von Mario Beck (mb343) und Felix Ruh (fr067)
Einleitung
Unser Ziel war es, einen Programm Updater für Entwickler zu erstellen, den diese einfach in ihre CI/CD-Pipeline integrieren können. Für die Umsetzung haben wir die IBM Cloud und eine Serverless Architektur verwendet, um eine unbegrenzte Skalierbarkeit zu erreichen. Zu den verwendeten Serverless Services zählen die Cloud Functions, DB2 und ein Object Storage.
Das Projekt besteht aus einem Uploader, mit dem der Entwickler sein Programm in den Object Storage hochladen kann. Und einem Downloader für den Benutzer, mit dem automatisch die aktuelle Version heruntergeladen wird.
Verwendung aus der Entwicklersicht:
- Programm wird registriert und man bekommt die dazugehörigen API-Keys
- Erstellen der Config für den Downloader
- Mit dem Uploader kann das Programm hochgeladen werden, dies kann einfach in eine CI/CD Pipeline eingebunden werden
Verwendung aus der Benutzersicht:
- Herunterladen des Downloaders und der Config
- Starten des Downloaders
- Vor Programmstart wird nach neuen Updates gesucht und diese falls vorhanden heruntergeladen
- Nach dem Update wird das eigentliche Programm gestartet
Beispiel
Entwicklersicht
Programm registrieren:java -jar upload.jar registerprogram -p <name> --publishread
Config erstellen:updater_info.json : {"program": "<name>", "exe": "<path to exe>", "modules": [{"module": "main", "version": ""}]}
Beispiel Command für CI/CD:java -jar upload.jar upload -a <apiKey> -p <name> -v <version> PATH_TO_UPLOAD
(Optional) Extra Modul registrieren:java -jar upload.jar registermodule -a <apiKey> -p <name> -m <moduleName>
(Optional) Auf neuem Modul hochladen:java -jar upload.jar upload -a <apiKey> -p <name> -m <moduleName> -v <version> PATH_TO_UPLOAD
Benutzersicht:
1. Herunterladen des Downloaders und Config
2. Starten der “download.exe”, config muss auf derselben Ebene des Downloaders liegen. (./download.exe)
Module
Jedes Programm, welches von einem Entwickler registriert wird, ist in Module gegliedert.
Dabei wird bei der Registrierung des Hauptprogramms das Hauptmodul automatisch erstellt. Dieses Hauptmodul beinhaltet alle Dateien, die für das Programm grundsätzlich benötigt werden.
Es ist dann auch möglich, weitere Module für dieses Programm zu registrieren. Alle Dateien, welche in diesen enthalten sind, können dann zusätzlich zu den Dateien des Hauptmoduls heruntergeladen werden.
Dies ermöglicht eine sehr einfache Erweiterung des Hauptprogramms und kann daher unumständlich für die Umsetzung von Plugins oder DLCs genutzt werden.
Zusätzliche Module können vom Entwickler des Hauptmoduls, aber auch von 3rd-Party Entwicklern registriert werden. Die einzige Möglichkeit, 3rd-Party Entwickler nicht für Module zuzulassen, ist die Entwicklung eines eigenen Downloadprogramms.
Der Endnutzer kann außerdem sehr einfach auswählen, welche zusätzlichen Module er herunterladen möchte und welche nicht.
Versionen
Jedes Modul hat eine Versionierung. Das bedeutet, beim Hochladen der Dateien muss eine Versionsnummer oder -bezeichnung vergeben werden.
Dadurch ist es möglich, dass beim Updaten des Moduls nur die Dateien heruntergeladen werden müssen, die sich verändert haben. Selbiges gilt auch für die Speicherung im Object Storage.
