Willkommen zu unserem Erfahrungsbericht aus der Vorlesung „System Engineering and Management“. In den letzten Monaten haben wir uns an ein Projekt gewagt, das uns sowohl technisch als auch persönlich herausgefordert hat – CrowdCloud. Anstatt uns in trockene Theorien zu verlieren, möchten wir euch in diesem Blog-Beitrag erzählen, wie aus einer spontanen Idee eine interaktive, skalierbare Wortwolke wurde, die live das Publikum begeisterte.
CrowdCloud: Wenn Worte abheben
Im Wintersemester 2024/2025 haben wir, Simon und Milena, beschlossen, uns intensiv mit verteilten Systemen und Cloud-Umgebungen auseinanderzusetzen. Kaum hatte die Vorlesung begonnen, stand die erste Herausforderung vor uns: Ein passendes Semesterprojekt zu finden. Nach einigem Hin und Her entschieden wir uns, eine kleine Webanwendung zu entwickeln und diese in die Cloud zu bringen – so wurde CrowdCloud geboren. CrowdCloud ermöglicht es, zu einem bestimmten Thema durch die Auswahl einzelner Wörter abzustimmen. Ein cleverer Algorithmus sortiert dabei die eingegebenen Begriffe, sodass häufiger genannte Wörter größer dargestellt werden. Und das Beste: Die Wortwolke aktualisiert sich live, sodass alle Nutzer stets die aktuellsten Abstimmungsergebnisse sehen.
Das große Ziel: Mehr als nur Wörter
Unser Hauptziel mit CrowdCloud war es, praktische Erfahrungen mit modernen Deployment- und Containerisierungstechnologien zu sammeln. Dabei lag unser Fokus darauf, den Umgang mit Kubernetes, Azure und Terraform zu erlernen und eine skalierbare, automatisierte Infrastruktur aufzubauen. Uns war bewusst, dass wir in diesem Bereich noch Neuland betreten, was die Herausforderungen besonders spannend machte – und uns auf eine steile, aber lohnenswerte Lernkurve schickte.
CrowdCloud unter der Haube – Unsere Architektur
Um unsere interaktive Wortwolke zu entwickeln, haben wir uns für einen modernen Tech-Stack entschieden, der uns nicht nur in der reinen Umsetzung unterstützt hat, sondern uns zugleich tiefgehende Einblicke in das Zusammenspiel der einzelnen Komponenten – von der Entwicklung über das Testing bis hin zum Betrieb – ermöglichte.
Gleichzeitig stand bei der Planung und Umsetzung von CrowdCloud die Wahl der richtigen Technologien im Mittelpunkt. Dabei mussten wir viele Entscheidungen treffen und stets abwägen, welche Tools am besten zu unseren Anforderungen passen. Neben den rein technischen Aspekten flossen auch praktische Überlegungen und Kosteneffizienz in unsere Entscheidungen ein – etwa die kostengünstigen Vorteile von Azure, die speziell für Studierende besonders attraktiv waren.
