Blog von Manuel Heim (mh375) und Silas Blumenstock (sb309).
Einleitung
In den letzten Jahren hat sich die Welt der künstlichen Intelligenz (KI) rasend schnell entwickelt. Eine der spannendsten Entwicklungen in diesem Bereich ist die Einführung von Sprachmodellen, die menschenähnliche Gespräche führen können. Eines der bekanntesten und leistungsfähigsten Sprachmodelle ist ChatGPT. ChatGPT basiert auf dem Modell GPT-3, das von der Firma OpenAI entwickelt wurde. Microsoft hat mehrere Milliarden in OpenAI investiert, um Zugang zu diesem und anderen KI-Modellen zu erhalten. In nur zwei Monaten seit seiner Veröffentlichung hat ChatGPT bereits 100 Millionen Benutzer erreicht, von denen die meisten regelmäßige Nutzer sind. Täglich nutzen etwa 13 Millionen Menschen ChatGPT. Diese Zahlen zeigen, wie schnell ChatGPT an Bedeutung gewinnt und wie nützlich es für die Entwicklung von KI-basierten Anwendungen sein kann.
Die Qualität der von ChatGPT generierten Texte ist besonders beeindruckend. Sie sind häufig kaum noch von menschengeschriebenen Texten zu unterscheiden. Der vorherige Abschnitt wurde zum Beispiel vollständig von ChatGPT geschrieben, was Ihnen vermutlich nicht aufgefallen ist. Neben dem Generieren von Texten kann ChatGPT auch für viele weitere Aufgaben genutzt werden. Zum Beispiel für die Beantwortung von Fragen, oder auch für das Schreiben und die Fehlersuche in Code. Es kann auch Bezug auf bereits generierte Texte genommen werden und ChatGPT kann diese umschreiben, übersetzen oder im Stil verändern. Bittet man ChatGPT z.B. darum, den oberen Abschnitt auf Englisch zu übersetzen und als Gedicht umzuformulieren, erhält man die folgende Ausgabe:
In the world of AI, advances are rife Language models can now talk like human life ChatGPT is one that's made a great leap Built on GPT-3, OpenAI's star keep
Microsoft invested billions in the AI game To access the power of models that became ChatGPT, in particular, has made waves In the workplace, where it helps to save
With conversations like a human touch ChatGPT finds uses in tasks that clutch Repetitive work, like customer support It automates and saves time, that's its forte forte
So whether it's sales, marketing, or journalism too ChatGPT can do it all, with responses anew The future's bright, and there's more to come From AI advancements, where possibilities hum.
ChatGPT kann als Meilenstein in der Entwicklung von Sprachmodellen und im Bereich Machine Learning generell gesehen werden, auch wenn die Texte, wie im Gedicht zu erkennen, noch nicht ganz fehlerfrei sind.
In den folgenden Kapiteln erklären wir die technischen Grundlagen, die zum Verständnis der Funktionsweise von ChatGPT nötig sind. Es wird das Konzept der Self-Attention erklärt, welches eine der relevantesten Entwicklung im Bereich von Sprachmodellen ist. Wir gehen auf das Fine-Tuning beim Training von ChatGPT ein. Zusätzlich wird ein Überblick über verschiedene GPT-Modelle gegeben. Da bei Sprachmodellen ein Trend zu immer größeren Modellen existiert, möchten wir auch auf die Skalierung großer Sprachmodelle eingehen und diesen Trend bewerten.
Grundlagen
Sprachmodelle
Das von ChatGPT genutzte Modell GPT-3 ist ein Sprachmodell. Sprachmodelle können für verschiedene Anwendungen eingesetzt werden, z.B. zur automatischen Vervollständigung von Sucheingaben oder zur Textgenerierung. Grundsätzlich werden unter Sprachmodellen Modelle verstanden, die mithilfe verschiedener probabilistischer Techniken Wahrscheinlichkeiten von Wortsequenzen in Sätzen bestimmen, indem sie Textdaten analysieren. Dabei lernt ein Modell Merkmale und Eigenschaften der Sprache und nutzt diese, um neue Sätze zu verstehen oder zu produzieren. Je nach Komplexität der Aufgabe werden unterschiedliche Modelltypen verwendet. GPT-3 ist zum Beispiel ein neuronales Sprachmodell. Diese repräsentieren Wörter als Vektoren auf Grundlage von Gewichten in neuronalen Netzen, diese Vektoren werden als Word-Embeddings bezeichnet. Word-Embeddings werden vor allem bei komplexen Modellen mit großen Datenmengen eingesetzt, hier existieren einzelne Wörter, die selten in Texten vorkommen. Bei einfachen probabilistischen Modelltypen kann es dabei zu Problemen kommen [1]. Da der Blog-Beitrag ChatGPT behandelt, beschäftigen wir uns nur mit neuronalen Sprachmodellen. Ein Überblick weiterer Modelltypen wird in [1] gegeben.
Wie bereits erwähnt, wird ChatGPT zur Textgenerierung eingesetzt. Dabei wird aus einer Sequenz von Word-Embeddings als Eingabe eine Wahrscheinlichkeitsverteilung über Ausgabewörter eines Textkorpus bestimmt. In Texten bestehen dabei zwischen den Word-Embeddings der Eingabesequenz Abhängigkeiten, weshalb Architekturen genutzt werden, die diese Abhängigkeiten berücksichtigen. In den ersten neuronalen Sprachmodellen wurden dafür z.B. rekurrente neuronale Netze (RNNs) verwendet. RNNs sind neuronale Netze, bei denen die Ausgabe eines Neurons im nächsten Zeitschritt Teil der Eingabe in dasselbe Neuron ist. Bei der Textverarbeitung bedeutet dies, dass zusätzlich alle vorherigen Wörter in die Berechnung der Ausgabe mit einfließen und das ein Wort pro Zeitschritt prozessiert wird. RNNs in Sprachmodellen besitzen jedoch zwei entscheidende Nachteile. Zum einen haben sie Schwierigkeiten, Informationen über Wörter, die am Anfang eines langen Textes stehen, in die Verarbeitung von Wörtern am Ende des Textes einzubeziehen. Zum anderen können RNNs nur sequenziell trainiert werden, weshalb kein effizienteres Training durch die Nutzung mehrerer GPUs ermöglicht werden kann.
Durch die Vorstellung einer weiteren Modellarchitektur in dem Paper „Attention is all you need“, wurde eine neue Architektur zur Berücksichtigung von Abhängigkeiten zwischen Eingaben eingeführt. Der als Transformer bezeichnete Modelltyp verwendet dabei sogenannte Self-Attention und gilt als Meilenstein im Bereich Natural Language Processing [2].
