt hat, wurde das Abfragen von Daten schwieriger dargestellt, als es eigentlich ist und auch der Code, den wir dafür geschrieben haben, wurde durch dieses sehr unleserlich. Dadurch kam es in unserer Gruppe oft zu Fehlern bei den Abfragen, da der Fehler nicht direkt erkannt wurde und die endgültige Datenstruktur in der Datenbank für unsere Gruppe unklar wurde.
Wir haben diesbezüglich, auch nachdem wir die Struktur festgelegt hatten, mehrmals gelesen, dass DynamoDB für komplexe Datenstrukturen und Interaktionen (auch das Updaten von Daten) schlichtweg nicht geeignet ist. Dennoch haben wir es dabei belassen, da wir bereits im Projekt weit fortgeschritten waren und keine Zeit mehr hatten, eine Alternative zu finden.
Deployen von Lambdas
Damit die Lambdas, die wir in der serverless.yaml definiert und in den jeweiligen Handler-Dateien implementiert hatten, in unserer Anwendung aufgerufen werden konnten, war es nötig, den Befehl „serverless deploy“ aufzurufen, der alle definierten Lambdas in den Handler-Dateien deployed. Das Problem war, dass dadurch bestehende Funktionen, an denen andere Gruppenmitglieder arbeiteten, anschließend überschrieben wurden, was das Arbeiten sehr behinderte, wenn man an dem Projekt gleichzeitig arbeitete.
Um diese Situation weitestgehend zu verhindern, haben wir beschlossen, die Methoden auf dem Development Branch allesamt mit dem Befehl „serverless deploy“ zu deployen. Anschließend wird auf unterschiedlichen Branches gearbeitet und anschließend nur die Funktion, an der man gerade arbeitet, mit dem Befehl „serverless deploy function –function [Name der Funktion]“ deployed. Dieses hat nur teilweise funktioniert, da das Deployen einer einzigen Funktion nur möglich war, wenn diese bereits existiert, also durch „Serverless deploy“ deployed wurde.
Fazit
Alles in allem haben wir durch das Projekt einen Einblick in die Möglichkeiten von Cloud Computing bekommen und konnten verschiedene Dinge in diesem Bereich ausprobieren. Wir konnten vor allem Erfahrungen mit AWS Lambda, API Gateway und dem serverless Framework sammeln, da dies der Schwerpunkt unseres Projektes war. Zudem haben wir einige grundlegende Dinge gelernt, zum Beispiel dass es sinnvoll ist, schon früh im Projekt eine CI/CD Pipeline aufzubauen oder auch CloudWatch zu aktivieren, um Fehler in den Lambda Funktionen schneller zu erkennen und beheben zu können.
Allgemein haben wir durch das Projekt auch gelernt, dass es sehr wichtig ist, sich am Anfang Gedanken zu Themen wie Security oder auch dem generellen Aufbau des Projektes zu machen. Aus Zeitgründen verfolgt man sonst oft die am schnellsten funktionierende Lösung und kann dann später nur mit viel Aufwand grundlegende Dinge ändern. Für das nächste Projekt würden wir daher mehr Zeit für die Einarbeitung und Recherche einplanen, um dies zu vermeiden. Bei unserem Projekt wäre es vor allem sinnvoll gewesen, schon von Beginn an die verschiedenen Umgebungen einzurichten, sodass alle Entwickler lokal unabhängig voneinander entwickeln und testen können und man auf der Entwicklungsumgebung Änderungen durchführen kann, ohne die Produktivumgebung zu beeinflussen.
Leave a Reply
You must be logged in to post a comment.