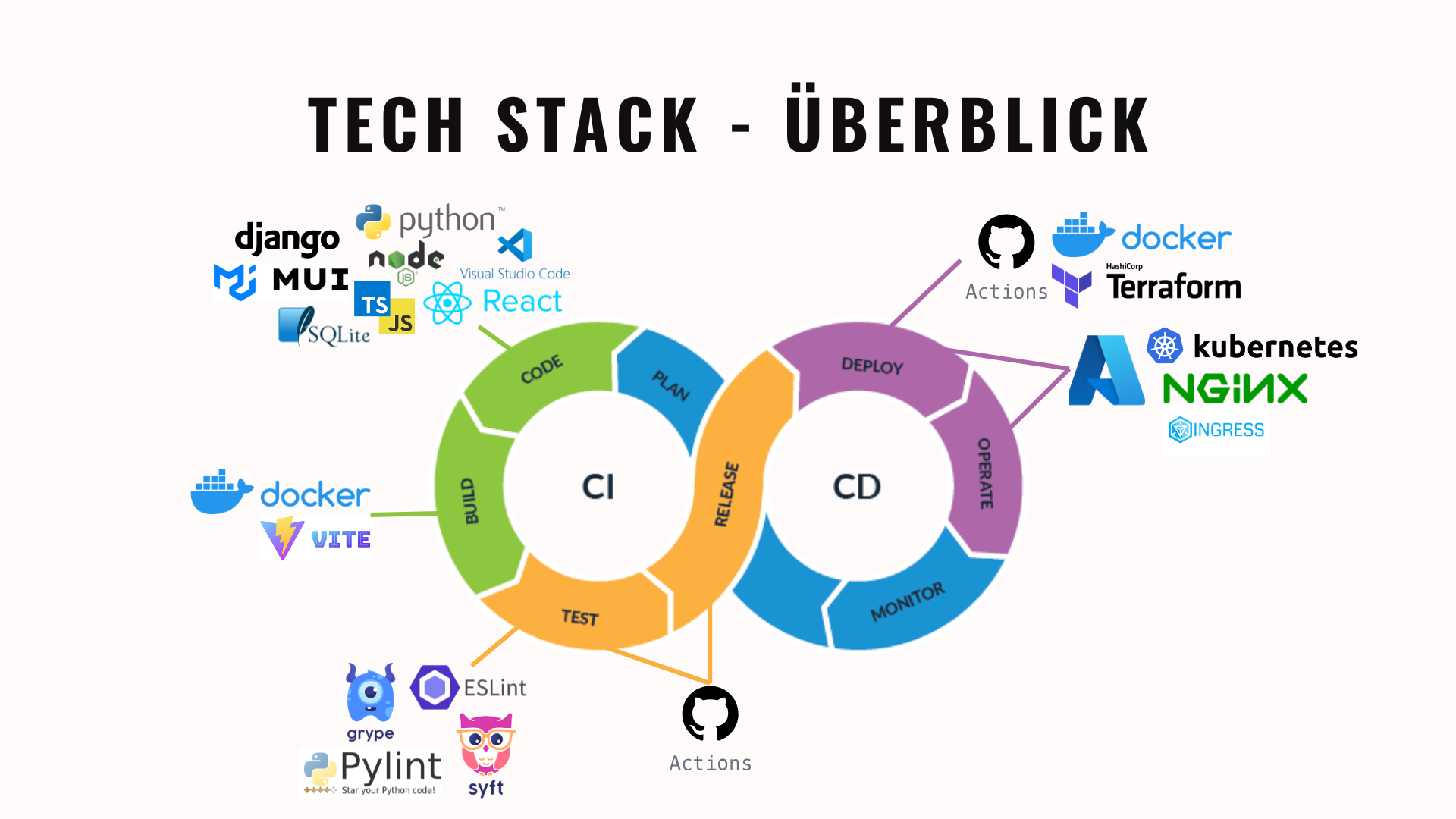
Frontend – Die Bühne für eure Worte
Mit React und TypeScript haben wir eine flexible, komponentenbasierte Architektur aufgebaut, die es uns ermöglichte, wiederverwendbare Bausteine zu entwickeln. MUI sorgte dabei für ein ansprechendes, professionelles Design, während Vite uns durch blitzschnelle Projektinitialisierung und optimierte Builds überzeugte. Zudem spielt Node.js eine zentrale Rolle in unserem Entwicklungsprozess – es liefert die Laufzeitumgebung, die für Tools wie Vite, ESLint und den lokalen Entwicklungsserver unerlässlich ist. So konnten wir sicherstellen, dass die Benutzeroberfläche nicht nur schick aussieht, sondern auch stabil und performant läuft.
Backend – Das Herzstück von CrowdCloud
Auf der Serverseite setzten wir auf Python und Django. Diese Kombination machte es uns leicht, eine robuste und sichere Anwendung zu entwickeln – und das mit einer Syntax, die sich angenehm lesbar und schnell umsetzen ließ. Für die Speicherung der Session-Daten wählten wir die leichtgewichtige SQLite-Datenbank, die genau den richtigen Rahmen für unser Projekt bot.