Self-Attention
Self-Attention bezeichnet eine Methode, mit der der Einfluss anderer Wörter auf das aktuell zu verarbeitende Wort berücksichtigt wird. Für den folgenden Beispielsatz:
„The animal didn't cross the street because it was too tired.“
Wird durch Self-Attention zum Beispiel der Einfluss der Wörter animal und street auf das Wort it gelernt, Self-Attention sollte dabei dafür sorgen, dass der Einfluss von animal größer ist als von street. Für einen Menschen scheint dies ein triviales Problem zu sein, während es für einen Algorithmus ein deutlich komplizierteres Problem ist. Bei Self-Attention werden für jedes Wort Attention-Koeffizienten zu allen anderen Eingabewörtern berechnet. Diese definieren die Beziehungsstärken zwischen den Word-Embeddings der Eingabewörter. In einem ersten Schritt werden mithilfe des Word-Embeddings eines Eingabewortes Query, Key und Value Matrizen berechnet. Dies erfolgt durch die Gewichtsmatrizen Wq, Wk und Wv. Die Parameter dieser Gewichtsmatrizen sind veränderbar und werden während des Trainingsprozesses gelernt.
Query, Key und Value haben dabei die folgenden Funktionen:
- Query: Die Query qi der i-ten Eingabe wird verwendet, um den Einfluss aller Eingaben auf die Eingabe an Stelle i zu berechnen.
- Key: Der Key kj wird von Queries qi genutzt, um den Einfluss des Elements an der Stelle j für das Element an der Stelle i zu bestimmen.
- Value: Der Value vj wird für die Berechnung des Gesamtergebnisses zusammen mit dem Attention-Koeffizienten aij verwendet.
Es wird auch die Query auf einen Key der gleichen Eingabe angewandt, um für eine Eingabe den eigenen Einfluss zu bestimmen. Durch Betrachtung des oberen Beispiels wird deutlich, warum dies relevant ist. Bei Verarbeitung des Wortes it ist zum Beispiel der Einfluss von animal größer als das Wort it selbst.
Nach der Berechnung von Query, Key und Value werden die Attention-Koeffizienten aij durch das Skalarprodukt von Query qi und Key kj gebildet. Diese werden normalisiert, anschließend wird die Softmax-Aktivierungsfunktion darauf angewandt. Die Ausgabe yi bei Eingabe xi unter Berücksichtigung der restlichen Eingaben in der Sequenz kann dann durch die Linearkombination der Attention-Koeffizienten mit den jeweiligen Value-Werten berechnet werden [3].
In Abbildung 1 ist die Berechnung für die erste Eingabe abgebildet, dabei werden die Einflüsse aller weiterer Eingaben auf das erste Eingabeelement berücksichtigt.

In der obigen Abbildung wird eine sogenannte Single-Head Attention abgebildet. Das heißt, für jedes Paar von Eingaben wird ein einzelner Attention-Koeffizient berechnet. In Modellen wie GPT wird Multi-Head Attention verwendet. Das heißt, für Paare von Eingaben werden mehrere Attention-Koeffizienten in sogenannten Heads berechnet. In jedem Head werden dabei unterschiedliche Gewichtsmatrizen zur Berechnung von Query, Key und Value verwendet, wobei die Startgewichte zufällig initialisiert werden. Alle Ergebnisse der verschiedenen Heads werden verkettet und durch eine erneute lernbare Gewichtsmatrix auf ein Ergebnis projiziert. Die Verwendung von Multi-Head Attention bringt den Vorteil, dass für ein Paar von Eingaben unterschiedliche Gewichtsmatrizen für Query, Key und Value gelernt werden und somit mehrere Attention-Koeffizienten für gleiche Paare von Eingabewörtern gelernt werden können. Dies ist relevant, weil Wortpaare je nach Gesamtkontext eines Textes unterschiedliche Bedeutungen und damit unterschiedliche Beziehungsstärken haben können [3, 4].
Transformer
GPT steht für Generative Pretrained Transformer. Das heißt GPT beruht auf einem Transfomer in dem das Konzept Self-Attention umgesetzt wird. Ein Transformer besteht aus zwei Teilen, einem Encoder und Decoder-Teil. Diese beinhalten, wie in Abbildung 2 zu erkennen, mehrere Encoder- bzw. Decoder-Blöcke, welche neben Self-Attention Schichten auch Schichten zur Normalisierung und reguläre Feed-Forward Neural Networks enthalten. Die Eingabe in den Encoder-Teil eines Transformers sind Sequenzen von Word-Embeddings. In der Eingabe ist zusätzlich eine Information über die Position des Word-Embeddings in der Sequenz enthalten. Diese wird durch den Positional-Encoding Vektor repräsentiert, der auf die Eingabe addiert wird. Positional-Encoding Vektoren sind dabei so aufgebaut, dass weiter entfernte Eingaben eine höhere euklidische Distanz besitzen als benachbarte Eingaben. In den Decoder-Teil wird die Ausgabe des Decoders zum vorherigen Zeitpunkt als Eingabe gegeben. Encoder und Decoder sind über einen Encoder-Decoder Attention-Block verbunden. Die Eingabe in diesen Block sind die Keys und Values des letzten Encoder-Blocks sowie die Queries des vorangeschalteten Decoder-Layers [3].
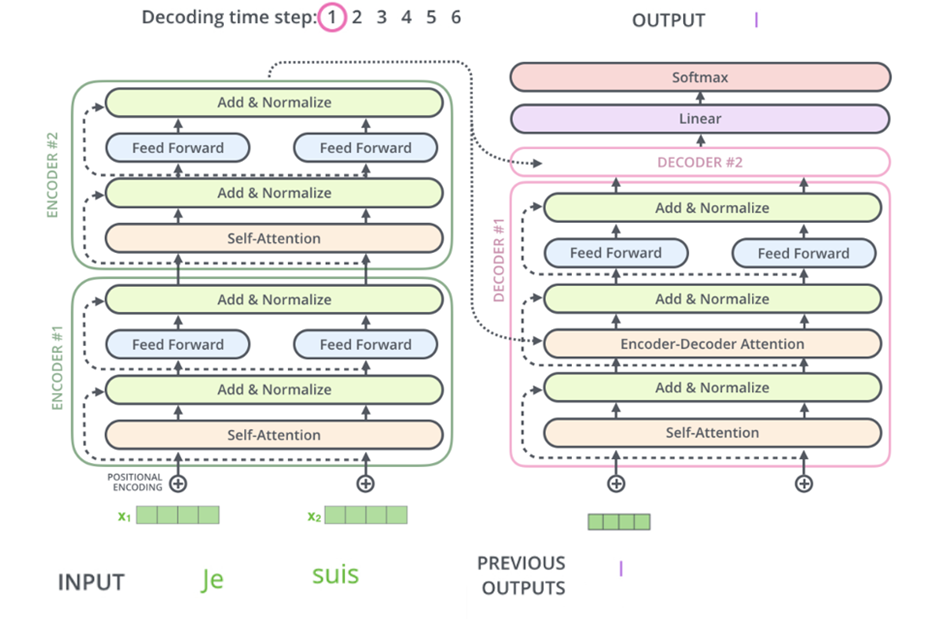
Durch die Umsetzung der Transformer, wie sie in „Attention is all you need“ vorgestellt wurden, konnten bessere Ergebnisse wie durch andere Modelle bei gängigen NLP-Aufgaben erzielt werden, wobei der Trainingsaufwand signifikant geringer war [4]. In vielen Sprachmodellen werden heutzutage Transformer verwendet, wobei diese zum Teil angepasst werden.
