Auf zu neuen Ufern: Einleitung
Die Cloud-Computing-Technologie hat die Art und Weise, wie Unternehmen Anwendungen entwickeln, bereitstellen und skalieren, revolutioniert. In diesem Beitrag, der im Rahmen der Vorlesung “143101a System Engineering und Management” entstanden ist, werden wir uns darauf konzentrieren, wie eine bereits bestehende Webanwendung zur Visualisierung und Filterung von Aktienkennzahlen auf der IBM Cloud-Infrastruktur bereitgestellt werden kann. Dabei liegt der Fokus nicht auf der Anwendung selbst, sondern vielmehr auf den verwendeten Cloud-Ressourcen und dem Prozess der automatisierten Bereitstellung mithilfe von Terraform. Ziel ist es, eindrücklich zu zeigen, wie die Verwendung von cloud-native Ressourcen und Tools die Hochverfügbarkeit, Skalierbarkeit und Effizienz einer Webanwendung gewährleisten kann.
Den Kurs festlegen: Überblick Architektur
Aufbau der Aktien Webanwendung
Die Webanwendung, die vorab im Rahmen der Veranstaltung “143111a Web Application Architecture” entstanden ist, umfasst die folgenden Services:
- Next.js Frontend: Eine interaktive Anwendungsoberfläche, die es Benutzern ermöglicht, Kennzahlen von Aktien (KGV, KBV, etc.) auf einem Dashboard anzeigen zu lassen und neue, interessante Aktien durch eine Filter-Funktion zu finden.
- Node.js Web-Server: Ein Backend-Server, der Anfragen vom Frontend entgegennimmt und verarbeitet. Der Web-Server ist für die Authentifizierung des Nutzers zuständig und speichert die Nutzerdaten in einer MongoDB.
- Python-Server: Ein Server, der Aktiendaten von einer externen Aktien-API abruft und sie für das Web-Server-Backend bereitstellt. Eine Redis Datenbank wird zum Cachen von Aktiendaten verwendet, da täglich nur eine beschränkte Anzahl an Requests an die externe API gerichtet werden können.
Architektur der Cloud Infrastruktur
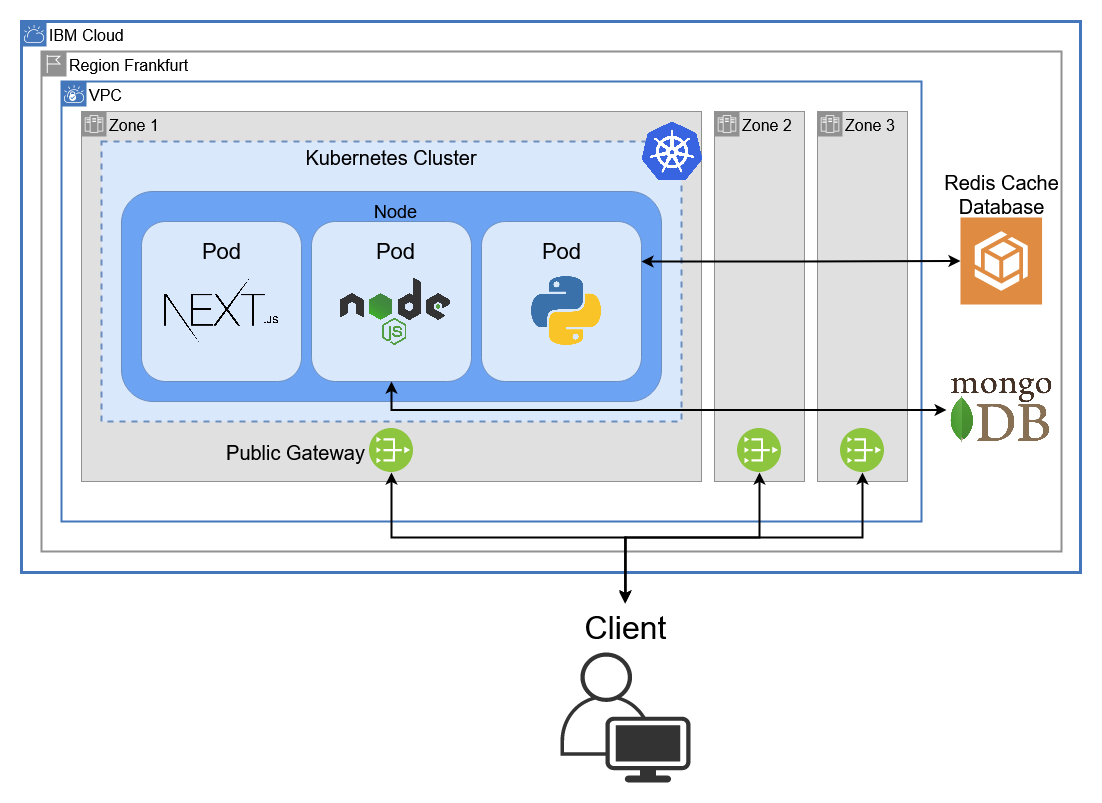
Networking mit Virtual Private Cloud
Die Verwendung einer VPC (Virtual Private Cloud) als logisch isoliertes Netzwerk innerhalb der öffentlichen IBM Cloud Infrastruktur ermöglicht es, Cloud-Ressourcen in einer privaten und sicheren Umgebung zu betreiben. Die VPC wird in der Region Frankfurt bereitgestellt und erstreckt sich über drei Zonen, wobei jede Zone einem physischen Datenzentrum in dieser Region entspricht. Durch die geografische Redundanz des Netzwerks über drei voneinander unabhängige Datenzentren kann die Verfügbarkeit des Netzes gewährleistet werden, selbst wenn eines dieser Datenzentren ausfallen sollte. Die VPC verfügt außerdem über einen reservierten Adressbereich(Subnet) und ein öffentliches Gateway in jeder Zone, um Services organisieren und mit dem Internet verbinden zu können. Die Regulierung von eingehendem und ausgehendem Netzwerkverkehr auf die VPC kann durch die Verwendung von Sicherheitsgruppen und Zugriffskontrolllisten bewerkstelligt werden.
