
Part 1 of this series discussed how AI technology can be used for good or evil. But what if the AI itself becomes an attack vector? Could an attacker use my models against me? Also, what’s the worst that could happen? Welcome to the domain of adversarial AI!
Introduction
If you’re reading technology-focused magazines or blogs, you might have stumbled upon the term adversarial examples before. In recent years (mostly since 2013), there has been a large number of publications on them and their possible impact on AI technology. According to the OpenAI blog:
Adversarial examples are inputs to machine learning models that an attacker has intentionally designed to cause the model to make a mistake; they’re like optical illusions for machines.
Some Fun Examples
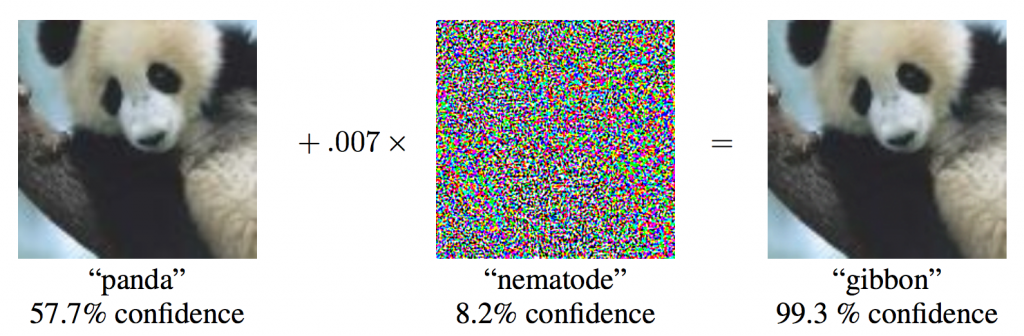
Source: Explaining and Harnessing Adversarial Examples, Goodfellow et al., 2015
The example above shows one of the earlier attacks. In short, an attacker generates some very specific noise, which turns a regular image into one that is classified incorrectly. This noise is so small that it is invisible to the human eye.
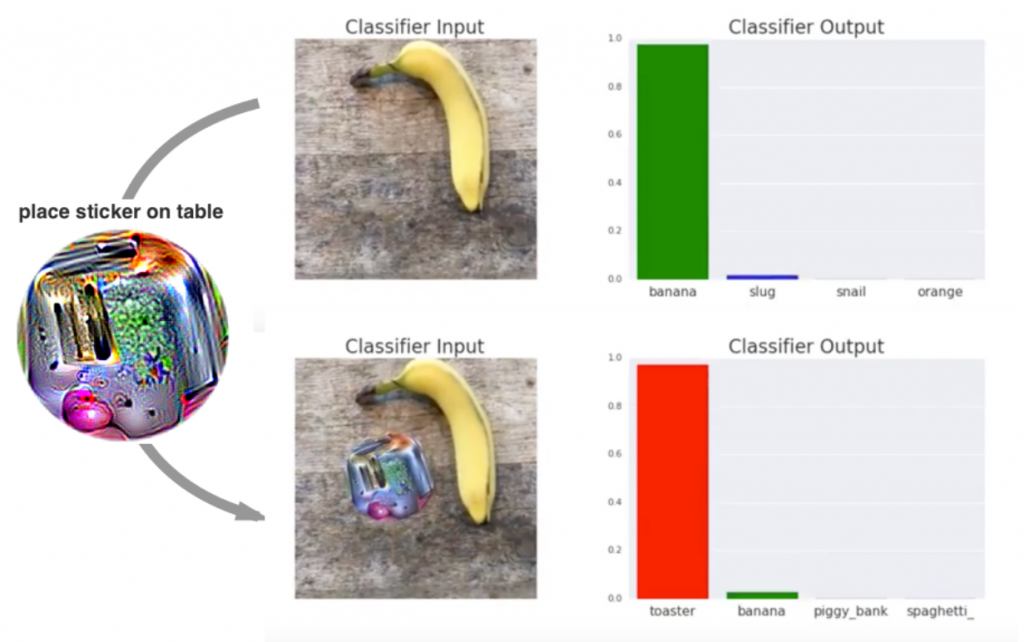
Adversarial attacks can also be applied in the physical world. In this example, a so-called adversarial patch is created. If the patch is present, the attacked classifier detects the image as a toaster, instead of a banana. Such a patch is visible to the human eye, but there are other ways to hide or disguise it. For example, it might be shaped like a pair of glasses. Patches on traffic signs may likewise be designed to look similar to graffiti.