Aufbau/Architektur
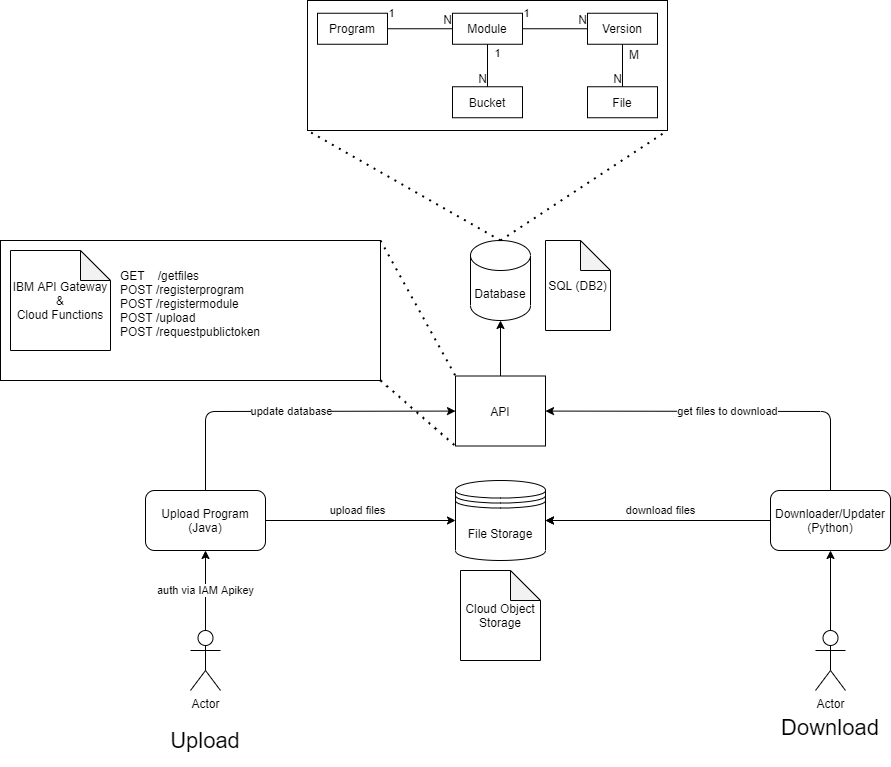
API Routen
POST registerprogram/-module
Bei den /register Routen können neue Programme und Module registriert werden. Dabei werden die entsprechenden Einträge in der Datenbank erstellt und dem Entwickler wird ein API-Schlüssel gegeben, um Schreibzugriff auf das Modul zu ermöglichen.
POST upload
Mit der /upload Route werden die Dateien einer neuen Version angegeben, sodass diese in der Datenbank registriert werden können. Dabei werden alle Hashes der Dateien übergeben, sodass die Cloud-Function nur die neuen Dateien einträgt.
POST requestpublictoken
Mit der /requestpublictoken Route kann man sich Bearer Tokens für alle veröffentlichten Module anfordern, um Lesezugriff auf den entsprechenden Bucket zu erhalten.
GET getfiles
Mit der /getfiles Route kann eine Liste der benötigten Files angerufen werden, die benötigt werden, um von einer Version auf eine andere zu kommen.
Filestorage: Cloud Object Storage (COS)
Wir haben ein Object Storage in dem alle Buckets, welche jeweils für ein Programm oder Third-Party Module stehen (siehe Module) erstellt werden.
Diese Buckets werden alle in der EU Region erstellt, das ist nicht optimal und könnte mit mehr verfügbaren Ressourcen verbessert werden (siehe Verbesserungsmöglichkeiten).
In diesen Buckets werden alle unterschiedlichen Versionen und Module gespeichert, um diese zu unterscheiden werden die mit einem gewissen Prefix gekennzeichnet, der wie folgt aufgebaut ist: programname_modulname_version.
Um die Ordnerstruktur beizubehalten, folgt nach dem Prefix der Pfad mit dem Dateinamen am Ende.
Beispiel eines für die Unit Tests erstellten Buckets:
downloadTestingBucket_main_1/testFolder/testFolder1/test_file_3.txt
DB2

Wir haben das relationale Datenbank Management System DB2 von IBM benutzt.