Orchestrierung mit Kubernetes
Der zentrale Baustein der Infrastruktur ist ein Kubernetes Cluster, das in der VPC als Einzel-Zonen-Cluster mit einer Node bereitgestellt wird. Kubernetes (altgriechisch für Steuermann, passend zum Seemanns-Thema dieses Beitrags) ist eine Open-Source-Plattform, die eine automatische und skalierbare Container-Orchestrierung bietet. Dies ermöglicht es, Anwendungen flexibel zu skalieren und automatisch auf wechselnde Lasten zu reagieren. Die containerisierten Services der Aktien-Webanwendung werden durch Deployments in Pods im Cluster bereitgestellt. Zusätzlich verfügt jeder Pod über einen eigenen Kubernetes-Service, der ihn innerhalb des Clusters für andere Pods freigibt. Nur der Pod, in dem das Next.js-Frontend gehostet wird, verfügt über einen zusätzlichen Loadbalancer-Service, der eine Verbindung über das Internet ermöglicht. Durch die Verwendung von Kubernetes kann eine hohe Verfügbarkeit der einzelnen Services garantiert werden, da ein gecrashter oder fehlerhafter Pod automatisch neu gestartet wird.
Persistenter Speicher mit MongoDB und Redis
Die persistente Datenspeicherung wird durch die Verwendung von IBM Cloud Databases for MongoDB und Redis sichergestellt. Beide Datenbanken werden außerhalb des VPC Netzwerkes in der IBM Cloud bereitgestellt. MongoDB ermöglicht die effiziente Speicherung von Daten in einem dokumentenorientierten NoSQL-Format, während Redis als In-Memory-Datenbank eine schnelle Datenverarbeitung und -abfrage ermöglicht. Um von dem Kubernetes Cluster auf die Datenbanken zugreifen zu können, werden Service Credentials benötigt, welche über ein sog. Service Binding als Kubernetes Secret im Cluster hinterlegt werden und von Pods verwendet werden können.
Architektur der CI/CD Infrastruktur
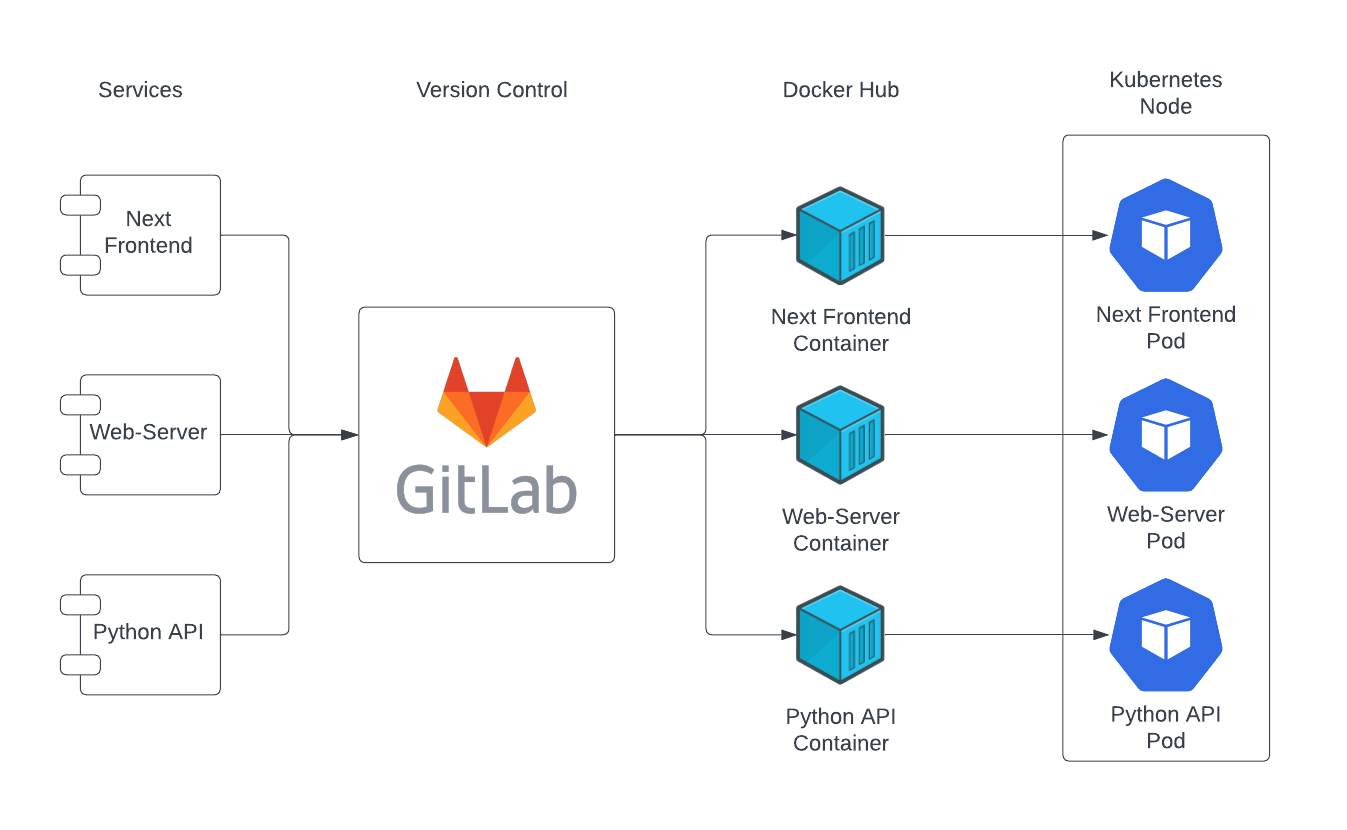
Unser Projekt sollte auf jeden Fall eine effiziente CI/CD Pipeline haben, die wir für Automatisierungen nutzen können. Ebenfalls soll durch Versionskontrolle die Zusammenarbeit erleichtert werden, da Änderungen transparent und nachvollziehbar sind. Automatische Builds werden bei jedem Push auf den Main Branch durchgeführt, wodurch eine schnelle Iteration ermöglicht wird. Die Docker-Images werden zentral auf Docker Hub gespeichert, was die Verfügbarkeit und Verwaltung erleichtert. Dank dieser Pipeline ist kein manuelles Eingreifen erforderlich, was zu einer geringeren Fehleranfälligkeit und vor allem zu reproduzierbaren Builds führt.
Containerization mit Docker