Some Not so Fun Examples
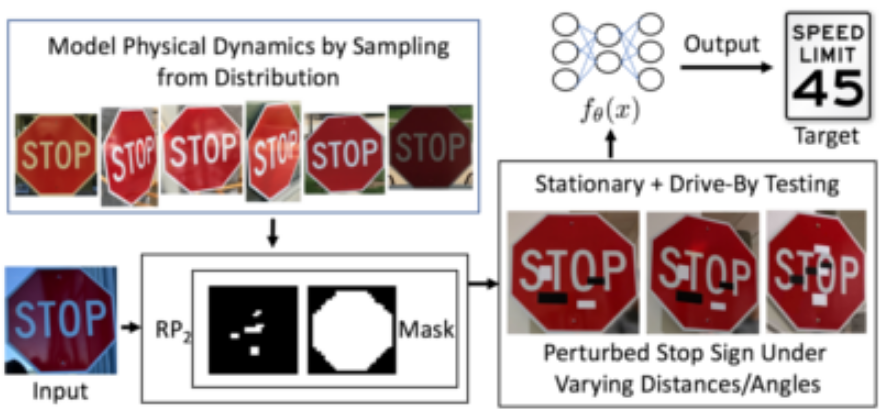
Adversarial attacks are most prevalent in the domain of computer vision, the majority being aimed at misclassification. There are many attack scenarios, from spoofing facial recognition systems to fooling autonomous vehicles. In this example, adversarial examples cause a classifier to mistake a “Stop” sign for a “Speed limit 45” sign. Notably, this attack is robust against changes in scale, rotation and shift of the adversarial patch, which means that it can fool a driving car.
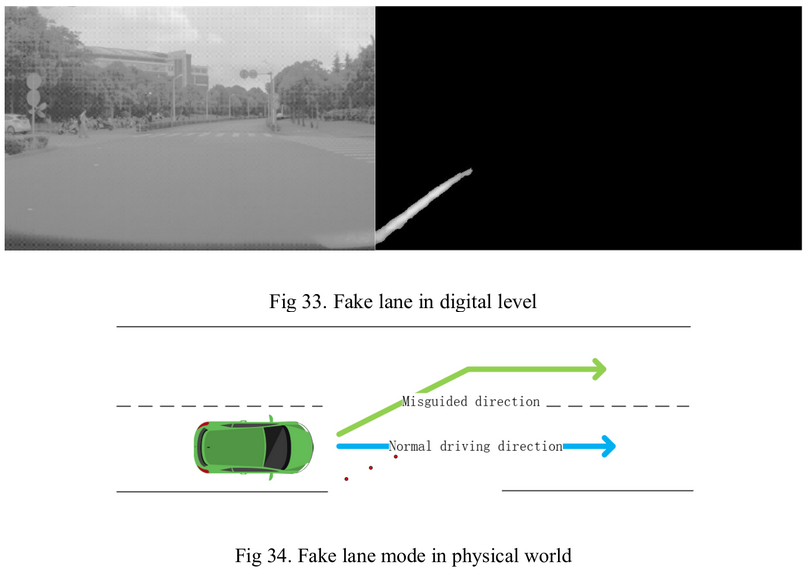
A security report on “Tesla Autopilot” (HW 2.5) from March 2019 found that the platform can be attacked with adversarial examples. The researchers placed adversarial patches on the road to cause the vehicle to detect and follow lanes which weren’t there. The fact that this flaw is (or was) present in a commercial product, firmly places this example in the “not so fun” section.
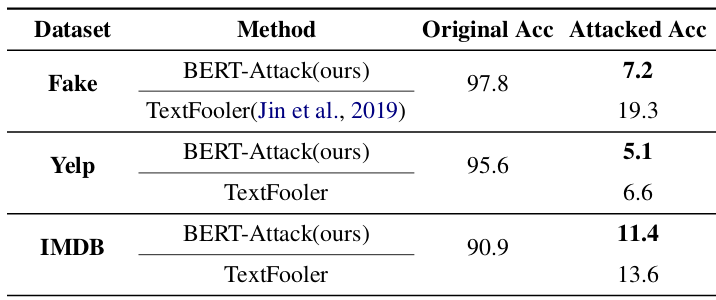
Source: BERT-ATTACK: Adversarial Attack Against BERT Using BERT, Li et al., 2020
Adversarial attacks are by no means restricted to the domain of computer vision. Here is an example from the domain of Natural Language Processing. It shows a successful adversarial attack on the powerful BERT language model, using “BERT-Attack”. In this example, one original task of the model was to classify Yelp reviews as “positive” or “negative” – which BERT did with an accuracy of 95.6 percent. After the attack, BERT’s accuracy was only 5.1 percent – much worse than random. To achieve this, BERT-Attack was able to find the exact words that needed to be replaced with synonyms, to fool the language model.