Containerisierung & Deployment – Unser Weg in die Cloud
Damit alles reibungslos läuft, haben wir unsere Anwendung in Docker-Container verpackt – so konnten wir sicherstellen, dass sie in einer einheitlichen Umgebung läuft, egal ob in der Entwicklung oder im Produktivbetrieb. Anschließend setzten wir auf Kubernetes, um unsere Container effizient zu verwalten und bei Bedarf zu skalieren. Für den Aufbau unserer Cloud-Infrastruktur auf Microsoft Azure nutzten wir Terraform, mit dem wir die gesamte Umgebung deklarativ und reproduzierbar konfigurieren konnten. Den gesamten Ablauf – von der Code-Integration bis hin zum finalen Deployment – unterstützten uns GitHub Actions, die uns einen kontinuierlichen und reibungslosen Workflow ermöglichten.
Testing – Den Code auf Herz und Nieren prüfen
Damit wir immer sicher sein konnten, dass unser Code einwandfrei funktioniert, setzten wir auf einen mehrstufigen Testansatz. Mit ESLint für unser TypeScript und PyLint für Python stellten wir sicher, dass der Code sauber und fehlerfrei ist. Gleichzeitig halfen uns Syft und Grype, indem sie mittels einer Software Bill of Materials (SBOM) und anschließender Sicherheitsanalysen potenzielle Schwachstellen frühzeitig aufdeckten. All diese Tests liefen automatisiert in unseren GitHub Actions – so war Qualität nicht nur ein Versprechen, sondern ein gelebter Standard.
Operate – Der zuverlässige Betrieb von CrowdCloud
Nach dem erfolgreichen Deployment ist der laufende Betrieb das A und O. Microsoft Azure sorgt für eine stabile und skalierbare Infrastruktur, während Kubernetes auch im laufenden Betrieb sicherstellt, dass unsere Anwendung optimal verteilt und verwaltet wird. Ergänzend kommt ein Ingress-Controller zum Einsatz, der den eingehenden Traffic effizient an die richtigen Services weiterleitet und zentralisierte Routing-Regeln ermöglicht. Zusätzlich spielt nginx als Webserver und Reverse Proxy eine zentrale Rolle, indem es den Traffic steuert und für eine zusätzliche Sicherheitsebene sorgt.
Mit diesem Setup können wir gewährleisten, dass CrowdCloud nicht nur gut aussieht und funktioniert, sondern auch dauerhaft zuverlässig und sicher betrieben wird.
Push, Pray, Deploy: Effizienz und Kontrolle im Workflow
Damit unser Entwicklungsprozess reibungslos abläuft und wir jederzeit die volle Kontrolle behalten, haben wir unsere CI/CD-Pipelines bewusst in drei separate Bereiche unterteilt:
Deployment Pipeline – Automatisierte Updates für CrowdCloud
Unsere Deployment-Pipeline wird bei jedem Push in den develop-Branch sowie bei Pull Requests automatisch angestoßen. Sie kümmert sich um den gesamten Ablauf, von der Code-Checkout-Phase über das Erstellen und Pushen der Docker-Images (für Frontend und Backend) bis hin zum Rollout der neuen Versionen über Kubernetes. So stellen wir sicher, dass unsere Anwendung stets aktuell ist und ohne großen manuellen Aufwand live geschaltet werden kann.
Terraform Pipeline – Manuelle Steuerung für stabile Infrastruktur
Das Aufbauen der Infrastruktur benötigt naturgemäß einige Minuten – und nicht jede Code-Änderung erfordert einen erneuten Aufbau. Deshalb haben wir uns bewusst dafür entschieden, die Terraform-Pipeline ausschließlich manuell (über workflow_dispatch) zu starten. Sobald die Infrastruktur einmal steht, musste sie nicht ständig neu aufgebaut werden. Natürlich wollten wir sichergehen, dass unser Plan funktioniert. Also haben wir – in einem mutigen Moment – die gesamte Infrastruktur gelöscht. Ein paar Klicks (und Schweißperlen) später konnten wir stolz feststellen: Die Pipeline hat alles sauber wieder aufgebaut. Mission erfolgreich.