Docker ist eine Plattform, die es ermöglicht, Anwendungen in isolierten Containern auszuführen. Diese Container sind eigenständige Umgebungen, die alles enthalten, was eine Anwendung zur Ausführung braucht. Die Vorteile von Docker liegen in seiner Portabilität, Effizienz und Skalierbarkeit. Durch die Verwendung von Docker können Anwendungen schnell entwickelt, getestet und bereitgestellt werden, was Zeit und Kosten spart. Außerdem verbessert Docker die Sicherheit, indem es Konflikte zwischen Anwendungen verhindert und die Ressourcennutzung optimiert.
Um die Entwicklung und das Testen unserer drei Services zu erleichtern, haben wir uns für die Containerisierung mit Docker entschieden. Jeder Service wird in einem eigenen Container gehostet, der sowohl für die lokale Entwicklung als auch für das Hosting auf einem Kubernetes-Node verwendet werden kann.
Version-Control mit Gitlab und GitHub
Für die Versionierung der Aktien-Anwendung verwenden wir die GitLab Instanz aus der HdM Infrastruktur, während die Terraform Konfigurationsdateien in einem separaten GitHub-Repository abgelegt sind. Durch die Verwendung von Git als Versionskontrollsystem können wir Änderungen an unserem Code verfolgen, verwalten und kollaborativ bearbeiten. GitLab und GitHub bieten eine benutzerfreundliche Oberfläche für das Management unserer Repositories sowie Funktionen wie Branching und Merging, um parallel an verschiedenen Funktionen zu arbeiten und Änderungen sicher zusammenzuführen. Dies fördert die Zusammenarbeit im Team und ermöglicht eine effektive Code-Verwaltung. Darüber hinaus ermöglichen die beiden Versionskontroll-Plattformen die Integration von CI/CD Pipelines, was die Automatisierung von Tests und Bereitstellungsprozessen erleichtert und die Effizienz unserer Entwicklungsprozesse weiter steigert.
Terraform-as-a-Service mit IBM Cloud Schematics
Mit Schematics bietet IBM Cloud ein Cloud-Angebot an, das das Infrastructure-as-Code-Tool Terraform (dazu gleich mehr) in die Cloud bringt. Das bedeutet, dass Terraform-Konfigurationsdateien ohne die lokale Installation von Terraform in der Cloud ausgeführt werden können und mehrere Nutzer am selben Konfigurations-State arbeiten können. Schematics bezieht die Konfigurationsdateien aus einem verknüpften GitHub-Repository und ermöglicht die Organisation von Cloud-Ressourcen in Arbeitsbereichen. Mit IBM Schematics ist es ebenfalls spielend leicht eine tekton CI/CD Pipeline zwischen dem verknüpften GitHub-Repository und dem Arbeitsbereich bereitzustellen, wodurch dieser automatisch mit den neuesten Änderungen an der Terraform Konfiguration versorgt wird.