Not Fun at All
Among adversarial attacks, physical attacks against computer vision are arguably one of the more immediate threats. This is especially true in areas where AI is used in systems with safety- or security relevance, such as autonomous driving or others:
What you don’t want is your enemy putting an adversarial image on top of a hospital so that you strike that hospital.
Jeff Clune, University of Wyoming, on The Verge
Purely digital attacks might not have the same immediate impact, but they also have the potential to cause significant trouble as well. There are many more domains that I didn’t touch on, such as cybersecurity, sentiment analysis, movement prediction etc., and there are some quite uncomfortable scenarios imaginable if one is only creative enough. Adversarial attacks are clearly more than just a theoretical threat. While the exploration of adversarial attack mechanisms has been a rather academic exercise in the past, there is now a growing awareness of them and their potential impact.
Threat Model
Technically, adversarial attacks have been around for almost two decades now, since long before the recent success of deep learning. Early adversarial attacks often involved manual input. For example, a spammer might try to design their spam emails to appear innocuous to spam filters. To that end they would guess “bad words” that are likely to trigger a filter rule and replace them with others. Modern attacks are largely automated and employ machine learning methods themselves.
Most adversarial attacks are designed against some classification mechanism, for example machine learning models. Such classifiers receive some input and react in a certain way, e.g. by returning an output class. An attacker tries to change this behavior in some way the mechanism was not designed.
While adversarial attacks can target any artificial intelligence and machine learning model, today most research into adversarial attacks concerns (deep) neural networks.
There are several factors to consider when modeling an adversarial attack threat: The attacker’s assumed control over the target mechanism, their knowledge about it and finally their goal.
Attack Strategy
Adversarial attacks come in two categories: Poisoning and Evasion attacks. The key difference lies in the attacker’s influence on the target mechanism:
Poisoning Attacks
In a poisoning attack, an attacker has access to the creation process itself. In machine learning models this may happen if an attacker can somehow manipulate the training data. Take our spam example from earlier: An “intelligent” spam filter learns which emails are spam and which are not over time. If an attacker can insert spam emails labeled as “not spam” during this training process, the spam filter will learn to ignore them and won’t filter such spam emails in the future.
Of course, this scenario only works if the attacker has at some point access to the training process. Due to this restriction, poisoning attacks are somewhat less prevalent than evasion attacks.
Evasion Attacks
Evasion attacks on the other hand assume that the target mechanism is already fully developed and immutable. It only assumes that an attacker can send some input to it.
The basic idea is as follows: An attacker causes some minimal change in the input data that they send to the target. This change is either imperceptible to humans, or seems so innocuous that it is simply ignored. The machine learning model on the other hand is affected by this change and produces a different result. Such manipulated inputs are called adversarial examples. An Attacker now has two options: Either the adversarial examples simply throw off the AI model enough as to make it unsuitable for its task (untargeted attack), or they force the model to behave in a specific way designed by the attacker (targeted attack).
In the field of deep learning and especially computer vision, evasion attacks are much more prevalent than poisoning attacks, due not in small part to their applicability in the real world. For that reason, this article will focus on evasion attacks.
Adversarial Example Crafting
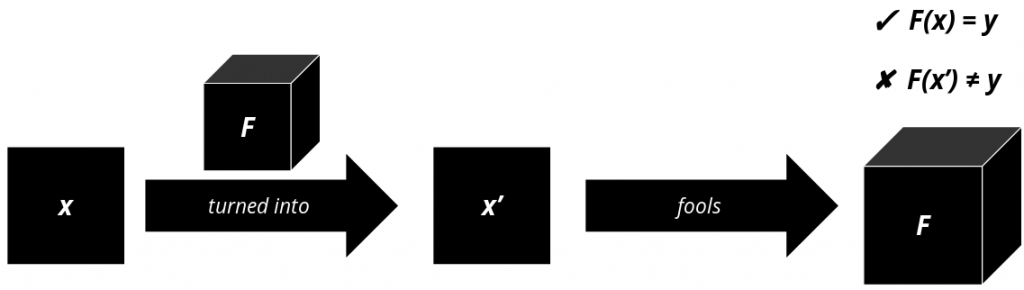
The process of crafting adversarial examples usually requires knowledge about the target’s internal decision boundaries. This information is necessary, since an attacker will try to change the inputs in such a way that the target comes to a different decision, e.g. to make it predict another class than it normally would.