Tests Pipeline – Qualitätssicherung auf allen Ebenen
Parallel dazu läuft unsere Test-Pipeline, die den Code auf Herz und Nieren prüft. Angefangen bei der Einrichtung einer sauberen, isolierten Umgebung für das Backend, über das Ausführen von Unit-Tests, bis hin zu umfassenden Sicherheits-Scans (mit pip-audit, Syft und Grype) und der statischen Code-Analyse (PyLint für den Backend-Code und ESLint für den Frontend-Code). Diese Pipeline wird bei jedem Push und Pull Request automatisch gestartet und sorgt dafür, dass unser Code immer den höchsten Qualitätsstandards entspricht.
Herausforderungen: Die dunkle Seite der Wörterwolke
Die Entwicklung von CrowdCloud war nicht nur ein technisch spannendes Abenteuer, sondern brachte auch einige echte Herausforderungen mit sich, die uns zum Grübeln und intensivem Debuggen zwangen. Im Folgenden möchten wir detailliert auf die größten Stolpersteine eingehen, die uns auf unserem Weg begegnet sind.
Probleme beim Deployment des Blob Storage – Das Henne-Ei-Problem
Ein unerwartetes Problem tauchte bereits zu Beginn unseres Deployments auf: Wir wollten den Blob Storage – also den Speicherort für unsere Terraform-State-Dateien – zusammen mit der restlichen Infrastruktur über dieselbe Pipeline bereitstellen. Dabei stießen wir auf ein klassisches Henne-Ei-Problem.
Unser Ziel war es, den Blob Storage automatisiert über Terraform zu deployen und ihn gleichzeitig als sicheren Ablageort für den Terraform-State zu nutzen. Doch genau hier ergab sich der Teufelskreis:
- Der erste Schritt: Terraform benötigt bereits einen existierenden Blob Storage, um seinen eigenen State sicher ablegen zu können.
- Der zweite Schritt: Gleichzeitig sollte Terraform den Blob Storage selbst anlegen, was aber ohne einen bestehenden State-Bereich nicht optimal funktioniert.
Diese wechselseitige Abhängigkeit führte zu einem logischen Zirkel: Der Blob Storage muss existieren, damit Terraform initialisiert werden kann – und doch soll Terraform dafür sorgen, dass der Blob Storage erstellt wird.
Unsere Lösung:
Um diesen Henne-Ei-Zustand zu durchbrechen, haben wir uns letztlich dafür entschieden, den Blob Storage als manuellen Bootstrapping-Schritt zu erstellen, da der Blob Storage im weiteren Verlauf des Projekts ohnehin nicht verändert wurde. Dieser pragmatische Eingriff ermöglichte es uns, einen stabilen Ausgangspunkt zu schaffen. Sobald der Blob Storage manuell eingerichtet war, konnten wir Terraform einsetzen, um den Rest der Infrastruktur automatisiert und konsistent zu managen.
Ingress – Ein Albtraum in der Konfiguration
Ein zentrales Hindernis in unserem Deployment war die komplexe Einrichtung des Ingress. Ursprünglich hatten wir versucht, statt Ingress die nativen Bordmittel von Kubernetes und Azure zu nutzen, um die Netzwerkkommunikation zwischen Frontend und Backend zu steuern. Doch trotz intensiver Versuche und verschiedener Konfigurationsansätze kamen wir hier nicht weiter – entweder fehlten essenzielle Funktionen, oder die Umsetzung war so aufwendig, dass sie den Nutzen nicht mehr rechtfertigte.