Segel Setzen: Implementierung und Bereitstellung
Bereitstellung mit Terraform
Terraform, ein Open-Source Infrastructure as Code Tool von HashiCorp, ermöglicht die deklarative Definition, Bereitstellung und Verwaltung von Cloud-Ressourcen durch Konfigurationsdateien in der HashiCorp Configuration Language (HCL). Terraform automatisiert die Bereitstellung und Skalierung von Cloud Ressourcen, sorgt für wiederholbare, konsistente Deployments und orchestriert alles von der Erstellung virtueller Maschinen bis hin zur Konfiguration von Datenbanken. Die deklarative Natur von Terraform gewährleistet Konsistenz zwischen Umgebungen, während Automatisierung, Wiederholbarkeit und minimierte menschliche Fehler die Verwaltung der Infrastruktur effizienter machen.
Modularität durch Terraform Modules
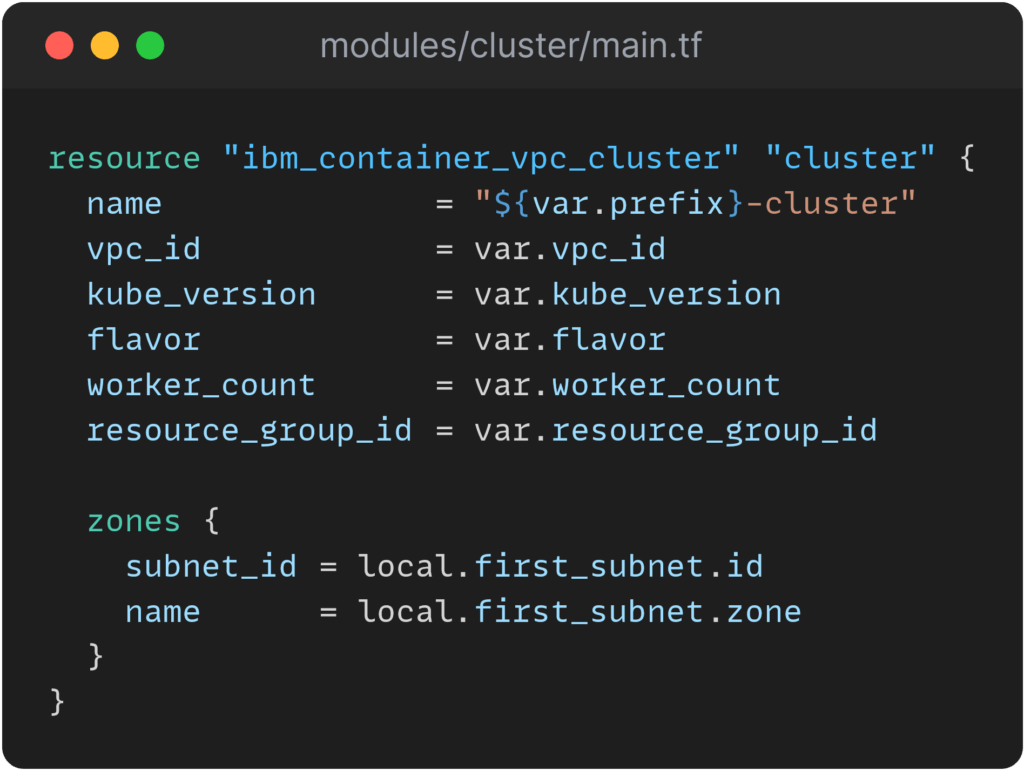


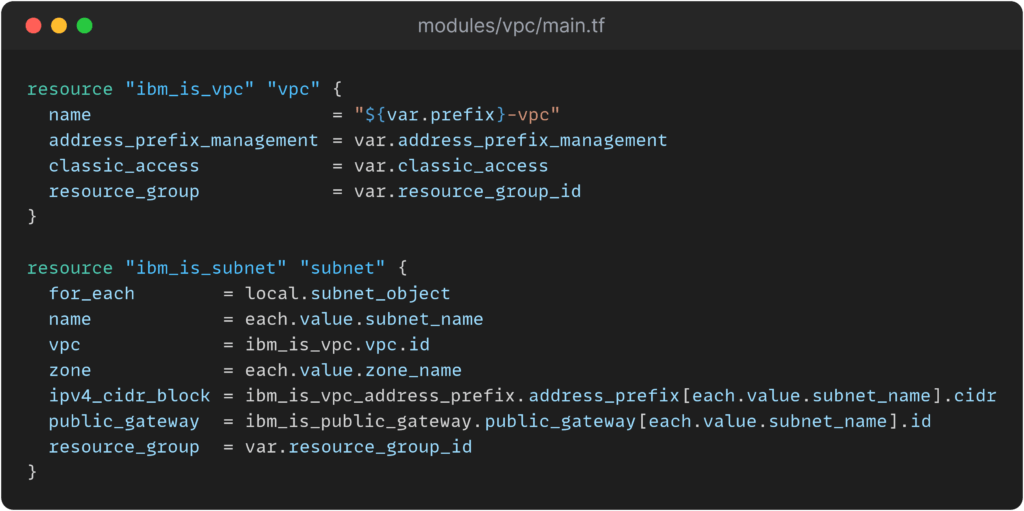
Mit Terraform können wiederverwendbare Module definiert werden, die zu einer übersichtlichen Struktur der Konfigurationsdateien beitragen. Module können speziell für ein Projekt erstellt werden, es können aber auch fertige Module aus dem Internet der Konfiguration hinzugefügt werden, sofern diese den gewünschten Zweck erfüllen. Für die Bereitstellung der Infrastruktur für die Aktien-Webanwendung wurden mehrere Module erstellt, darunter beispielsweise zwei Module für die Bereitstellung des VPC-Clusters, eines für die Konfiguration der VPC und eines für das Kubernetes Cluster. Im VPC-Modul werden die Zonen, Subnetze und Adresspräfixe der Virtual Private Cloud definiert, während im Cluster-Modul u.a. der Flavor, die Kubernetes-Version und die Anzahl an Worker-Nodes konfiguriert wird. Auch die Bereitstellung der drei Aktien-Services wird modular durchgeführt, indem für jeden