Dort werden alle Informationen der Programme, dessen Module und Dateien gespeichert.
Zu Optimierungszwecken besteht zwischen den Versionen und den Files eine “N zu M”-Beziehung, sodass alte Dateien nicht doppelt gespeichert werden und Redundanz vermieden wird. Eine Datei kann also zu mehreren Versionen gehören, wenn diese sich nicht verändert hat.
Downloader
Default Downloader
Mit dem Downloader soll es möglich sein Programme vor dem eigentlichen Programmstart zu aktualisieren. Die Downloader Executable ist somit für den eigentlichen Programmstart und das Updaten verantwortlich.
Der Downloader sucht zuerst nach einer neuen Version und aktualisiert das Programm, falls eine vorhanden ist. Nach dem Update wird dann das eigentliche Programm gestartet, welches in einer Config Datei angegeben ist. In dieser Config Datei wird außerdem noch angegeben, um welches Programm es sich handelt und welche Module mit welcher Version installiert sind.
Um weitere Module zu installieren, gibt es die Möglichkeit der Exe ein Start Argument mit zu übergeben, durch welches man in der Konsole dann alle möglichen Module aufgelistet bekommt und unter diesen auswählen kann, welche man installieren möchte.
Anwendung: “./download.exe modules”
Custom Downloader
Es wäre ebenso möglich, sich einen benutzerdefinierten Downloader zu schreiben. Das ist beispielsweise notwendig, falls man für ein Programm nicht den Public Access aktiviert, da in dem Default Downloader die Tokens für die Lese Berechtigung des Buckets über die Route /requestpublictoken angefordert werden.
Außerdem ist es so möglich, 3rd-Party Module zu unterbinden und Geld für die eigenen Module zu verlangen.
Uploader
Der Uploader ist eine Java CLI Anwendung, die mithilfe von dem picocli Framework erstellt wurde. Durch das Framework war es möglich, simpel und schnell eine Konsolen Anwendung zu schreiben.
Mit dem Uploader ist es möglich, Programme und Module zu erstellen/registrieren und ein Programm hochzuladen. Beim Uploaden einer neuen Version werden außerdem nur die Dateien hochgeladen, die sich seit der letzten Version verändert haben. Der Ablauf des Programmes ist wie folgt:

Die Dateien werden parallel gehasht und später ebenso parallel geuploadet.
Man Page des CLI Programms:
Commands:
registermodule Register a new module
registerprogram Register a new program and get the corresponding api key
upload upload files
registermodule:
Register a new module
-a, --apiKey=<apiKey> The corresponding Api Key to the bucket/program
-b, --newbucket Creates the custom module in a new bucket. Default is false
-c, --custommodule=<customModule> Module name of the custom module which was used to create a new bucket
-m, --module=<moduleName> Module name to add
-p, --program=<programName> name where the module gets added to
-r, --publishread Everyone can download your custom module. Default is false
registerprogram:
Register a new program and get the corresponding api key
-p, --program=<programName> The name of the program you want to register
-r, --publishread Everyone can download your program
upload:
upload files
FOLDER folder which should get uploaded
-a, --apiKey=<apiKey> The corresponding Api Key to the bucket/program
-m, --module=<moduleName> Module name of the files to upload. Default is main
-p, --program=<programName> Program name of the files to upload.Authentification
Damit man nicht in den Buckets von fremden Entwicklern Dateien hochladen kann und somit dort Schadware verbreitet wird, erfolgt eine Authentifizierung über die IBM Service-IDs (IAM).
Bei der Registrierung eines Programms oder Moduls werden zwei Service-IDs erstellt. Davon hat einer nur Leseberechtigungen und eine hat Schreib- und Leseberechtigungen für den Bucket des Entwicklers im Object Storage. Der Entwickler bekommt dann zwei entsprechende API-Keys zum Hochladen der Dateien und zum Verteilen der Software.
Der Schlüssel mit Lesezugriff kann entweder direkt veröffentlicht werden, oder der Entwickler behält diesen für sich.