Decision Boundaries
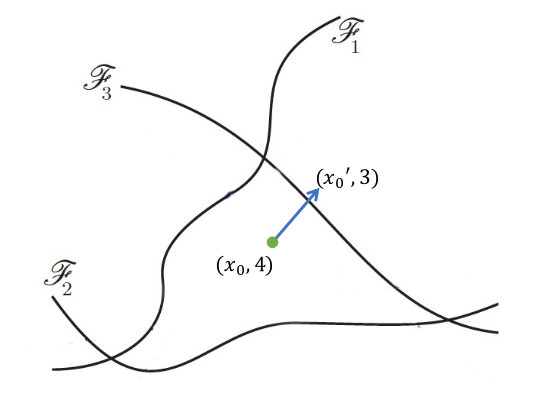
Source: Adversarial AI Survey Paper, Xu et al., 2019
A neural network classifier learns decision boundaries, that allow it to classify an input sample x as its corresponding class y. These decision boundaries are represented by the network’s internal parameters. If an attacker knows where the decision boundaries are, they can change the input example x in such a way that “pushes” it over the boundary.
Perturbation and Robustness
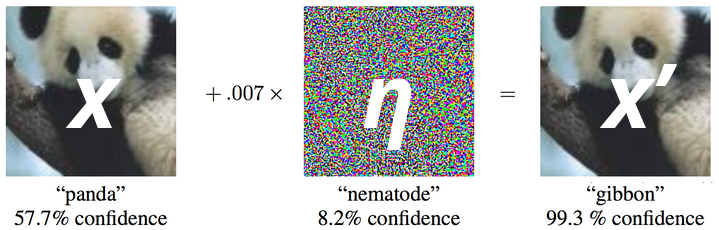
In some attack methods like FGSM, an adversarial example x’ is created from a regular input example by adding some perturbation η. This perturbation is also often called adversarial noise. The noise is then added on top of the original input x. Usually, an attacker tries to make this noise as imperceptible as possible, while still having an adverse effect on the target’s performance.
Conversely, a model is more robust against adversarial attacks, the more perturbation is necessary to fool it. If the minimum necessary perturbation is large enough, the attack may become obvious to the naked eye and the attack is easily detected.
Adversarial Patch
Other attacks, such as most physical attacks, rely on adversarial patches. In such cases, the perturbation isn’t hidden but constrained to some patch within the input image. Here the attacker’s goal is to make the patch as small and unassuming as possible, while retaining its adverse effect.
Transferability
Transferability refers to a property of many adversarial attacks, that allows them to be successful on more than one specific target. This concept can even work across different architectures. Only the domain of the models must be the same.
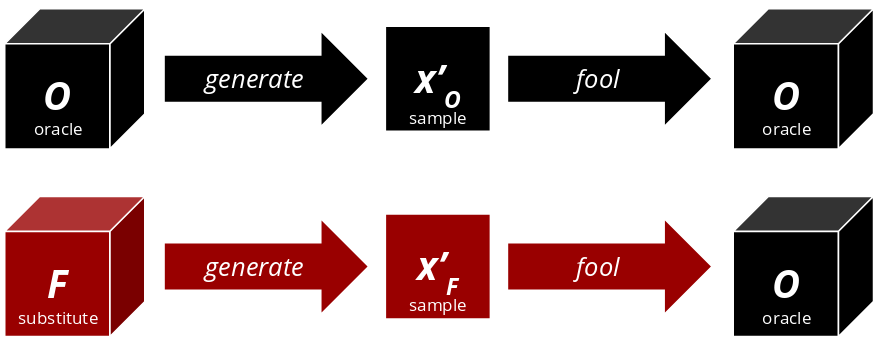
Attacker’s Knowledge
How successful an attack can be largely depends on the information available to the attacker. One common approach to model such information is to consider black-box, gray-box and white-box attacks:
White-box
The attacker knows everything about the target model. They have access to the training data, the neural network graph and the trained parameters. The attacker can essentially use the model against itself.