Service die nötigen Kubernetes Ressourcen in einem Modul festgehalten sind. Über Umgebungsvariablen bekommen die Service-Container alle notwendigen Daten, um miteinander kommunizieren zu können. Zwei weitere Module sind für die Installation von MongoDB und Redis außerhalb der VPC zuständig. Die Module beinhalten die nötigen IBM Cloud Ressourcen für die Provisionierung der beiden Datenbanken, sowie die Credentials, um eine Verbindung mit den Datenbanken herzustellen.
Automatische Docker Builds
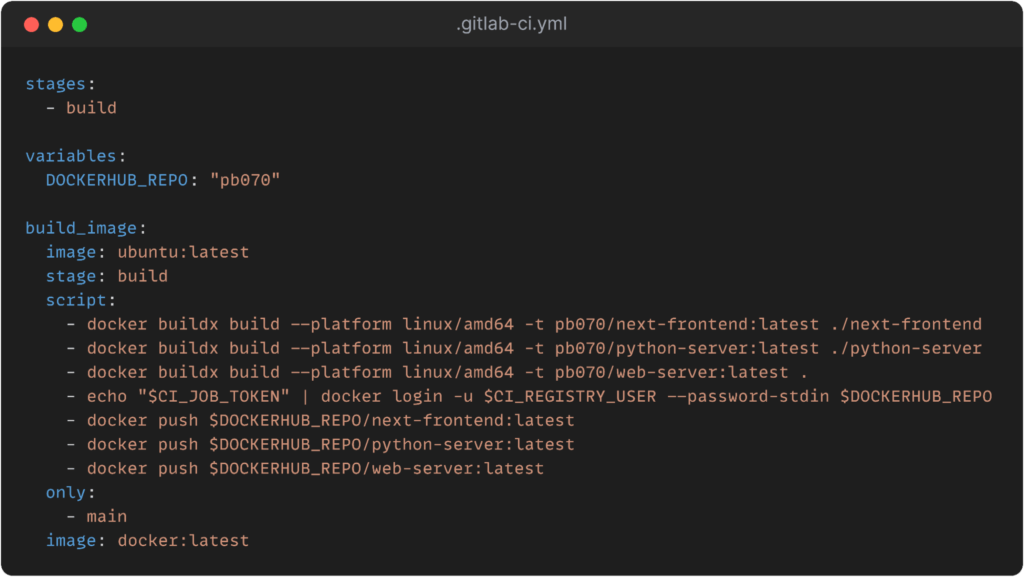
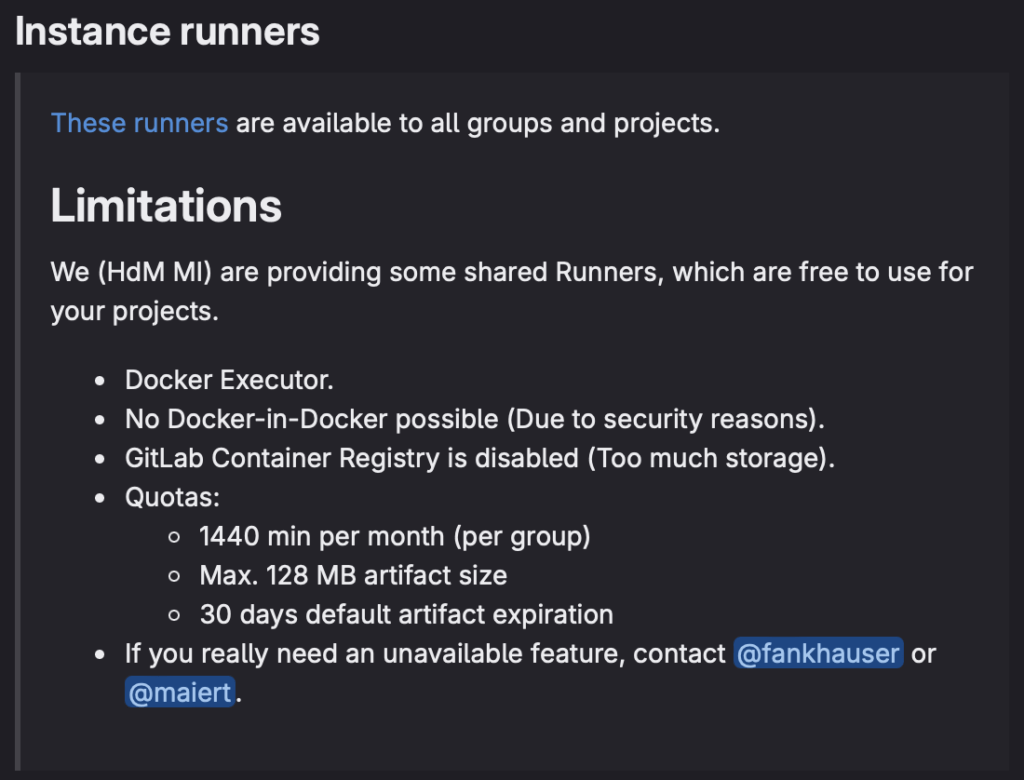
Die Build Pipeline ist ein entscheidender Bestandteil unseres Continuous Integration/Continuous Deployment (CI/CD)-Prozesses, der sicherstellt, dass unsere Anwendungen stets auf dem neuesten Stand sind. Durch die Automatisierung dieses Prozesses können wir effizientere Entwicklungszyklen erreichen und die Ausfallsicherheit unserer Anwendungen verbessern. Darüber hinaus ermöglicht die Integration von GitLab, Docker Hub und Kubernetes eine nahtlose Bereitstellung unserer Anwendungen in einer skalierbaren und zuverlässigen Umgebung.
Der ursprüngliche Plan war es, dass bei jedem Push auf Main eine Build Pipeline in GitLab gestartet wird und ein Job läuft, der die Docker Images neu baut und in den Docker Hub pusht. Von dort aus zieht sich unser Kubernetes Cluster die Images und erzeugt neue Pods, sobald ein Update verfügbar ist. Leider konnten wir diesen Plan nicht komplett umsetzen, da “Docker in Docker” im HdM Gitlab nicht erlaubt ist. Der Worker ist so aufgesetzt, dass er ein Base Image (z.B. Ubuntu) nimmt und die Applikation darin baut. Da wir beim Bauen aber auch Docker aufrufen, haben wir hier einen “Docker in Docker” Fall. Nun machen wir es so, dass es ein Shell Script gibt, welches die Images baut und pusht. Dieses Script muss allerdings manuell gestartet werden.