Generative Pre-Trained Transformer (GPT)
In den vorherigen Abschnitten sind wir bereits darauf eingegangen, was ein Sprachmodell ist und wie Transformer funktionieren und aufgebaut sind. Doch wie stehen diese im Zusammenhang mit Generativen Pre-Trained Transformern (GPTs)?
Die ersten GPT-Modelle wurden erstmals im Jahr 2018 von OpenAI als GPT-1 eingeführt [5]. Die Architektur der GPT-Modelle basiert dabei, wie bereits erwähnt, auf der der Transformer. Ein GPT nutzt dabei nur die Decoder-Struktur des Transformers, da nur dieser Teil relevant für die Erzeugung von Text ist. Alle GPT-Varianten stellen dabei sogenannte autoregressive Sprachmodelle dar. Diese sagen für eine Sequenz von Wörtern das nachfolgende Wort vorher. Für diese neue Sequenz wird dann wieder das Wort vorhergesagt, das am wahrscheinlichsten auf diese Sequenz folgt. Durch diese Funktionsweise sind GPT-Modelle für die Generierung von Texten oder jeder Art von Sequence-To-Sequence Transformationen wie Übersetzung, Text-to-Code, etc. geeignet. Sie werden deshalb auch generative Modelle genannt, da sie neuen Text generieren können. GPT-1 wird dabei, wie der Name es verrät, auf einer großen Menge an Daten vortrainiert und dann für jede spezifische Task, die das Modell erfüllen soll, Fine-Tuned (Gezielt abgestimmt). Daher haben Generative Pre-Trained Transformer ihren Namen.
| GPT-1 (2018) | GPT-2 (2019) | GPT-3 (2020) |
|---|---|---|
| Autoregressives Sprachmodell | Autoregressives Sprachmodell | Autoregressives Sprachmodell |
| Decoder-Only | Decoder-Only | Decoder-Only |
| 12 Layer | 48 Layer | 96 Layer |
| 117 Millionen Parameter | 1.5 Milliarden Parameter | 175 Milliarden Parameter |
| Unsupervised Pre-Training + Task-Specific Supervised Fine-Tuning | Task-Conditioned Training (Unsupervised) | Task-Conditioned Training (Unsupervised) |
| 5GB Unsupervised Data | 40GB Unsupervised Data | 600GB Unsupervised Data |
Das Pre-Training erfolgt dabei unüberwacht (unsupervised) und kann auf einer sehr großen Menge an Daten erfolgen, da für unüberwachtes Lernen keine gewünschten Ausgabedaten vorhanden sind. Bei GPT-1 hat sich gezeigt, dass ein umfangreiches Pre-Training auf einem großen Textkorpus die Leistung dieser Modelle in unterschiedlichen Aufgaben verbessert, selbst wenn der Korpus nicht speziell auf die Aufgaben zugeschnitten war. Diese Erkenntnis hat gezeigt, dass ein großer vielfältiger Textkorpus sehr wertvolle Informationen für die Modelle liefert. Für das überwachte Fine-Tuning, bei dem nun eine gewünschte Ausgabe vorhanden ist, benötigt man deshalb nur einen kleinen Datensatz, um das Modell speziell auf eine Aufgabe abzustimmen. In manchen Bereichen ist jedoch selbst die Beschaffung dieses kleinen Datensatzes nicht sonderlich einfach [5].
Diese Modelle wurde im Jahr 2019 mit GPT-2 [6] und 2020 mit GPT-3 [7] weiter verbessert. Ab GPT-2 wurde dabei das Prinzip des Multi-Task Learning (MTL) angewendet. In GPT-1 musste dabei für jede spezifische NLP-Aufgabe ein eigenes Modell trainiert werden. Im Multi-Task Learning dagegen wird nur ein einziges Sprachmodell für mehrere NLP-Aufgaben trainiert, indem die Trainingsdaten mit Task-spezifischen Beispielen oder Prompts erweitert werden. Da das Modell nicht für eine spezielle Aufgabe trainiert wurde, handelt es sich um ein Beispiel für Few-Shot-, One-Shot- oder Zero-Shot-Learning. Das Konzept der X-Shot-Ansätze ist in der folgenden Abbildung dargestellt.
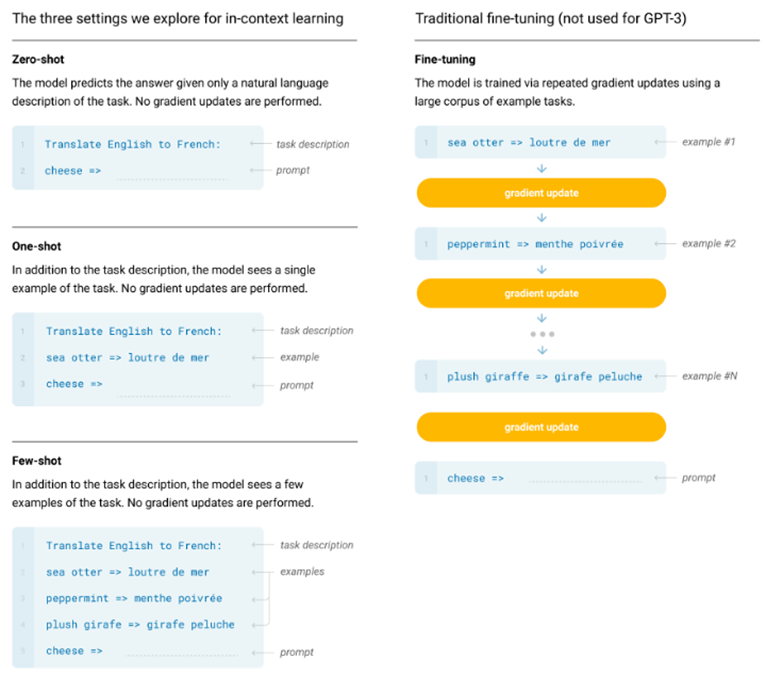
Das Multi-Task Learning wird bei den X-Shot-Ansätzen dabei auf Datenebene integriert, indem, wie in der Abbildung dargestellt, der Eingabe („Cheese“) die Task-Beschreibung („Translate English to French“) hinzugefügt wurde. Beim Few-Shot-Learning werden dem Modell so einige Beispiele beigefügt, die genau die Aufgabe beschreiben. Um Multi-Task Learning / X-Shot-Learning anwenden zu können, muss das Modell natürlich immer noch mit einer sehr großen Menge an Daten vortrainiert werden. Dieser Ansatz hat gezeigt, dass immer größere Sprachmodelle, wie GPT-3, mit immer mehr Parametern eine sehr starke Leistung auf unterschiedlichen NLP-Aufgaben bieten. Die Tatsache, dass wir nun kein Fine-Tuning mehr benötigen, ist ein Schritt in Richtung der „allgemeinen Intelligenz“ [7, 8].