Wenn er ihn für sich behält, muss er einen eigenen Downloader schreiben, mit welchem er dann den Zugriff darauf beschränken kann.
Momentan kann sich jeder beliebig viele Module registrieren, und es gibt keine Möglichkeit nachzuvollziehen, wer welche Module registriert hat. Wenn man dies erreichen möchte kann man Services benutzen, welche äquivalent zu AWS Cognito sind. Möglichkeiten sind zum Beispiel “App ID” (allerdings keine Berechtigungsverwaltung für Buckets) oder IBM Security Verify (allerdings nicht als Service in der Cloud nutzbar).
CI/CD-Pipeline
Wir betreiben eine simple CI/CD Pipeline über Gitlab. Diese testet alle Teilprojekte (Functions, Downloader, Uploader), daraufhin wird für den Uploader eine Jar erstellt, für den Downloader eine Executable und die Functions werden auf die IBM Cloud deployed.

Tests Uploader
Mit den Unit Tests für den in Java geschriebenen Uploader wird sichergestellt, dass Dateien korrekt in den Bucket hochgeladen werden. Außerdem wird getestet, ob die Ordnerstruktur beibehalten wird. Die anderen Funktionen wie das Registrieren eines Programms oder Moduls muss nicht getestet werden, da das nur Api Calls sind, die schon bei den Api Tests getestet wird.
Tests Downloader
Mit den Unit Tests für den in Python geschriebenen Downloader, wird sichergestellt, dass Dateien korrekt, vollständig und in den richtigen Pfad heruntergeladen werden. Außerdem wird getestet, ob Ordner korrekt erstellt werden und ob die Ordnerstruktur die richtige ist. Da das Programm nicht wirklich mehr Funktionen hat, muss auch nicht mehr getestet werden.
Tests API-Routen
Die Routen der API werden mithilfe von Maven getestet. Wir haben uns dafür entschieden Maven zu verwenden, da es das Testing-Tool ist, mit welchem wir uns am besten auskennen.
Im Nachhinein wäre es besser gewesen, ein anderes Tool dafür zu verwenden, da so keine grundlegenden Unit-Tests möglich sind, sondern lediglich die Gesamtfunktionalität der Route überprüft werden kann.
Außerdem könnte man die Tests noch verbessern, indem man eine eigene Testumgebung erstellt und dort testet, statt dies in der produktiven Umgebung zu machen. Das war uns leider nicht möglich, da der IMB-Lite-Account nur eine Instanz pro Service zulässt.
Deployment von Functions
Die Functions laufen auf einem benutzerdefinierten Docker Build, welches in der in der Pipeline gebaut werden sollte, aber leider nicht möglich war, siehe Herausforderungen. Nach dem Bauen und Pushen des Docker Build werden die Functions zusammen mit dem Docker Image geupdatet.
Herausforderungen
Aspera
Da in der IBM Cloud Object Storage Dokumentation erwähnt wurde, dass man für große Dateigröße Aspera verwenden soll, haben wir versucht, das in das Java Uplaoder Programm mit einzubauen. Aspera ist eine Dateiübertragungs und Streaming Technologie.
Anstatt das Standarduploadverfahren der Cos API zu nutzen, haben wir versucht die Aspera Java API zu benutzen. Dabei hatten wir aber Probleme, da die Dateien zwar hochgeladen wurden, die laufende Uploads aber nicht korrekt beendet wurden und somit ab einem gewissen Zeitpunkt keine Uploads mehr gestartet werden konnten, da ein Maximum erreicht wurde.
Da uns das Problem aber zu viel Zeit gekostet hat und wir es nicht gelöst bekommen haben, sind wir auf den Multipartupload umgestiegen. Das ist zwar nicht so effizient, aber hilft trotzdem für große Dateigrößen, da die Datei in kleinere Parte unterteilt werden, welche dann hochgeladen werden.