Schließlich entschieden wir uns für Ingress, in der Hoffnung, eine standardisierte und bewährte Lösung zu implementieren. Doch das sollte sich als nervenaufreibender Prozess herausstellen:
- Fehlender Service Principal:
Die Ingress-Konfiguration benötigte einen eigenen Service Principal, um auf die notwendigen Container-Images zugreifen zu können. Diese Abhängigkeit führte dazu, dass unsere Pods zunächst gar nicht starten konnten. - Komplexe Routen-Weiterleitung:
Selbst nach der erfolgreichen Einrichtung des Ingress gab es anhaltende Probleme bei der Weiterleitung der Anfragen. Wir mussten die Routen mehrfach anpassen und testen, bis sie endlich stabil funktionierten.
Unsere Lösung:
Nach langem Debugging erkannten wir, dass das manuelle Anlegen des Service Principals und das Zuweisen der entsprechenden Berechtigungen der einzige Weg war, um die Ingress-Pods zuverlässig ans Laufen zu bekommen. Diese Schritte nahmen wir schließlich in unsere Terraform-Pipeline auf, um zukünftige manuelle Eingriffe zu vermeiden.
Rückblickend:
Obwohl Ingress letztendlich funktionierte, hat es uns während der Entwicklung so viele Nerven gekostet, dass wir uns für zukünftige Projekte tatsächlich überlegen, eine Alternative zu den Bordmitteln und Ingress zu testen. Weder die ursprünglichen Kubernetes- und Azure-Lösungen noch Ingress haben uns vollständig überzeugt. Das zeigt einmal mehr, dass die Wahl der richtigen Infrastruktur nicht nur eine technische, sondern auch eine pragmatische Entscheidung ist.
Wenn die Session schweigt: Unser Websocket-Fehler und die Lösung
Nachdem wir CrowdCloud lokal ausgiebig getestet hatten, schien alles perfekt zu funktionieren. Die Websockets bauten eine stabile Verbindung auf, und die Live-Aktualisierung lief reibungslos – zumindest in unserer Testumgebung. Doch als wir die Anwendung in Azure deployten, wurden wir schnell eines Besseren belehrt.
Obwohl der Client sich erfolgreich mit der Session verband, blieben die Echtzeit-Updates aus. Beim Test unseres Voting-Features fiel uns auf: Die Stimmen wurden zwar korrekt erfasst, doch das Ergebnis aktualisierte sich nicht von selbst. Erst durch ein manuelles Neuladen der Seite erschienen die neuen Daten – ein Umstand, der uns besonders frustrierte, da wir dachten, endlich alles richtig konfiguriert zu haben, und dann versagte der zentrale Echtzeit-Mechanismus.
Unsere Lösung: Die falsche URL als Stolperstein
Nach intensiver Fehlersuche entdeckten wir den Übeltäter: Die Websocket-Verbindung wurde nicht korrekt hergestellt. Lokal hatten wir uns über die URL ws://localhost problemlos mit der Session verbunden. In Azure jedoch war der Einsatz einer ws://-URL nicht vorgesehen – stattdessen war nur die URL http://50.85.88.155 konfiguriert. Da unser Client in der Architektur ausschließlich über diese Verbindung mit der Session kommuniziert, war es entscheidend, dass die korrekte URL verwendet wird.
Die Lösung war letztlich einfach, aber essenziell: Wir passten die Umgebungsvariable an, sodass alle Verbindungen über http://50.85.88.155 liefen. Damit wurde die Websocket-Verbindung korrekt hergestellt und der Client konnte wieder wie vorgesehen die Echtzeit-Updates empfangen.
Mögliche Alternativen: Server-Sent Events als Option
Auch wenn wir uns letztlich für Websockets entschieden haben, hätten wir alternativ auch auf Server-Sent Events (SSE) setzen können – ideal, wenn es um eine unidirektionale Kommunikation geht, bei der der Server Updates an den Client sendet, ohne dass dieser ständig aktiv nachfragen muss. Dennoch sprachen mehrere Faktoren für Websockets:
- Sie ermöglichen eine dauerhafte Verbindung, über die der Client jederzeit an die Session angebunden bleibt und flexibel auf neue Daten reagieren kann.
- Umfangreiche Dokumentation und Ressourcen erleichterten uns den Einstieg.