Schwierige Gewässer kartieren: Herausforderungen und Lösungen
Limitierungen von Terraform
Obwohl Terraform viele tolle Features umfasst, bringt es auch einige Limitierungen mit sich. Trotz des Terraform Syntax-Highlighting und der Autovervollständigung entstehen häufig Syntax-Probleme, die erst zum Zeitpunkt der Anwendung der Konfiguration bemerkt werden, da Terraform nicht das Format oder den Wert der Variablen, sondern lediglich den Datentyp überprüft. Außerdem hat jeder Cloud-Anbieter seine individuellen Funktionen und Einschränkungen. Als Entwickler muss man sich dieser anbieterspezifischen Nuancen bewusst sein, um unerwartetes Verhalten zu vermeiden. Einzig und allein die Dokumentation des Providers und viel Trial&Error können hier weiterhelfen, allerdings kann das ziemlich frustrierend und zeitaufwendig sein.
Cross-Platform-Kompatibilität

Da wir die Docker Images auf einem Mac mit ARM64 Architektur entwickelt und gebaut haben, stellten wir beim Deployment in die Pods fest, dass die Binaries, wie sie z.B. für Python Skripte erstellt werden, nicht auf den Pods laufen. Unser Node in der IBM Cloud basiert auf AMD64 und somit müssen auch die Docker Images dafür gebaut werden. Glücklicherweise bietet Docker mit der Funktion buildx eine einfache Möglichkeit, Images für mehrere Plattformen durch sogenannte “Multi-Platform Images” zu erstellen.
Diese können für mehrere Plattformen gleichzeitig gebaut werden. Ein weiterer Vorteil ist, dass auch wenn ein Image für die AMD64 Architektur gebaut wurde, es unter ARM64 als Emulation läuft. Dies ist natürlich sehr instabil und nicht effizient, aber es reicht aus, um rudimentäre Tests durchzuführen.