Docker Image Build in der Pipeline
Es war geplant, das Docker Image, das selbst geschrieben Helper Funktionen und ein weiteres IBM-Package enthält, in der Pipeline zu bauen und zu pushen, was aber aufgrund von Gitlab Pipeline Runner Limitierungen nicht möglich war.
Cloud Functions sind nicht für den Upload von Dateien geeignet
Unsere ursprüngliche Idee war es, die Dateien nicht über den Uploader in den COS hochzuladen, sondern diese der /upload Route als Argument zu übergeben. So wäre es möglich gewesen, dass die Route die komplette Logik übernimmt, welche Dateien, wo hochgeladen werden müssen.
Allerdings haben die Cloud Functions ein Upload-Limit von ein paar Megabytes. Dadurch war uns nicht möglich, die Logik komplett auszulagern. Stattdessen wird als Argument der Route nur eine Liste mit den Namen und Hashes der Dateien gegeben. Damit kann die Route dann die Datenbank updaten und als Antwort dem Client mitteilen, welche Dateien er hochladen muss.
Keine eigenen Bibliotheken mit NodeJS in Cloud Functions möglich
Wenn man die Standard NodeJS-Umgebung der Cloud Functions verwendet, sind darin nur einzelne Bibliotheken vorhanden. Möchte man eigene Bibliotheken verwenden, muss man ein Dockerimage erstellen.
Da wir bis zu diesem Zeitpunkt noch nie Docker verwendet hatten, mussten wir uns dort erst etwas einarbeiten. Sobald jedoch alles aufgesetzt war, hat es einwandfrei funktioniert.
Verbesserungen
Test Db & Test Cos
Für die Tests wäre es optimal, die Produktion Datenbank und Object Storage von den Tests zu trennen. Das ist für uns aber leider nicht möglich, da wir durch den Lite Plan nur eine Db und einen Object Storage benutzten können. Deshalb läuft alles über dieselbe Datenbank und Object Storage.
Verbesserte Downloadgeschwindigkeit für den Download
Die Geschwindigkeit des Dateiuploads und Downloads sind schon recht gut optimiert, und wir konnten selbst mit einem Download von 900 Mbit/s kein Limit erreichen.
Allerdings werden zurzeit alle Programme direkt aus dem entsprechendem Bucket in Europa heruntergeladen. Um eine verbesserte Downloadgeschwindigkeit zu erreichen, wenn viele Benutzer über verschiedene Kontinente etwas herunterladen, kann ein Content Delivery Network (CDN) verwendet werden. Dies war uns leider mit einem Lite-Account nicht möglich.
Alternativ könnten auch mehrere Buckets pro Programm in verschiedenen Regionen erstellt werden.
Limit der Service-IDs
Wir verwenden für die Authentifizierung die IAM Service-IDs und diese sind pro Account auf 2000 Stück beschränkt. Für jedes Programm wird ein neuer Bucket erstellt und jeder Bucket benötigt 2 Service-IDs (eine pro API-Key).
Das bedeutet, dass unser Projekt auf 1000 Buckets beschränkt ist, und es keine einfache Möglichkeit gibt dieses Limit zu erhöhen.
Die beste Möglichkeit ist es nicht IAM zu verwenden und eine Alternative dazu zu finden oder etwas selber zu entwickeln. Es könnte beispielsweise das IMB-Äquivalent des AWS Cognito Services verwendet werden.
Fazit
Wir haben all unsere eigenen Anforderungen an das Projekt erfolgreich umgesetzt. Dabei sind wir auf einige Herausforderungen und Limitationen des Lite-Accounts der IBM-Cloud gestoßen.
Haben uns aber auch mit vielen uns neuen Technologien, Themen und Konzepten auseinander gesetzt. Dazu zählen unter anderem Konzepte, wie Serverless Architektur und Skalierbarkeit.
Aber auch der generelle Umgang mit Cloud-Funktionalitäten insbesondere der Cloud Object Storage, DB2, Cloud Functions, Authentifizierung (IAM) und Docker.
Leave a Reply
You must be logged in to post a comment.