Die obige Tabelle zeigt deutlich, dass die GPT-Modelle im Laufe der Jahre immer größer geworden sind und GPT-3 im Vergleich zu GPT-2 auf deutlich mehr Daten vortrainiert wurde. Es war damals das größte öffentlich verfügbare Sprachmodell der Welt und die Qualität der generierten Texte so hoch, dass es für Menschen schwierig war, festzustellen, ob Texte von GPT-3 oder einem Menschen geschrieben wurden [9]. Obwohl GPT-3 große Fortschritte im Bereich der Verarbeitung natürlicher Sprache erzielt hatte, ist es nur begrenzt in der Lage, sich an den Absichten der Benutzer zu orientieren. So erzeugte GPT-3 Ausgaben die:
- mangelnde Hilfsbereitschaft enthalten, d.h. sie befolgen nicht die ausdrücklichen Anweisungen des Nutzers.
- Halluzinationen enthalten, die nichtexistierende oder falsche Fakten widerspiegeln.
- nicht interpretierbar sind, sodass es für den Menschen schwierig ist, zu verstehen, wie das Modell zu einer bestimmten Entscheidung oder Vorhersage gekommen ist.
- toxische oder voreingenommene Inhalte enthalten, die schädlich oder beleidigend sind und Fehlinformationen verbreiten [7, 10].
Um diesen Problemen von GPT-3 entgegenzuwirken, entwickelte OpenAI InstructGPT, welches im Januar 2022 veröffentlicht wurde. Dazu wurde GPT-3 als Basismodell mit den gleichen Pre-Training Datensätzen verwendet und das Modell durch einen neuartigen Ansatz zur Einbeziehung von menschlichem Feedback in den Trainingsprozess weiter verbessert. InstructGPT ist durch diesen Ansatz besser an die Absichten der Benutzer angepasst („aligned“) [11].
ChatGPT
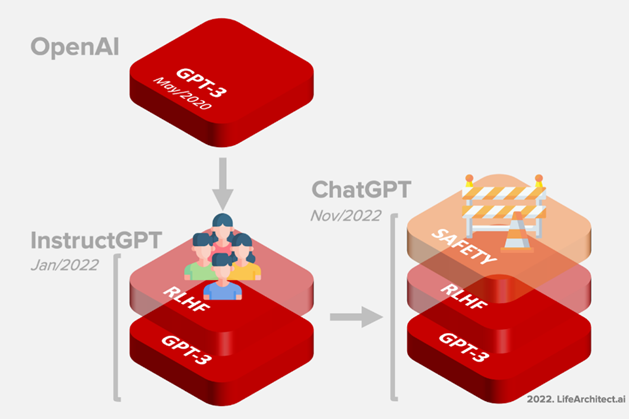
ChatGPT ist ein großes Sprachmodell, das darauf trainiert wurde, natürliche Sprache zu verstehen und auf verschiedene Arten von Fragen und Anfragen zu antworten. Es wurde am 30. November 2022 von OpenAI ins Leben gerufen. Der Dienst, mit einem ansprechenden Design und einfacher Benutzeroberfläche, ist bisher kostenlos für die Öffentlichkeit verfügbar. Im Januar 2023 erreichte ChatGPT über 100 Millionen Nutzer und war damit die am schnellsten wachsende Verbraucheranwendung überhaupt [12, 13].
ChatGPT stellt ein Geschwister-Modell von InstructGPT dar, welches darauf trainiert ist, einer Instruktion in einem Prompt zu folgen und eine detaillierte Antwort zu geben. Es wurde dabei auf einem Modell der GPT-3.5 Reihe trainiert, zu der InstructGPT zählt. Dabei wurde derselbe Ansatz wie bei InstructGPT gewählt, jedoch mit leichten Unterschieden in der Datenerhebung [14].
Zusätzlich dazu wurde eine Sicherheitsschicht hinzugefügt, um unangemessene und beleidigende Inhalte zu erkennen und herauszufiltern. Wenn ChatGPT eine unangemessene oder beleidigende Eingabe erhält, versucht es, das Thema zu wechseln oder den Benutzer höflich zu bitten, die Konversation fortzusetzen. Diese Sicherheitsmaßnahmen sind auf jeden Fall notwendig, da Sprachmodelle oft dazu neigen, auch unangemessene Antworten zu liefern.