TLS Zertifikate in Docker
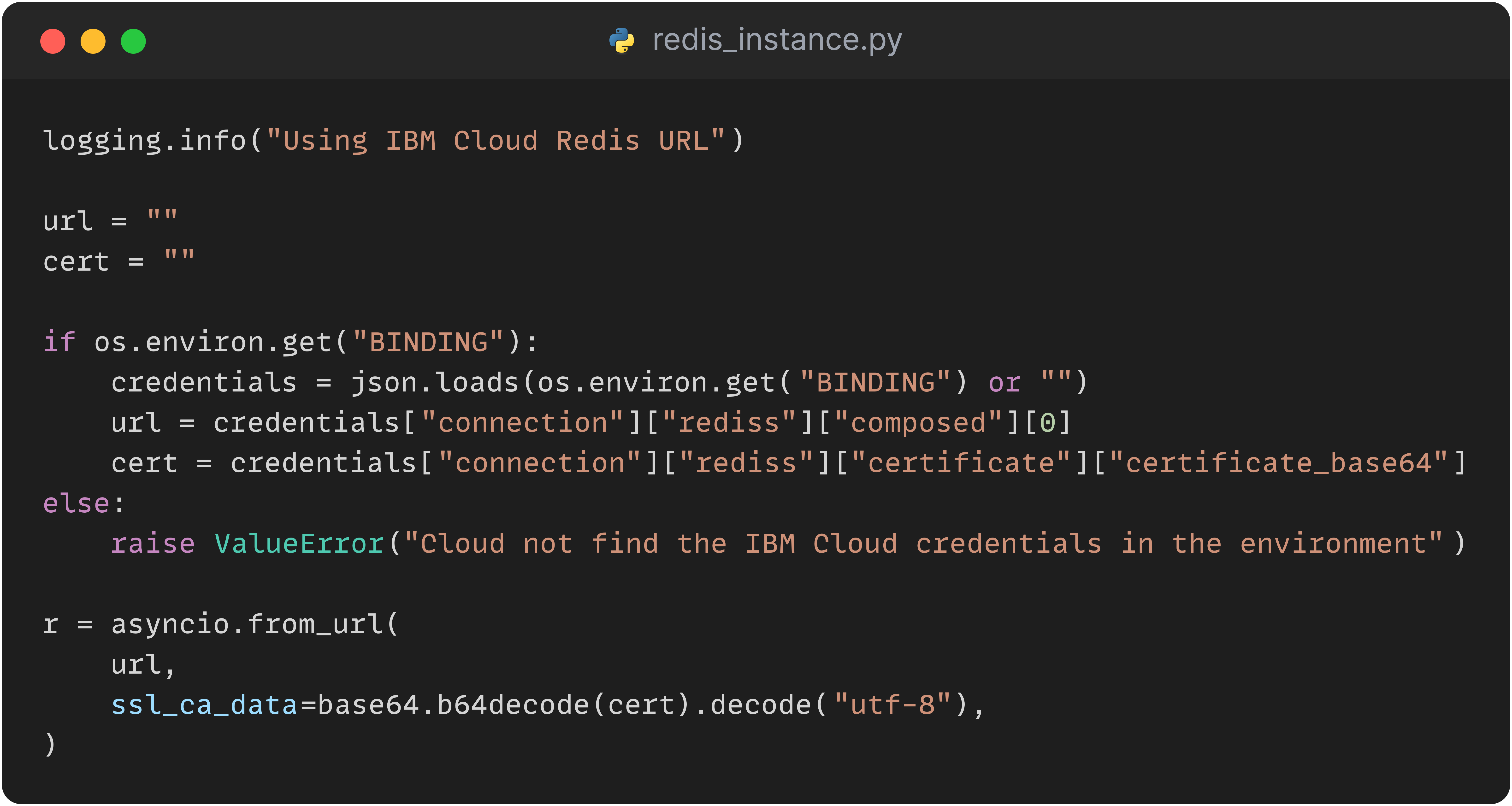
Für den Verbindungsaufbau zu den MongoDB- und Redis-Ressourcen in der IBM Cloud ist die Angabe eines SSL/TLS-Zertifikats erforderlich. Damit kann eine verschlüsselte Verbindung zwischen den Diensten hergestellt werden. Oftmals liegen diese Zertifikate als Dateien vor, die dann auf dem Server oder Client installiert und mitgesendet werden können. Die Methoden der Klassen von MongoDB und Redis erlauben zwar jeweils die Angabe eines Dateipfades für diese Zertifikate, jedoch erschien uns dies als eher suboptimale Lösung, da sonst ein Prozess implementiert werden müsste, der die Existenz und Gültigkeit dieser Dateien überprüft. Ein weiteres Problem ist, dass das Zertifikat zwar einfach heruntergeladen werden kann, aber schnell ungültig wird, wenn wir zum Beispiel die Ressourcen durch Terraform abreißen und neu aufbauen.
Hier bietet die IBM Cloud eine elegante Möglichkeit, das Zertifikat einfach über ein Binding Secret als eine Umgebungsvariablen an den Pod zu geben und als JSON-String an die entsprechenden Methoden zu übergeben. So ist das Zertifikat immer aktuell und mit wenigen Zeilen Code in unserem Service implementiert.