- Wir wollten uns intensiver mit Websockets auseinandersetzen, da diese in vielen modernen Echtzeit-Anwendungen eine zentrale Rolle spielen.
Der Moment der Wahrheit: CrowdCloud live!
Nach Wochen intensiver Entwicklungsarbeit, zahlreichen Tests und dem ständigen Hin und Her der Fehlersuche stand es endlich so weit: Der Moment der Wahrheit. Die Live-Demo von CrowdCloud war ein voller Erfolg. Es war unglaublich, zu sehen, wie unsere interaktive Wortwolke in Echtzeit funktionierte, Feedback sammelte und ein Lächeln auf die Gesichter der Zuschauer zauberte. Dieser Augenblick – wenn all die langen Stunden und zahllosen Tassen Kaffee sich auszahlen – bleibt unvergesslich.
Learnings: Technische Erkenntnisse und Soft Skills
Für alle, die den Sprung in die Welt der modernen Deployment- und Containerisierungstechnologien wagen möchten, haben wir einige wertvolle Tipps und Erkenntnisse zusammengestellt:
Technische Erkenntnisse
- Modulare Architekturen setzen: Durch die komponentenbasierte Architektur von React und den deklarativen Ansatz in Terraform können Anwendungen flexibel erweitert und angepasst werden. Das hat uns geholfen, unser System effizient und skalierbar zu gestalten.
- Automatisierung ist Gold wert: Der Einsatz von Tools wie GitHub Actions zur Automatisierung von Tests und Deployments hat uns gezeigt, wie viel Zeit und Fehler wir durch kontinuierliche Automatisierung sparen können. Besonders die Implementierung von CI/CD-Pipelines und Sicherheits-Tools wie Syft und Grype hat uns den Wert der Automatisierung und kontinuierlichen Überprüfung nahegebracht.
- Fehlersuche nicht scheuen: Debugging kann frustrierend sein, aber jede gelöste Herausforderung bringt uns weiter. Dokumentiert eure Lösungen, damit ihr bei ähnlichen Problemen in der Zukunft schneller reagieren könnt. In unserem Projekt haben wir nicht nur technische Tools und Technologien gemeistert, sondern auch gelernt, den passenden Mix aus verschiedenen Tools für ein spezifisches Projekt zusammenzustellen.
Soft Skills
- Frustrationstoleranz und Durchhaltevermögen: Jede Herausforderung, egal wie groß, wurde zur Chance, unser Können zu erweitern. Der Umgang mit unerwarteten Problemen und die Geduld, Lösungen zu finden, hat uns als Team gestärkt.
- Teamarbeit macht den Unterschied: Oft war es die gemeinsame Suche nach Lösungen, die uns durch schwierige Phasen getragen hat. Der regelmäßige Austausch von Ideen und das kollektive Problemlösen haben uns sowohl technisch als auch zwischenmenschlich vorangebracht. Flexibilität, um von ursprünglichen Plänen abzuweichen und Anpassungen vorzunehmen, war ebenso wichtig wie das Festhalten an Visionen.
Diese Learnings – sowohl aus technischen Herausforderungen als auch aus zwischenmenschlichen Erfahrungen – werden uns sicherlich in zukünftigen Projekten zugutekommen und sind eine wertvolle Grundlage für weiteres Wachstum und Erfolg.
Wolken am Horizont – Was kommt als Nächstes?
CrowdCloud ist bereits funktionsfähig, doch wie bei jeder Webanwendung gibt es auch hier Bereiche, die sich noch verbessern lassen. Einige dieser Verbesserungen könnten potenziell umgesetzt werden, um das Projekt weiter zu optimieren und den Nutzern ein noch besseres Erlebnis zu bieten.
Hinzufügen von Monitoring-Tools
Eine der nächsten möglichen Verbesserungen wäre das Hinzufügen von Monitoring-Tools. Der Einsatz von Diensten wie Azure Monitor oder Prometheus könnte helfen, die Anwendung und Infrastruktur in Echtzeit zu überwachen. Dies würde es ermöglichen, Probleme schneller zu identifizieren und die Performance proaktiv zu verbessern. Obwohl dies momentan nicht geplant ist, könnte eine solche Integration helfen, das System zu stabilisieren und Fehler frühzeitig zu erkennen.