Reinforcement Learning From Human Feedback
Der Ansatz, der bei InstructGPT dabei zum Einsatz kommt, heißt „Reinforcement Learning From Human Feedback“. Diese Technik nutzt die menschlichen Präferenzen als ein Reward-Signal, um das Modell damit zu verbessern. Dieser Ansatz wird im Folgenden mit dem InstructGPT Paper erklärt und besteht aus folgenden drei Schritten:
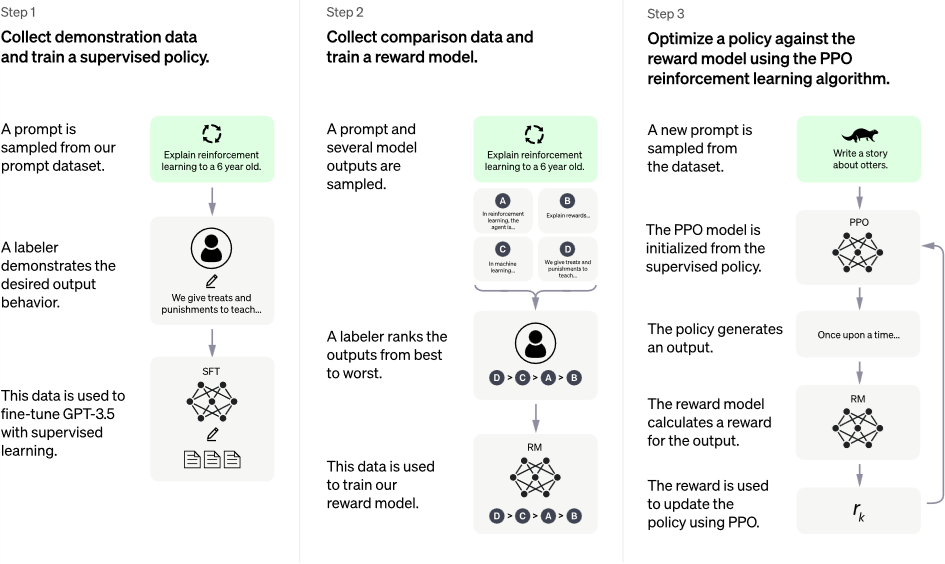
1. Supervised Fine-Tuning (SFT) Modell
Im ersten Schritt wird das GPT-3 Modell mithilfe von überwachten Lernen Fine-Tuned. Dazu wurden 40 Personen (Labeler) beauftragt, diesen Trainingsdatensatz zu erstellen, indem für jede Eingabe-Prompt eine Antwort erstellt wird. Die Eingabe-Prompts stammen dabei zum größten Teil aus tatsächlichen Benutzereingaben, die in der OpenAI API gesammelt wurden, aber auch zum Teil aus Eingaben, die die Labeler selbst erstellten, um Kategorien auszufüllen, in denen nur wenige tatsächliche Benutzereingaben vorhanden waren. Die Labeler schrieben dann für diese Eingabe-Prompts eine Antwort und erzeugten so eine Ausgabe für die zugehörige Eingabe. Diese Zusammenstellung der Eingabe-Prompts aus der OpenAI API und den selbsterstellten Prompts ergaben 13.000 Datensätze mit Eingabe und zugehöriger Ausgabe, die für das überwachte Fine-Tuning des Modells verwendet werden konnten [10, 11, 15].
In diesem Schritt wird eine sogenannte überwachte Policy (das SFT-Modell selbst) gelernt. Eine Policy stellt im Reinforcement Learning eine Strategie dar, die ein Agent verfolgt, um Ziele zu erreichen. Die Strategie sagt die Aktionen voraus, die der Agent in Abhängigkeit vom Zustand des Agenten und der Umgebung durchführt [16].
2. Reward Modell (RM)
Das resultierende SFT-Modell zeigte schon eine Verbesserung in Bezug auf die Benutzerabsichten, war jedoch noch nicht gut genug. Das Problem des überwachten Ansatzes aus dem vorherigen Schritt ist außerdem der langsame und kostspielige Prozess für die Erstellung des Datensatzes.
Deshalb wird in diesem Schritt ein sogenanntes Reward Modell trainiert. Dazu werden die Labeler gebeten, die Ausgaben des SFT-Modells (Antworten auf Prompts) zu bewerten. Diese Bewertung drückt aus, wie wünschenswert diese Ausgabe für den Menschen ist. Am Ende dieses Schrittes besitzt man dann ein Reward Modell, das die menschlichen Vorlieben nachahmen soll. Das funktioniert dabei folgendermaßen:
- Eine Eingabe-Prompt wird ausgewählt und das SFT-Modell generiert mehrere Ausgaben (4-9) für diese Eingabe-Prompt.
- Die Labeler sortieren die Ausgaben von der besten bis hin zur schlechtesten.
- Das Ergebnis ist ein neuer Datensatz, bei dem das Ranking das Label darstellt. Dieser Datensatz wird verwendet, um das Reward Modell zu trainieren. Das Reward Modell nimmt dabei als Eingabe mehrere Ausgaben des SFT-Modells und ordnet diese nach der Reihenfolge der Präferenzen.
Da es für die Labeler viel einfacher ist, die Ergebnisse zu bewerten, als sie von Grund auf neu zu erstellen, lässt sich dieser Prozess viel effizienter skalieren [10, 11, 15].
3. Reinforcement Learning Modell
Im letzten Schritt wird das Reward Modell als Reward-Funktion verwendet und das SFT-Modell so Fine-Tuned, um diesen Reward zu maximieren. Dazu wird dem Modell eine zufällige Eingabe-Prompt übergeben und eine Ausgabe dazu vom Modell erzeugt. Diesem Paar an Eingabe und Ausgabe wird vom Reward Modell ein Reward-Wert zugeordnet. Dieser Reward fließt dann wieder in das Modell mit ein, um die Policy, also das Modell zu verbessern. Die Policy wird mit dem sogenannte Proximal Policy Optimization (PPO) Algorithmus angepasst. PPO ist dabei eine Methode, die bei der Aktualisierung der Policy verwendet wird. Er führt dabei einen sogenannten Clipping-Mechanismus ein, um sicherzustellen, dass die Aktualisierungen der Policy innerhalb einer Vertrauensregion liegen. Dadurch wird verhindert, dass die Policy zu stark verändert wird, indem zu viel vergessen wird. PPO verwendet außerdem eine sogenannte Value-Funktion (Reward Modell), um die Varianz der Policy-Gradienten zu verringern und die Lernleistung zu verbessern [10, 11, 15].
Evaluation des Modells
Die Bewertung des Modells erfolgt, indem während des Trainings ein Testdatensatz, den das Modell noch nie gesehen hat, beiseitegelegt wird. Anhand dieses Testdatensatzes wird dann eine Reihe von Bewertungen durchgeführt, um zu überprüfen, ob das Modell besser an die Absichten der Benutzer angepasst ist.
Das Modell wird dabei anhand von drei übergeordneten Kriterien bewertet:
- Hilfsbereitschaft: Beurteilung der Fähigkeit des Modells, den Anweisungen des Benutzers zu folgen und Anweisungen abzuleiten.
- Wahrheitsgehalt: Beurteilung der Neigung des Modells zu Halluzinationen (Erfinden von Fakten) bei Aufgaben in geschlossenen Bereichen.
- Harmlosigkeit: die Fähigkeit des Modells, unangemessene, herabsetzende und verunglimpfende Inhalte zu vermeiden.
Dieser gesamte Ansatz hat natürlich auch gewisse Unzulänglichkeiten, die im InstructGPT Paper von OpenAI noch genauer aufgezählt werden [10, 11, 15].