Ein Image für die Cloud und die lokale Entwicklung

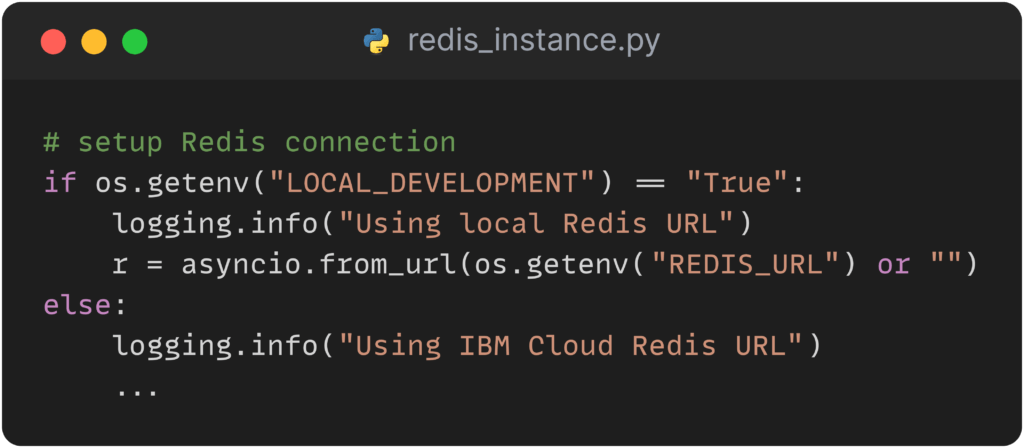
Unser Ziel ist es, dasselbe Docker Image sowohl für die lokale Entwicklung als auch für die Cloud-Bereitstellung zu verwenden. Auf diese Weise können wir alle Services lokal in einem Docker Container hosten und ausgiebig testen, bevor sie in die Cloud verschoben werden. Um dies zu erreichen, haben wir ein Docker Compose File erstellt, das alle Services in einem gemeinsamen Netzwerk verbindet. Dabei nutzen wir Umgebungsvariablen, um zwischen dem lokalen Entwicklungsmodus und dem Cloud-Betrieb umzuschalten.
Mit Hilfe dieser Umgebungsvariablen können wir die Services auf LOCAL_DEVELOPMENT setzen, wodurch sie standardmäßig lokale IP-Adressen wie beispielsweise localhost:6379 anstelle der IBM Cloud IP-Adressen verwenden. Dies ermöglicht eine nahtlose Anpassung der Umgebung je nach Bedarf, ohne das Docker Image ändern zu müssen. Auf diese Weise wird die Entwicklung und Wartung unserer Services erheblich vereinfacht und beschleunigt.
Volle Fahrt voraus: Fazit und Zukunftsaussichten
Insgesamt ist das Hosting einer eigenen Web-App, die aus drei einzelnen Services besteht, in der Cloud ein spannendes Projekt. Die Kombination von Terraform und Kubernetes bietet nicht nur eine effiziente, skalierbare und hochverfügbare Lösung, sondern löst auch spezifische Probleme im Bereich der Infrastrukturverwaltung. Durch die Nutzung dieser Tools können Entwicklerteams ihre Ressourcen effizienter nutzen und sich auf die Weiterentwicklung und Optimierung der Anwendung konzentrieren. Jedoch erfordert es gründliche Überlegungen, wie die einzelnen Services strukturiert werden müssen, damit am Ende ein reibungsloses automatisches Deployment möglich ist.
Besonders im Umgang mit Terraform können einige Herausforderungen auftreten. Die Vielzahl an Details und die oft undurchsichtige Fehlerursache können dazu führen, dass man viel Zeit mit Debugging verbringt. Es kommt nicht selten vor, dass ein Fehler aufgrund einer Kleinigkeit wie einem falschen Wort oder einer veralteten Konfiguration entsteht, von der man dachte, sie könne nicht Teil des Problems sein.
Docker hingegen ist eine vergleichsweise einfach zu beherrschende Technologie mit vielen Vorteilen. Die Gewissheit, dass jeder den gleichen Stand einer Applikation auf seinem Rechner hat und typische Probleme wie das “aber auf meiner Maschine läuft es” vermieden werden, erleichtert die Entwicklung erheblich.
Eine Verbesserungsmöglichkeit für unser Projekt wäre sicherlich das automatische Erstellen der Docker-Images in GitLab. Dadurch könnte die gesamte Pipeline vom Bauen bis hin zum Bereitstellen der Infrastruktur automatisiert werden. Auch die Erweiterung des Clusters zu einem Mehrzonen-Cluster würde sich positiv auf die Verfügbarkeit und Zuverlässigkeit der Umgebung auswirken, jedoch war dies aufgrund der entstehenden Kosten im Rahmen dieser Vorlesung nicht möglich.
Wir würden jedem, der Cloud-Ressourcen in seinen Applikationen nutzen möchte, raten, sich vorab einmal programmatisch mit diesen zu verbinden, um den Workflow kennenzulernen. Beispielsweise die Implementierung von TLS-Zertifikaten war ein Punkt, den wir nicht von Anfang an auf dem Schirm hatten.
Leave a Reply
You must be logged in to post a comment.