Gray-box
The attacker only has access to parts of the model, such as the architecture or the classifier’s confidence values. This information is then used to recreate the target model as close to the original as possible.
Black-box
The attacker has no knowledge about the target model at all. However, they can make educated guesses. There are a number of attack strategies, that are each able to extract valuable information from a black-box model. Most of these strategies assume that the attacker correctly guesses the target model’s domain and that they can communicate with the black-box, e.g. through an API. They can then send queries to the black-box model, to learn how it classifies inputs. The goal is again to acquire enough information to recreate a close approximation of the target model.
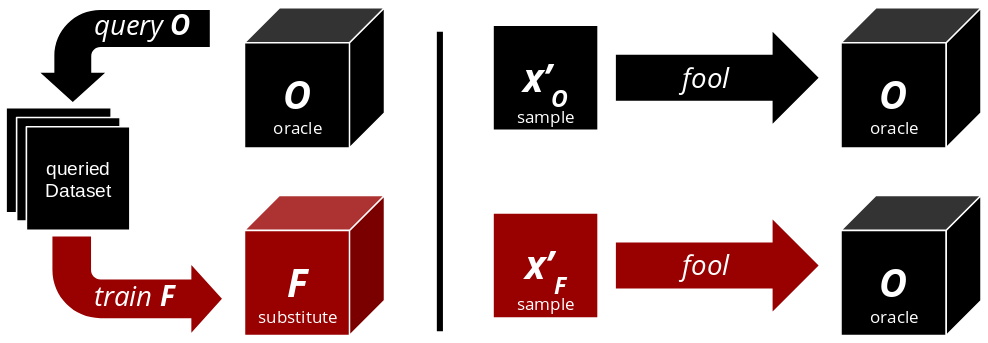
1. The attacker finds input data that fits the domain of the black-box (oracle).
2. The attacker sends the input data to the oracle, which returns predictions.
3. The attacker uses the input data and the labels predicted by the oracle to train a substitute model.
Defending Against Adversarial AI
So what can you do about adversarial attacks? Can they be averted or mitigated? Well, yes and no. Here are some security practices I found – you’ll likely recognize some of the more general ones. Let’s explore what works, what doesn’t, and why.
Gradient Masking
Since many white-box attacks require access to the gradients of a neural network, one way to prevent them is to simply hide their parameters. In practice this boils down to: Don’t put your trained deep neural network up on GitHub for everyone to see, if you want to use it in production. This is what many autonomous car manufacturers do, they keep their network graphs and parameters closed source, which in theory makes it harder to attack them. If that sounds like “security through obscurity” to you: That’s because it is.
The problem with this “defense” is that many attacks are transferable. An attack on one machine learning model may not work perfectly on another, but just well enough. In addition, there are black-box attacks out there that don’t require full access to the original network parameters at all.
Verdict: Gradient Masking is better than nothing, but it doesn’t really work as a defense strategy on its own, other than giving you a false sense of security.
Rate Limiting
Say you employ gradient masking and put your neural network behind an API. A user sends some input (e.g. an image), the API returns some output (e.g. a classification). An attacker can only observe the black-box from outside. Without rate limiting, you’re now inviting a substitute model black-box attack. An attacker can send as many queries against the API as they like, until they have labeled a complete dataset. They then train their own substitute model that has the same internal decision boundaries as the original, and attack from there.
Rate limiting can prevent some substitute model attacks, because sending millions of queries would simply take forever. Depending on your use case, you can even use CAPTCHAs or charge money for every API use.
On the flip side, this still doesn’t protect against some of the more advanced black-box attacks. Some of these are especially designed to minimize the number of queries necessary to create a good substitute.
Verdict: It’s a good idea to use rate limiting, but it doesn’t offer consistent protection either and may significantly impact user experience.
Input Validation
Given that most recent adversarial attack methods use machine learning techniques, it only makes sense to use machine learning techniques to defend against them. To neutralize adversarial examples before they reach their target, one can use a secondary detector model. Such a model is either trained to flag and filter adversarial examples, or to turn them into regular, harmless examples. The latter can be done by training a denoising autoencoder to remove any adversarial noise from its input examples and pass only the “cleaned” inputs to the primary model. The advantage of input validation is that the actual model (the one with the business logic) can stay as-is. The downside here is that you’ll have to train and maintain yet another model. The second disadvantage is the increase in latency, because every input goes through two neural networks now. Finally, there’s no guarantee that a detector itself cannot be fooled.