Limitationen
Es gibt trotzdem noch gewisse Limitationen, die ChatGPT besitzt und die nicht unterschätzt werden dürfen. Dadurch, dass das Modell nur aus Sprache lernt, nimmt es dessen Eigenheiten an und wird so natürlich auch Fehlverhalten annehmen:
- ChatGPT schreibt manchmal plausibel klingende, aber falsche oder unsinnige Antworten.
- ChatGPT reagiert empfindlich auf Änderungen der Eingabeformulierung oder auf mehrfache Versuche mit der gleichen Frage.
- Das Modell ist oft übermäßig wortreich und verwendet bestimmte Phrasen zu oft, wie z. B. den Hinweis, dass es sich um ein von OpenAI trainiertes Sprachmodell handelt.
- Im Idealfall würde das Modell klärende Fragen stellen, wenn der Benutzer eine mehrdeutige Anfrage stellt. Stattdessen erraten aktuelle Modelle in der Regel, was der Benutzer beabsichtigt.
- ChatGPT kann gelegentlich schädliche Anweisungen oder voreingenommene Inhalte produzieren.
- Das Modell besitzt nur ein begrenztes Wissen über die Welt und Ereignisse, die nach 2021 passiert sind, da es auf Daten vor 2022 trainiert wurde.
Doch trotz der Limitationen, die bei ChatGPT bestehen, wurde ein riesiger Hype ausgelöst.
Hype von ChatGPT
ChatGPT ist von der technischen Sicht aus betrachtet keine neue bahnbrechende Erfindung. Die Methodiken, die zum Einsatz kommen, werden in der Forschung bereits in vielen anderen Modellen benutzt. Der Hype um ChatGPT kommt vor allem durch die öffentliche Bereitstellung des Modells für jedermann. Diese kostenlose Testphase mit einer einfachen und schönen Gestaltung des Dialogs macht ChatGPT so erfolgreich. Punkte, die ChatGPT selbst aufzählt, warum es so erfolgreich ist, sind:
- 24/7-Verfügbarkeit: Als KI benötige ich keine Pausen oder Ruhezeiten, sodass ich zu jeder Tages- und Nachtzeit zur Verfügung stehe, um Menschen bei ihren Fragen und Gesprächen zu helfen.
- Erreichbarkeit: Die Menschen können mich von überall auf der Welt erreichen, solange sie eine Internetverbindung haben. Das macht es für die Menschen einfach, die benötigten Informationen zu erhalten, egal wo sie sich befinden.
- Flexibel: Ich kann bei einem breiten Spektrum von Themen und Fragen helfen, von allgemeinem Wissen bis hin zu speziellen technischen Fragen. Das macht mich zu einem vielseitigen Werkzeug für die Menschen.
- Schnelle Reaktionszeit: Ich kann Anfragen fast sofort bearbeiten und beantworten, was besonders hilfreich für Menschen ist, die schnelle Antworten brauchen.
- Datenschutz: Als Sprachmodell benötige ich keine persönlichen Informationen der Nutzer. Das bedeutet, dass die Menschen mir Fragen stellen und Hilfe erhalten können, ohne sich Sorgen machen zu müssen, dass ihre Privatsphäre gefährdet wird.
Wenn ChatGPT bereits jetzt so große Wellen schlägt, stellt sich natürlich die Frage, wie es mit dem Nachfolger GPT-4 aussieht.
Ausblick GPT-4
GPT-4, die Weiterentwicklung der GPT-Serie, soll laut Gerüchten der New York Times sogar noch im Jahr 2023 erscheinen. Es soll sich dabei auf jeden Fall um ein noch mächtigeres Modell handeln als die bisherigen veröffentlichten Modelle. Die Gerüchte, dass es sich um ein Modell mit 100 Billionen Parametern handeln soll, wurden vom OpenAI CEO Sam Altman als völliger Blödsinn bezeichnet. Zu diesen Gerüchten sagte er: „Die GPT-4-Gerüchteküche ist eine lächerliche Sache. Ich weiß nicht, woher das alles kommt. Die Leute betteln darum, enttäuscht zu werden, und das werden sie auch.“ Somit kann man nur gespannt sein, wie gut GPT-4 sein wird und wann OpenAI das neue Modell veröffentlicht [17].
Es gab jedoch noch einige Veröffentlichungen von Konkurrenten zu ChatGPT, die ebenfalls neue Modelle ankündigten:
- Google hat seinen Counterpart Bard veröffentlicht, der jedoch in einer Demo eine falsche Antwort lieferte und deshalb die Aktien des Mutterkonzerns einbrachen und 100 Milliarden Dollar Börsenwert kostete [18].
- Das chinesische Unternehmen Baidu kündigte im Februar 2023 an, dass es im März 2023 einen ChatGPT-ähnlichen Dienst namens “Wenxin Yiyan” auf Chinesisch oder “Ernie Bot” auf Englisch auf den Markt bringen wird [19].
- Die südkoreanische Suchmaschinenfirma Naver kündigte im Februar 2023 an, dass sie in der ersten Jahreshälfte 2023 einen ChatGPT-ähnlichen Dienst namens “SearchGPT” in koreanischer Sprache auf den Markt bringen werden [19].
Die Modelle, die in nächster Zeit veröffentlicht werden sollen, werden immer größer. Doch kann die Skalierung immer so weiter gehen und die Anzahl der Parameter immer vergrößert werden? Oder bringt das ganze letztendlich keine Verbesserung der Leistung dieser Modelle? Diese Frage werden wir im nächsten Kapitel klären.
Skalierung von Sprachmodellen
Wie wir festgestellt haben, ist die Anzahl der Parameter sowie die Menge der Trainingsdaten mit jeder Version von GPT angestiegen (siehe Tabelle 1). Zwar ist nicht bekannt, wie groß GPT-4 sein wird, es lässt sich aber vermuten, dass GPT-4 mehr Parameter enthalten wird, auch wenn der Anstieg unter Umständen nicht so stark sein wird wie zwischen vorherigen Versionen von GPT. Aufgrund des Trends zu immer größeren Modellen möchten wir nun auf die Skalierbarkeit von Sprachmodellen eingehen.
OpenAI hat dabei in dem Paper „Scaling Laws for Neural Language Models“ selbst empirische Untersuchungen zur Skalierung in Sprachmodellen aufgestellt. Dabei werden Decoder-Only-Transformer als autoregressive Sprachmodelle evaluiert.
Es wurden Eigenschaften wie Parameteranzahl, Größe des verwendeten Trainingsdatensatzes und Trainingsaufwand sowie die Modellarchitektur untersucht. Die Erkenntnisse der Untersuchungen werden wir hier zusammenfassen.
