Tag: DevOps
Integration von KI in DevOps: Ein Überblick über AIOps-Prinzipien und -Praktiken
Wie baut man eine CI/CD Pipeline mit Jenkins auf?
Im Rahmen der Vorlesung “System Engineering und Management (143101a)” haben wir es uns zum Ziel gesetzt, mehr über CI/CD Pipelines zu lernen und eine eigene Pipeline für ein kleines Projekt aufzusetzen. Wir haben uns dabei entschieden, Jenkins für die CI/CD Pipeline einzusetzen und eine kleine ToDo App mit dem Framework Flutter zu entwickeln. Im Verlauf…
Secure Code, Fast Delivery: The Power of DevSecOps
In today’s fast-paced digital world, security breaches are more than just a risk; they’re almost a guarantee if you don’t stay ahead. Imagine being able to develop software at lightning speed without compromising on security. Sounds like a dream, right? Welcome to the world of DevSecOps! If you’re curious about how you can seamlessly integrate…
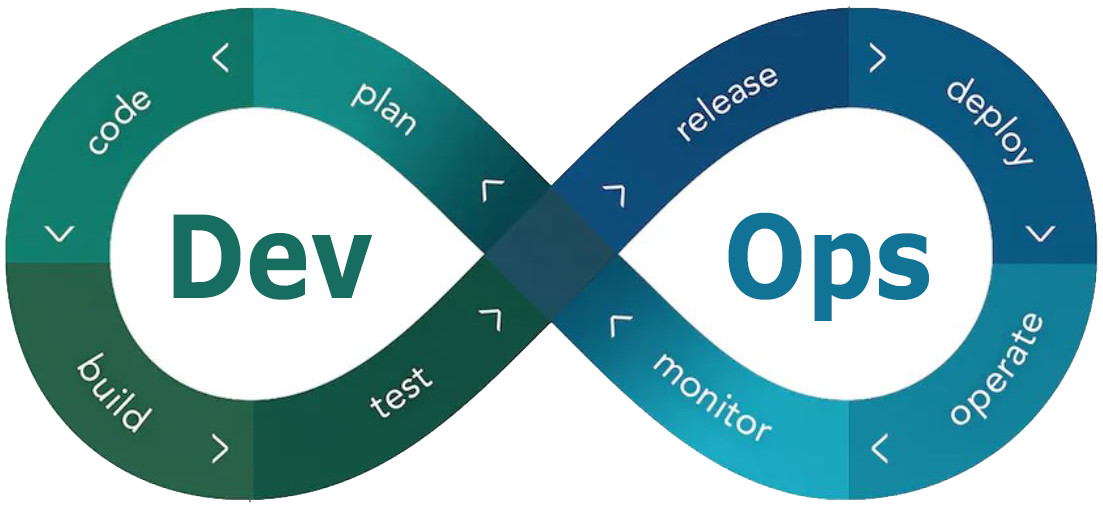
Getting Started with your first Software Project using DevOps
This Post is a getting started guide for creating a DevOps enabled web based software project.
Kubernetes (K8S) everywhere, but how?
In the last months, nearly everybody has been talking about Kubernetes. It’s incredible! This semester the Stuttgart Media University even held a training course on this topic. For DevOps or “cloud-computing specialist” mastering Kubernetes and the concepts around it is becoming more and more important.

Observability?! – Where do we go from here?
The last two years in software development and operations have been characterized by the emerging idea of “observability”. The need for a novel concept guiding the efforts to control our systems arose from the accelerating paradigm changes driven by the need to scale and cloud native technologies. In contrast, the monitoring landscape stagnated and failed…
Radcup Part 2 – Transition into Cloud
Written by: Immanuel Haag, Christian Müller, Marc Rüttler Several steps are necessary to transfer the Radcup backend to the cloud and make it accessible to everyone from the outside. These are explained in more detail in the following sections.
Cloud security tools and recommendations for DevOps in 2018
Introduction Over the last five years, the use of cloud computing services has increased rapidly, in German companies. According to a statistic from Bitkom Research in 2018, the acceptance of cloud-computing services is growing. Cloud-computing brings many advantages for a business. For example, expenses for the internal infrastructure and its administration can be saved. Resource…
You must be logged in to post a comment.