Verdict: Input validation with a detector model can actually be a reasonable protection against known adversarial attacks, but it comes with high recurring costs.
Adversarial Training
Finally, one can try and make the model itself more robust to attacks. Remember that the main problem with adversarial examples is that the target model has never seen that specific type of noise during training. Adversarial training means that adversarial examples are added to the training data, so that some specific attacks become useless against the model. Unfortunately, this can make the model larger and more complex, as it must learn more information. This drives up training cost for no immediate performance gain. Finally, adversarial training might theoretically open the door for poisoning attacks. If detected adversarial examples are used in training, an attacker might thus manipulate the training process itself.
Verdict: This is a valid defense method, but it comes with high recurring costs, because it must be done again once new attacks are discovered. The space of possible adversarial attacks is very large, so it is intractable to defend against all of them. This means that adversarial training is only a crutch, but cannot fix the deeper problem.
The Deeper Problem
The issue with the “solutions” above is that they are all only symptomatic fixes. The deeper problem lies within a general limitation of state-of-the-art machine learning, that has been documented as early as 2014:
These results suggest that classifiers based on modern machine learning techniques, even those that obtain excellent performance on the test set, are not learning the true underlying concepts that determine the correct output label. Instead, these algorithms have built a Potemkin village that works well on naturally occuring data, but is exposed as a fake when one visits points in space that do not have high probability in the data distribution. […]
Goodfellow et al., Explaining and Harnessing Adversarial Examples
We regard the knowledge of this flaw as an opportunity to fix it.
In other words: Current machine learning models do not really understand the concept of what they see. All they learn is some shallow set of rules that happens to result in the expected behavior. As soon as some pattern appears which they haven’t seen during training, their flaw will be revealed.
This means in practice that there is never a guarantee against adversarial attacks, because there are simply too many ways to create such patterns. Machine learning models cannot be made proactively robust against every possible attack, because that would require them to understand the true concept behind the data. That leaves us in a situation where:
The current state-of-the-art attacks will likely be neutralized by new defenses, and these defenses will subsequently be circumvented.
Xu et al., Michigan State University, 2019 Survey Paper
Some even call it an adversarial AI arms race. A grim outlook? Perhaps, but it is at least something we can work with.
General Strategy
A recent report published by Accenture Labs features a three-step plan on how to prepare for adversarial threats. I’ve compiled the items that I found most actionable, as well as a few of my own thoughts:
- Take stock of everything in your organization that uses AI models.
- Think about which AI components are exposed to third parties (and who they are).
- Have some process to assess the risks of your active models regularly.
- Keep your models current, define a model lifecycle and replacement strategy.
- Rank and prioritize each model by its associated risk.
There is not yet a dedicated security process (that I know of) for adversarial attacks. That said, many existing security principles and management processes should readily apply to adversarial risks as well.
Conclusion
AI and deep learning models expose a new attack surface that has appeared alongside the deep learning boom of recent years. New papers on attacks and defenses keep appearing constantly, some even call it an arms race.
So far, we know adversarial attacks mostly from controlled academic settings. That said, the possibility of actual large scale attacks is certainly a reality, since many productive systems have been shown to be prone to such attacks.
There is not (yet) a panacea against adversarial attacks, because they exploit the limitations of machine learning as it exists today. However, there are ways to protect against adversarial threats, if one knows which systems are vulnerable and how to strengthen them.
Further Reading
Sources
- Accenture Labs AI Security Report Overview
- Accenture Labs AI Security Full Report
- Adversarial AI Survey Paper, Xu et al., 2019
- Adversarial Patch, Brown et al., 2018
- Attacking Machine Learning with Adversarial Examples (OpenAI blog)
- BERT-ATTACK: Adversarial Attack Against BERT Using BERT, Li et al., 2020
- Cleverhans AI Security Blog (OpenAI)
- Experimental Security Research of Tesla Autopilot, Tencent Keen Security Lab, 2019
- Explaining and Harnessing Adversarial Examples, Goodfellow et al., 2015
- Magic AI: these are the optical illusions that trick, fool, and flummox computers (The Verge)
- McAfee Labs 2018 Threats Predictions
- Robust Physical-World Attacks on Deep Learning Visual Classification, Eykholt et al., 2018
Code Repositories on Adversarial AI and Defenses
More Interesting Reads
- A great German article on physical adversarial attacks against autonomous vehicles: Pixelmuster irritieren die KI autonomer Fahrzeuge
Leave a Reply
You must be logged in to post a comment.