Es lässt sich feststellen, dass die Performance in starkem Maße von der Skalierung der genannten Parameter abhängt. Das bedeutet, dass durch größere Modelle mit mehr Parametern und mehr Trainingsdaten sowie durch einen höheren Trainingsaufwand die Qualität von Sprachmodellen signifikant verbessert wird. Dieser Zusammenhang ist in Abbildung 6 abgebildet. Der Fehler auf den Testdaten nimmt bei Erhöhung der entsprechenden Größen ab.
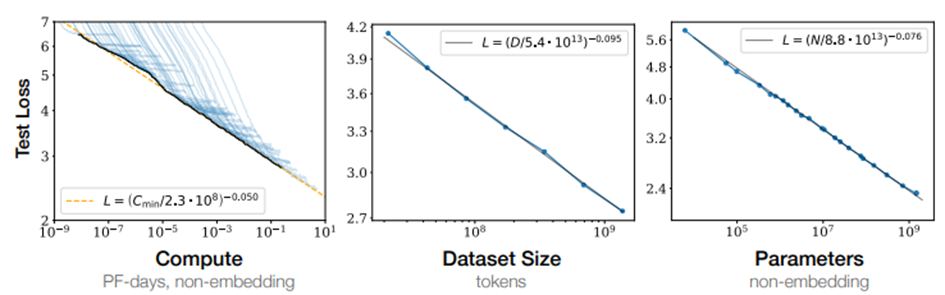
Der Einfluss anderer Modelleigenschaften, wie etwa der Architektur z.B. in Bezug auf Anzahl der Layer hat einen deutlich geringeren Einfluss auf die Qualität des Modells. Bei Erhöhung der Parameteranzahl sollte zwar auch die Menge der Trainingsdaten erhöht werden, in den Experimenten von Open-AI hat sich dabei jedoch gezeigt, dass diese nicht im gleichen Maße erhöht werden müssen. Für eine Erhöhung der Parameteranzahl um den Faktor 8 ist nur eine Erhöhung der Menge der Trainingsdaten um den Faktor 5 nötig, um Overfitting zu vermeiden.
Durch die Experimente wurde auch festgestellt, dass bei größeren Modellen mit mehr Parametern weniger Trainingssamples prozessiert werden müssen, um die gleiche Qualität wie bei einem kleinen Modell zu erreichen (siehe Abbildung 7). Dadurch sollte der Trainingsaufwand größerer Modelle im Vergleich zu kleineren Modellen gering gehalten werden, da nur ein kürzeres Training nötig ist [20].

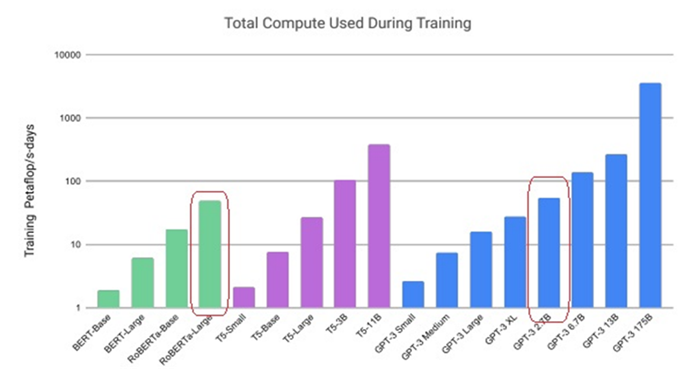
Dies ist auch bei Betrachtung von Abbildung 8 zu erkennen. Hier sind die gesamten Rechenaufwände verschiedener bekannter Modelle abgebildet. Die hervorgehobenen Modelle GPT-3 2.7B (2.65 Mrd. Parameter) und RoBERTa-Large (355 Mio. Parameter) sind beides Tansformer-Sprachmodelle. Trotz der deutlich höheren Parameteranzahl in GPT-3 2.7B sind die Gesamtkosten des Trainings im Vergleich zu RoBERTa-Large nicht wesentlich größer, was sich dadurch begründen lässt, dass zum Training von GPT-3 2.7B deutlich weniger Trainingselemente prozessiert werden müssen [7].
Größere Modelle mögen zwar eine bessere Qualität besitzen und nach der Evaluation von weniger Trainingssamples wird bereits die gleiche Qualität wie in kleinen Modellen erreicht, sie haben dennoch auch einige Nachteile. Der Trainingsprozess ist oft aufwendiger und erfordert mehr Speicherplatz. Das Training von Modellen wie GPT-3 ist nur durch verteiltes Training auf verschiedenen GPUs möglich. Grundsätzlich werden dabei die zwei Vorgehen Model-Parallelism und Data-Parallelism unterschieden. Beim Model-Parallelism erfolgt dabei eine Aufteilung des Modells, während beim Data-Parallelism eine Aufteilung der Daten erfolgt [21]. Wir werden in diesem Blog-Artikel nicht auf Details dazu eingehen, diese wurden bereits unter An overview of Large Scale Deep Learning erklärt.
Gerade das Training auf mehreren Grafikkarten führt zu sehr hohen Energiekosten. Bei GPT-3 werden die Energiekosten zum Pre-Training z.B. auf 1287 MWh. geschätzt, was einem Ausstoß von 552 Tonnen CO₂-Äquivalent entspricht [22].
Fazit
Generell sollte die Anzahl der Modellparameter sorgfältig abgewogen werden, eine höhere Anzahl von Parametern, die unter Umständen zu einer besseren Qualität führt, rechtfertigt nicht immer einen Mehraufwand. Eine einfache Nutzung des Sprachmodells als Anwendung z.B. über einen Chat-Bot wie bei ChatGPT ist für Nutzer ebenso relevant wie eine hohe Qualität der Sprachausgabe. GPT-3 ist im Vergleich mit vielen anderen Sprachmodellen nämlich bei Weitem nicht das größte Modell. Dennoch ist GPT-3 durch ChatGPT aktuell mit Abstand am stärksten im Fokus der Aufmerksamkeit. Die Ausgaben von ChatGPT sind bereits sehr gut. Neben einer Verbesserung durch ein größeres Sprachmodell wären vor allem auch Aspekte wie Verfügbarkeit der Anwendung für den Nutzer relevant, diese sollten nicht ignoriert werden.