Verbesserung des Designs und der User Experience
Das Design und die User Experience (UX) könnten ebenfalls weiter optimiert werden. Derzeit erfüllt die Anwendung ihren Zweck, aber durch eine noch intuitivere Benutzeroberfläche und ein ansprechenderes Design könnte das Nutzererlebnis weiter verbessert werden. Eine Überarbeitung des UI könnte dafür sorgen, dass die Benutzer die Wörterwolke effizienter und angenehmer bedienen können. Diese Art der Verbesserung könnte in Betracht gezogen werden, wenn mehr Nutzerfeedback eingeholt wird oder die Anwendung für größere Zielgruppen zugänglich gemacht wird.
Umstellung auf HTTPS
Ein weiterer Schritt, der die Sicherheit der Anwendung verbessern könnte, wäre die Umstellung auf HTTPS. Aktuell sind die Datenübertragungen nicht verschlüsselt, was die Anwendung potenziell angreifbar macht. Durch die Einführung von HTTPS könnte die Kommunikation zwischen Nutzern und Anwendung verschlüsselt werden, was zu einer verbesserten Datensicherheit und einem höheren Vertrauen der Nutzer führen würde. Dies ist jedoch eine optionale Maßnahme, die nur bei Bedarf umgesetzt werden sollte.
Entwickeln von Frontend-Tests
Zudem könnte das Entwickeln von Frontend-Tests ein nächster Schritt sein, um die Stabilität der Anwendung zu erhöhen. Automatisierte Tests würden helfen, Bugs frühzeitig zu erkennen und sicherzustellen, dass zukünftige Änderungen die Benutzeroberfläche nicht beeinträchtigen. Dies würde es ermöglichen, dass die Anwendung auch bei kontinuierlicher Weiterentwicklung stabil bleibt, ohne die User Experience negativ zu beeinflussen. Auch diese Maßnahme ist jedoch nicht zwingend notwendig und würde nur bei einer signifikanten Erweiterung der Anwendung in Erwägung gezogen werden.
Fazit: Unser Weg durch die Wolken
Die Arbeit an CrowdCloud war für uns eine wertvolle praktische Erfahrung, die uns tiefere Einblicke in moderne Cloud-Technologien und Deployment-Methoden ermöglicht hat. Durch den Einsatz von Kubernetes, Azure und Terraformkonnten wir lernen, wie man eine skalierbare und automatisierte Infrastruktur aufbaut.
Während der Entwicklung sind wir auf einige technische Herausforderungen gestoßen, insbesondere bei der Ingress-Konfiguration, dem Deployment des Blob Storage und der Websocket-Integration. Diese Probleme haben uns gezeigt, wie wichtig es ist, flexibel zu bleiben, pragmatische Lösungen zu finden und eine strukturierte Fehlersuche zu betreiben.
Neben den technischen Erkenntnissen haben wir auch unsere Fähigkeiten im Teamwork und im Problemlösen weiterentwickelt. Die Nutzung von CI/CD-Pipelines, Automatisierungstests und Sicherheitschecks hat uns den Wert von sauberem, reproduzierbarem Code verdeutlicht.
Auch wenn CrowdCloud in seiner jetzigen Form bereits einsatzbereit ist, gibt es weiterhin Optimierungspotenzial, beispielsweise durch die Integration von Monitoring-Tools, Verbesserungen im Design oder die Umstellung auf HTTPS. Insgesamt hat uns dieses Projekt gezeigt, wie viele Aspekte beim Aufbau einer Cloud-Anwendung zu berücksichtigen sind und wie wichtig eine durchdachte Architektur für den langfristigen Erfolg ist.
Danke, dass ihr uns auf dieser Reise begleitet habt!
Leave a Reply
You must be logged in to post a comment.