Insgesamt lässt sich festhalten, dass die Entwicklung von Sprachmodellen wie ChatGPT in den letzten Jahren rasant vorangeschritten ist und die Modelle immer größer und leistungsfähiger geworden sind. Dabei wurde durch die Skalierung der Parameter auch immer wieder die Frage aufgeworfen, ob dies sinnvoll ist und ob es tatsächlich zu einer Verbesserung der Leistung führt. Die Forschungsergebnisse zeigen jedoch, dass eine Skalierung der Parameter tatsächlich zu einer deutlichen Steigerung der Leistungsfähigkeit von Sprachmodellen führen kann. ChatGPT und ähnliche Modelle sind in der Lage, erstaunlich komplexe Aufgaben zu lösen, wie zum Beispiel das Verfassen von Texten, die kaum von menschlicher Schreibweise zu unterscheiden sind.
Im Hinblick auf die Zukunft stehen jedoch noch zahlreiche Herausforderungen bevor, die es in den nächsten Jahren zu meistern gilt. Eine der wichtigsten Aufgaben ist es, die Modellinterpretierbarkeit zu verbessern, um sicherzustellen, dass Entscheidungen auf nachvollziehbare und transparente Weise getroffen werden können. Darüber hinaus müssen neue Methoden entwickelt werden, um die Rechenressourcen effizienter zu nutzen und den Energieverbrauch der Modelle zu reduzieren. Nichtsdestotrotz haben ChatGPT und ähnliche Modelle das Potenzial, die Art und Weise zu revolutionieren, wie wir mit Sprache interagieren und wie wir Informationen verarbeiten und kommunizieren. Angesichts der rasanten Entwicklung dieser Technologien bleibt es spannend zu beobachten, wie sich diese in Zukunft weiterentwickeln werden und welche Forschungsthemen sich ergeben.
Verwendete Quellen:
| [1] | B. Lutkevich, „Language Modeling,“ März 2020. [Online]. Available: https://www.techtarget.com/searchenterpriseai/definition/language-modeling#:~:text=Language%20modeling%20(LM)%20is%20the,basis%20for%20their%20word%20predictions. |
| [2] | D. Markowitz, „Transformers, Explained: Understand the Model Behind GPT-3, BERT, and T5,“ Medium, 06 Mai 2021. [Online]. Available: https://towardsdatascience.com/transformers-explained-understand-the-model-behind-gpt-3-bert-and-t5-cdbf3fc8a40a. |
| [3] | J. Alammar, „The Illustrated Transformer,“ 27 Juni 2018. [Online]. Available: http://jalammar.github.io/illustrated-transformer/. |
| [4] | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser und I. Polosukhin, „Attention Is All You Need,“ Open-AI, 2017. [Online]. Available: http://arxiv.org/abs/1706.03762. |
| [5] | A. Radford und K. Narasimhan, „Improving Language Understanding by Generative Pre-Training,“ 2018. [Online]. Available: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf. |
| [6] | A. Radford, J. Wu, R. Child, D. Luan, D. Amodei und I. Sutskever, „Language Models are Unsupervised Multitask Learners,“ 2019. [Online]. Available: https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf. |
| [7] | T. B. Brown, B. Mann, N. Ryder, M. Subbiah und J. Kaplan, „Language Models are Few-Shot Learners,“ Open-AI, 28 Mai 2020. [Online]. Available: https://arxiv.org/abs/2005.14165. |
| [8] | Johannes Maucher, „Sequence-To-Sequence, Attention, Transformer — Machine Learning Lecture,“ 2023. [Online]. Available: https://hannibunny.github.io/mlbook/transformer/attention.html#gpt-gpt-2-and-gpt-3. |
| [9] | R. Sagar, „OpenAI Releases GPT-3, The Largest Model So Far,“ 2020. [Online]. Available: https://analyticsindiamag.com/open-ai-gpt-3-language-model/. |
| [10] | M. Ramponi, „How ChatGPT actually works,“ 2022. [Online]. Available: https://www.assemblyai.com/blog/how-chatgpt-actually-works/. |
| [11] | L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. Christiano, J. Leike und R. Lowe, „Training language models to follow instructions with human feedback,“ 2022. [Online]. Available: https://arxiv.org/pdf/2203.02155.pdf. |
| [12] | Alan D. Thompson, „GPT-3.5 + ChatGPT: An illustrated overview – Dr Alan D. Thompson – Life Architect,“ 2022. [Online]. Available: https://lifearchitect.ai/chatgpt/. |
| [13] | Dan Milmo, „ChatGPT reaches 100 million users two months after launch,“ 2023. [Online]. Available: https://www.theguardian.com/technology/2023/feb/02/chatgpt-100-million-users-open-ai-fastest-growing-app. |
| [14] | OpenAI, „ChatGPT: Optimizing Language Models for Dialogue,“ 2022. [Online]. Available: https://openai.com/blog/chatgpt/. |
| [15] | M. Ruby, „How ChatGPT Works: The Model Behind The Bot – Towards Data Science,“ 2023. [Online]. Available: https://towardsdatascience.com/how-chatgpt-works-the-models-behind-the-bot-1ce5fca96286. |
| [16] | Gabriele De Luca, „What is a Policy in Reinforcement Learning?,“ 2020. [Online]. Available: https://www.baeldung.com/cs/ml-policy-reinforcement-learning. |
| [17] | J. Vincent, „OpenAI CEO Sam Altman on GPT-4: ‘people are begging to be disappointed and they will be’,“ 2023. [Online]. Available: https://www.theverge.com/23560328/openai-gpt-4-rumor-release-date-sam-altman-interview. |
| [18] | tagesschau, „Panne im Werbeclip für “Bard”: Google-Textroboter gibt falsche Antwort,“ 2023. [Online]. Available: https://www.tagesschau.de/wirtschaft/google-ki-chatbot-bard-101.html. |
| [19] | Wikipedia, „ChatGPT,“ 2023. [Online]. Available: https://en.wikipedia.org/w/index.php?title=ChatGPT&oldid=1140902725. |
| [20] | J. Kaplan, T. Henighan, T. B. Brown, R. Child, S. Gray, A. Radford, J. Wu und D. Amodei, „Scaling Laws for Neural Language Models,“ Open-AI, 23 Januar 2020. [Online]. Available: https://arxiv.org/abs/2001.08361. |
| [21] | C. Wolfe, „Language Model Scaling Laws and GPT-3,“ Medium, 10 Dezember 2022. [Online]. Available: https://towardsdatascience.com/language-model-scaling-laws-and-gpt-3-5cdc034e67bb. |
| [22] | D. Patterson, J. Gonzalez, U. Hölzle, Q. Le und C. Liang, „The Carbon Footprint of Machine Learning Training Will Plateau, Then Shrink,“ 11 April 2022. [Online]. Available: https://arxiv.org/abs/2204.05149. |
Leave a Reply
You must be logged in to post a comment.